半监督学习概述
半监督学习(Semi-Supervised Learning,SSL)类属于机器学习(Machine Learning,ML)。
一 ML有两种基本类型的学习任务:
1.监督学习(Supervised Learning,SL)
根据输入-输出样本对L={(x1,y1),···,(xl,yl)}学习输入到输出的映射f:X->Y,来预测测试样例的输出值。SL包括分类(Classification)和回归(Regression)两类任务,分类中的样例xi∈Rm(输入空间),类标签yi∈{c1,c2,···,cc},cj∈N;回归中的输入xi∈Rm,输出yi∈R(输出空间)。
2. 无监督学习(Unsupervised Learning,UL)
利用无类标签的样例U={x1,···,xn}所包含的信息学习其对应的类标签Yu=[y1···yn]T,由学习到的类标签信息把样例划分到不同的簇(Clustering)或找到高维输入数据的低维结构。UL包括聚类(Clistering)和降维(Dimensionality Reduction)两类任务。
二 半监督学习(Semi-Supervised Learning,UL)
在许多ML的实际应用中,很容易找到海量的无类标签的样例,但需要使用特殊设备或经过昂贵且用时非常长的实验过程进行人工标记才能得到有类标签的样本,由此产生了极少量的有类标签的样本和过剩的无类标签的样例。因此,人们尝试将大量的无类标签的样例加入到有限的有类标签的样本中一起训练来进行学习,期望能对学习性能起到改进的作用,由此产生了SSL,如如图1所示。SSL避免了数据和资源的浪费,同时解决了SL的 模型泛化能力不强和UL的模型不精确等问题。
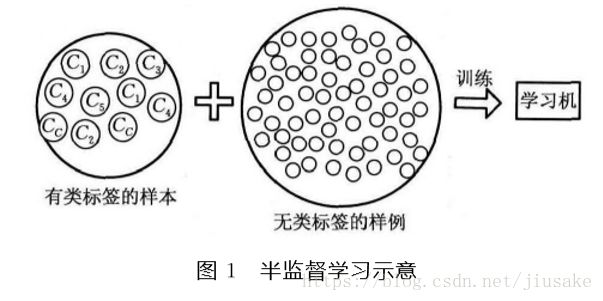
1.半监督学习依赖的假设
SSL的成立依赖于模型假设,当模型假设正确时,无类标签的样例能够帮助改进学习性能。SSL依赖的假设有以下3个:
(1)平滑假设(Smoothness Assumption)
位于稠密数据区域的两个距离很近的样例的类标签相似,也就是说,当两个样例被稠密数据区域中的边连接时,它们在很大的概率下有相同的类标签;相反地,当两个样例被稀疏数据区域分开时,它们的类标签趋于不同.
(2)聚类假设(Cluster Assumption)
当两个样例位于同一聚类簇时,它们在很大的概率下有相同的类标签.这个假设的等价定义为低密度分离假设(Low Sensity Separation Assumption),即分类 决策边界应该穿过稀疏数据区域,而避免将稠密数 据区域的样例分到决策边界两侧.
