Scrapy + Selenium 爬取京东商品列表
爬取思路框架:
- 先创建一个scrapy项目
- 编写items文件
- 创建爬虫
- 修改middlewares
- 修改pipelines
- 配置settings
- 运行Scrapy
直接进入正题:
1、先创建一个scrapy项目
在系统命令行输入:
scrapy startproject jd- 项目创建成功后,会出现下图所示文件。
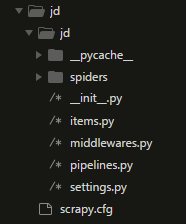
各个主要文件的作用:
scrapy.cfg :项目的配置文件
jd/ :项目的Python模块,将会从这里引用代码
jd/items.py :项目的目标文件
jd/pipelines.py :项目的管道文件
jd/settings.py :项目的设置文件
jd/spiders/ :存储爬虫代码目录
2、编写items文件
我们这里主要爬取商品列表里的商品名称、价格、店铺、评论条数、商品详情的url和商品的提供商是否为自营,代码如下:
import scrapy
class JdItem(scrapy.Item):
# define the fields for your item here like:
#名字
name = scrapy.Field()
#价格
price = scrapy.Field()
#店铺
store = scrapy.Field()
#评论条数
evaluate_num = scrapy.Field()
#商品url
detail_url = scrapy.Field()
#提供商
support = scrapy.Field()3、items文件写完之后,就要制作我们的爬虫啦,在系统命令行中当前目录下输入命令,将在jd/spider目录下创建一个名为jingdong的爬虫,并指定爬取域的范围,代码如下:
scrapy genspider jingdong "search.jd.com"- 打开 jd/spider目录里的 jingdong.py,要建立一个Spider, 你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性 和 一个方法。
name = “” :这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
allow_domains = [] 是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
start_urls = () :爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
parse(self, response) :解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:
负责解析返回的网页数据(response.body),提取结构化数据(生成item)
生成需要下一页的URL请求。
- 了解了各自的使用方法后,修改代码为以下:
# -*- coding: utf-8 -*-
import scrapy
from jd.items import JdItem
class JingdongSpider(scrapy.Spider):
name = "jingdong"
allowed_domains = ["search.jd.com"]
#这里我爬取的是手机,可根据要爬取的不同商品,修改关键词
base_url = 'https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&psort=4&click=0'
page = 1
start_urls = [base_url + '&page=' + str(page) + '&click=0']
def start_requests(self):
yield scrapy.Request(url = self.base_url,callback=self.parse,meta={'page':self.page},dont_filter=True)
def parse(self,response):
#商品列表,在网页源码上用xpath尽情解析吧,每个item都加上try,except使程序更加强壮
products = response.xpath('//ul[@class="gl-warp clearfix"]/li')
#列表迭代
for product in products:
item = JdItem()
try:
name = ''.join(product.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()').extract()).strip().replace(' ','')
except:
name = ''
try:
price = product.xpath('.//div[@class="p-price"]//i/text()').extract()[0]
except:
price = ''
try:
store = product.xpath('.//div[@class="p-shop"]//a/@title').extract()[0]
except:
store = ''
try:
evaluate_num = product.xpath('.//div[@class="p-commit"]/strong/a/text()').extract()[0]
except:
evaluate_num = ''
try:
detail_url = product.xpath('.//div[@class="p-name p-name-type-2"]/a/@href').extract()[0]
except:
detail_url = ''
try:
if product.xpath('.//div[@class="p-icons"]/i/text()').extract()[0]=='自营':
support = '自营'
else:
support = '非自营'
except:
support = '非自营'
item['name'] = name
item['price'] = price
item['store'] = store
