celery入门介绍
Celery 分布式任务队列快速入门
(参考文献:https://mp.weixin.qq.com/s?__biz=MzA3NDk1NjI0OQ==&mid=2247483737&idx=1&sn=3f44134e630408c9b950f7d513722059&chksm=9f76adefa80124f94d0d0faa8751530636cb9863e9af9d6c56475719b57c105aa611423d5656&scene=0&key=fe4410a4c5efc39c0e8446813f2c912b96cf642896a427c38fa7696c16c05e0d71aa6d459a3dc06323635f70f446f624&ascene=0&uin=MjIxMzU3Nzk0Mw==&devicetype=iMac+MacBookPro11,1+OSX+OSX+10.11.5+build(15F34)&version=11020201&pass_ticket=JHZTvo8aIbGsUd9a9yaAEFOv3sC+l/v3QZQCZ/jJTAGDTmE+NNNGgg3PKPAGT7Fb)
https://www.rapospectre.com/blog/celery-user-guide(大牛)
本节内容
Celery介绍和基本使用
在项目中如何使用celery
启用多个workers
Celery 定时任务
与django结合
通过django配置celery periodic task
一、Celery介绍和基本使用
Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理, 如果你的业务场景中需要用到异步任务,就可以考虑使用celery, 举几个实例场景中可用的例子:
- 你想对100台机器执行一条批量命令,可能会花很长时间 ,但你不想让你的程序等着结果返回,而是给你返回 一个任务ID,你过一段时间只需要拿着这个任务id就可以拿到任务执行结果, 在任务执行ing进行时,你可以继续做其它的事情。
- 你想做一个定时任务,比如每天检测一下你们所有客户的资料,如果发现今天 是客户的生日,就给他发个短信祝福
Celery 在执行任务时需要通过一个消息中间件来接收和发送任务消息,以及存储任务结果, 一般使用rabbitMQ or Redis,后面会讲
1.1 Celery有以下优点:
- 简单:一单熟悉了celery的工作流程后,配置和使用还是比较简单的
- 高可用:当任务执行失败或执行过程中发生连接中断,celery 会自动尝试重新执行任务
- 快速:一个单进程的celery每分钟可处理上百万个任务
- 灵活: 几乎celery的各个组件都可以被扩展及自定制
Celery基本工作流程图
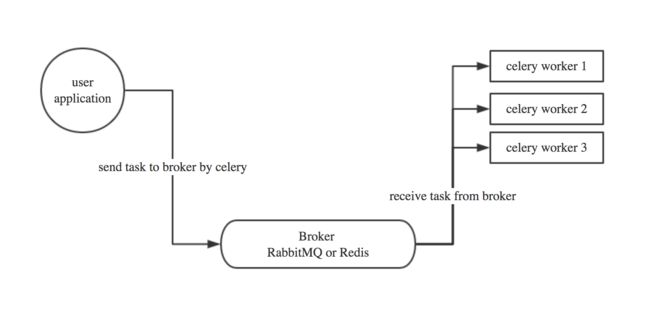
1.2 Celery安装使用
Celery的默认broker是RabbitMQ, 仅需配置一行就可以
然后进行配置,一般都在项目的config.py文件里配置:
broker_url = 'amqp://guest:guest@localhost:5672//'rabbitMQ 没装的话请装一下,安装看这里 http://docs.celeryproject.org/en/latest/getting-started/brokers/rabbitmq.html#id3
使用Redis做broker也可以
安装redis组件
$ pip install -U "celery[redis]"
配置
Configuration is easy, just configure the location of your Redis database:
app.conf.broker_url = 'redis://localhost:6379/0'( (配置很简单,只要配置你的Redis数据库的位置:))
Where the URL is in the format of:
redis://:password@hostname:port/db_number(配置redis数据库,配置数据库储存结果)
all fields after the scheme are optional, and will default to localhost on port 6379, using database 0.
