python编程学习——第四周(2)
第四周
python学习笔记和做的一些习题 (python编程快速上手——让繁琐工作自动化)
第八章 读写文件
文件与文件路径
文件的两个属性:文件名和路径
在 Windows 上,路径书写使用倒斜杠作为文件夹之间的分隔符。但在 OS X 和Linux 上,使用正斜杠作为它们的路径分隔符。如果想要程序运行在所有操作系统上,在编写 Python 脚本时,用os.path.join()函数可以处理这两种情况。如果将单个文件和路径上的文件夹名称的字符串传递给它,os.path.join()就会返回一个文件路径的字符串,包含正确的路径分隔符。
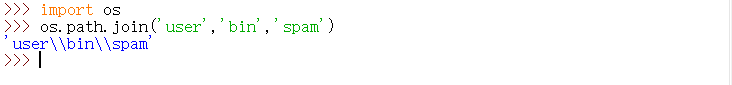
如果需要创建文件名称的字符串,也可以用os.path.join()函数。
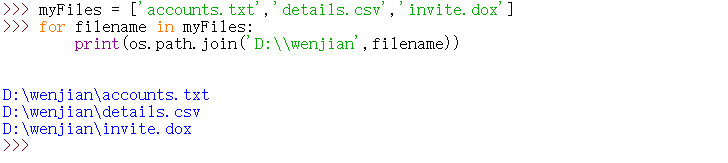
当前工作目录:利用 os.getcwd()函数,可以取得当前工作路径的字符串,并可以利用 os.chdir()改变它。
有两种方法指定一个文件路径:
绝对路径:总是从根文件夹开始。
相对路径:相当于程序的当前工作目录
用os.makeddirs()创建新的文件夹:

os.path模块:包含了许多与文件名和文件路径相关的有用函数。
处理绝对路径和相对路径:
os.path 模块提供了一些函数,返回一个相对路径的绝对路径,以及检查给定的路径是否为绝对路径。
• 调用 os.path.abspath(path)将返回参数的绝对路径的字符串。这是将相对路径转换为绝对路径的简便方法。
• 调用 os.path.isabs(path),如果参数是一个绝对路径,就返回 True,如果参数是一个相对路径,就返回 False。
• 调用 os.path.relpath(path, start)将返回从 start 路径到 path 的相对路径的字符串。
查看文件大小和文件夹内容:
os.path 模块提供了一些函数,用于查看文件的字节数以及给定文件夹中的文件和子文件夹。
• 调用 os.path.getsize(path)将返回 path 参数中文件的字节数。
• 调用 os.listdir(path)将返回文件名字符串的列表,包含 path 参数中的每个文件。
检查路径有效性:
os.path 模块提供了一些函数,用于检测给定的路径是否存在,以及它是文件还是文件夹。
• 如果 path 参数所指的文件或文件夹存在,调用 os.path.exists(path)将返回 True,否则返回 False。
• 如果 path 参数存在,并且是一个文件,调用 os.path.isfile(path)将返回 True,否则返回 False。
• 如果 path 参数存在,并且是一个文件夹,调用 os.path.isdir(path)将返回 True,否则返回 False。
文件读写过程
在 Python 中,读写文件有 3 个步骤:
1.调用 open()函数,返回一个 File 对象。
2.调用 File 对象的 read()或 write()方法。
3.调用 File 对象的 close()方法,关闭该文件。


用shelve模块保存变量
利用 shelve 模块,你可以将 Python 程序中的变量保存到二进制的 shelf 文件中。这样,程序就可以从硬盘中恢复变量的数据。shelve 模块让你在程序中添加“保存”和“打开”功能。

在“D:\Creat\text”目录下多了三个新文件:

可以使用 shelve 模块,重新打开这些文件并取出数据。shelf 值不必用读模式或写模式打开,因为它们在打开后,既能读又能写。
先检查之前输入的数据是否正确:

