cp11_Working with Unlabeled Data_Clustering Analysis_Kmeans_hierarchical_dendrogram_heat map_DBSCAN
In the previous chapters, we used supervised learning techniques to build machine learning models using data where the answer was already known—the class labels were already available in our training data. In this chapter, we will switch gears and explore cluster analysis, a category of unsupervised learning techniques that allows us to discover hidden structures in data where we do not know the right answer upfront 预先的. The goal of clustering聚类 is to find a natural grouping in data such that items in the same cluster are more similar to each other than those from different clusters.
Given its exploratory nature, clustering is an exciting topic and, in this chapter, you will learn about the following concepts that can help you to organize data into meaningful structures:
- Finding centers of similarity using the popular k-means algorithm
- Using a bottom-up approach to build hierarchical cluster trees
- Identifying arbitrary shapes of objects using a density-based clustering approach
Grouping objects by similarity using kmeans
In this section, we will discuss one of the most popular clustering algorithms, k-means, which is widely used in academia as well as in industry. Clustering (or cluster analysis) is a technique that allows us to find groups of similar objects, objects that are more related to each other than to objects in other groups. Examples of business-oriented applications of clustering include the grouping of documents, music, and movies by different topics, or finding customers that share similar interests based on common purchase behaviors as a basis for recommendation engines.
As we will see in a moment, the k-means algorithm is extremely easy to implement but is also computationally very efficient compared to other clustering algorithms, which might explain its popularity. The k-means algorithm belongs to the category of prototype-based clustering. We will discuss two other categories of clustering, hierarchical and density-based clustering, later in this chapter. Prototype-based clustering means that each cluster is represented by a prototype, which can either be the centroid质心 (average) of similar points with continuous features, or the medoid (the most representative or most frequently occurring point) in the case of categorical features. While k-means is very good at identifying clusters of spherical shape球形, one of the drawbacks of this clustering algorithm is that we have to specify the number of clusters k a priori先验. An inappropriate choice for k can result in poor clustering performance. Later in this chapter, we will discuss the elbow 肘部 method and silhouette轮廓plots, which are useful techniques to evaluate the quality of a clustering to help us determine the optimal number of clusters k.
Although k-means clustering can be applied to data in higher dimensions, we will walk through the following examples using a simple two-dimensional dataset for the purpose of visualization:
from sklearn.datasets import make_blobs
X,y = make_blobs( n_samples=150,
n_features=2,
centers=3,
cluster_std=0.5, #cluster_std--skip distance--diameter
shuffle=True,
random_state=0
) #制作团点
import matplotlib.pyplot as plt
plt.scatter(X[:,0], X[:,1], c='black', marker='o', s=50)
plt.grid()
plt.show()The dataset that we just created consists of 150 randomly generated points that are roughly grouped into three regions with higher density(cluster_std=0.5), which is visualized via a two-dimensional scatterplot:

In real-world applications of clustering, we do not have any ground truth category information about those samples; otherwise, it would fall into the category of supervised learning. Thus, our goal is to group the samples based on their feature similarities, which we can be achieved using the k-means algorithm that can be summarized by the following four steps:
- Randomly pick k centroids(averages of similar points) from the sample points as initial cluster centers.
https://towardsdatascience.com/machine-learning-algorithms-part-9-k-means-example-in-python-f2ad05ed5203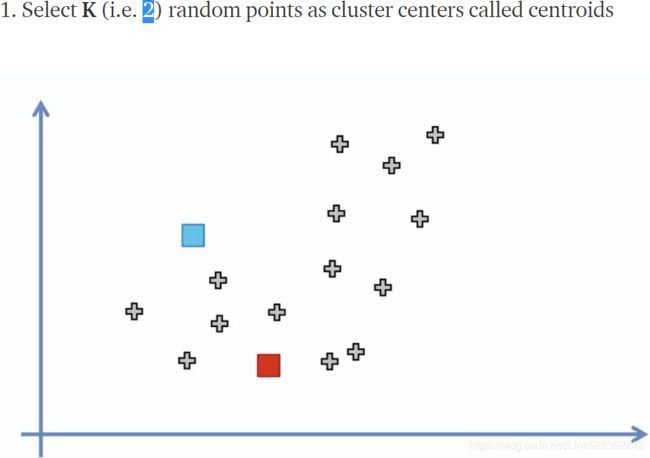
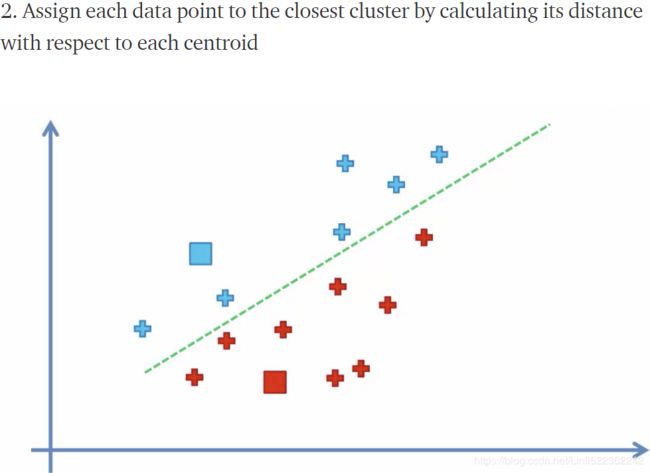
- Assign each sample to the nearest centroid
 ,
, 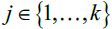 .
.
- Move the centroids质心 to the center中心 of the samples that were assigned to it.
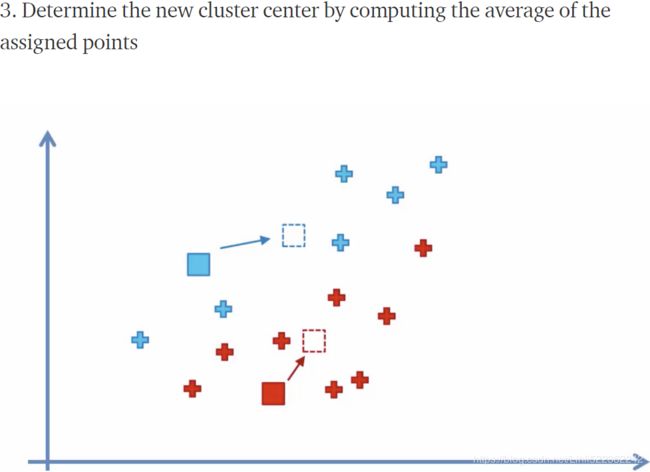
- Repeat steps 2 and 3 until the cluster assignments do not change or a user-defined tolerance or a maximum number of iterations is reached.

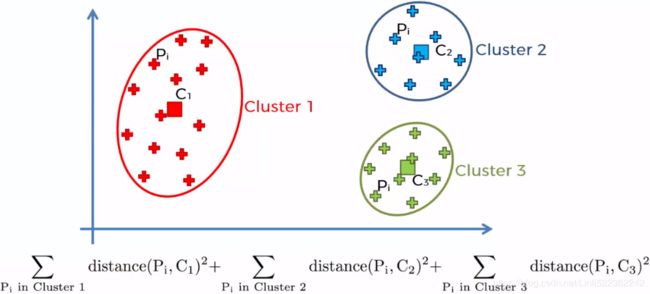
Now the next question is how do we measure similarity between objects? We can define similarity as the opposite of distance, and a commonly used distance for clustering samples with continuous features is the squared Euclidean distance between two points x and y in m-dimensional space: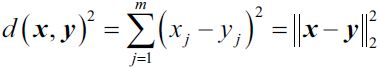
Note that, in the preceding equation, the index j refers to the jth dimension (feature column) of the sample points x and y. In the rest of this section, we will use the superscripts i and j to refer to the sample index and cluster index, respectively. Based on this Euclidean distance metric, we can describe the k-means algorithm as a simple optimization problem, an iterative approach for minimizing the within cluster sum of squared errors (SSE)簇内误差平方和, which is sometimes also called cluster inertia聚类惯性: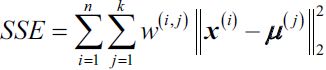
Here, 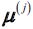 is the representative point (centroid) for cluster j, and
is the representative point (centroid) for cluster j, and 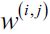 =1 if the sample
=1 if the sample 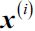 is in cluster j; = 0 otherwise.
