python web面试题整理-从放弃到入门-day03
第一部分Python基础题(80)
41.def func(a,b=[]) 这种写法有什么坑?
def func(a,b=[]):
b.append(a)
print(b)
func(1)
func(1)
func(1)
func(1)
结果
[1]
[1, 1]
[1, 1, 1]
[1, 1, 1, 1]
函数的第二个默认参数是一个list,当第一次执行的时候实例化了一个list,
第二次执行还是用第一次执行的时候实例化的地址存储,
所以三次执行的结果就是 [1, 1, 1] ,想每次执行只输出[1] ,
默认参数应该设置为None。
42.如何实现 “1,2,3” 变成 [‘1’,’2’,’3’] ?
a='1,2,3'
b=a.split(',')
print(b)
['1', '2', '3']
43.如何实现[‘1’,’2’,’3’]变成[1,2,3] ?
a = ['1', '2', '3']
b = [int(i) for i in a]
print(b)
print(list(map(int,['1','2','3'])))
[1, 2, 3]
44.比较: a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的区别?
a = [1,2,3]
b1 = [(1),(2),(3)]
b2 = [(1,),(2,),(3,)]
print(a) #[1, 2, 3]
print(b1) #[1, 2, 3]
print(b2) #[(1,), (2,), (3,)]
print(a==b1) #True
print(a==b2) #False
print(a is b1) #False
print(a is b2) #False
45.如何用一行代码生成[1,4,9,16,25,36,49,64,81,100] ?
a=[i*i for i in range(1,11)]
46.一行代码实现删除列表中重复的值 ?
优先参考第一种
#想按照之前list列表顺序显示
list0=['b','c', 'd','b','c','a','a']
print(sorted(set(list0),key=list0.index)) # sorted output
>>>['b', 'c', 'd', 'a']
list3=list(set(list0))
list3.sort(key=list0.index)
print(list3)
>>>['b', 'c', 'd', 'a']
list0=['b','c', 'd','b','c','a','a']
print(set(list0))
>>>{'d', 'c', 'b', 'a'}#随机的字典
#方法2:使用 {}.fromkeys().keys()
list0=['b','c', 'd','b','c','a','a']
list2={}.fromkeys(list0).keys()
print(list2)
print(list(list2))
>>>dict_keys(['b', 'c', 'd', 'a'])
>>>['b', 'c', 'd', 'a']
#方法3:迭代
list0=['b','c', 'd','b','c','a','a']
list4=[]
for i in list0:
if not i in list4:
list4.append(i)
print(list4)
>>>['b', 'c', 'd', 'a']
47.如何在函数中设置一个全局变量 ?
在函数的内部,通过global声明,使在函数内部中设置一个全局变量,这个全局变量可以在任意的函数中进行调用!
SOLR_URL='http://solr.org'
def tt():
global SOLR_URL
SOLR_URL=SOLR_URL+'#aa'
def aa():
if __name__=='__main__':
tt()
print(SOLR_URL)
aa() # http://solr.org#aa
48.logging模块的作用?以及应用场景?
通过log的分析,可以方便用户了解系统或软件、应用的运行情况;如果你的应用log足够丰富,也可以分析以往用户的操作行为、类型喜好、地域分布或其他更多信息;如果一个应用的log同时也分了多个级别,那么可以很轻易地分析得到该应用的健康状况,及时发现问题并快速定位、解决问题,补救损失。
简单来讲就是,我们通过记录和分析日志可以了解一个系统或软件程序运行情况是否正常,也可以在应用程序出现故障时快速定位问题。比如,做运维的同学,在接收到报警或各种问题反馈后,进行问题排查时通常都会先去看各种日志,大部分问题都可以在日志中找到答案。再比如,做开发的同学,可以通过IDE控制台上输出的各种日志进行程序调试。对于运维老司机或者有经验的开发人员,可以快速的通过日志定位到问题的根源。可见,日志的重要性不可小觑。日志的作用可以简单总结为以下3点:
程序调试
了解软件程序运行情况,是否正常
软件程序运行故障分析与问题定位
如果应用的日志信息足够详细和丰富,还可以用来做用户行为分析,如:分析用户的操作行为、类型洗好、地域分布以及其它更多的信息,由此可以实现改进业务、提高商业利益。
logging模块默认定义了以下几个日志等级,它允许开发人员自定义其他日志级别,但是这是不被推荐的,尤其是在开发供别人使用的库时,因为这会导致日志级别的混乱。
日志等级(level) 描述
DEBUG 最详细的日志信息,典型应用场景是 问题诊断
INFO 信息详细程度仅次于DEBUG,通常只记录关键节点信息,用于确认一切都是按照我们预期的那样进行工作
WARNING 当某些不期望的事情发生时记录的信息(如,磁盘可用空间较低),但是此时应用程序还是正常运行的
ERROR 由于一个更严重的问题导致某些功能不能正常运行时记录的信息
CRITICAL 当发生严重错误,导致应用程序不能继续运行时记录的信息
开发应用程序或部署开发环境时,可以使用DEBUG或INFO级别的日志获取尽可能详细的日志信息来进行开发或部署调试;应用上线或部署生产环境时,应该使用WARNING或ERROR或CRITICAL级别的日志来降低机器的I/O压力和提高获取错误日志信息的效率。日志级别的指定通常都是在应用程序的配置文件中进行指定的。
说明:
上面列表中的日志等级是从上到下依次升高的,
即:DEBUG < INFO < WARNING < ERROR < CRITICAL,而日志的信息量是依次减少的;
当为某个应用程序指定一个日志级别后,应用程序会记录所有日志级别大于或等于指定日志级别的日志信息,而不是仅仅记录指定级别的日志信息,nginx、php等应用程序以及这里要提高的python的logging模块都是这样的。同样,logging模块也可以指定日志记录器的日志级别,只有级别大于或等于该指定日志级别的日志记录才会被输出,小于该等级的日志记录将会被丢弃。
参考别人博客
49.请用代码简答实现stack 。
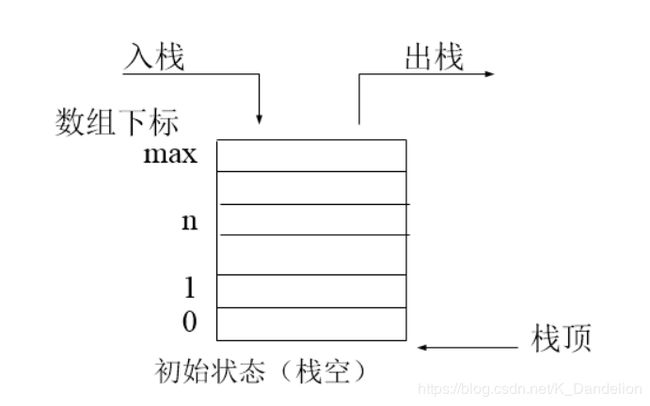
栈和队列是两种基本的数据结构,同为容器类型。两者根本的区别在于:
stack:后进先出
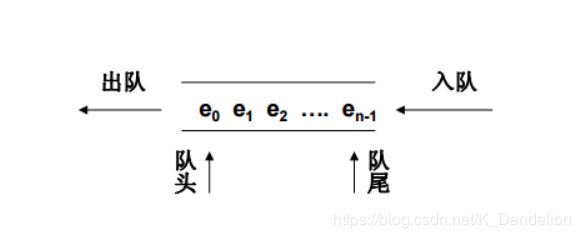
 queue:先进先出
queue:先进先出
 PS:stack和queue是不能通过查询具体某一个位置的元素而进行操作的。但是他们的排列是按顺序的
PS:stack和queue是不能通过查询具体某一个位置的元素而进行操作的。但是他们的排列是按顺序的
对于stack我们可以使用python内置的list实现,因为list是属于线性数组,在末尾插入和删除一个元素所使用的时间都是O(1),这非常符合stack的要求。当然,我们也可以使用链表来实现。
stack的实现代码(使用python内置的list),实现起来是非常的简单,就是list的一些常用操作
class Stack(object):
def __init__(self):
self.stack = []
def push(self, value): # 进栈
self.stack.append(value)
def pop(self): #出栈
if self.stack:
self.stack.pop()
else:
raise LookupError('stack is empty!')