就像字典一样,shelf 值有 keys()和 values()方法,返回 shelf 中键和值的类似列表的值。因为这些方法返回类似列表的值,而不是真正的列表,所以应该将它们传递给 list()函数,取得列表的形式。

用pprint.pformat()函数保存变量
pprint.pformat()函数将返回同样的文本字符串,但不是打印它。这个字符串不仅是易于阅读的格式,同时也是语法上正确的 Python 代码。pprint.pformat()函数将提供一个字符串,你可以将它写入.py 文件。该文件将成为你自己的模块,如果你需要使用存储在其中的变量,就可以导入它。

import 语句导入的模块本身就是 Python 脚本。如果来自 pprint.pformat()的字符串保存为一个.py 文件,该文件就是一个可以导入的模块,像其他模块一样。由于 Python 脚本本身也是带有.py 文件扩展名的文本文件,所以你的 Python 程序甚至可以生成其他 Python 程序。然后可以将这些文件导入到脚本中。

项目:生成随机的测验试卷文件
假如你是一位地理老师,班上有 35 名学生,你希望进行美国各州首府的一个
小测验。不妙的是,班里有几个坏蛋,你无法确信学生不会作弊。你希望随机调整问题的次序,这样每份试卷都是独一无二的,这让任何人都不能从其他人那里抄袭答案。
程序要做的事情:
• 创建 35 份不同的测验试卷。
• 为每份试卷创建 50 个多重选择题,次序随机。
• 为每个问题提供一个正确答案和 3 个随机的错误答案,次序随机。
• 将测验试卷写到 35 个文本文件中。
• 将答案写到 35 个文本文件中。
这意味着代码需要做下面的事:
• 将州和它们的首府保存在一个字典中。
• 针对测验文本文件和答案文本文件,调用 open()、write()和 close()。
• 利用 random.shuffle()随机调整问题和多重选项的次序。
import random
#将检测数据保存在一个字典中
capitals = {'Alabama': 'Montgomery', 'Alaska': 'Juneau', 'Arizona': 'Phoenix',
'Arkansas': 'Little Rock', 'California': 'Sacramento', 'Colorado': 'Denver',
'Connecticut': 'Hartford', 'Delaware': 'Dover', 'Florida': 'Tallahassee',
'Georgia': 'Atlanta', 'Hawaii': 'Honolulu', 'Idaho': 'Boise', 'Illinois':
'Springfield', 'Indiana': 'Indianapolis', 'Iowa': 'Des Moines', 'Kansas':
'Topeka', 'Kentucky': 'Frankfort', 'Louisiana': 'Baton Rouge', 'Maine':
'Augusta', 'Maryland': 'Annapolis', 'Massachusetts': 'Boston', 'Michigan':
'Lansing', 'Minnesota': 'Saint Paul', 'Mississippi': 'Jackson', 'Missouri':
'Jefferson City', 'Montana': 'Helena', 'Nebraska': 'Lincoln', 'Nevada':
'Carson City', 'New Hampshire': 'Concord', 'New Jersey': 'Trenton',
'NewMexico':'Santa Fe', 'New York': 'Albany', 'North Carolina': 'Raleigh',
'North Dakota': 'Bismarck', 'Ohio': 'Columbus', 'Oklahoma': 'Oklahoma City',
'Oregon': 'Salem', 'Pennsylvania': 'Harrisburg', 'Rhode Island': 'Providence',
'South Carolina': 'Columbia', 'South Dakota': 'Pierre', 'Tennessee':
'Nashville', 'Texas': 'Austin', 'Utah': 'Salt Lake City', 'Vermont':
'Montpelier', 'Virginia': 'Richmond', 'Washington': 'Olympia',
'WestVirginia': 'Charleston', 'Wisconsin': 'Madison', 'Wyoming': 'Cheyenne'}
for quizNum in range(35):
# 创建测验和答案文件。
quizFile = open('capitalsquiz%s.txt' % (quizNum + 1), 'w')
answerKeyFile = open('capitalsquiz_answers%s.txt' % (quizNum + 1), 'w')
# 写下测验的标题和开头。
quizFile.write('Name:\n\nDate:\n\nPeriod:\n\n')
quizFile.write((' ' * 20) + 'State Capitals Quiz (Form %s)' % (quizNum + 1))
quizFile.write('\n\n')
#随机排列(打乱capital字典)。
states = list(capitals.keys())
random.shuffle(states)
#循环states,制造5个问题
for questionNum in range(5):
correctAnswer = capitals[states[questionNum]]
wrongAnswers = list(capitals.values())
del wrongAnswers[wrongAnswers.index(correctAnswer)]
wrongAnswers = random.sample(wrongAnswers, 3)
answerOptions = wrongAnswers + [correctAnswer]
random.shuffle(answerOptions)
#将内容写入测验试卷和答案文件
quizFile.write('%s. What is the capital of %s?\n' % (questionNum + 1,
states[questionNum]))
for i in range(4):
quizFile.write(' %s. %s\n' % ('ABCD'[i], answerOptions[i]))
quizFile.write('\n')
# 将答案写入文件.
answerKeyFile.write('%s. %s\n' % (questionNum + 1, 'ABCD'[answerOptions.index(correctAnswer)]))
quizFile.close()
answerKeyFile.close()
完成后的txt文件:

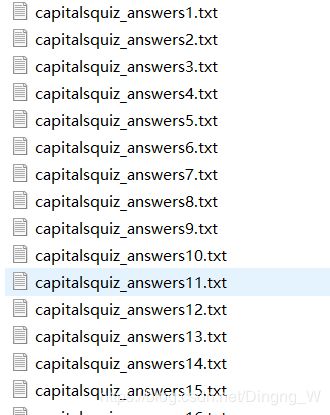
打开后应该是:


项目 多重剪贴板
假定你有一个无聊的任务,要填充一个网页或软件中的许多表格,其中包含一些文本字段。剪贴板让你不必一次又一次输入同样的文本,但剪贴板上一次只有一个内容。如果你有几段不同的文本需要拷贝粘贴,就不得不一次又一次的标记和拷贝几个同样的内容。
下面是程序要做的事:
• 针对要检查的关键字,提供命令行参数。
• 如果参数是 save,那么将剪贴板的内容保存到关键字。
• 如果参数是 list,就将所有的关键字拷贝到剪贴板。
• 否则,就将关键词对应的文本拷贝到剪贴板。
这意味着代码需要做下列事情:
• 从 sys.argv 读取命令行参数。
• 读写剪贴板。
• 保存并加载 shelf 文件。
#! python3
# mcb.pyw - Saves and loads pieces of text to the clipboard.
# Usage: py.exe mcb.pyw save - Saves clipboard to keyword.
# py.exe mcb.pyw - Loads keyword to clipboard.
# py.exe mcb.pyw list - Loads all keywords to clipboard.
import shelve, pyperclip, sys
mcbShelf = shelve.open('mcb')
# 用一个关键字保存剪贴板内容
if len(sys.argv) == 3 and sys.argv[1].lower() == 'save':
mcbShelf[sys.argv[2]] = pyperclip.paste()
elif len(sys.argv) == 2:
# 列出关键字和加载关键字的内容
if sys.argv[1].lower() == 'list':
pyperclip.copy(str(list(mcbShelf.keys())))
elif sys.argv[1] in mcbShelf:
pyperclip.copy(mcbShelf[sys.argv[1]])
mcbShelf.close()

