利用python爬虫爬取LOL所有英雄的皮肤
利用python爬虫爬取LOL所有英雄的皮肤
ps:我们先理解爬虫的原理
它的流程分为4步:发送请求-->获取响应内容-->解析内容-->保存数据
首先,我们打开LOL官网,点击资料库通过F12找到hero_list这个json文件:
我们将json文件整理:

这样我们就找到了目标文件的ID,但此时我们发现在这之中并没有我们所需要的皮肤,我们点击安妮进入,使用![]() 定位到安妮的所有皮肤:
定位到安妮的所有皮肤:
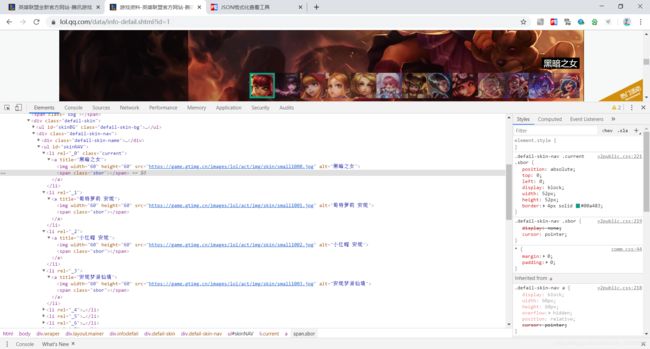
可以看出安妮皮肤的链接已经出现,由此我们就可以由英雄ID来爬取LOL所有英雄皮肤了
我们先导入工具库:
# 网页请求包 它可以模拟浏览器向网站发送一个请求[命令]
import requests
# 网页选择器
import jsonpath
# 文件操作
import os
# 多线程处理
from urllib.request import urlretrieve
编写获取ID方法:
def get_id():
req = requests.get("https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js").json()
banAudios = jsonpath.jsonpath(req, '$..banAudio')
print(banAudios)
items = []
for banAudios in banAudios:
id = banAudios.split("ban/")[1][0:-4]
items.append(id)
return items
获取皮肤方法:
def get_skin(items):
for item in items:
url = "https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js".format(item)
req = requests.get(url, headers=headers).json()
skins = req["skins"]
names = jsonpath.jsonpath(skins, '$..name')
mainImgs = jsonpath.jsonpath(req, '$..mainImg')
try:
if not os.path.exists(names[0]):
os.mkdir(names[0])
for name, mainImgs in zip(names, mainImgs):
urlretrieve(mainImgs, names[0] + "/" + name + ".jpg")
print(name + " 100%")
except:
pass
main函数:
def go():
# 此处写保存皮肤的文件夹
os.chdir("D:\A_spider_folder\lolPF")
items = get_id()
get_skin(items)
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/78.0.3904.108 Safari/537.36"} # 访问权限
go()
代码编写完成,我们run一下:
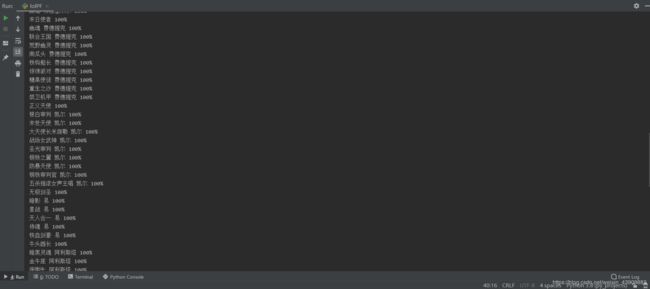

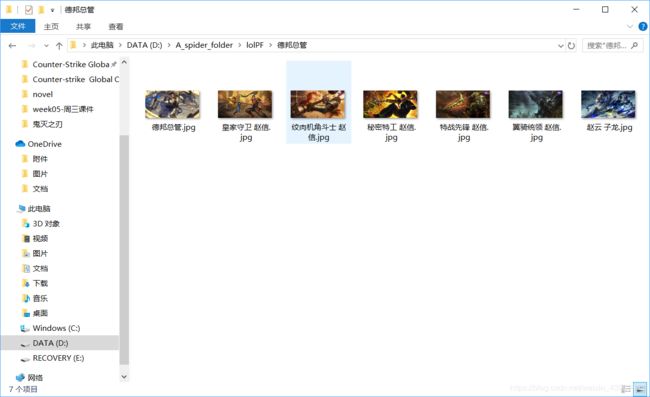
由于英雄过多,所以我暂停了一下,我们可以看到所有LOL皮肤已经被我们爬取下来了。
代码中的许多方法需要大家自己理解,多写几遍,自然就熟练了,爬虫难点在于寻找网页中的信息,爬取即是一个固定过程。
ps:附源码
# -*- coding: utf-8 -*-
# @File : lolPF.py
# @Author: wangfanfan
import requests
import jsonpath
import os
from urllib.request import urlretrieve
def get_id():
req = requests.get("https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js").json()
banAudios = jsonpath.jsonpath(req, '$..banAudio')
print(banAudios)
items = []
for banAudios in banAudios:
id = banAudios.split("ban/")[1][0:-4]
items.append(id)
return items
def get_skin(items):
for item in items:
url = "https://game.gtimg.cn/images/lol/act/img/js/hero/{}.js".format(item)
req = requests.get(url, headers=headers).json()
skins = req["skins"]
names = jsonpath.jsonpath(skins, '$..name')
mainImgs = jsonpath.jsonpath(req, '$..mainImg')
try:
if not os.path.exists(names[0]):
os.mkdir(names[0])
for name, mainImgs in zip(names, mainImgs):
urlretrieve(mainImgs, names[0] + "/" + name + ".jpg")
print(name + " 100%")
except:
pass
def go():
os.chdir("D:\A_spider_folder\lolPF")
items = get_id()
get_skin(items)
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/78.0.3904.108 Safari/537.36"}
go()