def is_empty(self): # 如果栈为空
return bool(self.stack)
def top(self):
#取出目前stack中最新的元素
return self.stack[-1]
我们定义如下的链表来实现队列数据结构:
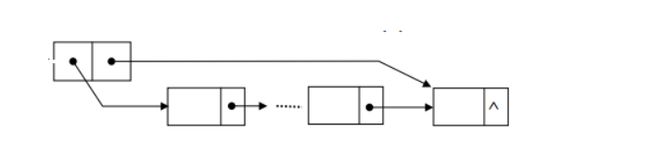 定义一个头结点,左边指向队列的开头,右边指向队列的末尾,这样就可以保证我们插入一个元素和取出一个元素都是O(1)的操作,使用这种链表实现stack也是非常的方便。实现代码如下:
定义一个头结点,左边指向队列的开头,右边指向队列的末尾,这样就可以保证我们插入一个元素和取出一个元素都是O(1)的操作,使用这种链表实现stack也是非常的方便。实现代码如下:
class Head(object):
def __init__(self):
self.left = None
self.right = None
class Node(object):
def __init__(self, value):
self.value = value
self.next = None
class Queue(object):
def __init__(self):
#初始化节点
self.head = Head()
def enqueue(self, value):
#插入一个元素
newnode = Node(value)
p = self.head
if p.right:
#如果head节点的右边不为None
#说明队列中已经有元素了
#就执行下列的操作
temp = p.right
p.right = newnode
temp.next = newnode
else:
#这说明队列为空,插入第一个元素
p.right = newnode
p.left = newnode
def dequeue(self):
#取出一个元素
p = self.head
if p.left and (p.left == p.right):
#说明队列中已经有元素
#但是这是最后一个元素
temp = p.left
p.left = p.right = None
return temp.value
elif p.left and (p.left != p.right):
#说明队列中有元素,而且不止一个
temp = p.left
p.left = temp.next
return temp.value
else:
#说明队列为空
#抛出查询错误
raise LookupError('queue is empty!')
def is_empty(self):
if self.head.left:
return False
else:
return True
def top(self):
#查询目前队列中最早入队的元素
if self.head.left:
return self.head.left.value
else:
raise LookupError('queue is empty!')
50.常用字符串格式化哪几种?
Python的字符串格式化常用的有三种!-
第一种:最方便的
缺点:需一个个的格式化
print('hello %s and %s'%('df','another df'))
第二种:最好用的
优点:不需要一个个的格式化,可以利用字典的方式,缩短时间
print('hello %(first)s and %(second)s'%{'first':'df' , 'second':'another df'})
第三种:最先进的
优点:可读性强
print('hello {first} and {second}'.format(first='df',second='another df'))
51.简述 生成器、迭代器、可迭代对象 以及应用场景?
迭代器:是访问集合元素的一种方式,从集合的第一个元素开始访问,直到所有元素被访问结束。其优点是不需要事先准备好整个迭代过程中的所有元素,仅在迭代到某个元素时才开始计算该元素。适合遍历比较巨大的集合。iter():方法返回迭代器本身, next():方法用于返回容器中下一个元素或数据。
生成器:带有yield的函数不再是一个普通函数,而是一个生成器。当函数被调用时,返回一个生成器对象。不像一般函数在生成值后退出,生成器函数在生成值后会自动挂起并暂停他们的执行状态。
'''迭代器'''
print('for x in iter([1, 2, 3, 4, 5]):')
for x in iter([1, 2, 3, 4, 5]):
print(x)
'''生成器'''
def myyield(n):
while n>0:
print("开始生成...:")
yield n
print("完成一次...:")
n -= 1
for i in myyield(4):
print("遍历得到的值:",i)
52.用Python实现一个二分查找的函数。
data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35]
def binary_search(dataset,find_num):
if len(dataset) > 1:
mid = int(len(dataset) / 2)
if dataset[mid] == find_num: # find it
print("找到数字", dataset[mid])
elif dataset[mid] > find_num: # 找的数在mid左面
print("\033[31;1m找的数在mid[%s]左面\033[0m" % dataset[mid])
return binary_search(dataset[0:mid], find_num)
else: # 找的数在mid右面
print("\033[32;1m找的数在mid[%s]右面\033[0m" % dataset[mid])
return binary_search(dataset[mid + 1:], find_num)
else:
if dataset[0] == find_num: # find it
print("找到数字啦", dataset[0])
else:
print("没的分了,要找的数字[%s]不在列表里" % find_num)
binary_search(data,20)

53.谈谈你对闭包的理解?
再说说闭包之前,先说一说什么是外函数,什么是内函数?