(3)流形假设(Manifold Assumption)
将高维数据嵌入到低维流形中,当两个样例位于低维流形中的一个小局部邻域内时,它们具有相似的类标签。许多实验研究表明当SSL不满足这些假设或模型假设不正确时,无类标签的样例不仅不能对学习性能起到改进作用,反而会恶化学习性能,导致 SSL的性能下降.但是还有一些实验表明,在一些特殊的情况下即使模型假设正确,无类标签的样例也有可能损害学习性能。
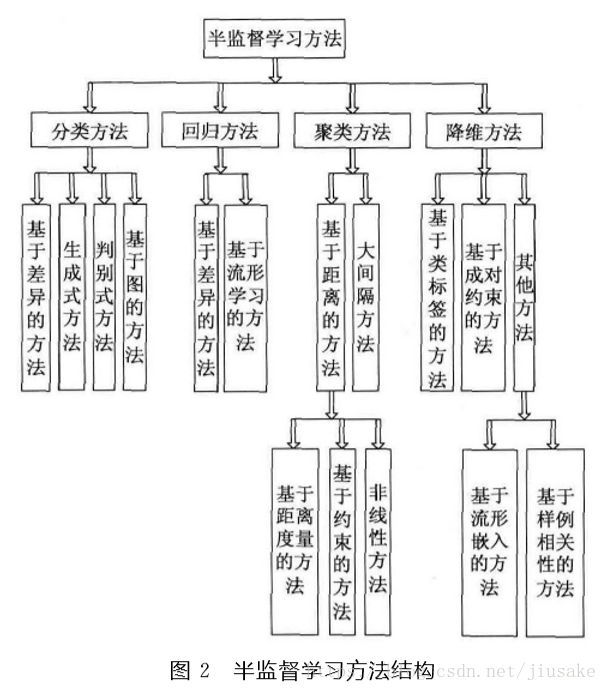
2.半监督学习的分类
SSL按照统计学习理论的角度包括直推 (Transductive )SSL和归纳(Inductive)SSL两类模式。直推 SSL只处理样本空间内给定的训练数据,利用训练数据中有类标签的样本和无类标签的样例进行训练,预测训练数据中无类标签的样例的类标签;归纳SSL处理整个样本空间中所有给定和未知的样例,同时利用训练数据中有类标签的样本和无类标签的样例,以及未知的测试样例一起进行训练,不仅预测训练数据中无类标签的样例的类标签,更主要的是预测未知的测试样例的类标签。从不同的学习场景看,SSL可分为4大类:
(1)半监督分类 (Semi-Supervised Classification)
在无类标签的样例的帮助下训练有类标 签的样本,获得比只用有类标签的样本训练得到的分类器性能更优的分类器,弥补有类标签的样本不足的缺陷,其中类标签yi取有限离散值yi∈{c1,c2,···,cc},cj∈N。
(2)半监督回归(Semi-Supervised Regression)
在无输出的输入的帮助下训练有输出的输入,获得比只用有输出的输入训练得到的回归器性能更好的回归器,其中输出yi 取连续值 yi∈R。
(3)半监督聚类(Semi-Supervised Clustering)
在有类标签的样本的信息帮助下获得比只用无类标 签的样例得到的结果更好的簇,提高聚类方法的精度。
(4)半监督降维(Semi-Supervised Dimensionality Reduction)
在有类标签的样本的信息帮助下找到高维输入数据的低维结构,同时保持原始高维数据和成对约束(Pair-Wise Constraints)的结构不变,即在高维空间中满足正约束(Must-Link Constraints)的样例在低维空间中相距很近,在高维空间中满足负约束(Cannot-Link Constraints)的样例在低维空间中距离很远。
1.2 为什么使用半监督学习
(1) 实际中缺乏的不是数据,而是带标签的数据。给收集的数据进行标记是昂贵的。
(2) 在我们的一生中都在进行半监督学习。
1.3 为半监督学习是有帮助的
虽然没有标签的数据并不会提供标签,但是它提供了关于数据分布的一种信息。即没有标签的数据的分布会给我们提供一些信息,但是所给出的信息通常实在一些假定的条件下实现的。也就是说假设决定了半监督学习是否可以使用!
