Scrapy绕过反爬虫策略汇总
文章目录
- 一、Scrapy无法返回爬取内容的几种可能原因
- 1,ip封锁爬取
- 2,xpath路径不对
- 3,xpath路径出现font,tbody标签
- 4,xpath路径不够明确
- 5,robot协议
- 6,请求头封锁
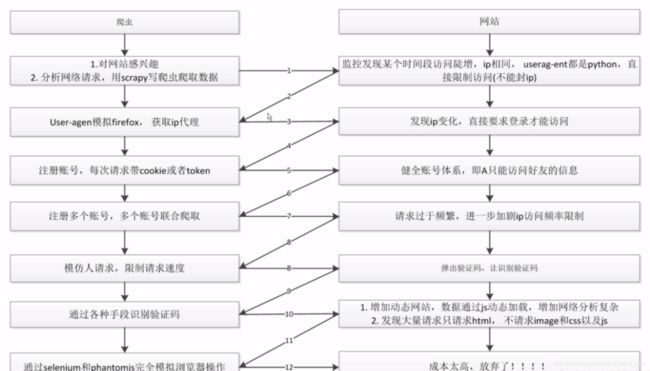
- 二、网站如何识别爬虫?
- 三、网站常见反爬虫策略?
- 五、实战演练
- 四、常见反反爬虫策略?
- 绕过反爬虫策略
- 1.设置下载延迟
- 2.禁用Cookie
- 3.使用user agent池(配置USER_AGENTS 和 PROXIES)
- 4.使用IP池
- 5.分布式爬取:
- 6.验证码验证:
- 7.javascript渲染:
- 8.ajax异步传输:
- 9.加速乐:
- 10.?
- 注:
一、Scrapy无法返回爬取内容的几种可能原因
1,ip封锁爬取
在dos窗口,输入 scrapy shell +你的网址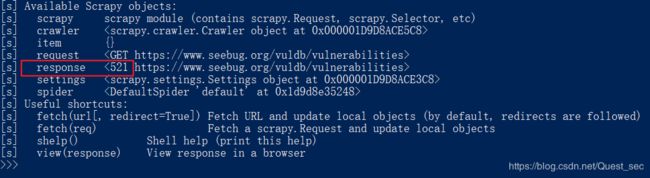
response的返回状态码是521 - Web 服务器已关闭 - 源服务器拒绝了云服务器的连接!
HTTP状态码200,300,404等是什么意思?参考一下网址:
https://www.cnblogs.com/cjwxf/p/6186287.html
https://blog.csdn.net/tan6600/article/details/51584087
2,xpath路径不对
3,xpath路径出现font,tbody标签
把它去掉改成 ***/***,之后内容可以正常显示,说明scrapy识别不了这两个标签。
4,xpath路径不够明确
观察你要爬取网页html结构,对要爬取的元素位置,最好把它的类名或者是id名写上,以保证路径的唯一性。
5,robot协议
如果在dos窗口中已经可以提取出要爬取的内容了,说明xpath路径正确,但是在编写的爬虫文件中,执行spider却不能爬取到结果,而在执行爬虫程序的dos窗口中,你仔细观察,发现有robot错误,response的返回编码是503之类的异常编码,那就需要你在setting.py中,把ROBOTSTXT_OBEY = True 改为 False。
6,请求头封锁
这个网址在浏览器中可以打开,但是scrapy中不行,scrapy shell +网址来执行后出现下图连接错误

这是因为scrapy的默认请求头是:“User-Agent”:“Scrapy/1.1.2 (+http://scrapy.org)”被网站封锁了,所以你需要伪造一个网站的请求头去进入这个网站。
你执行scrapy shell https://www.qiushibaike.com/ -s USER_AGENT=‘Mozilla/5.0’ 发现成功访问,所以记得伪造请求头。
参考:https://blog.csdn.net/weixin_44841312/article/details/95670015
————————————————————————————————
二、网站如何识别爬虫?
方法1:http日志和流量分析,如果单位时间内某个IP访问频率和流量超过特定阈值就可以界定为爬虫(封禁IP)
方法2:检测Headers参数:一般有User-Agent,Referer、Cookies等
1.User-Agent是检查用户所用客户端的种类和版本,在Scrapy中,通常是在下载器中间件中进行处理。
2.Referer是检查此请求由哪里来,通常可以做图片的盗链判断。在Scrapy中,如果某个页面url是通过之前爬取的页面提取到,Scrapy会自动把之前爬取的页面url作为Referfer。也可以通过上面的方式自己定义Referfer字段。
3.网站可能会检测Cookie中session_id的使用次数,如果超过限制,就触发反爬策略。
方法3:在网页源码内放置一个对浏览器不可见的链接,正常用户使用浏览器是看不到该链接的当然也不会去点击,如果检测到该链接被点击,来访IP就会被界定为爬虫。
三、网站常见反爬虫策略?