item['evaluate_num'] = evaluate_num
item['detail_url'] = detail_url
item['support'] = support
#这里的yield将数据交给pipelines
yield item
print(item)
#这里的目的是配合middlewares中的slenium配合,这里每次都要打开相同的网页self.base_url,然后运用selenium操作浏览器,在最下方的页码中输入要查询的页数,我们这里查询1-100页
if self.page < 100:
self.page += 1
print(self.page)
#这里的meta使用来传递page参数,dont_filter表示不去重,因为scrapy默认会去重url,我们每次请求的网页都是重复的,所以这里不去重
yield scrapy.Request(url=self.base_url,callback=self.parse,meta={'page':self.page},dont_filter=True)
4、修改middlewares,把请求传送给middlewares的selenium,由selenium发送请求,并将Response传给jingdong.py的parse函数解析。代码如下:
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
#导入 webdriver
from selenium import webdriver
from selenium.webdriver.common.by import By
#WebDriverWait库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
#excepted_conditions类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
#
from scrapy.http import HtmlResponse
from scrapy.conf import settings
import random
import time
#随机使用user_agent,user_agents从settings中读取
class JdDownloadmiddlewareRandomUseragent(object):
def __init__(self):
self.useragents = settings['USER_AGENTS']
def process_request(self,request,spider):
useragent = random.choice(self.useragents)
print(useragent)
request.headers.setdefault('User-Agent',useragent)
#下载中间件,用selenium爬取,这里我用的是Firefox的Webdriver,另外还带了Chromdriver的使用代码
class JdSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
def __init__(self):
print('打开了火狐浏览器')
#firefox浏览器
firefox_profile = webdriver.FirefoxProfile()
fireFoxOptions = webdriver.FirefoxOptions()
#设置无图打开
firefox_profile.set_preference('permissions.default.image', 2)
#设置不加载Flash
firefox_profile.set_preference('dom.ipc.plugins.enabled.libflashplayer.so', 'False')
#设置悟透浏览器
fireFoxOptions.set_headless()
fireFoxOptions.add_argument('lang=zh_CN.UTF-8')
#timeout表示网页请求超时
self.browser = webdriver.Firefox(firefox_options=fireFoxOptions,firefox_profile=firefox_profile,timeout=20)
self.wait = WebDriverWait(self.browser,timeout=15)
'''
#Chrome浏览器
options = webdriver.ChromeOptions()
#设置中文
#options.add_argument('lang=zh_CN.UTF-8')
#设置无图加载 1 允许所有图片; 2 阻止所有图片; 3 阻止第三方服务器图片
prefs = {
'profile.default_content_setting_values':{
'images': 2
}
}
options.add_experimental_option('prefs',prefs)
#设置无头浏览器
options.add_argument('--headless')
self.browser = webdriver.Chrome(chrome_options=options)
#设置等待请求网页时间最大为self.timeout
self.wait = WebDriverWait(self.browser,self.timeout)
self.browser.set_page_load_time(self.timeout)
'''
def __del__(self):
print('关闭Firefox')
#爬虫结束后,关闭浏览器
self.browser.close()
def process_request(self,request,spider):
page = request.meta.get('page',1)
try:
print('Selenium启动解析')
self.browser.get(request.url)
#滚动条下拉到底
self.browser.execute_script("document.documentElement.scrollTop=10000")
#等待网页加载完毕
time.sleep(2)
