Log-Linear Model & CRF 条件随机场详解
文章目录
- 往期文章链接目录
- Log-Linear model
- Conditional Random Fields (CRF)
- Formal definition of CRF
- Log-linear model to linear-CRF
- Inference problem for CRF
- Learning problem for CRF
- Learning problem for general Log-Linear model
- Learning problem for CRF
- Compute Z ( x ˉ , w ) Z(\bar x, w) Z(xˉ,w)
- Forward Algorithm
- Backward Algorithm
- Compute p ( y k = u ∣ x ˉ ; w ) p(y_k=u|\bar x; w) p(yk=u∣xˉ;w)
- Compute p ( y k = u , y k + 1 = v ∣ x ˉ ; w ) p(y_k=u, y_{k+1}=v|\bar x; w) p(yk=u,yk+1=v∣xˉ;w)
- 往期文章链接目录
往期文章链接目录
Log-Linear model
Let x x x be an example, and let y y y be a possible label for it. A log-linear model assumes that
p ( y ∣ x ; w ) = exp [ ∑ j = 1 J w j F j ( x , y ) ] Z ( x , w ) p(y | x ; w)=\frac{\exp [\sum_{j=1}^J w_{j} F_{j}(x, y)]}{Z(x, w)} p(y∣x;w)=Z(x,w)exp[∑j=1JwjFj(x,y)]
where the partition function
Z ( x , w ) = ∑ y ′ exp [ ∑ j = 1 J w j F j ( x , y ′ ) ] Z(x, w)=\sum_{y^{\prime}} \exp [\sum_{j=1}^J w_{j} F_{j}\left(x, y^{\prime}\right)] Z(x,w)=y′∑exp[j=1∑JwjFj(x,y′)]
Note that in ∑ y ′ \sum_{y^{\prime}} ∑y′, we make a summation over all possible y y y. Therefore, given x x x, the label predicted by the model is
y ^ = argmax y p ( y ∣ x ; w ) = argmax y ∑ j = 1 J w j F j ( x , y ) \hat{y}=\underset{y}{\operatorname{argmax}} p(y | x ; w)=\underset{y}{\operatorname{argmax}} \sum_{j=1}^J w_{j} F_{j}(x, y) y^=yargmaxp(y∣x;w)=yargmaxj=1∑JwjFj(x,y)
Each expression F j ( x , y ) F_j(x, y) Fj(x,y) is called a feature-function. You can think of it as the j j j-th feature extracted from ( x , y ) (x,y) (x,y).
Remark of the log-linear model:
-
a linear combination ∑ j = 1 J w j F j ( x , y ) \sum_{j=1}^J w_{j} F_{j}(x, y) ∑j=1JwjFj(x,y) can take any positive or negative real value; the exponential makes it positive.
-
The division makes the result p ( y ∣ x ; w ) p(y | x ; w) p(y∣x;w) between 0 and 1, i.e. makes them be valid probabilities.
Conditional Random Fields (CRF)
Last time, we talked about Markov Random Fields. In this post, we are going to discuss Conditional Random Fields, which is an important special case of Markov Random Fields arises when they are applied to model a conditional probability distribution p ( y ∣ x ) p(y|x) p(y∣x), where x x x and y y y are vactor-valued variables.
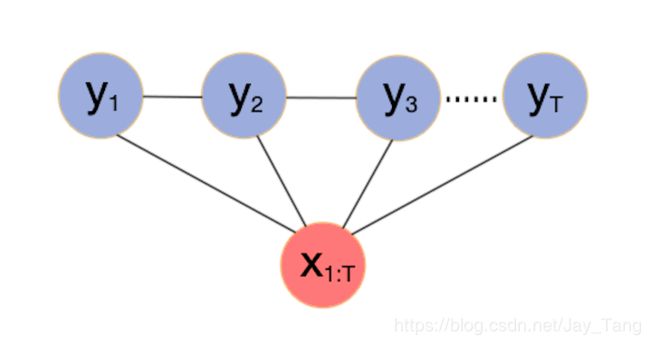
Formal definition of CRF
Formally, a CRF is a Markov network which specifies a conditional distribution
P ( y ∣ x ) = 1 Z ( x ) ∏ c ∈ C ϕ c ( x c , y c ) P(y\mid x) = \frac{1}{Z(x)} \prod_{c \in C} \phi_c(x_c,y_c) P(y∣x)=Z(x)1c∈C∏ϕc(xc,yc)
with partition function
Z = ∑ y ∈ Y ∏ c ∈ C ϕ c ( x c , y c ) Z = \sum_{y \in \mathcal{Y}} \prod_{c \in C} \phi_c(x_c,y_c) Z=y∈Y∑c∈C∏ϕc(xc,yc)
we further assume that the factors ϕ c ( x c , y c ) \phi_c(x_c,y_c) ϕc(xc,yc) (maximal cliques) are of the form
ϕ c ( x c , y c ) = exp [ w c T f c ( x c , y c ) ] \phi_c(x_c,y_c) = \exp[w_c^T f_c(x_c, y_c)] ϕc(xc,yc)=exp[wcTfc(xc,yc)]
Since we require our potential function ϕ \phi ϕ to be non-negative, it’s natural to use the exponential function. f c ( x c , y c ) f_c(x_c, y_c) fc(xc,yc) can be an arbitrary set of features describing the compatibility between x c x_c xc and y c y_c yc. Note that these feature functions could be designed by manually doing feature engineering or using deep learning, LSTM, etc.
Log-linear model to linear-CRF
As a remainder, let x x x be an example, and let y y y be a possible label for it. Then a log-linear model assumes that
p ( y ∣ x ; w ) = exp [ ∑ j = 1 J w j F j ( x , y ) ] Z ( x , w ) p(y | x ; w)=\frac{\exp [\sum_{j=1}^J w_{j} F_{j}(x, y)]}{Z(x, w)} p(y∣x;w)=Z(x,w)exp[∑j=1JwjFj(x,y)]
From now on, we use the bar notation for sequences. Then to linear-CRF, we write the above equation as
p ( y ˉ ∣ x ˉ ; w ) = exp [ ∑ j = 1 J w j F j ( x ˉ , y ˉ ) ] Z ( x ˉ , w ) = exp [ ∑ j = 1 J w j ∑ i = 2 T f j ( y i − 1 , y i , x ˉ ) ] Z ( x ˉ , w ) ( 1 ) \begin{aligned} p(\bar y | \bar x; w) &= \frac{\exp [\sum_{j=1}^J w_{j} F_{j}(\bar x, \bar y)]}{Z(\bar x, w)}\\ &= \frac{\exp [\sum_{j=1}^J w_{j} \sum_{i=2}^{T} f_j (y_{i-1}, y_i, \bar x)]}{Z(\bar x, w)} &&\quad(1) \end{aligned} p(yˉ∣xˉ;w)=Z(xˉ,w)exp[∑j=1JwjFj(xˉ,yˉ)]=Z(xˉ,w)exp[∑j=1Jwj∑i=2Tfj(yi−1,yi,xˉ)](1)
where y y y can take values from { 1 , 2 , . . . , m } \{1,2,...,m\} {1,2,...,m}. Here is an example:
Assume we have a sequence x ˉ = ( x 1 , x 2 , x 3 , x 4 ) \bar x = (x_1, x_2, x_3, x_4) xˉ=(x1,x2,x3,x4) and the corresponding hidden sequence y ˉ = ( y 1 , y 2 , y 3 , y 4 ) \bar y = (y_1, y_2, y_3, y_4) yˉ=(y1,y2,y3,y4).
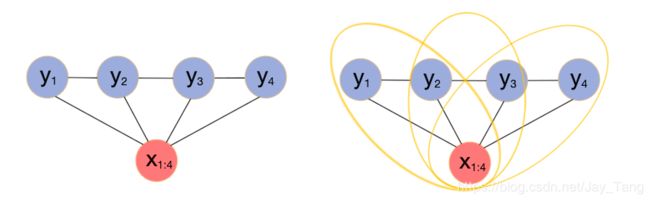
We can divide each feature-function F j ( x ˉ , y ˉ ) F_j(\bar x, \bar y) Fj(xˉ,yˉ) into fuctions for each maximal clique. That is,
F j ( x ˉ , y ˉ ) = ∑ i = 2 T f j ( y i − 1 , y i , x ˉ ) (1.1) F_j(\bar x, \bar y) = \sum_{i=2}^{T} f_j (y_{i-1}, y_i, \bar x) \tag {1.1} Fj(xˉ,yˉ)=i=2∑Tfj(yi−1,yi,xˉ)(1.1)
Perticularly, from the above figure, since we have 3 3 3 maximal cliques, so
F j ( x ˉ , y ˉ ) = f j ( y 1 , y 2 , x ˉ ) + f j ( y 2 , y 3 , x ˉ ) + f j ( y 3 , y 4 , x ˉ ) F_j(\bar x, \bar y) = f_j(y_1, y_2, \bar x) + f_j(y_2, y_3, \bar x) + f_j(y_3, y_4, \bar x) Fj(xˉ,yˉ)=fj(y1,y2,xˉ)+fj(y2,y3,xˉ)+fj(y3,y4,xˉ)
If we extract J J J feature functions from the ( x ˉ , y ˉ ) (\bar x, \bar y) (xˉ,yˉ) pair, then it becomes
∑ j = 1 J w j F j ( x , y ) = ∑ j = 1 J w j ∑ i = 2 T f j ( y i − 1 , y i , x ˉ ) \sum_{j=1}^J w_{j} F_{j}(x, y) = \sum_{j=1}^J w_{j} \sum_{i=2}^{T} f_j (y_{i-1}, y_i, \bar x) j=1∑JwjFj(x,y)=j=1∑Jwji=2∑Tfj(yi−1,yi,xˉ)
Inference problem for CRF
- Goal: given a sequence x ˉ \bar x xˉ, and parameter w w w, find the best hidden sequence y ˉ \bar y yˉ. The condition probability of y ˉ \bar y yˉ is
p ( y ˉ ∣ x ˉ ; w ) = exp [ ∑ j = 1 J w j ∑ i = 2 T f j ( y i − 1 , y i , x ˉ ) ] Z ( x ˉ , w ) p(\bar y | \bar x; w) = \frac{\exp [\sum_{j=1}^J w_{j} \sum_{i=2}^{T} f_j (y_{i-1}, y_i, \bar x)]}{Z(\bar x, w)} p(yˉ∣xˉ;w)=Z(xˉ,w)exp[∑j=1Jwj∑i=2Tfj(yi−1,yi,xˉ)]
Our objective is(check that the objective of CRF is the objective of Log-Linear model described above):
y ^ = argmax y ˉ p ( y ˉ ∣ x ˉ ; w ) ( 2 ) = argmax y ˉ ∑ j = 1 J w j ∑ i = 2 T f j ( y i − 1 , y i , x ˉ ) ( 3 ) = argmax y ˉ ∑ i = 2 T g i ( y i − 1 , y i ) ( 4 ) \begin{aligned} \hat{y} &= \underset{\bar y}{\operatorname{argmax}} p(\bar y | \bar x ; w) &&(2)\\ &= \underset{\bar y}{\operatorname{argmax}} \sum_{j=1}^J w_{j} \sum_{i=2}^{T} f_j (y_{i-1}, y_i, \bar x) &&(3) \\ &= \underset{\bar y}{\operatorname{argmax}} \sum_{i=2}^{T} g_i(y_{i-1}, y_i) && (4) \end{aligned} y^=yˉargmaxp(yˉ∣xˉ;w)=yˉargmaxj=1∑Jwji=2∑Tfj(yi−1,yi,xˉ)=yˉargmaxi=2∑Tgi(yi−1,yi)(2)(3)(4)
Note:
-
( 2 ) → ( 3 ) (2) \to (3) (2)→(3): we can ignore the denominator since it stays the same for all possible y ˉ \bar y yˉ. Exponential function won’t affect our objective.
-
We set
g i ( y i − 1 , y i ) = ∑ j = 1 J w j ⋅ f j ( y i − 1 , y i , x ˉ ) (5) g_i(y_{i-1}, y_i) = \sum_{j=1}^J w_{j} \cdot f_j (y_{i-1}, y_i, \bar x) \tag 5 gi(yi−1,yi)=j=1∑Jwj⋅fj(yi−1,yi,xˉ)(5)
Based on our objective in ( 5 ) (5) (5), we want to find the best path from y 1 y_1 y1 to y T y_T yT such that the objective function is maximized. Clearly, we can use Dynamic Programming (DP) here.
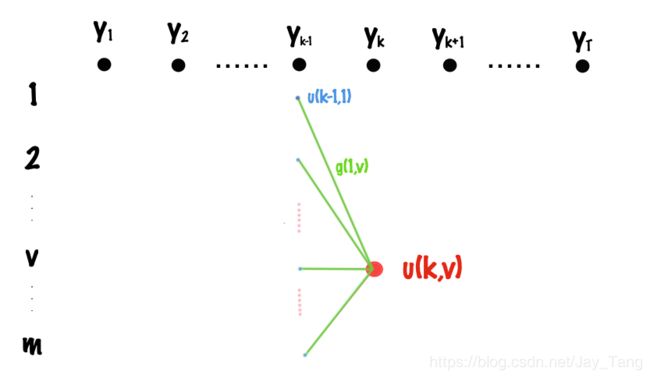
Let u ( k , v ) u(k,v) u(k,v) denote the score of the best path from t = 1 t=1 t=1 to t = k t=k t=k, where the tag of time k k k is v v v. Then the recursion formula can be easily visualized from the above figure and we can write it as
u ( k , v ) = max s [ u ( k − 1 , s ) + g k ( s , v ) ] u(k,v) = \underset{s}{\operatorname{max}} [u(k-1, s) + g_k(s,v)] u(k,v)=smax[u(k−1,s)+gk(s,v)]
where s s s takes values from states { 1 , 2 , . . . , m } \{1,2,...,m\} {1,2,...,m}. The maximum of the objective is max { u ( T , 1 ) , u ( T , 2 ) , . . . , u ( T , m ) } \operatorname{max} \{u(T,1), u(T,2), ..., u(T,m)\} max{u(T,1),u(T,2),...,u(T,m)}.
-
Time complexity: O ( m T ) ⋅ O ( m ) = O ( m 2 T ) O(mT) \cdot O(m) = O(m^2 T) O(mT)⋅O(m)=O(m2T).
-
Space complexity: O ( m T ) O(mT) O(mT) since we need to track the path of the best sequence y ˉ \bar y yˉ.
Learning problem for CRF
Goal: Given the data set D = { ( x ( 1 ) , y ( 1 ) ) , . . . , ( x ( n ) , y ( n ) ) } D = \{ ({x^{(1)}}, {y^{(1)}}), ..., ({x^{(n)}}, {y^{(n)}})\} D={(x(1),y(1)),...,(x(n),y(n))}, we want to find parameter w w w to maximize p ( D ∣ w ) p(D|w) p(D∣w). That is,
w ^ M L E = max w p ( D ∣ w ) = max w ∏ i = 1 n p ( y ( i ) ∣ x ( i ) ; w ) \begin{aligned} \hat{w}_{MLE} &= \underset{w}{\operatorname{max}} p(D|w) \\ &= \underset{w}{\operatorname{max}} \prod_{i=1}^{n} p( {y^{(i)}} | {x^{(i)}}; w) \end{aligned} w^MLE=wmaxp(D∣w)=wmaxi=1∏np(y(i)∣x(i);w)
That is, we need to take derivatives and then use the gradient descent method.
Learning problem for general Log-Linear model
p ( y ˉ , x ˉ ; w ) = exp [ ∑ j = 1 J w j F j ( x , y ) ] Z ( x , w ) p(\bar y, \bar x; w) = \frac{\exp [\sum_{j=1}^J w_{j} F_{j}(x, y)]}{Z(x, w)} p(yˉ,xˉ;w)=Z(x,w)exp[∑j=1JwjFj(x,y)]
Take the derivative with respect to w j w_j wj:
∂ ∂ w j [ log p ( y ∣ x ; w ) ] = ∂ ∂ w j [ ∑ j = 1 J w j F j ( x , y ) − log Z ( x , w ) ] = F j ( x , y ) − 1 Z ( x , w ) ⋅ ∂ ∂ w j Z ( x , w ) ( 6 ) \begin{aligned} \frac{\partial}{\partial w_j} [\log p(y| x; w)] &= \frac{\partial}{\partial w_j} [\sum_{j=1}^J w_{j} F_j(x, y) - \log Z(x,w)] \\ &= F_j(x, y) - \frac{1}{Z(x,w)} \cdot \frac{\partial}{\partial w_j} Z(x,w) &&(6) \end{aligned} ∂wj∂[logp(y∣x;w)]=∂wj∂[j=1∑JwjFj(x,y)−logZ(x,w)]=Fj(x,y)−Z(x,w)1⋅∂wj∂Z(x,w)(6)
where