外函数:函数A的内部定义了函数B,那么函数A就叫做外函数 内函数:函数B就叫做内函数
什么是闭包?
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。**
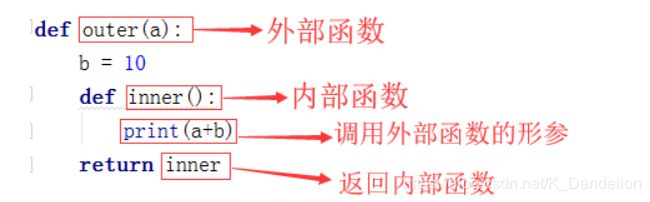 一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
def outer(a):
b = 10
def inner():
print(a+b)
return inner
if __name__ == '__main__':
demo = outer(5)
demo()
demo2 = outer(7)
demo2()
15
17
54.os和sys模块的作用?
sys模块主要是用于提供对python解释器相关的操作
函数
sys.argv #命令行参数List,第一个元素是程序本身路径
sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.modules.keys() #返回所有已经导入的模块列表
sys.modules #返回系统导入的模块字段,key是模块名,value是模块
sys.exc_info() #获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息
sys.exit(n) #退出程序,正常退出时exit(0)
sys.hexversion #获取Python解释程序的版本值,16进制格式如:0x020403F0
sys.version #获取Python解释程序的版本信息
sys.platform #返回操作系统平台名称
sys.maxint # 最大的Int值
sys.stdout #标准输出
sys.stdout.write('aaa') #标准输出内容
sys.stdout.writelines() #无换行输出
sys.stdin #标准输入
sys.stdin.read() #输入一行
sys.stderr #错误输出
sys.exc_clear() #用来清除当前线程所出现的当前的或最近的错误信息
sys.exec_prefix #返回平台独立的python文件安装的位置
sys.byteorder #本地字节规则的指示器,big-endian平台的值是'big',little-endian平台的值是'little'
sys.copyright #记录python版权相关的东西
sys.api_version #解释器的C的API版本
sys.version_info #'final'表示最终,也有'candidate'表示候选,表示版本级别,是否有后继的发行
sys.getdefaultencoding() #返回当前你所用的默认的字符编码格式
sys.getfilesystemencoding() #返回将Unicode文件名转换成系统文件名的编码的名字
sys.builtin_module_names #Python解释器导入的内建模块列表
sys.executable #Python解释程序路径
sys.getwindowsversion() #获取Windows的版本
sys.stdin.readline() #从标准输入读一行,sys.stdout.write("a") 屏幕输出a
sys.setdefaultencoding(name) #用来设置当前默认的字符编码(详细使用参考文档)
sys.displayhook(value) #如果value非空,这个函数会把他输出到sys.stdout(详细使用参考文档)
常用功能
sys.arg 获取位置参数
print(sys.argv)
执行该脚本,加参数的打印结果
python3 m_sys.py 1 2 3 4 5
['m_sys.py', '1', '2', '3', '4', '5']
可以发现 sys.arg返回的是整个位置参数,类似于shell的$0 $1...
sys.exit(n) 程序退出,n是退出是返回的对象
sys.version 获取python版本
>>> sys.version
'3.5.1 (v3.5.1:37a07cee5969, Dec 5 2015, 21:12:44) \n[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)]'
sys.path 返回模块的搜索路径列表,可通过添加自定义路径,来添加自定义模块
>>> sys.path
['', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python35.zip', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/plat-darwin', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages']
sys.platform 返回当前系统平台 linux平台返回linux,windows平台返回win32,MAC返回darwin
>>> sys.platform
'darwin
sys.stdout.write() 输出内容
>>> sys.stdout.write('asd')
asd3
>>> sys.stdout.write('asd')
asd3
>>> sys.stdout.write('as')
as2
应用:
进度条:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
#pyversion:python3.5
#owner:酸奶
"""
sys 和python解析器相关
"""
import sys
import time
def view_bar(num,total):
rate = num / total
rate_num = int(rate * 100)
#r = '\r %d%%' %(rate_num)
r = '\r%s>%d%%' % ('=' * rate_num, rate_num,)
sys.stdout.write(r)
sys.stdout.flush
if __name__ == '__main__':
for i in range(0, 101):
time.sleep(0.1)
view_bar(i, 100)
====================================================================================================>100%
os模块
OS模块是Python标准库中的一个用于访问操作系统功能的模块,使用OS模块中提供的接口,可以实现跨平台访问
用于提供系统级别的操作
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dir1/dir2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","new") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 操作系统特定的路径分隔符,win下为"\",Linux下为"/"
os.linesep 当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 用于分割文件路径的字符串
os.name 字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.lexists #路径存在则返回True,路径损坏也返回True
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.commonprefix(list) #返回list(多个路径)中,所有path共有的最长的路径。
os.path.expanduser(path) #把path中包含的"~"和"~user"转换成用户目录
os.path.expandvars(path) #根据环境变量的值替换path中包含的”$name”和”${name}”
os.access('pathfile',os.W_OK) 检验文件权限模式,输出True,False
os.chmod('pathfile',os.W_OK) 改变文件权限模式
55.如何生成一个随机数?
random模块
- 随机整数:random.randint(a,b):返回随机整数x,a<=x<=b
random.randrange(start,stop,[,step]):返回一个范围在(start,stop,step)之间的随机整数,不包括结束值。
- 随机实数:random.random( ):返回0到1之间的浮点数
- random.uniform(a,b):返回指定范围内的浮点数。
import random # 随机模块
data = list(range(10))
print(data) # 打印有序的列表 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
random.shuffle(data) # 使有序变为无序
print(data) # 打印无序的列表 [4, 2, 5, 1, 6, 3, 9, 8, 0, 7]
56.如何使用python删除一个文件?
若想利用python删除windows里的文件,这里需要使用os模块!那接下来就看看利用os模块是如何删除文件的!
具体实现方法如下!
os.remove(path)
删除文件 path. 如果path是一个目录, 抛出 OSError错误。如果要删除目录,请使用rmdir().
remove() 同 unlink() 的功能是一样的
在Windows系统中,删除一个正在使用的文件,将抛出异常。在Unix中,目录表中的记录被删除,但文件的存储还在。
import os
my_file = 'D:/text.txt' # 文件路径
if os.path.exists(my_file): # 如果文件存在
#删除文件,可使用以下两种方法。
os.remove(my_file) # 则删除
#os.unlink(my_file)
else:
print('no such file:%s'%my_file)
>>>no such file:D:/text.txt
os.removedirs(path)
递归地删除目录。类似于rmdir(), 如果子目录被成功删除, removedirs() 将会删除父目录;但子目录没有成功删除,将抛出错误。
例如, os.removedirs(“foo/bar/baz”) 将首先删除baz目录,然后再删除bar和 foo, 如果他们是空的话,则子目录不能成功删除,将抛出 OSError异常
os.rmdir(path)
删除目录 path,要求path必须是个空目录,否则抛出OSError错误
import os
for root, dirs, files in os.walk(top, topdown=False):
for name in files:
os.remove(os.path.join(root, name))
for name in dirs:
os.rmdir(os.path.join(root, name))
方法2:
代码如下:
import shutil
shutil.rmtree()
57.谈谈你对面向对象的理解?
什么是封装?
所谓的面向对象就是将我们的程序模块化,对象化,把具体事物的特性属性和通过这些属性来实现一些动作的具体方法放到一个类里面,这就是封装。封装是我们所说的面相对象编程的特征之一。除此之外还有继承和多态。
什么是继承?
继承有点类似与我们生物学上的遗传,就是子类的一些特征是来源于父类的,儿子遗传了父亲或母亲的一些性格,或者相貌,又或者是运动天赋。有点种瓜得瓜种豆得豆的意思。面向对象里的继承也就是父类的相关的属性,可以被子类重复使用,子类不必再在自己的类里面重新定义一回,父类里有点我们只要拿过来用就好了。而对于自己类里面需要用到的新的属性和方法,子类就可以自己来扩展了。
什么是多态?
我们在有一些方法在父类已经定义好了,但是子类我们自己再用的时候,发现,其实,我们的虽然都是计算工资的,但是普通员工的工资计算方法跟经理的计算方法是不一样的,所以这个时候,我们就不能直接调用父类的这个计算工资的方法了。这个时候我们就需要用到面向对象的另一个特性,多态。我们要在子类里面把父类里面定义计算工资的方法在子类里面重新实现一遍。多态包含了重载和重写。
什么是重写?