如果想获取每个任务的执行结果,还需要配置一下把任务结果存在哪
If you also want to store the state and return values of tasks in Redis, you should configure these settings:
app.conf.result_backend = 'redis://localhost:6379/0'
1. 3 开始使用Celery啦
安装celery模块
$ pip install celery个celery application 用来定义你的任务列表
创建一个任务文件就叫tasks.py吧
from celery import Celery
import time
app = Celery('tasks', #创建了一个celery的实例app
broker='redis://localhost', #指定消息中间件用redis
backend='redis://localhost')#指定储存用redis
@app.task
def add(x,y):
print("running...",x,y) #模拟耗时操作
time.sleep()
return x+y
启动Celery Worker来开始监听并执行任务
$ celery -A tasks worker --loglevel=info
#这里tasks指项目存放app的文件夹
执行命令详解
celery -A app.celery_tasks.celery worker -Q queue --loglevel=info
1.A参数指定celery对象的位置,该app.celery_tasks.celery指的 是app包下面的celery_tasks.py模块的 celery实例,注意一定是初始化后的实例,
2.Q参数指的是该worker接收指定的队列的任务,这是为了当多个队列有不同的任务时可以独立;如果不设会接收所有的队列的任务;
3.l参数指定worker的日志级别;
调用任务
再打开一个终端, 进行命令行模式,调用任务
| 1 2 |
|
看你的worker终端会显示收到 一个任务,此时你想看任务结果的话,需要在调用 任务时 赋值个变量
| 1 |
|
The ready() method returns whether the task has finished processing or not:(ready()方法返回任务是否完成处理:)
>>> result.ready() False
You can wait for the result to complete, but this is rarely used since it turns the asynchronous call into a synchronous one:
(您可以等待结果完成,但这很少使用,因为它将异步调用转换为同步调用:)
>>> result.get(timeout=1) 8
In case the task raised an exception, get() will re-raise the exception, but you can override this by specifying the propagate argument:
(如果任务引发异常,get()将重新引发异常,但是您可以通过指定propagate参数来覆盖该异常:)
>>> result.get(propagate=False)
If the task raised an exception you can also gain access to the original traceback:(如果任务引发异常,您还可以访问原始回溯:)
>>> result.traceback …
二、在项目中如何使用celery
可以把celery配置成一个应用
目录格式如下
proj/__init__.py
/Celery.py
/task.pyproj/celery.py内容
from __future__ import absolute_import, unicode_literals
from celery import Celery
方案一:
proj/Celery.py
app = Celery('proj',
broker='amqp://',
backend='amqp://',
include=['proj.tasks'])
# Optional configuration, see the application user guide.
app.conf.update(
result_expires=3600,
)
if __name__ == '__main__':
app.start()
方案二:
from __future__ import absolute_importfrom celery import Celery
app = Celery('proj', include=['proj.tasks'])
app.config_from_object('proj.celeryconfig') #导入celery的celeryconfig.py的配置文件
if __name__ == '__main__':
app.start()proj/tasks.py中的内容
from __future__ import absolute_import, unicode_literals
from .celery import app
@app.task
def add(x, y):
return x + y
@app.task
def mul(x, y):
return x * y
@app.task
def xsum(numbers):
return sum(numbers)启动worker
| 1 |
|
输出
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
后台启动worker
In the background
In production you’ll want to run the worker in the background, this is described in detail in the daemonization tutorial.
The daemonization scripts uses the celery multi command to start one or more workers in the background:
(1.在后台在生产中,您希望在后台运行worker,这在守护进程教程中有详细描述。守护化脚本使用celery命令在后台启动一个或多个worker::
2.1.执行进程 2.管理定时任务进程
3.在xshell连接中,超过一定的时间会自动断开 .ssh连接
)
$ celery multi start w1 -A proj -l info
celery multi v4.0.0 (latentcall)
> Starting nodes...
> w1.halcyon.local: OK
You can restart it too:
$ celery multi restart w1 -A proj -l info
celery multi v4.0.0 (latentcall)
> Stopping nodes...
> w1.halcyon.local: TERM -> 64024
> Waiting for 1 node.....
> w1.halcyon.local: OK
> Restarting node w1.halcyon.local: OK
celery multi v4.0.0 (latentcall)
> Stopping nodes...
> w1.halcyon.local: TERM -> 64052
or stop it:
$ celery multi stop w1 -A proj -l info
The stop command is asynchronous so it won’t wait for the worker to shutdown. You’ll probably want to use the stopwait command instead, this ensures all currently executing tasks is completed before exiting:
(stop命令是异步的,所以它不会等待worker关闭。你可能会想要使用stopwait命令,这可以确保所有当前执行的任务都在退出之前完成:)
$ celery multi stopwait w1 -A proj -l info
三、Celery 定时任务
celery支持定时任务,设定好任务的执行时间,celery就会定时自动帮你执行, 这个定时任务模块叫celery beat
写一个脚本 叫periodic_task.py
from celery import Celery
from celery.schedules import crontab
app = Celery()
@app.on_after_configure.connect
def setup_periodic_tasks(sender, **kwargs): #1.设置定期执行的任务 2.根据传入的arg的参数设置定任务执行的时间
# Calls test('hello') every 10 seconds.(#每10秒调用test('hello')一次。)
sender.add_periodic_task(10.0, test.s('hello'), name='add every 10')
# Calls test('world') every 30 seconds(#每30秒调用test(“world”)一次)
sender.add_periodic_task(30.0, test.s('world'), expires=10)
# Executes every Monday morning at 7:30 a.m.(#在每周一早上7:30执行。)
sender.add_periodic_task(
crontab(hour=7, minute=30, day_of_week=1),
test.s('Happy Mondays!'),
)
@app.task
def test(arg):
print(arg)add_periodic_task 会添加一条定时任务
上面是通过调用函数添加定时任务,也可以像写配置文件 一样的形式添加, 下面是每30s执行的任务
| 1 2 3 4 5 6 7 8 |
|
任务添加好了,需要让celery单独启动一个进程来定时发起这些任务, 注意, 这里是发起任务,不是执行,这个进程只会不断的去检查你的任务计划, 每发现有任务需要执行了,就发起一个任务调用消息,交给celery worker去执行
启动任务调度器 celery beat
| 1 |
|
输出like below
| 1 2 3 4 5 6 7 8 9 10 |
|
此时还差一步,就是还需要启动一个worker,负责执行celery beat发起的任务(以上表述可能不是很明确。可以参考下图,查看django-celery-beat的执行流程)

启动celery worker来执行任务
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
好啦,此时观察worker的输出,是不是每隔一小会,就会执行一次定时任务呢!
