爬虫3_猫眼TOP100
猫眼TOP100
好多人的爬虫都是从爬取猫眼排行榜,或者爬爬妹子图开始的,我也不例外,今天和大家分享一下猫眼TOP100榜的爬取。
目标网址:https://maoyan.com/board/4
分析url
![]()
还是从第二页开始找,可以看到offset一直是以10的倍数在递增,因为每一个都展示10部电影,所以url就很容易分析出来。
def main():
url = 'http://maoyan.com/board/4?offset={}'
my = MaoYanTop100()
for i in range(10):
# 每次偏移都是10的倍数,这里用了线程池,只是用用好像并没有加快速度
my.threadpool.submit(my.get_html, (url.format(i * 10)))
my.threadpool.shutdown(wait=True)
分析源码
- F12和Ctrl+U都打开看一下,没有使用js动态加载,也没有加密,真是太好了。
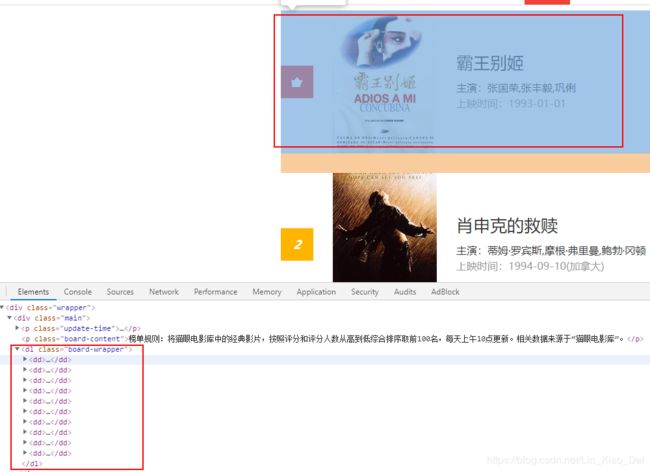
- 可以看到每个页面的10个item就放在这10个
标签里面。
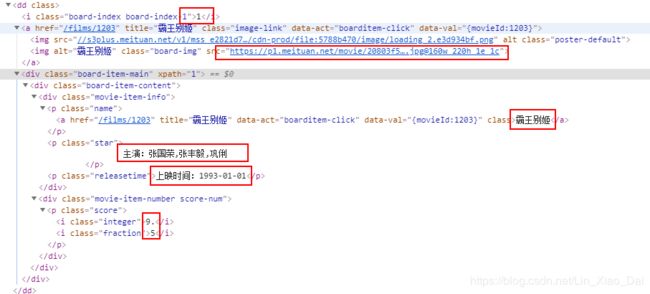
- 打开一个
标签可以看到需要爬取的信息,画出红框的就是这次我准备采集的,使用的xpath方式来解析,但是在解析 - 这次还是使用mongodb的方式来存储信息,因为用mysql还得创建表好烦。
完整代码
"""
爬取猫眼电影TOP100
"""
import datetime
import pymongo
import requests
from gevent.threadpool import ThreadPoolExecutor
from lxml import etree
class MaoYanTop100(object):
def __init__(self):
self.mongo_conn = pymongo.MongoClient()['猫眼top100']['ranking']
self.threadpool = ThreadPoolExecutor(max_workers=10)
def insert_mongo(self, data):
"""
一次性往mongodb插入10条数据
:param data:
:return:
"""
self.mongo_conn.insert_many(data)
print("插入成功")
def get_html(self, url):
"""
先获取页面的源码,再调用parse_page方法进行解析
:param url:
:return:
"""
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"Cookie": "__mta=44307867.1567951237989.1568739550085.1568739935102.39; uuid_n_v=v1; uuid=07D445D0D24111E9899D6B628470FE8D4BF76F7F4FBF4060B7425CFE6C5B7226; _lxsdk_cuid=16d112d2fbfc8-0dddfbc07046c-7373e61-1fa400-16d112d2fbfc8; _lxsdk=07D445D0D24111E9899D6B628470FE8D4BF76F7F4FBF4060B7425CFE6C5B7226; __mta=44307867.1567951237989.1568539181361.1568539516078.13; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; _csrf=d90780f5ecc4406a17ba30a2e91e891123d6730394048db16bbdfba6a296b703; _lxsdk_s=16d4014a9a6-41f-831-321%7C%7C7",
}
res = requests.get(url=url, headers=headers)
res.encoding = "UTF-8"
self.parse_page(res.text)
except Exception as e:
print(e)
return None
def parse_page(self, data):
"""
解析页面并插入数据库
:param html:
:return:
"""
html = etree.HTML(data)
dd_s = html.xpath("//dd")
value_s = []
for dd in dd_s:
value_s.append({
'ranking': dd.xpath("./i/text()")[0],
# 这个.attrib['data-src']我也不知道从哪里出来的,打断点就这么找出来的
'image': dd.xpath(".//a[1]//img[2]")[0].attrib['data-src'],
'title': dd.xpath(".//p/a/text()")[0],
'actors': dd.xpath(".//p[@class='star']/text()")[0].strip()[3:],
'time': dd.xpath(".//p[@class='releasetime']/text()")[0][5:],
'score': dd.xpath(".//p[@class='score']/i[1]/text()")[0] + dd.xpath(".//p[@class='score']/i[2]/text()")[
0],
})
self.insert_mongo(value_s)
def usetime(func):
"""
这是一个返回方法耗时多久的自定义装饰器
:param func:
:return:
"""
def wraper(*args, **kwargs):
start = datetime.datetime.now()
res = func(*args, **kwargs)
print('{}方法耗时{}s'.format(func.__name__, (datetime.datetime.now() - start).total_seconds()))
return res
return wraper
@usetime
def main():
url = 'http://maoyan.com/board/4?offset={}'
my = MaoYanTop100()
for i in range(10):
# 每次偏移都是10的倍数,这里用了线程池,只是用用好像并没有加快速度
my.threadpool.submit(my.get_html, (url.format(i * 10)))
my.threadpool.shutdown(wait=True)
if __name__ == '__main__':
main()
总结
- 这次没有用代理ip,因为免费的代理ip老是连接不上,也有可能是被猫眼封了。(免费的东西总是不靠谱,自建免费代理ip请看爬虫学习日记1_自建代理IP池)
- 自己手动写了一个自定义的计时装饰器。
- 整个代码的难度不高,入个门吧。
- 使用或不使用线程池,我这10页数据爬取下来都要1分钟,其中可能的原因如下:
– 自己家网络不好。(200M我感觉应该不算太慢)
– 猫眼的网络不好。(有可能,平时打开网址都要转好几圈)
– 线程池同开开启的线程太多,切换浪费时间。(我这代码里面同时开10条,不算太多啊)
– 网页源码爬取下来选取的解析方式不好,使用re模块或许会更快?
– 频繁插入数据库?
– 加了装饰器影响了速度? - 本次使用到的知识点:
– requests
– pymongo
– lxml
– ThreadPoolExecutor
– 装饰器 - 写的不好还请各位海涵,欢迎各位在底下留言或私信,谢谢。