重写很简单就是把子类从父亲类里继承下来的方法重新写一遍,这样,父类里相同的方法就被覆盖了,当然啦,你还是可以通过super.CaculSalary方法来调用父类的工资计算方法。
什么是重载?
重载就是类里面相同方法名,不同形参的情况,可以是形参类型不同或者形参个数不同,或者形参顺序不同,但是不能使返回值类型不同。
58.Python面向对象中的继承有什么特点?
继承的优点:
1、建造系统中的类,避免重复操作。
2、新类经常是基于已经存在的类,这样就可以提升代码的复用程度。
继承的特点:
1、在继承中基类的构造(init()方法)不会被自动调用,它需要在其派生类的构造中亲自专门调用。有别于C#
2、在调用基类的方法时,需要加上基类的类名前缀,且需要带上self参数变量。区别于在类中调用普通函数时并不需要带上self参数
3、Python总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。
59.面向对象深度优先和广度优先是什么?
二叉树的两种遍历是数据结构的经典考察题目, 广度遍历考察队列结构, 深度遍历考察递归
 深度优先
深度优先
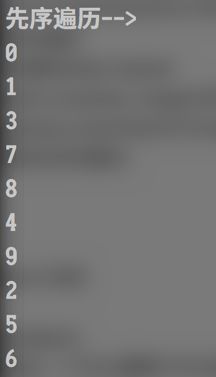
先序遍历(父, 左子, 右子) 0, 1, 3, 7, 8, 4, 9, 2, 5, 6
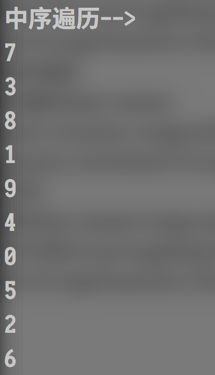
中序遍历(左子, 父, 右子) 7, 3, 8, 1, 9, 4, 0, 5, 2, 6
后序遍历(左子, 右子, 父) 7, 8, 3, 9, 4, 1, 5, 6, 2, 0
"深度优先遍历"考察递归, 将子节点为空作为终止递归的条件
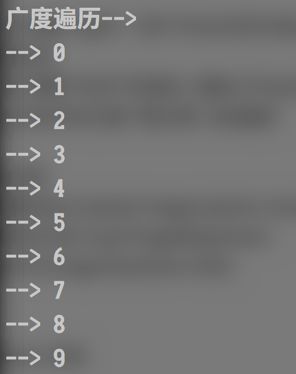
广度优先
"广度优先遍历"考察队列的结构, 消除父节点(出队列,顺便打印), 添加子节点(进队列),
当队列内元素个数为零, 完成遍历
添加元素
广度优先遍历
深度优先
class Node(object):
"""初始化一个节点,需要为节点设置值"""
def __init__(self, val):
self.val = val
self.left = None
self.right = None
class BinaryTree(object):
"""
创建二叉树,完成
- 添加元素
- 广度遍历
- 深度遍历(先序遍历, 中序遍历, 后序遍历)
"""
def __init__(self):
self.root = None
pass
# 添加元素
def addNode(self, val):
# 创建队列结构存储结点
nodeStack = [self.root,]
# 如果根结点为空
if self.root == None:
self.root = Node(val)
print("添加根节点{0}成功!".format(self.root.val))
return
while len(nodeStack) > 0:
# 队列元素出列
p_node = nodeStack.pop()
# 如果左子结点为空
if p_node.left == None:
p_node.left = Node(val)
print("添加左:{0} ".format(p_node.left.val))
return
# 如果右子节点为空
if p_node.right == None:
p_node.right = Node(val)
print("添加右:{0} ".format(p_node.right.val))
return
nodeStack.insert(0, p_node.left)
nodeStack.insert(0, p_node.right)
# 广度遍历(中序: 先读父节点,再读左子节点, 右子节点)
def breadthFirst(self):
nodeStack = [self.root, ];
while len(nodeStack) > 0:
my_node = nodeStack.pop()
print("-->",my_node.val)
if my_node.left is not None:
nodeStack.insert(0, my_node.left)
if my_node.right is not None:
nodeStack.insert(0, my_node.right)
# 深度优先(先序遍历)
def preorder(self, start_node):
if start_node == None:
return
print(start_node.val)
self.preorder(start_node.left)
self.preorder(start_node.right)
# 深度优先(中序遍历)
def inorder(self, start_node):
if start_node == None:
return
self.inorder(start_node.left)
print(start_node.val)
self.inorder(start_node.right)
# 深度优先(后序遍历)
def outorder(self, start_node):
if start_node == None:
return
self.outorder(start_node.left)
self.outorder(start_node.right)
print(start_node.val)
def main():
bt = BinaryTree()
bt.addNode(0)
bt.addNode(1)
bt.addNode(2)
bt.addNode(3)
bt.addNode(4)
bt.addNode(5)
bt.addNode(6)
bt.addNode(7)
bt.addNode(8)
bt.addNode(9)
print("广度遍历-->")
bt.breadthFirst()
print("先序遍历-->")
bt.preorder(bt.root)
print("中序遍历-->")
bt.inorder(bt.root)
print("后序遍历-->")
bt.outorder(bt.root)
if __name__ == '__main__':
main()
60.面向对象中super的作用?