1.4 本文的主要内容
本文的主要内容是四个部分:生成模型中的半监督学习、低密度分离假设、平滑性假设、更好的表示。本文将介绍前三节内容,最后一部分内容将在之后的博客中介绍。

2. 生成模型中的半监督学习(Semi-supervised Learning for Generative Model)
在监督学习中,生成模型的数据有 C1C1 和 C2C2 两类数据组成,我们统计数据的先验概率 P(C1)P(C1) 和 P(x|C1)P(x|C1) 。假设每一类的数据都是服从高斯分布的话,我们可以通过分布得到参数均值μ1,μ2μ1,μ2和方差ΣΣ。
利用得到参数可以知道P(C1),P(x|C1),μ1,μ2,ΣP(C1),P(x|C1),μ1,μ2,Σ,并利用这些参数计算某一个例子的类别
在非监督学习中,如下图所示,在已知类别的数据周围还有很多类别未知的数据,如图中绿色的数据。
这个时候如果仍在使用之前的数据分布明显是不合理的们需要重新估计数据分布的参数,这个时候可能分布式一个类似于圆形的形状。这里就需要用为标签数据来帮助估计新的”P(C1),P(x|C1),μ1,μ2,ΣP(C1),P(x|C1),μ1,μ2,Σ”。具体可以采用如下的EM算法进行估计
首先对参数进行初始化,之后利用参数计算无标签数据的后验概率;然后利用得到的后验概率更新模型参数,再返回step1,循环执行直至模型收敛。这个算法最终会达到收敛,但是初始化对于结果的影响也很大。
3. 低密度分离(Low-density Separation)
低密度分离假设就是假设数据非黑即白,在两个类别的数据之间存在着较为明显的鸿沟,即在两个类别之间的边界处数据的密度很低(即数据量很好)。
3.1 自训练(Self-training)
自训练的方法十分直觉,它首先根据有标签的数据训练出一个模型,将没有标签的数据作为测试数据输进去,得到没有标签的数据的一个为标签,之后将一部分的带有伪标签的数据转移到有标签的数据中,在进行训练,循环往复。其中选取哪一部分的伪标签数据转移至有标签数据需要自己定义,甚至可以自己提供一个权重。具体的过程如下图所示
在这里还有两个问题需要注意,首先自训练的方法是否可以用到回归问题中?答案是否定的。因为即使加入新的数据对于模型也没有什么改进。
之前讲的生成模型与后来讲的自训练模型之间是很相似的,区别在于生成模型采用的是软标签,而自训练采用的是硬标签,那么问题来了,自训练模型是都可以使用软标签呢?答案是否定的,如下图所示
因为不对标签进行改变的话,将这些放入带标签的数据中对于数据的输出一点改进都没有,输出的还是原来的数据。
3.2 基于熵的正则化
这种方法是自训练的进阶版,因为之前如果直接根据用有标签数据训练出来的模型直接对无标签数据进行分类会有一些武断,这里采用一种更严密的方法。
因为在低密度假设中认为这个世界是非黑即白的,所以无标签数据的概率分布应该是区别度很大的,这里使用熵来表示。将其加入损失函数中个可以看到,这个实际上可以认为是一项正则化项,所以也叫基于熵的正则化。训练的话,因为两个部分都是可微分的,所以直接使用梯度下降就可以进行训练。
4. 平滑性假设
白话性假设:如果输入 xx 是相似的,那么它们的标签值 y^y^ 同样应该是相似的。但是这样的假设不够精确,所以有下面的严格的假设:
(1) xx 的分布是不均匀的,在有的地方是稀疏的,在有的地方是密集的
(2) 如果在高密度区域比较相近,那么这两个数据具有相同的标签。
可以如下图进行进一步解释
在距离上虽然 x2x2 与 x3x3 的距离更接近,但是 x2x2 与 x1x1 位于同一个高密度的区域中。可以认为同一个高密度区域之间的数据可以很好的接触连接,具有相同的标签值,而不同的高密度区域无法相互接触,所以标签值不相同。
4.1 先聚类再标注
一种直观的方法是首先对数据进行聚类,看没有标签的数据落在哪一个部分,然后对其及进行标注,如下图所示

但是如果是对图像进行操作的话,无法单纯用像素对图像进行聚类,这样的聚类方法往往是不好的,这个时候可以采用 deep autoencoder 的方法提取图像的特征,利用特征对图像进行聚类,会得到较好的结果。
4.2 基于图的方法
将所有的数据点建成一个图,如果在图上两个点之间可以连通,那么他们之间标签就是相同的。那么如何形成图呢,有些图是天然的,比如说网页之间的连接,或者论文之间的相互引用,但有的时候需要自己建图。
参考
[1]Machine Learning (2016,Fall)-National Taiwan University (NTU)