∂ ∂ w j Z ( x , w ) = ∂ ∂ w j ∑ y ′ exp [ ∑ j = 1 J w j F j ( x , y ′ ) ] = ∑ y ′ ∂ ∂ w j [ exp ∑ j = 1 J w j F j ( x , y ′ ) ] = ∑ y ′ [ exp ∑ j = 1 J w j F j ( x , y ′ ) ] ⋅ F j ( x , y ′ ) ( 7 ) \begin{aligned} \frac{\partial}{\partial w_j} Z(x,w) &= \frac{\partial}{\partial w_j} \sum_{y^{\prime}} \exp [\sum_{j=1}^J w_{j} F_{j}\left(x, y^{\prime}\right)] \\ &= \sum_{y^{\prime}} \frac{\partial}{\partial w_j} [\exp \sum_{j=1}^J w_{j} F_{j}\left(x, y^{\prime}\right)] \\ &= \sum_{y^{\prime}} [\exp \sum_{j=1}^J w_{j} F_{j}\left(x, y^{\prime}\right)] \cdot F_{j}\left(x, y^{\prime}\right) &&(7) \end{aligned} ∂wj∂Z(x,w)=∂wj∂y′∑exp[j=1∑JwjFj(x,y′)]=y′∑∂wj∂[expj=1∑JwjFj(x,y′)]=y′∑[expj=1∑JwjFj(x,y′)]⋅Fj(x,y′)(7)
Combining ( 6 ) (6) (6) and ( 7 ) (7) (7), we have
∂ ∂ w j [ log p ( y ∣ x ; w ) ] = F j ( x , y ) − 1 Z ( x , w ) ∑ y ′ F j ( x , y ′ ) [ exp ∑ j = 1 J w j F j ( x , y ′ ) ] = F j ( x , y ) − ∑ y ′ F j ( x , y ′ ) exp ∑ j = 1 J w j F j ( x , y ′ ) Z ( x , w ) = F j ( x , y ) − ∑ y ′ F j ( x , y ′ ) ⋅ p ( y ′ ∣ x ; w ) = F j ( x , y ) − E y ′ ∼ p ( y ′ ∣ x ; w ) [ F j ( x , y ′ ) ] ( 8 ) \begin{aligned} \frac{\partial}{\partial w_j} [\log p(y| x; w)] &= F_{j}\left(x, y\right) - \frac{1}{Z(x,w)} \sum_{y^{\prime}} F_{j}\left(x, y^{\prime}\right) [\exp \sum_{j=1}^J w_{j} F_{j}\left(x, y^{\prime}\right)] \\ &= F_{j}\left(x, y\right) - \sum_{y^{\prime}} F_{j}\left(x, y^{\prime}\right) \frac{\exp \sum_{j=1}^J w_{j} F_{j}\left(x, y^{\prime}\right)}{Z(x,w)} \\ &= F_{j}\left(x, y\right) - \sum_{y^{\prime}} F_{j}\left(x, y^{\prime}\right) \cdot p(y^{\prime}|x;w) \\ &= F_{j}\left(x, y\right) - E_{y^{\prime} \sim p(y^{\prime}|x;w)}[F_{j}\left(x, y^{\prime}\right)] &&(8) \end{aligned} ∂wj∂[logp(y∣x;w)]=Fj(x,y)−Z(x,w)1y′∑Fj(x,y′)[expj=1∑JwjFj(x,y′)]=Fj(x,y)−y′∑Fj(x,y′)Z(x,w)exp∑j=1JwjFj(x,y′)=Fj(x,y)−y′∑Fj(x,y′)⋅p(y′∣x;w)=Fj(x,y)−Ey′∼p(y′∣x;w)[Fj(x,y′)](8)
Learning problem for CRF
We can edit ( 8 ) (8) (8) to get the partial derivative for CRF:
∂ ∂ w j [ log p ( y ˉ ∣ x ˉ ; w ) ] = F j ( x ˉ , y ˉ ) − E y ˉ ′ ∼ p ( y ˉ ′ ∣ x ; w ) [ F j ( x , y ˉ ′ ) ] ( 9 ) = F j ( x ˉ , y ˉ ) − E y ˉ ′ [ ∑ i = 2 T f j ( y i − 1 , y i , x ˉ ) ] ( 10 ) = F j ( x ˉ , y ˉ ) − ∑ i = 2 T E y ˉ ′ [ f j ( y i − 1 , y i , x ˉ ) ] ( 11 ) = F j ( x ˉ , y ˉ ) − ∑ i = 2 T E y i − 1 , y i [ f j ( y i − 1 , y i , x ˉ ) ] ( 12 ) = F j ( x ˉ , y ˉ ) − ∑ i = 2 T ∑ y i − 1 ∑ y i f j ( y i − 1 , y i , x ˉ ) ⋅ p ( y i − 1 , y i ∣ x ˉ ; w ) ( 13 ) \begin{aligned} \frac{\partial}{\partial w_j} [\log p(\bar y| \bar x; w)] &= F_{j}\left(\bar x, \bar y\right) - E_{\bar y^{\prime} \sim p(\bar