1.临时或永久封禁来访ip
2.返回验证码
3.异步加载(ajax):使只爬取静态网页的爬虫什么也得不到
4.爬虫陷阱:让你爬取的内容变成其他和本网站无关的信息
5.加速乐的服务:在访问之前先判断客户端的cookie正不正确。如果不正确,返回521状态码,set-cookie并且返回一段js代码通过浏览器执行后又可以生成一个cookie,只有这两个cookie一起发送给服务器,才会返回正确的网页内容。
6.javascript渲染:网页开发者将重要信息放在网页中但不写入html标签中,而浏览器会自动渲染
五、实战演练
1、在setting修改默认的User-Agent、默认HEADERS
参考:
https://blog.csdn.net/weixin_43430036/article/details/84851714
2、IP代理(未验证)
import requests
url = "http://www.baidu.com"
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
response = requests.get(url, proxies=proxies)
print response.content

3、python爬虫添加请求头:
不止有一种,根据用的方法为request、urllib、phantomjs请求等,有区别。
四、常见反反爬虫策略?
(1)设置等待时间
① 直接:导入time,然后限制时间为正常人浏览时间
② 间接:看具体情况来等待,比如某些元素需要一定时间加载。wait1.until(lambda driver:driver.find_element_by_xpath("//div[@id=‘link-report’]/span"))
(2 )使用高匿代理IP解决;
(3)针对验证码——如果不是每次都弹验证码也可以使用高匿代理IP解决,如果感觉高匿代理不稳定或者收集起来不方便使用Tor网络也可以,如果每次都弹验证码那就得涉及到验证码识别了,简单的验证码可以自己写代码处理,python有不少知名的图像处理(识别)库(如PIL/Pillow、Mahotas、Pymorph、pytesser、tesseract-ocr、openCV等)和算法(比如大名鼎鼎的KNN[K邻近算法]和SVM[支持向量机]);但复杂的验证码例如涉及逻辑判断和计算、字符粘连变形、前置噪音多色干扰、多语种字符混搭的,可能需要调用在线验证码识别软件接口识别验证码,正确率百分之八九十以上。
(4)异步加载:网页内容不会一次性全部展示出来,需要将滚动条滑到最底部才能继续浏览下一页内容。
① fiddler / wireshark抓包分析ajax请求的界面,再通过规律仿造服务器构造一个请求访问服务器得到返回的真实数据包。
② 通过PhantomJS+Selenium模拟浏览器行为,抓取经过js渲染后的页面。phantomjs是一个无头无界面浏览器,使用selenium可以驱动它模拟浏览器的一切操作,但缺点也很明显,爬取效率低;注意的是,调用PhantomJs需要指定PhantomJs的可执行文件路径,通常是将该路径添加到系统的path路径,让程序执行时自动去path中寻找。使用Selenium后,请求不再由Scrapy的Downloader执行,所以之前添加的请求头等信息都会失效,需要在Selenium中重新添加。本方法缺点也很明显,爬取效率低;
(5)爬虫陷阱:看情况而定,如果是比较简单的死循环陷阱,可以对爬虫将要爬取的链接进行判断,不重复爬取相同的页面,除此之外,对于特定的元素看清之后小心爬取,还可使用scrapy的LinkExtractor设定unique参数为True即可或者直接设定爬虫的最大循环次数。
此外增加爬取间隔和禁用cookie也能降低爬虫被ban的概率。
(6)针对用户行为:
① cookie禁用:对于一些不需要登录的网站,可以在setting.py文件中设置COOKIES_ENABLED = False
② 自动限速:在setting.py文件中设置DOWNLOAD_DELAY = 1
③判断header:在请求时构造一个header,每次url请求更换一次user-agent。可以百度,也可看看之前的文章
④ 采用代理IP:可以做一个IP代理池,每次运行时随机挑选一个做访问IP。IP代理有收费有免费(免费的代理不一定能用,需要先做一下测试)
参考:
https://blog.csdn.net/xiaoxianerqq/article/details/82884725
https://blog.csdn.net/weixin_41931602/article/details/80679623
————————————————————————————————————————————————
csdn代码是按照这两个:
https://www.jianshu.com/p/ba1bba6670a6 与 https://www.tuicool.com/articles/VRfQR3U 类似,各有侧重点点
仍然是策略与反策略的理论知识 https://www.cnblogs.com/micro-chen/p/8676312.html
绕过反爬虫策略
1.设置下载延迟
在settings.py文件中设置
DOWNLOAD_DELAY=3
2.禁用Cookie
有些网站会根据访问的cookie判断是否为机器人,除非特殊要求,我们都禁用cookie,在settings.py做如下设置:
COOKIES_ENABLED=False
原理解释:
服务器对每一个访问网页的人都set-cookie,给其一个cookies,当该cookies访问超过某一个阀值时就BAN掉该COOKIE,过一段时间再放出来,当然一般爬虫都是不带COOKIE进行访问的,然而,网页上有一部分内容如新浪微博是需要用户登录才能查看更多内容。
解决办法:控制访问速度,或者某些需要登录的如新浪微博,在某宝上买多个账号,生成多个cookies,在每一次访问时带上cookies。
3.使用user agent池(配置USER_AGENTS 和 PROXIES)
介绍两种方法:
一、在setings中写一个user agent列表并设置随机方法(让setings替我们选择)
二、在settings中写列表,在middleware.py中创建类,在downloadmiddleware中调用(让中间件完成选择)
第一种:settings创建user agent表,导入random,随机用choise函数调用user agent。
import random