什么是super?
super() 函数是用于调用父类(超类)的一个方法。 super
是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO)、重复调用(钻石继承)等种种问题。
MRO 就是类的方法解析顺序表, 其实也就是继承父类方法时的顺序表。
语法
super(type[, object-or-type])
参数
·type – 类。
·object-or-type – 类,一般是 self
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx :
Python3.x 实例:
class A:
pass
class B(A):
def add(self, x):
super().add(x)
Python2.x 实例:
class A(object): # Python2.x 记得继承 object
pass
class B(A):
def add(self, x):
super(B, self).add(x)
具体应用示例:
class Foo:
def bar(self, message):
print(message)
>>> Foo().bar("Hello, Python.")
Hello, Python.
当存在继承关系的时候,有时候需要在子类中调用父类的方法,此时最简单的方法是把对象调用转换成类调用,需要注意的是这时self参数需要显式传递,例如:
lass FooParent:
def bar(self, message):
print(message)
class FooChild(FooParent):
def bar(self, message):
FooParent.bar(self, message)
>>> FooChild().bar("Hello, Python.")
Hello, Python.
这样做有一些缺点,比如说如果修改了父类名称,那么在子类中会涉及多处修改,另外,Python是允许多继承的语言,如上所示的方法在多继承时就需要重复写多次,显得累赘。为了解决这些问题,Python引入了super()机制,例子代码如下:
class FooParent:
def bar(self, message):
print(message)
class FooChild(FooParent):
def bar(self, message):
super(FooChild, self).bar(message)
>>> FooChild().bar("Hello, Python.")
Hello, Python
表面上看 super(FooChild, self).bar(message)方法和FooParent.bar(self, message)方法的结果是一致的,实际上这两种方法的内部处理机制大大不同,当涉及多继承情况时,就会表现出明显的差异来,直接给例子:
代码一:
class A:
def __init__(self):
print("Enter A")
print("Leave A")
class B(A):
def __init__(self):
print("Enter B")
A.__init__(self)
print("Leave B")
class C(A):
def __init__(self):
print("Enter C")
A.__init__(self)
print("Leave C")
class D(A):
def __init__(self):
print("Enter D")
A.__init__(self)
print("Leave D")
class E(B, C, D):
def __init__(self):
print("Enter E")
B.__init__(self)
C.__init__(self)
D.__init__(self)
print("Leave E")
E()
结果为:
Enter E
Enter B
Enter A
Leave A
Leave B
Enter C
Enter A
Leave A
Leave C
Enter D
Enter A
Leave A
Leave D
Leave E
执行顺序很好理解,唯一需要注意的是公共父类A被执行了多次。
代码二:
class A:
def __init__(self):
print("Enter A")
print("Leave A")
class B(A):
def __init__(self):
print("Enter B")
super(B, self).__init__()
print("Leave B")
class C(A):
def __init__(self):
print("Enter C")
super(C, self).__init__()
print("Leave C")
class D(A):
def __init__(self):
print("Enter D")
super(D, self).__init__()
print("Leave D")
class E(B, C, D):
def __init__(self):
print("Enter E")
super(E, self).__init__()
print("Leave E")
E()
Enter E
Enter B
Enter C
Enter D
Enter A
Leave A
Leave D
Leave C
Leave B
Leave E
在super机制里可以保证公共父类仅被执行一次,至于执行的顺序,是按照MRO(Method Resolution Order):方法解析顺序 进行的。