Spark Streaming
资料:
Spark精品教程
Spark Streaming通过JDBC操作数据库
Spark Streaming的基本原理
以时间为单位( 通 常 在 0.5 到 2 秒 之 间 \color{red}通常在0.5到2秒之间 通常在0.5到2秒之间)切分为微型RDD,然后进行微批处理。
spark streaming $\color{red}无法实现毫秒级别 $的响应,因为他的微批处理的特性,使得它每一段数据的处理都会经历Spark DAG,任务调度等过程,需要一定的开销。因此可以认为spark streaming实现的是准实时计算。
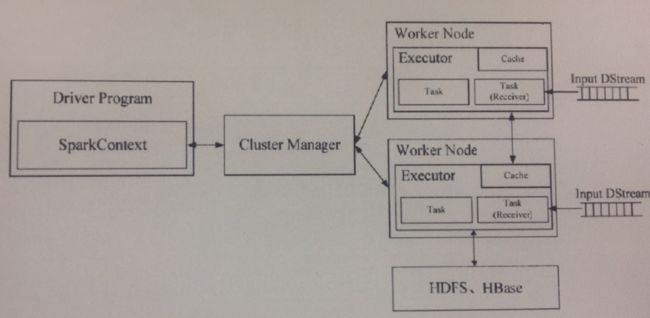
Spark Streaming工作机制
Spark streaming任务中会有一个组件(Receiver)作为一个task一直运行在一个Executor上,每个receiver实例负责一个流的读取,和提交给streaming task 程序处理。
Spark Streaming 可以接收从Socket、文件系统、Kafka、Flume等数据源产生的数据。
Spark Streaming 编程模型
- 创建DStream (Discretized Stream),定义数据源,Receiver组件在收到数据后会提交给用户自定义的Spark Streaming处理逻辑Task处理。
- 对DStream进行Transformation操作,从而实现用户自定义逻辑。
- 调用StreamingContext对象的 start() 方法启动程序。
- 调用StreamingContext对象的awaitTermination() 方法来等待进程结束,或者调用stop() 方法来手动结束进程。
StreamingContext创建代码
import org.apache.spark._
import org.apache.spark.streaming._
val sparkConf = new SparkConf().setAppName("Test").setMaster("local[2]")
// 设定处理时间段的长度为1秒
val sc = new StreamingContext(sparkConf, Seconds(1))
文件流,可用于本地测试时使用
val lines=sc.textFileStream("file:///d:/Test/text")
注意这里是按文件的生成日期来判断是否是最新文件,以及是否读取的。其中最新的标准以文件夹中最新的一个文件日期为准。所以启动之后,文件夹内的已经存在的文件并不会读取,直到有新创建的文件生成才会读取。
Kafka数据流
kafka基本概念回归:
-
Broker:kafka集群包含多个服务器节点,这些节点称为Broker。
-
Topic:一类业务数据的集合会发送到Kafka的一个Topic,订阅这个Topic的数据就可以对这一类业务数据进行处理。物理上,不同的Topic的消息是分开存储的,逻辑上,一个Topic的数据是可以按Partition有序读取的,也就是说,存储在同一个Partition上的消息是可以顺序读取的,但是无法做到全局有序。
-
Partition:每个Topic包含一个或者多个Partition,每个Partition可能存储在不同的Broker上。
-
Producer:负责向Kafka Broker写数据。
-
Consumer:读取Kafka Broker中消息的客户端。
-
Consumer Group:一个Consumer归属于一个Consumer Group,Consumer Group只顺序读取消息至少一次,并由组内的不同的Consumer进行处理。
Read Kafka in Spark Streaming Pom引入
对DStream的转换
和RDD一样,使用转换可以修改从输入DStream获取的数据。DStreams支持许多用在一般Spark RDD上的转换。其中一些常用的如下:
map(func):将源DStream中的每个元素通过一个函数func从而得到新的DStreams。
flatMap(func):和map类似,但是每个输入的项可以被映射为0或更多项。
filter(func):选择源DStream中函数func判为true的记录作为新DStreams
repartition(numPartitions):通过创建更多或者更少的partition来改变此DStream的并行级别。
union(otherStream):联合源DStreams和其他DStreams来得到新DStream
count:统计源DStreams中每个RDD所含元素的个数得到单元素RDD的新DStreams。
reduce(func):通过函数func(两个参数一个输出)来整合源DStreams中每个RDD元素得到单元素RDD的DStreams。这个函数需要关联从而可以被并行计算。
countByValue:对于DStreams中元素类型为K调用此函数,得到包含(K,Long)对的新DStream,其中Long值表明相应的K在源DStream中每个RDD出现的频率。
reduceByKey(func, [numTasks]):对(K,V)对的DStream调用此函数,返回同样(K,V)对的新DStream,但是新DStream中的对应V为使用reduce函数整合而来。Note:默认情况下,这个操作使用Spark默认数量的并行任务(本地模式为2,集群模式中的数量取决于配置参数spark.default.parallelism)。你也可以传入可选的参数numTaska来设置不同数量的任务。
join(otherStream,[numTasks]):两DStream分别为(K,V)和(K,W)对,返回(K,(V,W))对的新DStream。
cogroup(otherStream,[numTasks]):两DStream分别为(K,V)和(K,W)对,返回(K,(Seq[V],Seq[W])对新DStreams
transform(func):将RDD到RDD映射的函数func作用于源DStream中每个RDD上得到新DStream。这个可用于在DStream的RDD上做任意操作。
updateStateByKey(func):得到”状态”DStream,其中每个key状态的更新是通过将给定函数用于此key的上一个状态和新值而得到。这个可用于保存每个key值的任意状态数据。
这其中的一些转换操作值得详细讨论。