is in cluster j; = 0 otherwise.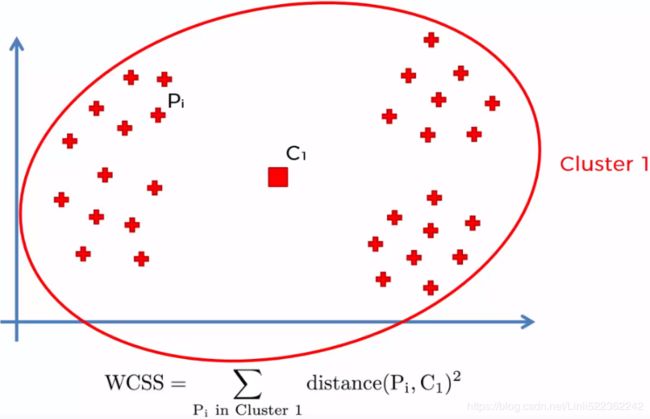
###############################################
import sklearn.metrics as m
d = m.pairwise_distances([(1,1),(0,0), (4,4)], [(2,2),(3,3),(0,0)],metric='euclidean')
print(d)
d_indices = m.pairwise_distances_argmin([(1,1),(0,0), (4,4)], [(2,2),(3,3),(0,0)],metric='euclidean')
d_indices![]()
###############################################
from sklearn.metrics import pairwise_distances_argmin
def find_clusters(X, n_clusters, rseed=2):
# https://jakevdp.github.io/PythonDataScienceHandbook/05.11-k-means.html
# 1. Randomly pick k centroids from the sample points as initial cluster centers.
rng = np.random.RandomState(rseed)
k_centroids_indices = rng.permutation( X.shape[0] )[:n_clusters]
centroids = X[k_centroids_indices]
while True:
# 2. Assign each sample to the nearest centroid
# X --> nearest_centroids_indices
X_labeled_centroids = pairwise_distances_argmin(X, centroids)
#3. Move the centroids to the center of the samples that were assigned to it
#3.1 Find new centers from means of points #axis=0: mean( n_rows x 1_column )
new_centers = np.array([ X[X_labeled_centroids==i].mean(axis=0) for i in range(n_clusters) ])
#4. Repeat steps 2 and 3 until the cluster assignments do not change
# or a user-defined tolerance or a maximum number of iterations is reached.
#4.1 check for convergence
if np.all( centroids == new_centers ):
break
centroids = new_centers #3.2 assign the new center to the centroids
return centroids, X_labeled_centroids
centroids, y_km = find_clusters(X,3)
#plt.scatter(X[:,0], X[:,1], c=X_labeled_centroids, s=50, cmap="viridis")
plt.figure( figsize=(6,6) )
plt.scatter( X[y_km==0, 0], X[y_km==0, 1], s=50, c='lightgreen', marker='s', edgecolor='black',
label='cluster 1' )
plt.scatter( X[y_km==1, 0], X[y_km==1, 1], s=50, c='orange', marker='o', edgecolor='black',
label='cluster 2' )
plt.scatter( X[y_km==2, 0], X[y_km==2, 1], s=50, c='lightblue', marker='v', edgecolor='black',
label='cluster 3' )
plt.scatter( centroids[:,0], centroids[:,1], s=250, marker='*', c='blue',
edgecolor='black', label='centroids')
plt.legend( scatterpoints=1 )
plt.grid()
plt.show()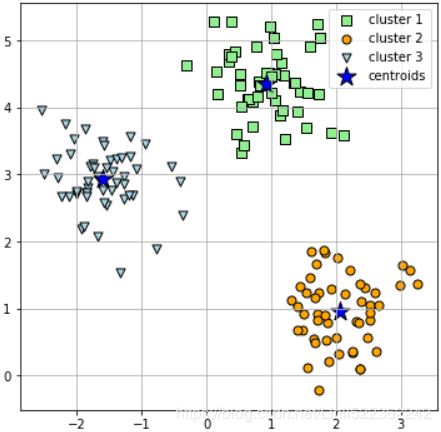
Now that you have learned how the simple k-means algorithm works, let's apply it to our sample dataset using the KMeans class from scikit-learn's cluster module:
from sklearn.cluster import KMeans
# n_clusters=3: set the number of desired clusters to 3
# set n_init=10 to run the k-means clustering algorithms 10 times
# independently with different "random" centroids to choose the final model
# as the one with the lowest SSE
km = KMeans( n_clusters=3, init="random", n_init=10, max_iter=300, tol=1e-04, random_state=0)
y_km = km.fit_predict(X)Using the preceding code, we set the number of desired clusters to 3; specifying the number of clusters a priori is one of the limitations(drawbacks) of k-means. We set n_init=10 to run the k-means clustering algorithms 10 times independently with different random centroids to choose the final model as the one with the lowest SSE. Via the max_iter parameter, we specify the maximum number of iterations for each single run (here, 300). Note that the k-means implementation in scikit-learn stops early if it converges before the maximum number of iterations is reached.
However, it is possible that k-means does not reach convergence for a particular run, which can be problematic (computationally expensive) if we choose relatively large values for max_iter. One way to deal with convergence problems is to choose larger values for tol, which is a parameter that controls the tolerance with regard to the changes in the within-cluster sum-squared-error to declare convergence. In the preceding code, we chose a tolerance of 1e-04 (=0.0001).
Another problem with k-means is that one or more clusters can be empty. Note that this problem does not exist for k-medoids or fuzzy C-means, an algorithm that we will discuss in the next subsection. However, this problem is accounted for in the current k-means implementation in scikit-learn. If a cluster is empty, the algorithm will search for the sample that is farthest away from the centroid of the empty cluster. Then it will reassign the centroid to be this farthest point.
#################################################
Note
When we are applying k-means to real-world data using a Euclidean distance metric, we want to make sure that the features are measured on the same scale(尺度) and apply z-score standardization or min-max scaling if necessary.
#################################################
After we predicted the cluster labels y_km and discussed the challenges of the k-means algorithm, let's now visualize the clusters that k-means identified in the dataset together with the cluster centroids. These are stored under the cluster_centers_ attribute of the fitted KMeans object:
km.cluster_centers_
plt.figure( figsize=(6,6) )
plt.scatter( X[y_km==0, 0], X[y_km==0, 1], s=50, c='lightgreen', marker='s', edgecolor='black',
label='cluster 1' )
plt.scatter( X[y_km==1, 0], X[y_km==1, 1], s=50, c='orange', marker='o', edgecolor='black',
label='cluster 2' )
plt.scatter( X[y_km==2, 0], X[y_km==2, 1], s=50, c='lightblue', marker='v', edgecolor='black',
label='cluster 3' )
plt.scatter( km.cluster_centers_[:,0], km.cluster_centers_[:,1], s=250, marker='*', c='blue',
edgecolor='black', label='centroids')
plt.legend( scatterpoints=1 )
plt.grid()
plt.show()In the following scatterplot, we can see that k-means placed the three centroids at the center of each sphere, which looks like a reasonable grouping given this dataset:
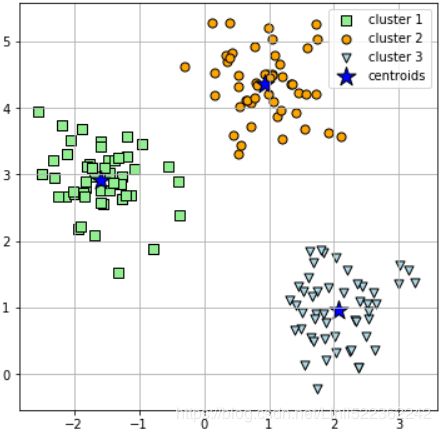
print('WC_SSE: %.2f' % km.inertia_)![]()
Although k-means worked well on this toy dataset, we need to note some of the main challenges of k-means. One of the drawbacks of k-means is that we have to specify the number of clusters k a priori, which may not always be so obvious in real-world applications, especially if we are working with a higher dimensional dataset that cannot be visualized. The other properties of k-means are that clusters do not overlap and are not hierarchical, and we also assume that there is at least one item in each cluster. Later, we will encounter different types of clustering algorithms, hierarchical and density-based clustering. Neither type of algorithm requires us to specify the number of clusters upfront预先的 or assume spherical structures in our dataset两种算法都不需要我们预先指定簇数或在数据集中采用球形结构.
In the next subsection, we will introduce a popular variant变异的 of the classic k-means algorithm called k-means++. While it doesn't address解决 those assumptions and drawbacks of k-means discussed in the previous paragraph, it can greatly improve the clustering results through more clever seeding of the initial cluster centers.
K-means++
So far, we discussed the classic k-means algorithm that uses a random seed to place the initial centroids, which can sometimes result in bad clusterings or slow convergence if the initial centroids are chosen poorly (https://blog.csdn.net/Linli522362242/article/details/105722461). One way to address this issue is to run the k-means algorithm multiple times on a dataset and choose the best performing model in terms of the SSE. Another strategy is to place the initial centroids far away from each other via the k-means++ algorithm, which leads to better and more consistent results than the classic k-means (D. Arthur and S.Vassilvitskii. k-means++: The Advantages of Careful Seeding. In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, pages 1027–1035. Society for Industrial and Applied Mathematics, 2007).
The initialization in k-means++ can be summarized as follows:
- Initialize an empty set M to store the k centroids being selected.
- Randomly choose the first centroid
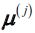 (is the representative point (centroid) for cluster j) from the input samples and assign it to M.
(is the representative point (centroid) for cluster j) from the input samples and assign it to M. - For each sample
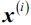 that is not in M, find the minimum squared distance
that is not in M, find the minimum squared distance  to any of the centroids in M.
to any of the centroids in M. - To randomly select the next centroid
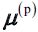 , use a weighted probability distribution equal to
, use a weighted probability distribution equal to 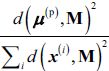 .
. - Repeat steps 2 and 3 until k centroids are chosen.
- Proceed with the classic k-means algorithm.
########################################
To use k-means++ with scikit-learn's KMeans object, we just need to set the init parameter to k-means++ (the default setting) instead of random. In fact, 'k-means++' is the default argument to the init parameter, which is strongly recommended in practice. The only reason why we haven't used it in the previous example was to not introduce too many concepts all at once. The rest of this section on k-means will use k-means++, but readers are encouraged to experiment more with the two different approaches (classic k-means via init='random' versus k-means++ via init='k-means++') for placing the initial cluster centroids.
########################################
wc_sse = []
for i in range(1,11):
kmeans = KMeans(n_clusters=i, init='k-means++', max_iter=300, n_init=10, random_state=0)
kmeans.fit(X)
wc_sse.append(kmeans.inertia_)#inertia_float:Sum of squared distances of samples to their closest cluster center
plt.plot(range(1,11), wc_sse)
plt.title('Elbow Method')
plt.xlabel('Number of Clusters')
plt.ylabel('WC_SSE', rotation=0, labelpad=22) #within cluster sum of squared errors
plt.show() 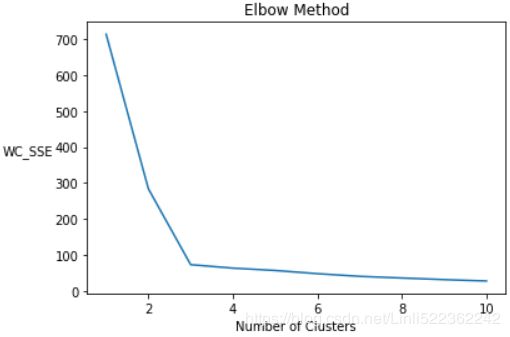
Next, we’ll categorize the data using the optimum number of clusters (3) we determined in the last step. k-means++ ensures that you get don’t fall into the random initialization trap.
# set n_init=10 to run the k-means clustering algorithms 10 times independently with
# different random centroids to choose the final model as the one with the lowest SSE
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=300, n_init=10, random_state=0)
y_km = kmeans.fit_predict(X)
plt.figure( figsize=(6,6) )
plt.scatter( X[y_km==0, 0], X[y_km==0, 1], s=50, c='lightgreen', marker='s', edgecolor='black',
label='cluster 1' )
plt.scatter( X[y_km==1, 0], X[y_km==1, 1], s=50, c='orange', marker='o', edgecolor='black',
label='cluster 2' )
plt.scatter( X[y_km==2, 0], X[y_km==2, 1], s=50, c='lightblue', marker='v', edgecolor='black',
label='cluster 3' )
plt.scatter( km.cluster_centers_[:,0], km.cluster_centers_[:,1], s=250, marker='*', c='blue',
edgecolor='black', label='centroids')
plt.legend( scatterpoints=1 )
plt.grid()
plt.show()
The k-Means++ algorithm (first 5 steps)
from sklearn.metrics.pairwise import pairwise_distances
a=[ [1,3],
[2,2],
[3,4]
]
b=[[3,3],
[2,2]
]
pairwise_distances(a,b) 
# https://www.geeksforgeeks.org/ml-k-means-algorithm/
# function to plot the selected centroids
def plot(data, centroids):
#plt.figure( figsize=(6,6) )
plt.scatter(data[:, 0], data[:, 1], marker = 'o', s=50, color = 'orange', edgecolor='black',
label = 'data points')
plt.scatter(centroids[:-1, 0], centroids[:-1, 1], marker='*', s=150,
color = 'black', label = 'previously selected centroids')
plt.scatter(centroids[-1, 0], centroids[-1, 1], marker='*', s=150, color = 'blue',
label = 'next centroid')
plt.title( 'Select % d th centroid'%(centroids.shape[0]) )
plt.grid(True)
plt.legend()
plt.show()
import sklearn.metrics as metrics
# initialisation algorithm
def initialize(data, k):
centroids = [] # 1. Initialize an empty set M to store the k centroids being selected.
# 2. Randomly choose the first centroid μ^(j) from the input samples and assign it to M.
k_centroids_indices =[]
index = np.random.randint(data.shape[0])
k_centroids_indices.append(index)
centroids.append( data[index, :] ) #first centroid
plot( data, np.array(centroids) )
dist=np.array([])
# 5. Repeat steps 2 and 3 until k centroids are chosen.
# compute remaining k - 1 centroids
for c_id in range(k - 1):
# 3. For each sample x^(i) that is not in M, find the minimum squared
# distance d(x^i,M) to any of the centroids in M.
unused= [i for i in range(data.shape[0]) if i not in k_centroids_indices]
d = metrics.pairwise_distances( data[unused,:], centroids, metric='euclidean' )
dist = np.min(d,axis=1) # for each row
# 4.To randomly select the next centroid μ^p, use a weighted probability distribution equal to
# here, select data point with maximum distance as our next centroid
index = np.argmax(dist)
k_centroids_indices.append(unused[index]) ######
next_centroid = data[unused[index], :] ######
centroids.append( next_centroid )
dist=np.array([])
plot( data, np.array(centroids) )
return centroids, k_centroids_indices
# call the initialize function to get the centroids
centroids, k_centroids_indices = initialize(X, k = 3) 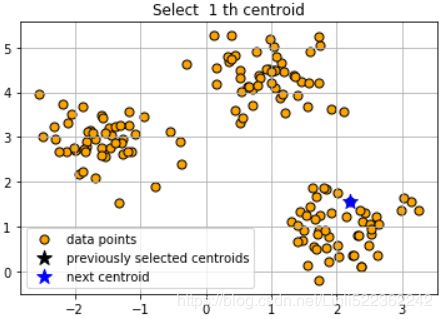

6. Proceed with the classic k-means algorithm.
from sklearn.metrics import pairwise_distances_argmin
def find_clusters(X, k_centroids_indices, n_clusters):
# https://jakevdp.github.io/PythonDataScienceHandbook/05.11-k-means.html
centroids = X[k_centroids_indices]
while True:
# 2. Assign each sample to the nearest centroid
# X --> nearest_centroids_indices
X_labeled_centroids = pairwise_distances_argmin(X, centroids)
#3. Move the centroids to the center of the samples that were assigned to it
#3.1 Find new centers from means of points #axis=0: mean( n_rows x 1_column )
new_centers = np.array([ X[X_labeled_centroids==i].mean(axis=0) for i in range(n_clusters) ])