注意:Beat needs to store the last run times of the tasks in a local database file (named celerybeat-schedule by default), so it needs access to write in the current directory, or alternatively you can specify a custom location for this file:
(celerybeat-schedule 文件可以存储上次任务结束时间周期 2.可以直接放在django文件下)
| 1 |
|
更复杂的定时配置
上面的定时任务比较简单,只是每多少s执行一个任务,但如果你想要每周一三五的早上8点给你发邮件怎么办呢?哈,其实也简单,用crontab功能,跟linux自带的crontab功能是一样的,可以个性化定制任务执行时间
linux crontab http://www.cnblogs.com/peida/archive/2013/01/08/2850483.html
| 1 2 3 4 5 6 7 8 9 10 |
|
上面的这条意思是每周1的早上7.30执行tasks.add任务
还有更多定时配置方式如下:
| Example | Meaning |
crontab() |
Execute every minute. |
crontab(minute=0, hour=0) |
Execute daily at midnight. |
crontab(minute=0, hour='*/3') |
Execute every three hours: midnight, 3am, 6am, 9am, noon, 3pm, 6pm, 9pm. |
|
|
Same as previous. |
crontab(minute='*/15') |
Execute every 15 minutes. |
crontab(day_of_week='sunday') |
Execute every minute (!) at Sundays. |
|
|
Same as previous. |
|
|
Execute every ten minutes, but only between 3-4 am, 5-6 pm, and 10-11 pm on Thursdays or Fridays. |
crontab(minute=0,hour='*/2,*/3') |
Execute every even hour, and every hour divisible by three. This means: at every hour except: 1am, 5am, 7am, 11am, 1pm, 5pm, 7pm, 11pm |
crontab(minute=0, hour='*/5') |
Execute hour divisible by 5. This means that it is triggered at 3pm, not 5pm (since 3pm equals the 24-hour clock value of “15”, which is divisible by 5). |
crontab(minute=0, hour='*/3,8-17') |
Execute every hour divisible by 3, and every hour during office hours (8am-5pm). |
crontab(0, 0,day_of_month='2') |
Execute on the second day of every month. |
|
|
Execute on every even numbered day. |
|
|
Execute on the first and third weeks of the month. |
|
|
Execute on the eleventh of May every year. |
|
|
Execute on the first month of every quarter. |
上面能满足你绝大多数定时任务需求了,甚至还能根据潮起潮落来配置定时任务, 具体看 http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html#solar-schedules
四、最佳实践之与django结合
django 可以轻松跟celery结合实现异步任务,只需简单配置即可
If you have a modern Django project layout like:
- proj/ - proj/__init__.py - proj/settings.py - proj/urls.py - manage.py
then the recommended way is to create a new proj/proj/celery.py module that defines the Celery instance:
file: proj/proj/celery.py
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
Then you need to import this app in your proj/proj/__init__.py module. This ensures that the app is loaded when Django starts so that the @shared_task decorator (mentioned later) will use it:
proj/proj/__init__.py:
| 1 2 3 4 5 6 7 |
|
Note that this example project layout is suitable for larger projects, for simple projects you may use a single contained module that defines both the app and tasks, like in the First Steps with Celery tutorial.
Let’s break down what happens in the first module, first we import absolute imports from the future, so that our celery.py module won’t clash with the library:
| 1 |
|
Then we set the default DJANGO_SETTINGS_MODULE environment variable for the celery command-line program:
| 1 |
|
You don’t need this line, but it saves you from always passing in the settings module to the celery program. It must always come before creating the app instances, as is what we do next:
| 1 |
|
This is our instance of the library.