第八章节习题
1.相对路径是相对于什么?
相对于当前工作目录。
2.绝对路径从什么开始?
从根文件夹开始。
3.os.getcwd()和 os.chdir()函数做什么事?
返回当前工作目录和改变当前工作目录。
4..和…文件夹是什么?
.是当前文件夹,…是父文件夹。
5.在 C:\bacon\eggs\spam.txt 中,哪一部分是目录名称,哪一部分是基本名称?
C:\bacon\eggs是目录名,spam.txt 是文件名。
6.可以传递给 open()函数的 3 种“模式”参数是什么?
‘r’:读模式;‘w’:写模式;‘a’:添加模式
7.如果已有的文件以写模式打开,会发生什么?
原有内容会被删除并重写。
8.read()和 readlines()方法之间的区别是什么?
read() 方法将文件的全部内容作为一个字符串返回。
readlines() 返回一个字符串列表,其中每个字符串是文件内容中的一行。
9.shelf 值与什么数据结构相似?
类似字典值
第八章实践项目
扩展多重剪贴板
扩展本章中的多重剪贴板程序,增加一个 delete 命令行参数,它将从 shelf 中删除一个关键字。然后添加一个 delete 命令行参数,它将删除所有关键字。
#! python3
# mcb.pyw - Saves and loads pieces of text to the clipboard.
# Usage: py.exe mcb.pyw save - Saves clipboard to keyword.
# py.exe mcb.pyw - Loads keyword to clipboard.
# py.exe mcb.pyw list - Loads all keywords to clipboard.
import shelve, pyperclip, sys
mcbShelf = shelve.open('mcb')
# 用一个关键字保存剪贴板内容
if len(sys.argv) == 3 and sys.argv[1].lower() == 'save':
mcbShelf[sys.argv[2]] = pyperclip.paste()
if sys.argv[1].lower() == 'delete' and sys.argv[2] in mcbShelf.keys():
del mcbShelf[sys.argv[2]]
print('键' + sys.argv[2] + '对应删除成功!')
else:
print('你要删除的键不存在,请确认!')
elif len(sys.argv) == 2:
# 列出关键字和加载关键字的内容
if sys.argv[1].lower() == 'list': #列出所有关键字
pyperclip.copy(str(list(mcbShelf.keys())))
elif sys.argv[1].lower() == 'delete':
for i in mcbShelf.keys():
del mcbShelf[i]
elif sys.argv[1] in mcbShelf.keys():
pyperclip.copy(mcbShelf[sys.argv[1]])
else:
print('不存在该键')
mcbShelf.close()
疯狂填词
创建一个疯狂填词(Mad Libs)程序,它将读入文本文件,并让用户在该文本文件中出现 ADJECTIVE、NOUN、ADVERB 或 VERB 等单词的地方,加上他们自己的文本。例如,一个文本文件可能看起来像这样:
The ADJECTIVE panda walked to the NOUN and then VERB. A nearby NOUN was unaffected by these events.
程序将找到这些出现的单词,并提示用户取代它们。
Enter an adjective:
silly
Enter a noun:
chandelier
Enter a verb:
screamed
Enter a noun:
pickup truck
以下的文本文件将被创建:
The silly panda walked to the chandelier and then screamed.
A nearby pickuptruck was unaffected by these events.
结果应该打印到屏幕上,并保存为一个新的文本文件。
#8.9.2 疯狂填词
import re
madLibsFile = open('D:\\Create\\text\\madLibs.txt')
madLibsContent = madLibsFile.read()
regex = re.compile(r'ADJECTIVE|NOUN|VERB|NOUN', re.IGNORECASE)
lis = regex.findall(madLibsContent)
reLis = [] #代替列表
for i in range(len(lis)):
print('Enter an '+lis[i].lower() + ' :')
madLibsContent = madLibsContent.replace(lis[i],input())
print(madLibsContent)
madLibsFinishedFile = open('D:\\Create\\text\\madLibsFinished.txt', 'w')
madLibsFinishedFile.write(madLibsContent)
这里有几个没有解决的问题:英文单词之前的定冠词a an 没有区分;在替代第二个NOUN时没有替代成功。