#4. Repeat steps 2 and 3 until the cluster assignments do not change
# or a user-defined tolerance or a maximum number of iterations is reached.
#4.1 check for convergence
if np.all( centroids == new_centers ):
break
centroids = new_centers #3.2 assign the new center to the centroids
return centroids, X_labeled_centroids
centroids, y_km = find_clusters(X,k_centroids_indices,3) ##########################
#plt.scatter(X[:,0], X[:,1], c=X_labeled_centroids, s=50, cmap="viridis")
plt.figure( figsize=(6,6) )
plt.scatter( X[y_km==0, 0], X[y_km==0, 1], s=50, c='lightgreen', marker='s', edgecolor='black',
label='cluster 1' )
plt.scatter( X[y_km==1, 0], X[y_km==1, 1], s=50, c='orange', marker='o', edgecolor='black',
label='cluster 2' )
plt.scatter( X[y_km==2, 0], X[y_km==2, 1], s=50, c='lightblue', marker='v', edgecolor='black',
label='cluster 3' )
plt.scatter( centroids[:,0], centroids[:,1], s=250, marker='*', c='blue',
edgecolor='black', label='centroids')
plt.legend( scatterpoints=1 )
plt.grid()
plt.show() 
Hard versus soft clustering
Hard clustering describes a family of algorithms where each sample in a dataset is assigned to exactly one cluster, as in the k-means algorithm that we discussed in the previous subsection. In contrast, algorithms for soft clustering (sometimes also called fuzzy clustering模糊聚类) assign a sample to one or more clusters. A popular example of soft clustering is the fuzzy C-means (FCM) algorithm (also called soft k-means or fuzzy k-means). The original idea goes back to the 1970s, when Joseph C. Dunn first proposed an early version of fuzzy clustering to improve k-means (A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters, J. C. Dunn, 1973). Almost a decade later, James C. Bedzek published his work on the improvement of the fuzzy clustering algorithm, which is now known as the FCM algorithm (Pattern Recognition with Fuzzy Objective Function Algorithms, J. C. Bezdek, Springer Science+Business Media, 2013).
The FCM(also called soft k-means or fuzzy k-means) procedure is very similar to k-means. However, we replace the hard cluster assignment with probabilities for each point belonging to each cluster (我们使用每个样本点隶属于各簇的概率来代替硬聚类的划分). In k-means, we could express the cluster membership of a sample x with a sparse vector of binary values:
Here, the index position with value 1 indicates the cluster centroid ![]() the sample is assigned to (assuming k = 3, j
the sample is assigned to (assuming k = 3, j ![]() {1, 2, 3}). In contrast, a membership vector in FCM could be represented as follows:
{1, 2, 3}). In contrast, a membership vector in FCM could be represented as follows:
Here, each value falls in the range [0, 1] and represents a probability of membership to the respective cluster centroid. The sum of the memberships for a given sample is equal to 1. Similarly to the k-means algorithm, we can summarize the FCM algorithm in four key steps:
- Specify the number of k centroids and randomly assign the cluster memberships for each point.
- Compute the cluster centroids
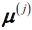 , j
, j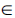 {1,…, k}.
{1,…, k}. - Update the cluster memberships for each point.
- Repeat steps 2 and 3 until the membership coefficients do not change or a user-defined tolerance or a maximum number of iterations is reached.
The objective function of FCM—we abbreviate it by ![]() —looks very similar to the within cluster sum-squared-error that we minimize in k-means:
—looks very similar to the within cluster sum-squared-error that we minimize in k-means: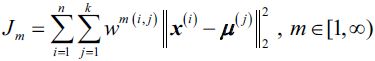
However, note that the membership indicator ![]() is not a binary value as in k-means
is not a binary value as in k-means ![]()
![]() {0,1} ) but a real value that denotes the cluster membership probability (
{0,1} ) but a real value that denotes the cluster membership probability (![]()
![]() [0,1] ). You also may have noticed that we added an additional exponent to
[0,1] ). You also may have noticed that we added an additional exponent to ![]() ; the exponent m, any number greater or equal to 1 (typically m = 2), is the so-called fuzziness coefficient (or simply fuzzifier) that controls the degree of fuzziness. The larger the value of m , the smaller the cluster membership
; the exponent m, any number greater or equal to 1 (typically m = 2), is the so-called fuzziness coefficient (or simply fuzzifier) that controls the degree of fuzziness. The larger the value of m , the smaller the cluster membership ![]() becomes, which leads to fuzzier clusters. The cluster membership probability itself is calculated as follows:
becomes, which leads to fuzzier clusters. The cluster membership probability itself is calculated as follows: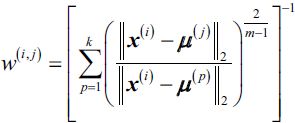
For example, if we chose three cluster centers as in the previous k-means example, we could calculate the membership of the ![]() sample belonging to the
sample belonging to the ![]() cluster as: j
cluster as: j![]() {1,…, k}.
{1,…, k}.
The center ![]() of a cluster itself is calculated as the mean of all samples in the cluster weighted by the membership degree of belonging to its own cluster:
of a cluster itself is calculated as the mean of all samples in the cluster weighted by the membership degree of belonging to its own cluster:
Just by looking at the equation to calculate the cluster memberships, it is intuitive to say that each iteration in FCM is more expensive than an iteration in k-means. However, FCM typically requires fewer iterations overall to reach convergence.
Unfortunately, the FCM algorithm is currently not implemented in scikit-learn. However, it has been found in practice that both k-means and FCM produce very similar clustering outputs, as described in a study by Soumi Ghosh and Sanjay K. Dubey (S. Ghosh and S. K. Dubey. Comparative Analysis of k-means and Fuzzy c-means Algorithms. IJACSA, 4:35–38, 2013).
https://www.geeksforgeeks.org/ml-fuzzy-clustering/
Using the elbow method to find the optimal number of clusters
One of the main challenges in unsupervised learning is that we do not know the definitive确定的 answer. We don't have the ground truth class labels in our dataset that allow us to apply the techniques that we used in Chapter 6, Learning Best Practices for Model Evaluation and Hyperparameter Tuning, in order to evaluate the performance of a supervised model. Thus, in order to quantify量化 the quality品质 of clustering, we need to use intrinsic metrics—such as the within-cluster SSE (distortion失真) that we discussed earlier in this chapter—to compare the performance of different k-means clusterings. Conveniently, we don't need to compute the within-cluster SSE explicitly as it is already accessible via the inertia_ attribute after fitting a KMeans model:
print('Distortion-WC_SSE: %.2f' % km.inertia_)![]()
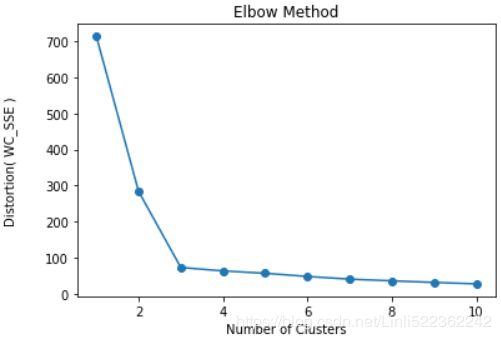
Based on the within-cluster SSE, we can use a graphical tool, the so-called elbow method, to estimate the optimal number of clusters k for a given task. Intuitively, we can say that, if k increases, the distortion(the within-cluster SSE) will decrease. This is because the samples will be closer to the centroids they are assigned to(). The idea behind the elbow method is to identify the value of k where the distortion begins to increase most rapidly, which will become more clear if we plot distortion for different values of k:
distortions_wc_sses = []
for i in range(1,11):
kmeans = KMeans(n_clusters=i, init='k-means++', max_iter=300, n_init=10, random_state=0)
kmeans.fit(X)
distortions_wc_sses.append(kmeans.inertia_)#inertia_float:Sum of squared distances of samples to
#their closest cluster center
plt.plot(range(1,11), distortions_wc_sses, marker='o')
plt.title('Elbow Method')
plt.xlabel('Number of Clusters')
plt.ylabel('Distortion( WC_SSE )', labelpad=22) #within cluster sum of squared errors
plt.show()As we can see in the following plot, the elbow is located at k = 3, which provides evidence that k = 3 is indeed a good choice for this dataset:
Quantifying量化 the quality品质 of clustering via silhouette轮廓 plots
Another intrinsic metric(such as the within-cluster SSE (distortion失真)) to evaluate the quality of a clustering is silhouette analysis, which can also be applied to clustering algorithms other than k-means that we will discuss later in this chapter. Silhouette analysis can be used as a graphical tool to plot a measure of how tightly grouped the samples in the clusters are. To calculate the silhouette coefficient of a single sample in our dataset, we can apply the following three steps:
- Calculate the cluster cohesion内聚度
 (is the mean intra cluster distance) as the average distance between a sample
(is the mean intra cluster distance) as the average distance between a sample 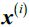 and all other points in the same cluster.
and all other points in the same cluster. - Calculate the cluster separation分离度
 from the next closest cluster(depicts mean nearest cluster distance) as the average distance between the sample and all samples in the nearest cluster.
from the next closest cluster(depicts mean nearest cluster distance) as the average distance between the sample and all samples in the nearest cluster. - Calculate the silhouette
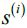 as the difference between cluster cohesion and separation divided by the greater of the two, as shown here:
as the difference between cluster cohesion and separation divided by the greater of the two, as shown here: : the silhouette coefficient==
: the silhouette coefficient== 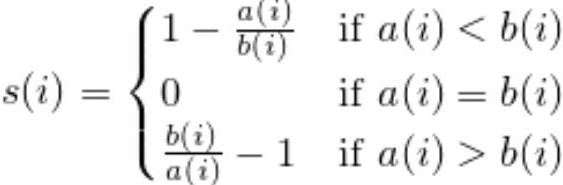
The silhouette coefficient is bounded in the range -1 to 1(###a coefficient close to +1 means that the instance is well inside its own cluster and far from other clusters, while a coefficient close to 0 means that it is close to a cluster boundary, and finally a coefficient close to -1 means that the instance may have been assigned to the wrong cluster###). Based on the preceding formula, we can see that the silhouette coefficient is 0 if the cluster separation and cohesion are equal (![]() =
= ![]() ). Furthermore, we get close to an ideal silhouette coefficient of 1 if
). Furthermore, we get close to an ideal silhouette coefficient of 1 if ![]() >>
>> ![]() , since
, since ![]() quantifies how dissimilar差异性 a sample is to other clusters, and
quantifies how dissimilar差异性 a sample is to other clusters, and ![]() tells us how similar相似性 it is to the other samples in its own cluster, respectively.
tells us how similar相似性 it is to the other samples in its own cluster, respectively.
The silhouette coefficient is available as silhouette_samples from scikit-learn's metric module, and optionally the silhouette_scores can be imported. This calculates the average silhouette coefficient across all samples, which is equivalent to numpy.mean(silhouette_samples(…)).
By executing the following code, we will now create a plot of the silhouette coefficients for a k-means clustering with k = 3:
km = KMeans(n_clusters=3, init='k-means++', n_init=10, max_iter=300, tol=1e-04, random_state=0)
y_km = km.fit_predict(X)
import numpy as np
from matplotlib import cm
from sklearn.metrics import silhouette_samples
cluster_labels = np.unique(y_km) # array([0, 1, 2])
n_clusters = cluster_labels.shape[0] # 3
silhouette_vals = silhouette_samples(X, y_km, metric='euclidean') #The silhouette coefficients
y_ax_lower, y_ax_upper = 0, 0
yticks = []
for i,c in enumerate(cluster_labels):
#Get all silhouette coefficients in the same cluster
c_silhouette_vals = silhouette_vals[y_km==c] #The silhouette coefficients when cluster ==c
c_silhouette_vals.sort() #ascending
y_ax_upper += len(c_silhouette_vals) #==the number of data points in the same cluster
color = cm.jet( float(i)/n_clusters)
#cm.jet(X): For floats, X should be in the interval ``[0.0, 1.0]`` to
#return the RGBA values ``X*100`` percent along the Colormap line.
plt.barh( range(y_ax_lower, y_ax_upper), c_silhouette_vals, height=1.0, edgecolor='none',
color=color)
yticks.append( (y_ax_lower+y_ax_upper)/2. ) #get the center of plt.barh as a ytick
y_ax_lower += len( c_silhouette_vals ) # The starting position of the next y-axis
silhouette_avg = np.mean( silhouette_vals )
plt.axvline(silhouette_avg, color="red", linestyle='--')
# replace ticks with [labels]
plt.yticks(yticks, cluster_labels+1) #( [25.0, 75.0, 125.0], array([1, 2, 3]) ) =(ticks, [labels])
plt.ylabel('Cluster')
plt.xlabel('Silhouette coefficient')
plt.show()Through a visual inspection of the silhouette plot, we can quickly scrutinize 仔细或彻底检查 the sizes of the different clusters( len(c_silhouette_vals) ) and identify clusters that contain outliers:

As we can see in the preceding silhouette plot, our silhouette coefficients are not even close to 0, which can be an indicator of a good clustering. Furthermore, to summarize the goodness of our clustering(为了总结我们聚类效果的好处), we added the average silhouette coefficient to the plot (dotted line).
To see how a silhouette plot looks for a relatively bad clustering, let's seed the k-means algorithm with two centroids only:
#set n_init=10 to run the k-means clustering algorithms 10 times independently
#with different random centroids to choose the final model as the one with the lowest SSE
km = KMeans(n_clusters=2, init='k-means++', n_init=10, max_iter=300, tol=1e-04, random_state=0)
y_km = km.fit_predict(X)
print(np.unique(y_km))![]()
plt.scatter( X[y_km==0,0], X[y_km==0,1], s=50, c='lightgreen', marker='o', edgecolor='black',
label='cluster 1' )
plt.scatter( X[y_km==1,0], X[y_km==1,1], s=50, c='orange', marker='s', edgecolor='black',
label='cluster 2')
plt.scatter(km.cluster_centers_[:,0], km.cluster_centers_[:,1], s=250, marker='*', c='red',
label='centroids')
plt.legend()
plt.grid()
plt.show()As we can see in the following scatterplot, one of the centroids falls between two of the three spherical groupings of the sample points. Although the clustering does not look completely terrible, it is suboptimal 不是最满意的.
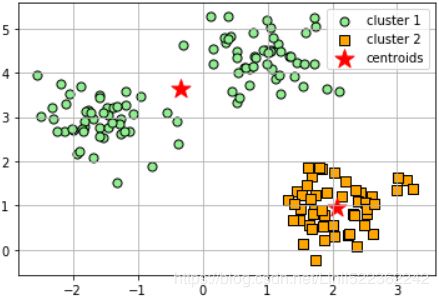
Next we create the silhouette plot to evaluate the results. Please keep in mind that we typically do not have the luxury of visualizing datasets我们不奢望可视化数据集 in two-dimensional scatterplots in real-world problems, since we typically work with data in higher dimensions:
cluster_labels = np.unique(y_km)
n_clusters = cluster_labels.shape[0]
#from sklearn.metrics import silhouette_samples
silhouette_vals = silhouette_samples(X, y_km, metric='euclidean')
y_ax_lower, y_ax_upper = 0,0
yticks = []
for i,c in enumerate(cluster_labels):
#extract all silhouette coefficients in the same cluster
c_silhouette_vals = silhouette_vals[y_km==c]
c_silhouette_vals.sort()
y_ax_upper += len(c_silhouette_vals) #==the number of data points in the same cluster
#cm.jet(X): For floats, X should be in the interval ``[0.0, 1.0]`` to
#return the RGBA values ``X*100`` percent along the Colormap line.
color = cm.jet(i/n_clusters)
plt.barh( range(y_ax_lower, y_ax_upper), c_silhouette_vals, height=1.0, edgecolor='none',
color=color)
yticks.append( (y_ax_lower + y_ax_upper)/2) #get the center of plt.barh as a ytick
y_ax_lower += len(c_silhouette_vals) # The starting position of the next y-axis
silhouette_avg = np.mean( silhouette_vals )
plt.axvline(silhouette_avg, color='red', linestyle='--')
plt.yticks(yticks, cluster_labels+1)
plt.ylabel('Cluster')
plt.xlabel('Silhouette coefficient')
plt.show()As we can see in the resulting plot, the silhouettes now have visibly different lengths and width, which yields further evidence for a suboptimal clustering:

Organizing clusters as a hierarchical tree将多个聚类组织为分层树
In this section, we will take a look at an alternative approach to prototype-based clustering: hierarchical clustering. One advantage of hierarchical clustering algorithms is that it allows us to plot dendrograms系统树图 (visualizations of a binary hierarchical clustering), which can help with the interpretation of the results by creating meaningful taxonomies分类系统. Another useful advantage of this hierarchical approach is that we do not need to specify the number of clusters upfront.
The two main approaches to hierarchical clustering are agglomerative and divisive hierarchical clustering成团块层次聚类和分裂层次聚类. In divisive hierarchical clustering, we start with one cluster that encompasses all our samples, and we iteratively split the cluster into smaller clusters until each cluster only contains one sample. In this section, we will focus on agglomerative clustering成团块聚类, which takes the opposite approach. We start with each sample as an individual cluster and merge the closest pairs of clusters until only one cluster remains.
Grouping clusters in bottom-up fashion
The two standard algorithms for agglomerative hierarchical clustering are single linkage and complete linkage.
Using single linkage, we compute the distances between the most similar members for each pair of clusters and merge the two clusters for which the distance between the most similar members is the smallest.
The complete linkage approach is similar to single linkage but, instead of comparing the most similar members in each pair of clusters, we compare the most dissimilar members to perform the merge. This is shown in the following diagram:
#####################################
Note
Other commonly used algorithms for agglomerative hierarchical clustering include average linkage and Ward's linkage. In average linkage, we merge the cluster pairs based on the minimum average distances between all group members in the two clusters. In Ward's linkage, the two clusters that lead to the minimum increase of the total within-cluster SSE are merged.
#####################################
In this section, we will focus on agglomerative clustering using the complete linkage approach. This is an iterative procedure that can be summarized by the following steps:
- Compute the distance matrix of all samples.
pd.DataFrame( squareform( pdist(df, metric="euclidean") ), columns=labels, index=labels ) - Represent each data point as a singleton单独 cluster.
- Merge the two closest clusters based on the distance of the most dissimilar (distant远离的) members.
- Update the distance matrix.
- Repeat steps 2 to 4 until one single cluster remains.
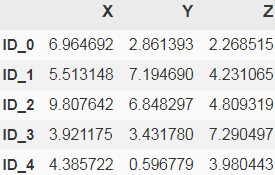
Now we will discuss how to compute the distance matrix (step 1). But first, let's generate some random sample data to work with. The rows represent different observations (IDs 0 to 4), and the columns are the different features (X, Y, Z) of those samples:
import pandas as pd
import numpy as np
np.random.seed(123)
variables = ['X','Y','Z'] #features
labels = ['ID_0', 'ID_1', 'ID_2', 'ID_3', 'ID_4'] #indices
X = np.random.random_sample([5,3]) * 10
df = pd.DataFrame(X, columns=variables, index=labels)
dfAfter executing the preceding code, we should now see the following data frame containing the randomly generated samples:
Performing hierarchical clustering on a distance matrix
To calculate the distance matrix as input for the hierarchical clustering algorithm, we will use the pdist function from SciPy's spatial.distance submodule:
np.sqrt((6.964692-5.513148)**2+(2.861393-7.194690)**2+(2.268515-4.231065)**2)![]()
pdist(df, metric="euclidean")![]()
A condensed distance matrix is a flat array containing the upper triangular of the distance matrix.
from scipy.spatial.distance import pdist, squareform
# pdist: calculated the Euclidean distance between each pair of sample points
# in our dataset based on the features X, Y, and Z as input to the squareform
#squareform: create a symmetrical matrix of the pair-wise distances
row_dist = pd.DataFrame( squareform(pdist(df, metric="euclidean")), columns=labels, index=labels)
row_distUsing the preceding code, we calculated the Euclidean distance between each pair of sample points in our dataset based on the features X, Y, and Z. We provided the condensed浓缩 distance matrix—returned by pdist—as input to the squareform function to create a symmetrical matrix of the pair-wise distances, as shown here:

Next we will apply the complete linkage agglomeration to our clusters using the linkage function from SciPy's cluster.hierarchy submodule, which returns a so-called linkage matrix(关联矩阵).
However, before we call the linkage function, let's take a careful look at the function documentation:
from scipy.cluster.hierarchy import linkage
help(linkage)linkage(y, method='single', metric='euclidean')[...]
Parameters
----------
y : ndarray
A condensed distance matrix. A condensed distance matrix
is a flat array containing the upper triangular of the distance matrix.
This is the form that ``pdist`` returns. Alternatively, a collection of
:math:`m` observation vectors in :math:`n` dimensions may be passed as an
:math:`m` by :math:`n` array. All elements of the condensed distance matrix
must be finite, i.e. no NaNs or infs.
method : str, optional
The linkage algorithm to use. See the ``Linkage Methods`` section below
for full descriptions.
metric : str or function, optional
The distance metric to use in the case that y is a collection of
observation vectors; ignored otherwise. See the ``pdist``
function for a list of valid distance metrics. A custom distance
function can also be used.
Returns
-------
Z : ndarray
The hierarchical clustering encoded as a linkage matrix.
[...]
Based on the function description, we conclude that we can use a condensed distance matrix (upper triangular) from the pdist function as an input attribute. Alternatively, we could also provide the initial data array and use the euclidean metric as a function argument in linkage. However, we should not use the squareform distance matrix
that we defined earlier, since it would yield different distance values from those expected. To sum it up, the three possible scenarios are listed here:
- Incorrect approach: In this approach, we use the squareform distance matrix. The code is as follows:
row_clusters = linkage(row_dist,method='complete',metric='euclidean')
- Correct approach: In this approach, we use the condensed distance matrix. The code is as follows:
row_clusters = linkage( pdist(df, metric='euclidean'), method='complete', metric='euclidean') -
Correct approach: In this approach, we use the input sample matrix. The code is as follows:
row_clusters = linkage(df.values, method='complete', metric='euclidean')
row_clusters = linkage( pdist(df, metric='euclidean'), method='complete', metric='euclidean' )
row_clusters
To take a closer look at the clustering results, we can turn them to a pandas DataFrame (best viewed in IPython Notebook) as follows:
pd.DataFrame( row_clusters, columns=['row label 1', 'row label 2',
'distance', 'no. of items in clust.'],
index=[ 'cluster %d' % (i+1) for i in range( row_clusters.shape[0] ) ]
)As shown in the following table, the linkage matrix consists of several rows where each row represents one merge(as an new cluster). The first and second columns denote the most dissimilar(distant远离的) members in each cluster, and the third row reports the distance between those members. The last column returns the count of the members in each cluster.
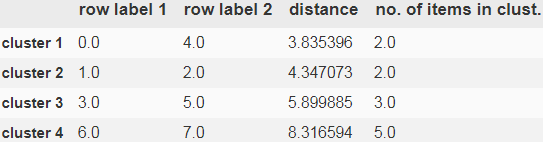
explain: complete linkage compares the most dissimilar members for each pair of clusters.
Why cluster 3==ID_3 + ID_5{ID_0, ID_4 } not the ID_3 + ID_6{ ID_1, ID_2 }![]()
![]()
since ID_5 [the most dissimilar member with ID_3 is ID_0==5.899885] < ID_6[the most dissimilar member with ID_3 is ID_2==7.244262] ==>single linkage==>[ ID_3, ID_0, ID_4 ] ==ID_3 + ID_5
| cluster 1 | 0 | 4 | 3.835396 | 2.0=Count of [ ID_0, ID_4 ] single linkage |
|---|---|---|---|---|
| cluster 2 | 1 | 2 | 4.347073 | 2.0=Count of [ ID_1, ID_2 ] single linkage |
| cluster 3 | 3 | 5= [ ID_0, ID_4 ] | 5.899885 since complete linkage | 3.0=Count of [ ID_3, ID_0, ID_4 ] single linkage |
| cluster 4 | 6 = [ ID_1, ID_2 ] | 7=[ ID_3, ID_0, ID_4 ] | 8.316594 since complete linkage | 5.0=Count of [ ID_1, ID_2, ID_3, ID_0, ID_4 ] single linkage |
Now that we have computed the linkage matrix, we can visualize the results in the form of a dendrogram(系统树图):
from scipy.cluster.hierarchy import dendrogram
from scipy.cluster.hierarchy import set_link_color_palette
set_link_color_palette(['black'])
#labels = ['ID_0', 'ID_1', 'ID_2', 'ID_3', 'ID_4']
row_dendrogram = dendrogram( row_clusters, labels=labels, color_threshold=5)
plt.tight_layout()
plt.ylabel('Euclidean distance', fontsize=14)
plt.show()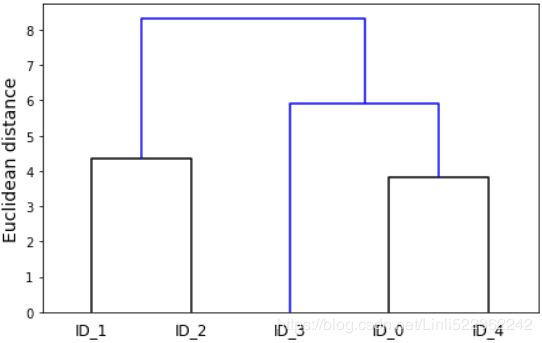
Such a dendrogram summarizes the different clusters that were formed during the agglomerative hierarchical clustering成团块层次聚类; for example, we can see that the samples ID_0 and ID_4, followed by ID_1 and ID_2, are the most similar ones based on the Euclidean distance metric.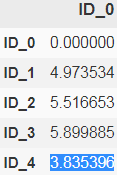
 <== the most similar<==single linkage
<== the most similar<==single linkage
single linkage, we compute the distances between the most similar members for each pair of clusters and merge the two clusters for which the distance between the most similar members is the smallest.
Attaching dendrograms to a heat map
In practical applications, hierarchical clustering dendrograms are often used in combination with a heat map, which allows us to represent the individual values in the sample matrix with a color code. In this section, we will discuss how to attach a dendrogram to a heat map plot and order the rows in the heat map correspondingly.
However, attaching a dendrogram to a heat map can be a little bit tricky, so let's go through this procedure step by step:
- We create a new figure object and define the x axis position, y axis position, width, and height of the dendrogram via the add_axes attribute. Furthermore, we rotate the dendrogram 90 degrees counter-clockwise.
The code is as follows:fig = plt.figure(figsize=(8,8), facecolor='white') axd = fig.add_axes([0.09, 0.1, 0.2, 0.6])#([left, bottom, width, height]) row_dendr = dendrogram(row_clusters, orientation='left')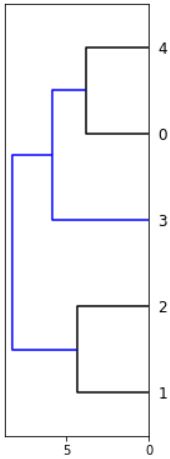
- Next we reorder the data in our initial DataFrame according to the clustering labels that can be accessed from the dendrogram object, which is essentially a Python dictionary, via the leaves key. The code is as follows:
row_dendr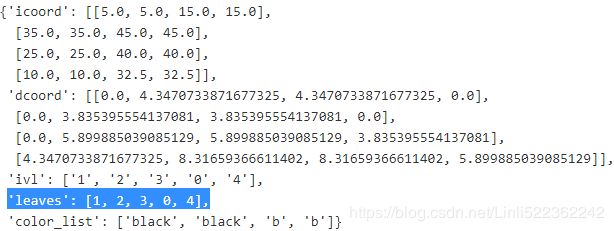
df_rowclust = df.iloc[row_dendr['leaves'][::-1]] df_rowclust
- Now we construct the heat map from the reordered DataFrame and position it right next to the dendrogram:
axm = fig.add_axes([0.23,0.1, 0.6,0.6]) #([left, bottom, width, height]) cax = axm.matshow(df_rowclust, interpolation='nearest', cmap='hot_r') - Finally we will modify the aesthetics审美 of the heat map by removing the axis ticks and hiding the axis spines. Also, we will add a color bar and assign the feature and sample names to the x and y axis tick labels, respectively. The code is as follows:
axd.spines.values() #the border objects of dendrogram
fig = plt.figure(figsize=(8,8), facecolor='white') axd = fig.add_axes([0.09, 0.1, 0.2, 0.6])#([left, bottom, width, height]) row_dendr = dendrogram(row_clusters, orientation='left') df_rowclust = df.iloc[row_dendr['leaves'][::-1]] axm = fig.add_axes([0.23,0.1, 0.6,0.6]) #([left, bottom, width, height]) cax = axm.matshow( df_rowclust, interpolation='nearest', cmap='hot_r' ) axd.set_xticks([]) #removing the axis ticks axd.set_yticks([]) # remove the border of dendrogram for i in axd.spines.values(): i.set_visible(False) fig.colorbar( cax ) #add a color bar axm.set_xticklabels( [''] + list(df_rowclust.columns) ) #[''] -->removing original ticklabels or axis ticks axm.set_yticklabels( [''] + list(df_rowclust.index)) #assign the feature and sample names to the x and y axis tick labels, respectively plt.show()After following the previous steps, the heat map should be displayed with the dendrogram attached:
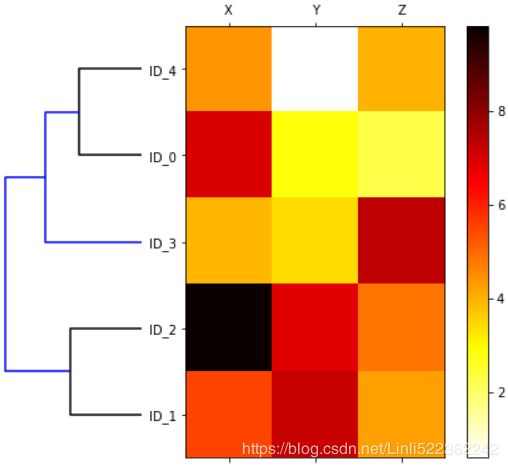
https://docs.scipy.org/doc/scipy/reference/generated/scipy.cluster.hierarchy.dendrogram.html
As we can see, the row order in the heat map reflects the clustering of the samples in the dendrogram. In addition to a simple dendrogram, the color-coded values of each sample and feature in the heat map provide us with a nice summary of the dataset. (This example just for demo, I'm not suggest to use heatmap for different feature with different scales)
Applying agglomerative clustering via scikit-learn
In this section, we saw how to perform agglomerative hierarchical clustering using SciPy. However, there is also an Agglomerative Clustering implementation in scikit-learn, which allows us to choose the number of clusters that we want to return. This is useful if we want to prune the hierarchical cluster tree. By setting the n_cluster parameter to 2, we will now cluster the samples into two groups using the same complete linkage approach based on the Euclidean distance metric as before:
from sklearn.cluster import AgglomerativeClustering
############
ac = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='complete')
labels = ac.fit_predict(X)
print('Cluster labels: %s' % labels)![]()
########################
from sklearn.cluster import AgglomerativeClustering
############
ac = AgglomerativeClustering(n_clusters=3, affinity='euclidean', linkage='complete')
labels = ac.fit_predict(X)
print('Cluster labels: %s' % labels)![]()
########################
df # <==X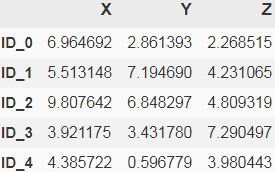
![]()
Looking at the predicted cluster labels, we can see that the first, fourth, and fifth sample (ID_0, ID_3, and ID_4) were assigned to one cluster (0), and the samples ID_1 and ID_2 were assigned to a second cluster (1), which is consistent with the
results that we can observe in the dendrogram.
Locating regions of high density via DBSCAN
Although we can't cover the vast number of different clustering algorithms in this chapter, let's at least introduce one more approach to clustering: Density-based Spatial [ˈspeɪʃl]空间的 Clustering of Applications with Noise (DBSCAN). The notion of density in DBSCAN is defined as the number of data points within a specified radius ![]() (epsilon).
(epsilon).
In DBSCAN, a special label is assigned to each sample (point) using the following criteria:
- A point is considered as core point if at least a specified number (MinPts) of neighboring points fall within the specified radius
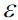 .
. - A border point is a point that has fewer neighbors than MinPts within ,but lies within the radius of a core point
- All other points that are neither core nor border points are considered as noise points
After labeling the points as core, border, or noise points, the DBSCAN algorithm can be summarized in two simple steps:
- Form a separate cluster for each core point or connected group of core points (core points are connected if they are no farther away than ).
- Assign each border point to the cluster of its corresponding core point.
To get a better understanding of what the result of DBSCAN can look like before jumping to the implementation, let's summarize what you have learned about core points, border points, and noise points in the following figure:
One of the main advantages of using DBSCAN is that it does not assume that the clusters have a spherical shape as in k-means. Furthermore, DBSCAN is different from k-means and hierarchical clustering in that it doesn't necessarily assign each point to a cluster but is capable of removing noise points.
For a more illustrative example, let's create a new dataset of half-moon-shaped structures to compare k-means clustering, hierarchical clustering, and DBSCAN:
from sklearn.datasets import make_moons
X,y = make_moons( n_samples=200, noise=0.05, random_state=0 )
plt.scatter( X[:,0], X[:,1] )
plt.show()As we can see in the resulting plot, there are two visible, half-moon-shaped groups consisting of 200 sample points each:

We will start by using the k-means algorithm and complete linkage clustering to see if one of those previously discussed clustering algorithms can successfully identify the half-moon shapes as separate clusters. The code is as follows:
f, (ax1, ax2) = plt.subplots(1,2, figsize=(10,3))
km = KMeans( n_clusters=2, random_state=0 )
y_km = km.fit_predict(X)
ax1.scatter( X[y_km==0, 0], X[y_km==0, 1], c='lightblue', edgecolor='black', marker='o', s=40,
label='cluster 1' )
ax1.scatter( X[y_km==1, 0], X[y_km==1, 1], c='red', edgecolor='black', marker='s', s=40,
label='cluster 2' )
ax1.set_title( 'K-means clustering' )
ac = AgglomerativeClustering( n_clusters=2, affinity='euclidean', linkage='complete' )
y_ac = ac.fit_predict(X)
ax2.scatter( X[y_ac==0, 0], X[y_ac==0, 1], c='lightblue', edgecolor='black', marker='o', s=40,
label='cluster 1' )
ax2.scatter( X[y_ac==1, 0], X[y_ac==1, 1], c='red', edgecolor='black', marker='s', s=40,
label='cluster 2' )
ax2.set_title('Agglomerative clustering')
plt.legend()
plt.show()Based on the visualized clustering results, we can see that the k-means algorithm is unable to separate the two cluster, and also the hierarchical clustering algorithm was challenged by those complex shapes:

Finally, let us try the DBSCAN algorithm on this dataset to see if it can find the two half-moon-shaped clusters using a density-based approach:
from sklearn.cluster import DBSCAN
db = DBSCAN( eps=0.2, min_samples=5, metric='euclidean' )
y_db = db.fit_predict(X)
plt.scatter( X[y_db==0,0], X[y_db==0,1], c='lightblue', marker='o', s=40, label='cluster 1')
plt.scatter( X[y_db==1,0], X[y_db==1,1], c='red', marker='s', s=40, label='cluster 2')
plt.legend()
plt.show() The DBSCAN algorithm can successfully detect the half-moon shapes, which highlights one of the strength of DBSCAN: clustering data of arbitrary shapes:
However, we shall also note some of the disadvantages of DBSCAN. With an increasing number of features in our dataset—assuming a fixed number of training examples—the negative effect of the curse of dimensionality increases. This is especially a problem if we are using the Euclidean distance metric. However, the problem of the curse of dimensionality is not unique to DBSCAN; it also affects other clustering algorithms that use the Euclidean distance metric, for example, kmeans and hierarchical clustering algorithms. In addition, we have two hyperparameters in DBSCAN (MinPts and ![]() ) that need to be optimized to yield good clustering results. Finding a good combination of MinPts and
) that need to be optimized to yield good clustering results. Finding a good combination of MinPts and ![]() can be problematic if the density differences in the dataset are relatively large.
can be problematic if the density differences in the dataset are relatively large.
#######################################
So far, we saw three of the most fundamental categories of clustering algorithms: prototype-based clustering with k-means, agglomerative hierarchical clustering, and density-based clustering via DBSCAN. However, I also want to mention a fourth class of more advanced clustering algorithms that we have not covered in this chapter: graph-based clustering. Probably the most prominent members of the graph-based clustering family are spectral clustering algorithms谱聚类算法 . Although there are many different implementations of spectral clustering, they all have in common that they use the eigenvectors of a similarity matrix to derive the cluster relationships. Since spectral clustering is beyond the scope of this book, you can read the excellent tutorial by Ulrike von Luxburg to learn more about this topic (U. Von Luxburg. A Tutorial on Spectral Clustering. Statistics and computing, 17(4):395–416, 2007). It is freely available from arXiv at http://arxiv.org/pdf/0711.0189v1.pdf.
#######################################
Note that, in practice, it is not always obvious which clustering algorithm will perform best on a given dataset, especially if the data comes in multiple dimensions that make it hard or impossible to visualize. Furthermore, it is important to emphasize that a successful clustering not only depends on the algorithm and its hyperparameters. Rather, the choice of an appropriate distance metric and the use of domain knowledge that can help guide the experimental setup can be even more important.
In the context of the curse of dimensionality, it is thus common practice to apply dimensionality reduction techniques prior to performing clustering. Such dimensionality reduction techniques for unsupervised datasets include principal
component analysis and RBF kernel principal component analysis, which we
covered in Chapter 5(https://blog.csdn.net/Linli522362242/article/details/105196037, https://blog.csdn.net/Linli522362242/article/details/105139547, https://blog.csdn.net/Linli522362242/article/details/105722461), Compressing Data via Dimensionality Reduction. Also, it is particularly common to compress datasets down to two-dimensional subspaces, which allows us to visualize the clusters and assigned labels using two-dimensional scatterplots, which are particularly helpful for evaluating the results.
Summary
In this chapter, you learned about three different clustering algorithms that can help us with the discovery of hidden structures or information in data. We started this chapter with a prototype-based approach, k-means, which clusters samples into spherical shapes based on a specified number of cluster centroids. Since clustering is an unsupervised method, we do not enjoy the luxury of ground truth labels to evaluate the performance of a model. Thus, we used intrinsic performance metrics such as the elbow method or silhouette analysis as an attempt to quantify the quality of clustering.
We then looked at a different approach to clustering: agglomerative hierarchical clustering. Hierarchical clustering does not require specifying the number of clusters up front, and the result can be visualized in a dendrogram representation, which can help with the interpretation of the results. The last clustering algorithm that we saw in this chapter was DBSCAN, an algorithm that groups points based on local densities and is capable of handling outliers and identifying non-globular shapes.
After this excursion into the field of unsupervised learning, it is now about time to introduce some of the most exciting machine learning algorithms for supervised learning: multilayer artificial neural networks. After their recent resurgence 复苏, neural networks are once again the hottest topic in machine learning research. Thanks to recently developed deep learning algorithms, neural networks are considered state-of-the-art最先进的 for many complex tasks such as image classification and speech recognition. In Chapter 12, Implementing a Multilayer Artificial Neural Network from Scratch, we will construct our own multilayer neural network from scratch. In Chapter 13, Parallelizing Neural Network Training with TensorFlow, we will introduce powerful libraries that can help us to train complex network architectures most efficiently.