y^{\prime}|x;w)}[F_{j}\left(x,\bar y^{\prime}\right)] &&(9)\\ &= F_{j}\left(\bar x, \bar y\right) - E_{\bar y^{\prime}}[\sum_{i=2}^T f_j(y_{i-1}, y_i, \bar x)] &&(10)\\ &= F_{j}\left(\bar x, \bar y\right) - \sum_{i=2}^T E_{\bar y^{\prime} }[f_j(y_{i-1}, y_i, \bar x)] &&(11)\\ &= F_{j}\left(\bar x, \bar y\right) - \sum_{i=2}^T E_{y_{i-1}, y_i}[f_j(y_{i-1}, y_i, \bar x)] &&(12)\\ &= F_{j}\left(\bar x, \bar y\right) - \sum_{i=2}^T \sum_{y_{i-1}} \sum_{y_{i}} f_j(y_{i-1}, y_i, \bar x) \cdot p(y_{i-1}, y_i| \bar x; w) &&(13) \end{aligned} ∂wj∂[logp(yˉ∣xˉ;w)]=Fj(xˉ,yˉ)−Eyˉ′∼p(yˉ′∣x;w)[Fj(x,yˉ′)]=Fj(xˉ,yˉ)−Eyˉ′[i=2∑Tfj(yi−1,yi,xˉ)]=Fj(xˉ,yˉ)−i=2∑TEyˉ′[fj(yi−1,yi,xˉ)]=Fj(xˉ,yˉ)−i=2∑TEyi−1,yi[fj(yi−1,yi,xˉ)]=Fj(xˉ,yˉ)−i=2∑Tyi−1∑yi∑fj(yi−1,yi,xˉ)⋅p(yi−1,yi∣xˉ;w)(9)(10)(11)(12)(13)
Note:
-
( 9 ) → ( 10 ) (9) \to (10) (9)→(10): Use equation ( 1 ) (1) (1).
-
( 11 ) → ( 12 ) (11) \to (12) (11)→(12): each term f j ( y i − 1 , y i , x ˉ ) f_j(y_{i-1}, y_i, \bar x) fj(yi−1,yi,xˉ) is only related to y i − 1 y_{i-1} yi−1 and y i y_i yi.
-
In the equation ( 13 ) (13) (13), the only unknown term is p ( y i − 1 , y i ∣ x ˉ ; w ) p(y_{i-1}, y_i| \bar x; w) p(yi−1,yi∣xˉ;w). Let’s now see how to compute it.
Compute Z ( x ˉ , w ) Z(\bar x, w) Z(xˉ,w)
Z ( x ˉ , w ) = ∑ y ˉ exp [ ∑ j = 1 J w j F j ( x ˉ , y ˉ ) ] = ∑ y ˉ exp [ ∑ j = 1 J w j ∑ i = 2 T f j ( y i − 1 , y i , x ˉ ) ] = ∑ y ˉ [ exp ∑ i = 2 T g i ( y i − 1 , y i ) ] ( 14 ) \begin{aligned} Z(\bar x, w) &= \sum_{\bar y} \exp \left[\sum_{j=1}^J w_{j} F_{j}\left(\bar x, \bar y \right)\right] \\ &= \sum_{\bar y} \exp \left[\sum_{j=1}^J w_{j} \sum_{i=2}^T f_j(y_{i-1}, y_i, \bar x)\right] \\ &= \sum_{\bar y} \left[\exp \sum_{i=2}^T g_i(y_{i-1}, y_i)\right] && (14) \end{aligned} Z(xˉ,w)=yˉ∑exp[j=1∑JwjFj(xˉ,yˉ)]=yˉ∑exp[j=1∑Jwji=2∑Tfj(yi−1,yi,xˉ)]=yˉ∑[expi=2∑Tgi(yi−1,yi)](14)
We see the term g i ( y i − 1 , y i ) g_i(y_{i-1}, y_i) gi(yi−1,yi) in the equation ( 14 ) (14) (14) again, and ( 14 ) (14) (14) is the sum of [ exp ∑ i = 2 T g i ( y i − 1 , y i ) ] \left[\exp \sum_{i=2}^T g_i(y_{i-1}, y_i)\right] [exp∑i=2Tgi(yi−1,yi)] over all y y y. If we list all the possibilities, the time complexity is O ( m T ) O(m^T) O(mT), which is not acceptable. So we should solve it in a similar way like what we did in the inference section (Dynamic Programming). There are two ways to solve it: forward algorithm and backward algorithm. Note that this is very similar to HMM we discussed before.
Forward Algorithm

Let α ( k , v ) \alpha(k,v) α(k,v) denote the sum of all possible paths from t = 1 t=1 t=1 to t = k t=k t=k, where the tag of time k k k is v v v. Then the recursion formula can be easily visualized from the above figure and we can write it as
α ( k , v ) = max s [ α ( k − 1 , s ) ⋅ exp g k ( s , v ) ] \alpha(k,v) = \underset{s}{\operatorname{max}} \left[\alpha(k-1, s) \cdot \text{exp}\, g_k(s,v)\right] α(k,v)=smax[α(k−1,s)⋅expgk(s,v)]
where s ∈ { 1 , 2 , . . . , m } s \in \{1,2,...,m\} s∈{1,2,...,m}. Then, we can write Z ( x ˉ , w ) Z(\bar x, w) Z(xˉ,w) as
Z ( x ˉ , w ) = ∑ s = 1 m α ( T , s ) Z(\bar x, w) = \sum_{s=1}^m \alpha(T, s) Z(xˉ,w)=s=1∑mα(T,s)
Backward Algorithm
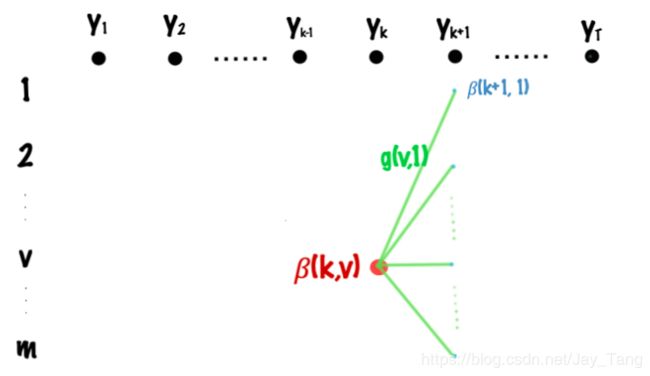
Let β ( k , v ) \beta(k,v) β(k,v) denote the sum of all possible paths from t = k t=k t=k to t = T t=T t=T, where the tag of time t t t is v v v. Then the recursion formula can be easily visualized from the above figure and we can write it as
β ( k , v ) = max s [ β ( k + 1 , s ) ⋅ exp g k + 1 ( v , s ) ] \beta(k,v) = \underset{s}{\operatorname{max}} \left[\beta(k+1, s) \cdot \text{exp}\, g_{k+1}(v,s)\right] β(k,v)=smax[β(k+1,s)⋅expgk+1(v,s)]
where s ∈ { 1 , 2 , . . . , m } s \in \{1,2,...,m\} s∈{1,2,...,m}. Then, we can write Z ( x ˉ , w ) Z(\bar x, w) Z(xˉ,w) as
Z ( x ˉ , w ) = ∑ s = 1 m β ( 1 , s ) Z(\bar x, w) = \sum_{s=1}^m \beta(1, s) Z(xˉ,w)=s=1∑mβ(1,s)
Compute p ( y k = u ∣ x ˉ ; w ) p(y_k=u|\bar x; w) p(yk=u∣xˉ;w)
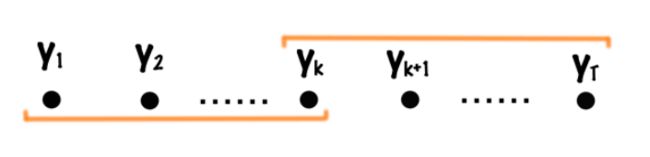
From the figure above, we can divide it into the product of a forward term and a backward term:
p ( y k = u ∣ x ˉ ; w ) = α ( k , u ) ⋅ β ( k , u ) Z ( x ˉ , w ) p(y_k=u|\bar x; w) = \frac{\alpha(k,u)\cdot \beta(k,u)}{Z(\bar x, w)} p(yk=u∣xˉ;w)=Z(xˉ,w)α(k,u)⋅β(k,u)
where
Z ( x ˉ , w ) = ∑ u α ( k , u ) ⋅ β ( k , u ) Z(\bar x, w) = \sum_u \alpha(k,u)\cdot \beta(k,u) Z(xˉ,w)=u∑α(k,u)⋅β(k,u)
- Note that we can also compute Z ( x ˉ , w ) Z(\bar x, w) Z(xˉ,w) by write it as a product of an α \alpha α term and a β \beta β term.
