利用爬虫爬出17173.com的lol英雄数据
自己本身很喜欢影响联盟这款游戏,虽然自己不经常打。最近做了一个小小的爬虫,爬取了一下英雄的数据信息。感觉蛮有意思的。其中包含英雄的名字、性别、攻击方式、被动技能、价格、背景故事。如果你喜欢的话,可以给我留言,我尽量会帮你查找你想要的数据。
17173地址:http://cha.17173.com/lol/
XiaoTommy的github地址:https://github.com/XiaoTommy/phpspider
爬虫框架:https://github.com/owner888/phpspider
爬虫QQ群:PHP爬虫研究中心 147824717
爬虫源代码
'lol_hero',
'log_show' => true,
'tasknum' => 1,
//'save_running_state' => true,
'domains' => array(
'cha.17173.com'
),
'scan_urls' => array(
'http://cha.17173.com/lol/'
),
'content_url_regexes' => array(
"http://cha.17173.com/lol/heros/details/(\d+).html",
),
'max_try' => 5,
//'export' => array(
//'type' => 'csv',
//'file' => PATH_DATA.'/qiushibaike.csv',
//),
//'export' => array(
//'type' => 'sql',
//'file' => PATH_DATA.'/qiushibaike.sql',
//'table' => 'content',
//),
'export' => array(
'type' => 'db',
'table' => 'lolhero',
),
'fields' => array(
array(
'name' => "hero_name",
'selector' => "//div[contains(@class,'hero_bg')]/div[contains(@class,'hero')]//div[contains(@class,'hero_parameter_tit')]/h1",
'required' => true,
),
array(
'name' => "hero_story",
'selector' => "//div[contains(@class,'hero_bg')]//div[contains(@class,'s_tit3 text_overflow')]/div[contains(@class,'xx_sq')]",
'required' => true,
),
array(
'name' => "sex",
'selector' => "//div[contains(@class,'hero_bg')]//div[contains(@class,'hero_parameter')]//ul[contains(@class,'info_li')]/li[5]/span",
'required' => true,
),
array(
'name' => "hero_price",
'selector' => "//div[contains(@class,'hero_bg')]//div[contains(@class,'parameter_info')]//strong[contains(@class,'m2')]",
'required' => true,
),
array(
'name' => "mode",
'selector' => "//div[contains(@class,'hero_bg')]//div[contains(@class,'hero_parameter')]//ul[contains(@class,'info_li')]/li[4]/span",
'required' => true,
),
array(
'name' => "pass_skill",
'selector' => "//div[contains(@class,'hero_bg')]//ul[contains(@class,'content_li')]/li[1]/ul/li/h6",
'required' => true,
),
// array(
// 'name' => "url",
// 'selector' => "/html/body/div[5]/div[1]/div[1]/div[2]/ul[2]/li[6]/span", // 这里随便设置,on_extract_field回调里面会替换
// 'required' => true,
// ),
),
);
$spider = new phpspider($configs);
$spider->on_extract_field = function($fieldname, $data, $page)
{
if ($fieldname == 'hero_name')
{
if (strlen($data) > 10)
{
// 下面方法截取中文会有异常
//$data = substr($data, 0, 10)."...";
$data = mb_substr($data, 0, 10, 'UTF-8')."...";
}
}
elseif ($fieldname == 'time')
{
// 用当前采集时间戳作为发布时间
$data = time();
}
// 把当前内容页URL替换上面的field
elseif ($fieldname == 'url')
{
$data = $page['url'];
}
return $data;
};
$spider->start();
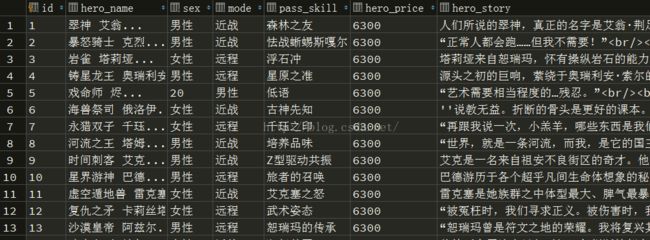
mysql效果图: