文本摘要生成--用过的方法及原理思考
起初,由于工作需要,需要对大量技术文章进行分类并用一两句话描述关键内容,做成类似简报之类的报告给领导看,但是材料又多又长,不可能一篇篇去读,怎么办呢?
最先想到的办法,就是抽取关键词,简单易行,就是后期需要自己梳理成句,当然还是需要浏览一遍文章,不过至少有的放矢了
1、第一版:获取TFIDF最高的n个词汇,作为关键词提取;
from sklearn.feature_extraction.text import CountVectorizer,TfidfTransformer
countVectorizer =CountVectorizer(stop_words=None,token_pattern=r'(?u)\b\w\w+\b',max_df=1.0,min_df=1)
text_seq_count = countVectorizer.fit_transform(text_seq)
tfidftransformer = TfidfTransformer()
text_seq_tfidf = tfidftransformer.fit_transform(text_seq_count)Tfidf公式=该词在某文档中出现的频率(即次数除以总词数)**log[1/(含有该词的文档在所有文件中出现的频率(即(含词文档数+1)除以总文档数))]
注:
1)除以总词数是为了排除文档长度对一个词出现次数的影响
2)+1是为了防止产生为0的除数;
3)取log是因为从信息论的角度分析:一个词对某个文档的贡献度,不仅与该词在该文档中出现的次数(词袋模型)有关,同时与该词所含有的信息量有关,而根据信息论,某事件信息量可以近似为其概率的负对数,那么一个词本身含有的信息量可以近似为该词的出现概率取负对数,即-log(含有这个词的文档数目与总文档数目的比值);因而,一个词在某文档中次数越多,信息量越大,那么贡献度就越大,即(word_count/text_word_num)-log(word_text_num/text_num)
4) 为什么一个词出现概率不用所有文件中该词出现次数/总文件词数呢?我想原因同样与1)类似,为了排除不同长度的文档对一个词出现次数的影响,因为首先文档的重要性并不能由其长度确定,而如果简单通过词数相加的总文件次数做分母,无形中长度长的文档所占比重更大,其次一个词在某个文档中的出现次数已经由TF表达了,如果次数再用该词在总文件中出现的次数进行计算,那么就部分与之重复,相当于扩大了这部分的作用,所以只需要用文档的频率进行信息量的计算。
2、后来工作增多,实在没有时间篇篇浏览,但是又不能随意就用几个关键词直接造句,怎么办呢?
第二版:获取这些词汇出现的句子进行整合作为摘要雏形
,句子筛选的原则就是:一句话里关键词出现的越多,这句话就越关键;一句话里关键词tfidf值之和越大,这句话就越关键。用这两个原则分别筛选前N条句子,然后根据这些句子进行摘要编写
3、之后接触到nlp,学习了文本摘要相关的算法,目前已经尝试过的有:1)textrank算法进行摘要抽取;2)用神经网络LSTM构建encoder-decoder的seq2seq+attention模型
1)第三版:textrank,摘要抽取
这个抽取效果不错,但作为简报给领导看还是不行
总体思想:采用词向量计算句子向量,进而计算句子相似度,采用pagerank算法获取与其他句子连接度最大,相似度最大的句子作为摘要;
词向量:
from gensim.models import word2vec
all_text = list(washed_text)
word_dim = 300 # Word vector dimensionality
min_word_count = 0 # Minimum word count
num_workers = 16 # Number of threads to run in parallel
context =2 # Context window size
downsampling = 1e-3 # Downsample setting for frequent words
model_sg_hs = word2vec.Word2Vec(all_text,size=word_dim,window=context,min_count=min_word_count,workers=num_workers,sg= 1,hs=1,sample= downsampling)
#Sg=1-----skip-gram(w--context); 0-----cbow (context--w)
#Hs=1-----层级softmax(构建霍夫曼树);0------Negative Sampling计算句子向量:
sentences_vectors = [sum(np.array(word2vec_model[word],dtype='float32').reshape(100,-1) for word in sentence) if len(sentence) !=0
else np.zeros((100,))/len(sentence.split(' ')+0.001) for sentence in clean_sentences]计算余弦相似度,生成相似度邻接矩阵作为状态转移矩阵