#如果传过来的page不是第一页就需要在最下面的输入页码处,输入page,并按确定键跳转到指定页面
if page > 1:
input = self.wait.until(EC.presence_of_element_located((By.XPATH,'.//span[@class="p-skip"]/input'))) # 获取输入页面数框
submit = self.wait.until(EC.element_to_be_clickable((By.XPATH,'.//span[@class="p-skip"]/a'))) # 获取确定按钮
input.clear()
input.send_keys(page)
submit.click()
#滚动条下拉到底,第二种写法
self.browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(2)
# 如果当 str(page),即当前页码出现在高亮文本的时候,就代表页面成功跳转
self.wait.until(
EC.text_to_be_present_in_element((By.XPATH,'.//span[@class="p-num"]/a[@class="curr"]'),str(page)))
# 等待加载完所有的商品list 然后进一步解析
self.wait.until(EC.element_to_be_clickable((By.XPATH,'.//span[@class="p-skip"]/a')))
#self.wait.until(EC.presence_of_element_located((By.XPATH,'.//ul[@class="gl-warp clearfix"]/li')))
time.sleep(1)
body = self.browser.page_source
print('selenium开始访问第'+str(page)+'页')
#将selenium得到的网页数据返回给parse解析
return HtmlResponse(url=request.url,body=body,encoding='utf-8',request=request)
except Exception as E:
print(str(E))
return HtmlResponse(url =request.url,status=500,request=request)5、修改pipelines,jingdong.py中parse函数中的yield item的数据给到了pipelines,将数据存入到Mongodb数据库,代码如下:
# -*- coding: utf-8 -*-
import pymongo
class JdPipeline(object):
def __init__(self):
self.client = pymongo.MongoClient('localhost',27017)
scrapy_db = self.client['jd'] # 创建数据库
self.coll = scrapy_db['scrapyphone'] # 创建数据库中的表格
def process_item(self, item, spider):
self.coll.insert_one(dict(item))
return item
def close_spider(self, spider):
self.client.close()6、配置settings,为减少篇幅,只把修改的地方放了上来,其他的默认就可以
BOT_NAME = 'jd'
SPIDER_MODULES = ['jd.spiders']
NEWSPIDER_MODULE = 'jd.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'jd (+http://www.yourdomain.com)'
#USER_AGENTS列表
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.132 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0"
]
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
#下载延时,一般设置2.5左右,防止被封哦
DOWNLOAD_DELAY = 3
#禁止cookies
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
#设置下载中间件,把我们自己写的加进去,后面的数字越小,代表执行优先级越高
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':None,
'jd.middlewares.JdDownloadmiddlewareRandomUseragent':299,
'jd.middlewares.JdSpiderMiddleware': 300
}
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
#PIPELINES把我们自己写的存储类加上
ITEM_PIPELINES = {
'jd.pipelines.JdPipeline': 300,
}
7、运行程序
在系统命令行中的jd目录下,执行代码:
scrapy crawl jingdong代码就跑起来了,大功告成,100页,每页60个,共爬取6000条商品:
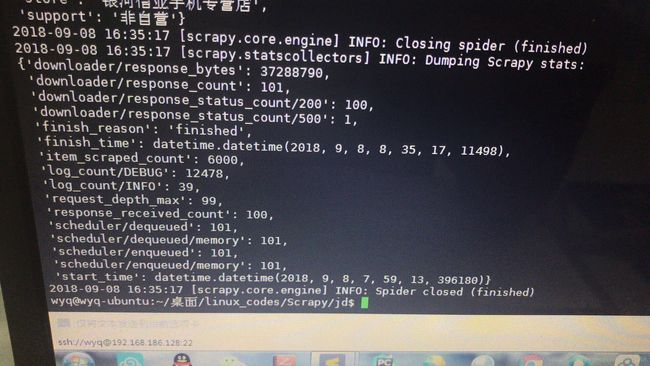
存入Mongodb数据库,查看如下图:
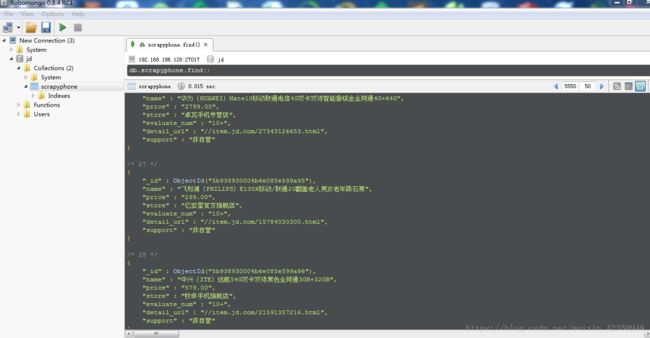
- 由于京东商品列表页为ajax请求,正常的请求只能拿到一半的数据,另一半数据需要下拉滚动条才会显示,因此我们用selenium模拟浏览器下拉操作访问网页,才能得到完整的数据。虽然用的selenium,但是爬取速度也还算可以,不知道您看完之后,是否学会了使用Scrapy + Selenium爬取网页呢,如果有不懂的地方,可以在下方留言,一起进步!
需要源码的可去Github下载,欢迎star和提出问题:
https://github.com/wangyeqiang/Craw
最后希望,早日学会Scrapy + Selenium。