MegDet: A Large Mini-Batch Object Detector「CVPR 2018」
基于Megdet 模型的目标检测框架
- 论文 | A Large Mini-Batch Object Detector
- 链接 | https://arxiv.org/abs/1711.07240
- 作者 | Chao Peng Tete Xiao Zeming Li
相关阅读:
- https://blog.csdn.net/np4rHI455vg29y2/article/details/78954803
- http://www.sohu.com/a/209995026_610300
- ppt:链接: https://pan.baidu.com/s/1pIYshTWU9aONyuuRk-YZTQ 密码: mvd8
- 视频回放:https://v.douyu.com/show/zBjq4Mepw4Q75Ea8
论文贡献:
(1)提出了linear scaling rule的新的解释;
(2)训练BN;(Imagenet和coco还是不一样的!)
(3)哈哈,用128块GPU在4小时内完成训练,大写的有钱!
(4)夺冠了~需要鼓掌~~
设计思想:
之前物体检测提升的策略主要关注:网络设计、框架设计、损失涉及,而训练部分关注很少,因此作者从大Mini-Batch的运用 和Batch Normalizatio(BN)的训练技巧出发,在训练方法上实现了突破,从而赢得了COCO 2017物体检测冠军。
small-batchsize缺陷:
-
不稳定的梯度。由于Batch-Size较小,每次迭代生成的梯度的变化会非常大,这会导致SGD算法在一个区域内来回震荡,不易收敛到局部最优值。
-
BN层统计不准确。由于Batch-Size较小,难以满足BN层的统计需求,人们常常在训练过程中固定住BN层的参数,这意味着BN层还保持着ImageNet数据集中的设置,但其余参数却是COCO这个数据集的拟合结果。这种模型内部的参数不匹配会影响最后的检测结果。
-
正负样本比例失调。由于Batch-Size较小,一个minibatch之中的图片变化可能非常大,很可能某些阶段正样本框只有个位数。当Batch-Size增大的时候,由于一个minibatch内部的图片数量增加,正负样本比例会优于小Batch-Size的情况。
-
超长的训练时间。这个原因非常好理解:当Batch-Size较小时,我们必须迭代更多的次数来让算法收敛;随着Batch-Size的增加,算法每次迭代见过的图片数量也随之增长,相应的迭代次数就可以下降,人们也能更快地得到结果。
Learning Rate for Large Mini-Batch
学习率和SGD算法密切相关。大mini-batch的设计还涉及到学习率的调整问题。传统的方法是:mini-batch增加 k 倍,学习率也增加倍。但已有的分析方法却较为简单,并不适用于物体检测中的先k决条件。
作者在文章中,针对这个点进行了详细的概率分析,指出了这种调节方法的理论正确性。另一方面,也借鉴了文献[3]的方法,采用线性增长学习率的方法来做热启动训练(warm-up)。
在大Batch-Size下的学习率调参技巧。16-batch的FPN标准学习率是0.02, 而我们的MegDet的Batch-Size是256。在这种情况下,我们如果直接设定学习率为0.32=0.02 x 16,会导致模型早期迅速发散,无法完成训练。因此,我们需要有一个“逐步预热”的过程,让模型逐渐适应较大的学习率。当训练到一定阶段的时候,我们设定了三个下降阶段:在前两个阶段,我们直接将学习率除以10,最后再将学习率减半。这种学习率的设计主要是为了在比赛中取得极致性能,也是我们的经验所得。
Cross-GPU Batch Normalization
BN(Batch Normalization)[1]是现代卷积神经网络的重要模块,特别是针对一些较深的网络的训练,如ResNet-101和ResNeXt-101。BN训练的一个要点在于统计的图片数量需要大于等于16,最优是32。在现有的图像检测模型之中,由于图片的尺寸非常大(短边800),一块GPU很难容纳足够多的图片。一般而言,现有的12GB GPU在图像检测任务中只能放两张图,远达不到16或32的计算需求。但在一台8卡机器上,整台机器总的mini-batch数量是满足了BN需求的,因此一个现有的折中方案是合并8张卡上的所有图片,然后再计算BN层的参数。
简单来讲,已有的BN统计方法局限于统计单张卡上的图片,做不到多张卡联合统计。由于物体检测本身的特性,单张卡上的图片数量达不到BN统计的要求,因此只能通过多卡联合统计来训练得到结果。为此,我们利用了NCCL(NVIDIA Collective Communications Library)代码库,实现了多卡BN。具体的算法流程可以参照上图,首先通过单卡自主统计BN的参数,再将参数发送到单张卡上进行合并,最后再把BN的结果同步到其他卡上,以进行下一步的训练。
根据BN的计算逻辑,作者设计了如下图所示的跨卡BN(Cross-GPU Batch Normalization, CGBN)。首先,CGBN会优先计算每张卡上feature之和 ,然后同步 s1⋯n 所有卡的数据得到mini-batch的均值。类似地,CGBN会再在每张卡上计算方差和 v1....n,同步所有卡的数据得到mini-batch的方差 。最后再根据BN的计算方法,输出最终结果 y1⋯n 。

设计理念:
Mini-Batch是机器学习中SGD算法的一个概念。在机器学习发展的早期,由于数据 集通常非常小,人们往往会把整个数据集过一遍,求得一个梯度向量并做相应的参数更新。到了21世纪,由于数据采集和标注的成本持续下降,数据量呈现了指数级爆发 增长的趋势,传统的梯度下降算法不再适用,人们往往会随机采样一个mini-batch,并计算该mini-batch的梯度来更新参数。现有的图像分类模型的mini-batch相对较大,例 如128、256、乃至最新的32K张图片。较大的mini-batch不仅能加快训练速度,也能对数据的整体分布拥有一个较好的近似,使得参数更新更有效率。在现有的物体检测算法之中,人们采用的mini-batch相对较小,一般是2、8和16。对于一些较小的数据集, 如VOC 2012,这个数量级的mini-batch基本是合理的;但对于更大的数据集,比如COCO Detection,16的mini-batch就会相对较小。这不仅会导致较长的训练时间,也会引起每个mini-batch的数据分布变化极端,导致每次梯度计算和参数更新的不准确。特 别地,在物体检测之中,正负样本的比例分布会随着图片的变化发生剧烈改变(见图2),较小的mini-batch必然会导致正负样本比例非常不均衡。
具体的统计结果参见表1。

为了解决物体检测问题中的小mini-batch问题,作者实现了sublinear-memory和多机训练系统。sublinear-memory[2]是一种节约GPU显存的技术,它通过舍弃一些网络中间层 的结果来减少显存使用量。多机训练系统则是一种动态扩容的方案,虽然一台机器上 可插GPU的数量是有限的,但组建一个集群的机器数量相对而言是不受限制的。这样 ,我们就可以通过增加机器数量来动态地增加mini-batch的大小。为了保持和单机训练 环境一致,作者采用的是同步更新策略,即每台机器计算之后会马上同步梯度值,再进行参数更新。
大mini-batch的设计还涉及到学习率的调整问题。传统的方法是:mini-batch增加 k 倍,学习率也增加倍。但已有的分析方法却较为简单,并不适用于物体检测中的先k决条件。作者在文章中,针对这个点进行了详细的概率分析,指出了这种调节方法的理论正确性。另一方面,也借鉴了文献[3]的方法,采用线性增长学习率的方法来做热启动训练(warm-up)。
实验效果:
在实验方面,作者设计了两组基于COCO Detection数据集的试验,实验的基础网络是ResNet-50 [4],物体检测所用框架是FPN[5]。在第一组实验之中,通过采用通用的训练 技巧——即锁住BN层进行训练,当mini-batch从16增加到32之后,物体检测的精度便得到了一定的提升,训练速度更是达到了几乎线性的增长。但当我们把 mini-batch增加到64时,现有的训练方法已经无法完整训练完COCO Detection,即便我们使用了热启动策略。此时,若我们使用32 mini-batch的学习率,会得到一个较差的结果。详细结果见表2

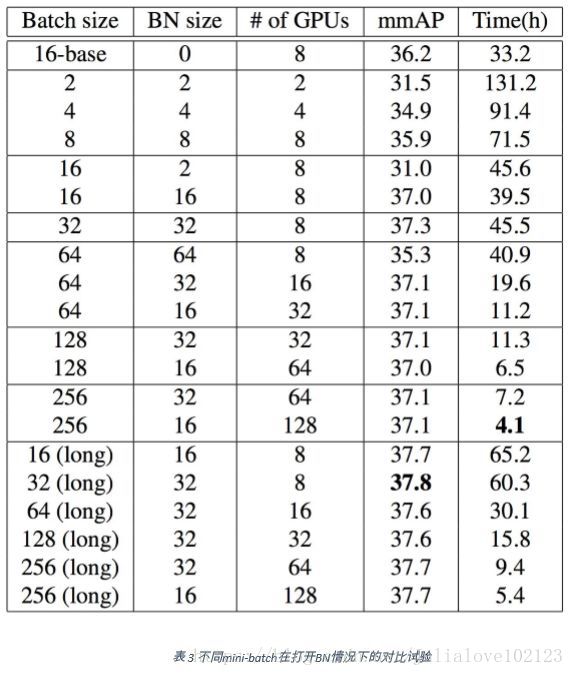
针对开启BN的试验,作者的实验结果如表3所示。不难发现,当BN统计的 mini-batch小于16时,会产生不同程度的性能衰退。特别是在单卡计算BN的时候(第六行),会比相同条件下的跨卡BN低6个点(31.0 VS 37.0)。其次,我们发现,在打开 BN训练的时候,我们可以无障碍训练更大的mini-batch,而这在没有BN的情况下是无 法实现的。 在打开了BN训练的时候,我们比较了不同mini-batch的性能比较。不难发现,随着mini-batch的增长,物体检测的精度并没有出现明显的变化,甚至基本保持不变。但与此同时,训练的时间却几乎线性下降。特别是在256-batch的设置下,我们仅用4小时 就完成了COCO数据的训练。 实验的最后,作者尝试了增加三分之一的训练时间。结果表明,在不同的 mini-batch设置下,增加时间均能提高性能,但显然在大mini-batch下的时间成本更低 ,更有利于获得更好的模型性能。
文章末尾,作者还比较了不用mini-batch设置下,每个epoch的模型精度,见图3。不难发现,在不同mini-batch(16 VS 256)下,模型精度的变化是不一致的,两者的曲线中间有一个明显的分隔区间,此处的观察和图像分类在ImageNet数据集上的表现非常不 同。
一般而言,当人们增大mini-batch的时候,同等epoch下的模型精度应该保持基本不变。但在物体检测这个任务上,这条经验法则并不成立,较大的mini-batch会在初期保持一个较低水平的精度,但最终还是会收敛到同一水平。

相关名词解释:
1、Linear Scaling Rule
- http://www.sohu.com/a/219057450_129720
- https://www.leiphone.com/news/201710/RIIlL7LdIlT1Mvm8.html
- https://www.zhihu.com/question/64134994/answer/216895968
2、Gradient Equivalence Assumption
3、Warmup Strategy
4、Astrous Convolution
- https://www.zhihu.com/question/54149221
5、ROIAlign
- https://blog.csdn.net/jningwei/article/details/78822159
- http://blog.leanote.com/post/[email protected]/b5f4f526490b
- https://blog.csdn.net/lanyuxuan100/article/details/71124596