from sklearn.metrics.pairwise import cosine_similarity
similarity_matrix = np.zeros((len(clean_sentences),len(clean_sentences)))
for i in range(len(clean_sentences)):
for j in range(len(clean_sentences)):
if i != j:
#sklearn 的cosine_similarity的输入是二维array,因此需要把sentence_vector,即一维的array,reshape为二维
similarity_matrix[i][j] = cosine_similarity(sentences_vectors[i].reshape(1,100),sentences_vectors[j].reshape(1,100))[0,0]
print(similarity_matrix)根据状态转移矩阵生成网络图,利用网络图的pagerank算法计算句子排名
import networkx as nx
import matplotlib.pyplot as plt
sentences_graph = nx.from_numpy_array(similarity_matrix)
nx.draw(sentences_graph)
#plt.show()
score = nx.pagerank(sentences_graph,max_iter=100)Networkx.pagerank是以图结构为基础通过迭代收敛方法计算PR值(PageRank值)
Pagerank的算法逻辑:
每个节点都有随机概率α去连接其出度节点,并为其出度节点的贡献自己pagerank值的出度数分之一;
如果出度节点数为0,则为所有节点贡献自己PageRank值的所有节点数分之一
每个节点都有(1-α)的概率去连接自己,因此每个节点都会收获自己给自己的总结点数分之一的(1-α)值
所以对于任一有向图,A节点的pagerank值等于:A节点对应的i个(入度节点X的(pagerank值/X出度数)*概率α)之和,再加上j个0出度的节点的[(pagerank值/(总结点数-1))*概率α]之和,再加上概率(1-α)/总结点数
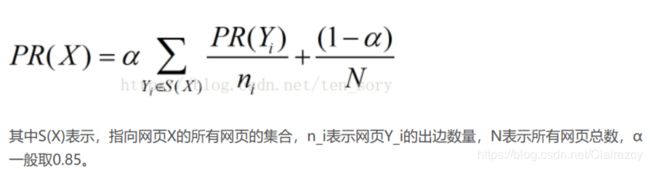
2)第四版:摘要生成
总体思想:采用分词,生成词向量,形成text向量与summary向量,分别构建text输入张量和summary输出张量,采用三层LSTM的encoder-一层LSTM的decoder-一层Attention-全连接Dense softmax架构搭建模型,学习什么样的文章词汇对应什么样的摘要词汇,以及对应在什么位置等规律,再利用模型进行摘要生成(即分为训练阶段和推理阶段)
用keras构建神经网络模型时,由于有embedding层,可以将输入直接生成词向量,因而可以不用word2vec,可以直接将词语进行tokenizer.text_to_sequence转化为数字序列,然后按照选定的最大长度进行添0 pad_sequences,作为原始词向量输入;如果想用word2vecor生成的词向量,我认为有两种方式,一是先将输入用tokenizer.text_to_matrix转化为one-hot-matrix,然后将word2vec矩阵作为embedding layer的weight参数,在embedding时直接转化为word2vec词向量,然后可以trainable选择false不再更新或者True继续更新;二是直接用word2vec表示每个词向量,然后直接输入LSTM
用神经网络LSTM建立encoder-decoder(seq2seq)模型
Encoder(Input层-Embedding层-3层LSTM)---->decoder(Input层-Embedding层-1层LSTM)----Attention层---->concatenate层----->TimeDistributed(Dense())层:
from tensorflow.python.keras.layers import Input,LSTM,Embedding,Concatenate,TimeDistributed,Dense
from tensorflow.python.keras import backend as K#Encoder
encoder_inputs = Input(shape=(text_length,))
#Embedding layer
encoder_embedding = Embedding(x_vocabulary,embedding_dim,trainable=True)(encoder_inputs)
#encoder LSTM 1
encoder_lstm1 = LSTM(latent_dim,return_sequences=True,return_state=True,dropout=0.4,recurrent_dropout=0.4)
encoder_lstm1_output, encoder_lstm1_state_h, encoder_lstm1_state_c = encoder_lstm1(encoder_embedding)
#encoder LSTM 2
encoder_lstm2 = LSTM(latent_dim,return_sequences=True,return_state=True,dropout=0.4,recurrent_dropout=0.4)
encoder_lstm2_output, encoder_lstm2_state_h, encoder_lstm2_state_c = encoder_lstm2(encoder_lstm1_output)
#encoder LSTM 3
encoder_lstm3 = LSTM(latent_dim,return_sequences=True,return_state=True,dropout=0.4,recurrent_dropout=0.4)
encoder_lstm3_output, encoder_lstm3_state_h, encoder_lstm3_state_c = encoder_lstm3(encoder_lstm2_output)
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = Input(shape=(None,))
#embedding layer
decoder_embedding = Embedding(y_vocabulary,embedding_dim,trainable=True)(decoder_inputs)
#decoder LSTM
decoder_lstm = LSTM(latent_dim,return_sequences=True,return_state=True,dropout=0.4,recurrent_dropout=0.2)
decoder_lstm_output, decoder_lstm_state_h, decoder_lstm_state_c = decoder_lstm(decoder_embedding,initial_state=[encoder_lstm3_state_h,encoder_lstm3_state_c])注1:LSTMs的输入必须是三维的(三维的结构是[样本批大小,滑窗大小,特征数量])
对于普通RNN:
隐藏层t时刻输出H(t) = 权重参数激活函数F(权重参数输入X(t)+权重参数*上一层隐藏层输出H(t-1)+偏置项参数)+偏置项参数
对于LSTM:
隐藏层多了几个同时发生的过程,同时多了一个输出即细胞状态C:
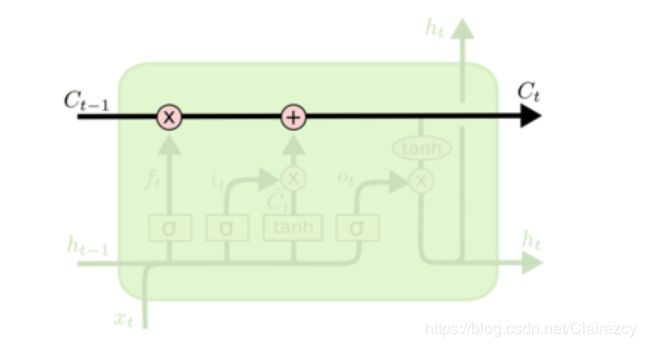 三个sigmoid函数就是三个门,控制对应的输入是否或者按照多少比例进入细胞状态值中
三个sigmoid函数就是三个门,控制对应的输入是否或者按照多少比例进入细胞状态值中
1)第一个sigmoid函数为遗忘门:控制C(t-1)中有多少比例进入到C(t)中,比例计算用σ(h(t-1),X(t)),遗忘门输出值为C(t-1)*σ(h(t-1),X(t))
2)第二个sigmoid函数为输入门:本时刻激活的h(t-1)和X(t)有多少比例进入到C(t)中,
比例计算依旧同上,输入门的值为tanh(h(t-1),X(t))*σ(h(t-1),X(t))
上两个门结果相加即得到本次细胞状态更新值:
上一细胞状态保留部分+本次隐藏层输出保留部分C(t) = C(t-1)*σ(h(t-1),X(t))+tanh(h(t-1),X(t))*σ(h(t-1),X(t))
3)第三个sigmoid函数为输出门:将本时刻细胞状态再进行激活后以同一比例进行输出,
作为本时刻的输出值,同时输出到下一时刻Output(t) or h(t) = tanh(C(t))*σ(h(t-1),X(t))
注2:LSTM的参数return_sequences和return_states对返回值的影响:这两个参数主要影响细胞状态C以及细胞输出的返回值
1)return_sequences主要影响细胞输出即output
当return_sequences=True时,output输出该步长/滑窗各个对应时刻的output值,即输出output(t-n)…output(t)
= False时,output只输出该步长下最后一个时刻的output值,即仅输出output(t)
2)return_states 主要影响细胞状态,即该时刻向下一时刻传递的值,包括C和h【当然,h其实等于output】
当return_states = True时,输出该步长各个对应时刻的所有细胞状态C和h,即C为C(t-n)…C(n);h为h(t-n)…h(t)
= False时,只输出该步长最后一个时刻的细胞状态C(t)和h(t)
3)当使用多层LSTM时,return_sequences只能选择True,这样输出(即下一时刻的LSTM输入)才能保证为统一步长,即三维的结构[样本批大小,滑窗大小,特征数量]的滑窗大小保持一致
注3:LSTM这种编码器-解码器方法的计算逻辑是通过神经网络将源句子的所有必要信息压缩成固定长度的向量。但对于长句来说,LSTM神经网络难以准确完整保留全部必要信息。
随着输入句子长度的增加,基本的编码器-解码器计算性能开销急剧增加,并且信息量的压缩使得准确性降低。
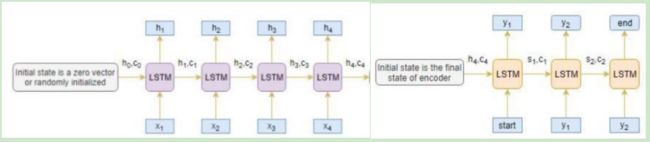
如何解决这个问题呢?这就是注意力机制被引入的地方。