We also add the Django settings module as a configuration source for Celery. This means that you don’t have to use multiple configuration files, and instead configure Celery directly from the Django settings; but you can also separate them if wanted.
The uppercase name-space means that all Celery configuration options must be specified in uppercase instead of lowercase, and start with CELERY_, so for example the task_always_eager` setting becomes CELERY_TASK_ALWAYS_EAGER, and the broker_url setting becomes CELERY_BROKER_URL.
You can pass the object directly here, but using a string is better since then the worker doesn’t have to serialize the object.
| 1 |
|
Next, a common practice for reusable apps is to define all tasks in a separate tasks.pymodule, and Celery does have a way to auto-discover these modules:
| 1 |
|
With the line above Celery will automatically discover tasks from all of your installed apps, following the tasks.py convention:
| 1 2 3 4 5 6 |
|
Finally, the debug_task example is a task that dumps its own request information. This is using the new bind=True task option introduced in Celery 3.1 to easily refer to the current task instance.
然后在具体的app里的tasks.py里写你的任务
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
在你的django views里调用celery task
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
五、在django中使用计划任务功能
There’s the django-celery-beat extension that stores the schedule in the Django database, and presents a convenient admin interface to manage periodic tasks at runtime.
To install and use this extension:
-
Use pip to install the package:
$ pip install django-celery-beat
-
Add the
django_celery_beatmodule toINSTALLED_APPSin your Django project’settings.py:INSTALLED_APPS = ( ..., 'django_celery_beat', ) Note that there is no dash in the module name, only underscores. -
Apply Django database migrations so that the necessary tables are created:
$ python manage.py migrate
-
Start the celery beat service using the
djangoscheduler:$ celery -A proj beat -l info -S django
-
Visit the Django-Admin interface to set up some periodic tasks.
在admin页面里,有3张表
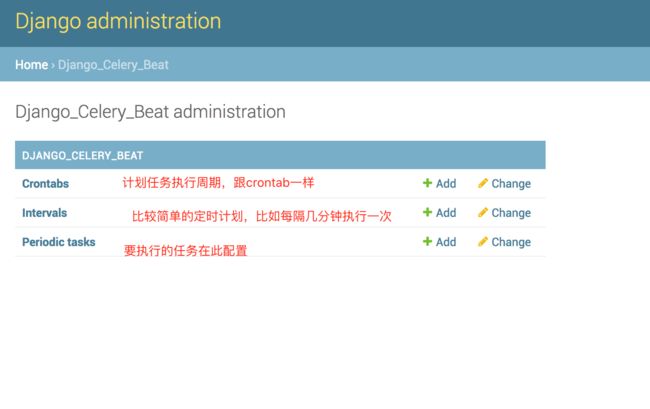
配置完长这样
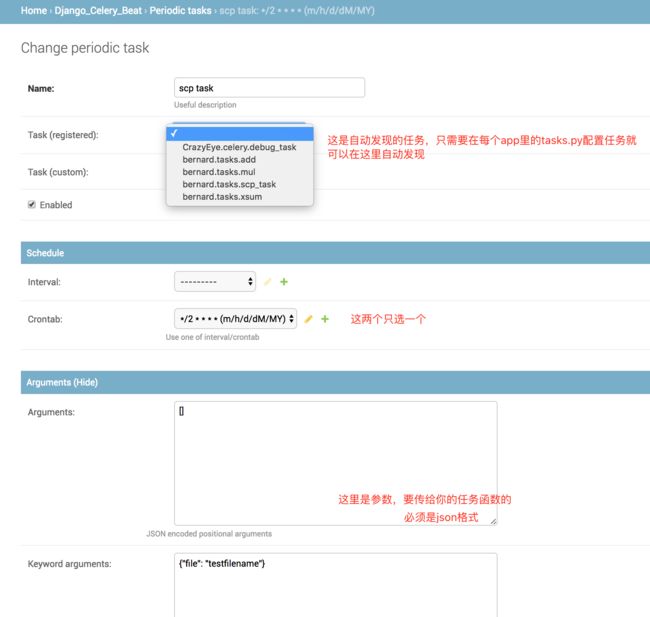
此时启动你的celery beat 和worker,会发现每隔2分钟,beat会发起一个任务消息让worker执行scp_task任务
注意:1.经测试,每添加或修改一个任务,celery beat都需要重启一次,要不然新的配置不会被celery beat进程读到
2.三、最佳实践之与Django的结合
celery中view和后端之间的请求过程:(开发核心流程)
传统模式:当前端发起请求有后台视图函数响应,直接返回结果,但是中间的响应时间不能把控
所以不建议使用
异步模式:当客户端发送请求时,后端会马上返回一个任务的id,在有前端发送【setinterval $getjson】
也就是定时器向后台服务器 task res api 发送请求。当然除了以上的内容可以采用 r