Compute p ( y k = u , y k + 1 = v ∣ x ˉ ; w ) p(y_k=u, y_{k+1}=v|\bar x; w) p(yk=u,yk+1=v∣xˉ;w)
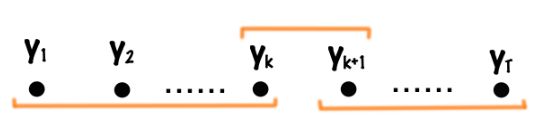
From the figure above, we can divide it into the product of a forward term, a backward term, and an term that represent the path going from y k = u y_k=u yk=u to y k + 1 = v y_{k+1}= v yk+1=v:
p ( y k = u , y k + 1 = v ∣ x ˉ ; w ) = α ( k , u ) ⋅ [ exp g k + 1 ( u , v ) ] ⋅ β ( k + 1 , v ) Z ( x ˉ , w ) p(y_k=u, y_{k+1}=v|\bar x; w) = \frac{\alpha(k,u)\cdot [\text{exp} \, g_{k+1} (u,v)] \cdot\beta(k+1,v)}{Z(\bar x, w)} p(yk=u,yk+1=v∣xˉ;w)=Z(xˉ,w)α(k,u)⋅[expgk+1(u,v)]⋅β(k+1,v)
where
Z ( x ˉ , w ) = ∑ u ∑ v α ( k , u ) ⋅ [ exp g k + 1 ( u , v ) ] ⋅ β ( k + 1 , v ) Z(\bar x, w) = \sum_u \sum_v \alpha(k,u)\cdot [\text{exp} \, g_{k+1} (u,v)] \cdot\beta(k+1,v) Z(xˉ,w)=u∑v∑α(k,u)⋅[expgk+1(u,v)]⋅β(k+1,v)
Now go back to where we stopped (equation ( 13 ) (13) (13)), and use what we just derived above, we have
∂ ∂ w j [ log p ( y ˉ ∣ x ˉ ; w ) ] = F j ( x ˉ , y ˉ ) − ∑ i = 2 T ∑ y i − 1 ∑ y i f j ( y i − 1 , y i , x ˉ ) ⋅ p ( y i − 1 , y i ∣ x ˉ ; w ) = F j ( x ˉ , y ˉ ) − ∑ i = 2 T ∑ y i − 1 ∑ y i f j ( y i − 1 , y i , x ˉ ) ⋅ α ( i − 1 , y i − 1 ) ⋅ [ exp g i ( y i − 1 , y i ) ] ⋅ β ( i , y 1 ) Z ( x ˉ , w ) ( 15 ) \begin{aligned} \frac{\partial}{\partial w_j} [\log p(\bar y| \bar x; w)] &= F_{j}\left(\bar x, \bar y\right) - \sum_{i=2}^T \sum_{y_{i-1}} \sum_{y_{i}} f_j(y_{i-1}, y_i, \bar x) \cdot p(y_{i-1}, y_i| \bar x; w) \\ &= F_{j}\left(\bar x, \bar y\right) - \sum_{i=2}^T \sum_{y_{i-1}} \sum_{y_{i}} f_j(y_{i-1}, y_i, \bar x) \cdot \frac{\alpha(i-1,y_{i-1})\cdot [\text{exp} \, g_{i} (y_{i-1},y_i)] \cdot\beta(i,y_1)}{Z(\bar x, w)} &&(15) \end{aligned} ∂wj∂[logp(yˉ∣xˉ;w)]=Fj(xˉ,yˉ)−i=2∑Tyi−1∑yi∑fj(yi−1,yi,xˉ)⋅p(yi−1,yi∣xˉ;w)=Fj(xˉ,yˉ)−i=2∑Tyi−1∑yi∑fj(yi−1,yi,xˉ)⋅Z(xˉ,w)α(i−1,yi−1)⋅[expgi(yi−1,yi)]⋅β(i,y1)(15)
Now every term in the equation ( 15 ) (15) (15) is known. So we can use SGD to update the parameter w w w.
Reference:
- https://ermongroup.github.io/cs228-notes/representation/undirected/
- http://cseweb.ucsd.edu/~elkan/250B/CRFs.pdf
- http://homepages.inf.ed.ac.uk/csutton/publications/crftut-fnt.pdf
- http://cseweb.ucsd.edu/~elkan/250Bfall2007/loglinear.pdf