注意力机制旨在通过将注意力按计算得到的权重分配到不同的位置,从而将位置信息直接利用起来,并通过位置权重有针对性的获取对应信息,从而更好的预测下一句话中各个位置的词汇。
注意力又分为全局和局部注意力:
全局注意力:注意力集中在所有源位置上。换句话说,编码器的所有隐藏状态都被考虑用于导出参与的上下文向量
局部注意力:只关注几个源位置。仅考虑编码器的几个隐藏状态来导出参与的上下文向量
全局注意力的引入:
# Attention layer
attention_layer = AttentionLayer(name='Attention_Layer')
attention_outputs,attention_states = attention_layer([encoder_lstm3_output,decoder_lstm_output])
# Concat attention input and decoder LSTM output
decoder_concate_inputs = Concatenate(axis=-1,name='concatenate_layer')([decoder_lstm_output,attention_outputs])
#dense layer
dense_layer = TimeDistributed(Dense(y_vocabulary,activation='softmax'))
decoder_dense_outputs = dense_layer(decoder_concate_inputs)TimeDistributed层
输出维度:[样本批数量,滑窗大小,特征维度(由输入特征维度变成全连接层神经元数目即输出类别数)]
注意输出仍为滑窗大小的一个序列即多个词,而非一个词
TimeDistributed层给予了模型一种一对多,多对多的能力,增加了模型的维度。

TimeDistributed层在每个时间步上均操作了Dense,由上面几个图明显可以看出了增加了模型实现一对多和多对多的能力。如果你使用正常的Dense层,你最后只会得到一个结果。
#define the model
from tensorflow.python.keras.models import Model
encoder_model = Model(inputs=encoder_inputs,outputs=[encoder_lstm3_output,encoder_lstm3_state_h,encoder_lstm3_state_c])
enc_dec_att_model = Model([encoder_inputs,decoder_inputs],decoder_dense_outputs)
enc_dec_att_model.summary()自定义模型完成
keras构建model有两种方法:
sequential序贯模型,只需在里面添加layer,确保是前面输出即为后面输入,那么就可选择这种;
函数式自定义模型,需要自己建立layer以及各输入与layer与各输出直接的关系,然后用Model([初始输入],[最终输出])函数将前后输入输出连起来,相当于整个模型定义完成
模型编译
model.compile(optimizer='rmsprop',loss='sparse_categorical_crossentropy')categorical_crossentropy 和 sparse_categorical_crossentropy 的区别在哪?
如果你的 targets 是 one-hot 编码(e.g.:[0, 0, 1], [1, 0, 0], [0, 1, 0]),用 categorical_crossentropy
如果你的 tagets 是 数字编码(e.g.:2, 0, 1) ,用 sparse_categorical_crossentropy
模型训练
Model.fit()按照Model([初始输入],[最终输出])的格式进行
es = EarlyStopping(monitor='val_loss',mode='min',verbose=1,patience=2)
history = model.fit([x_train_seq_pad,y_train_seq_pad[:,:-1]],y_train_seq_pad.reshape(y_train_seq_pad.shape[0],y_train_seq_pad.shape[1],1),epochs=1,callbacks=[es],batch_size=128,validation_data=([x_validation_seq_pad,y_validation_seq_pad[:,:-1]],y_validation_seq_pad.reshape(y_validation_seq_pad.shape[0],y_validation_seq_pad.shape[1],1)[:,1:]))注:
x的shape【样本数,文本长度,词向量维度】已经满足[样本批大小,滑窗大小,特征数量]的结构,
y.reshape是为了将最终输出转化为三维结构,以满足timedistributed的输出维度要求
此外,原始输入的y序列应该是从start标志开始到倒数第二个词结束;最终输出的y序列则是从第二个词开始到序列结束