# user agent 列表
USER_AGENT_LIST = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)',
'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)',
'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)',
'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0',
'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]
# 随机生成user agent
USER_AGENT = random.choice(USER_AGENT_LIST)
第二种:在middleware中调用user agent。先在setting中注释user agent 防止干扰,在middlewares中创建类
import random
class UserAgentMiddleware(object):
def __init__(self):
self.user_agent_list = [
'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23',
'Opera/9.20 (Macintosh; Intel Mac OS X; U; en)',
'Opera/9.0 (Macintosh; PPC Mac OS X; U; en)',
'iTunes/9.0.3 (Macintosh; U; Intel Mac OS X 10_6_2; en-ca)',
'Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)',
'iTunes/4.2 (Macintosh; U; PPC Mac OS X 10.2)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0',
'Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)',
'Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)'
]
#这个方法会在请求之前执行,所以可以添加代理pi和随机请求头等,参数2是发送的请求,参数3是发送请求的spider对象
def process_request(self,request,spider):
request.headers['USER_AGENT']=random.choice(self.user_agent_list)
然后在setting里面启用随机请求头中间件downloader middleware
DOWNLOADER_MIDDLEWARES = {
'爬虫名.middlewares.UserAgentMiddleware': 543 #而不是300的吧
}
原理解释:
“用户代理”——UA字串的标准格式:浏览器标识 (操作系统标识; 加密等级标识; 浏览器语言) 渲染引擎标识版本信息。
服务器通过它判断当前访问对象是浏览器、邮件客户端还是网络爬虫。
很多爬虫的请求头是默认的一些很明显的爬虫头python-requests/2.18.4等,当运维人员发现携带有这类headers的数据包,直接拒绝访问,返回403错误。
点击查看关于headers和user_agent?(headers包括UA…)
以上代码来源1:python爬虫之scrapy中user agent浅谈(两种方法)
来源2:scrapy框架-下载中间件
解决方法:把headers伪装成百度爬虫或者其他浏览器头即可。
关于随机请求头https://blog.csdn.net/qingminxiehui/article/details/81671161?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
4.使用IP池
修改settings.py文件中,b):添加代理IP设置PROXIES
PROXIES = [
{'ip_port': '111.11.228.75:80', 'user_pass': ''},
{'ip_port': '120.198.243.22:80', 'user_pass': ''},
{'ip_port': '111.8.60.9:8123', 'user_pass': ''},
{'ip_port': '101.71.27.120:80', 'user_pass': ''},
{'ip_port': '122.96.59.104:80', 'user_pass': ''},
{'ip_port': '122.224.249.122:8088', 'user_pass': ''},
]
#代理IP可以网上搜索一下,上面的代理IP获取自:http://www.xici.net.co/
原理解释:
web server应对爬虫的策略之一就是直接将你的IP或者是整个IP段都封掉禁止访问,这时候,当IP封掉后,转换到其他的IP继续访问即可。
第二种思路:
IP代理这是应对反爬虫的大招,可是免费的代理速度太慢,优质的代理收费又太高,所以个人推荐最好的方式就是ADSL重拨,目的就是通过ADSL的重拨使IP发生变化,穷人的IP池。
5.分布式爬取:
采用分布式爬取。暂时不讲。
6.验证码验证:
解决办法:
python可以通过一些第三方库如(pytesser,PIL)来对验证码进行处理,识别出正确的验证码,复杂的验证码可以通过机器学习让爬虫自动识别复杂验证码,让程序自动识别验证码并自动输入验证码继续抓取
7.javascript渲染:
网页开发者将重要信息放在网页中但不写入html标签中,而浏览器会自动渲染
解决办法:通过分析提取script中的js代码来通过正则匹配提取信息内容或通过webdriver+phantomjs直接进行无头浏览器渲染网页。
案例:前程无忧网随便打开一个前程无忧工作界面,直接用requests.get对其进行访问,可以得到一页的20个左右数据,显然得到的不全,而用webdriver访问同样的页面可以得到50个完整的工作信息。
8.ajax异步传输:
访问网页的时候服务器将网页框架返回给客户端,在与客户端交互的过程中通过异步ajax技术传输数据包到客户端,呈现在网页上,爬虫直接抓取的话信息为空。
解决办法:
通过fiddler或是wireshark抓包分析ajax请求的界面,然后自己通过规律仿造服务器构造一个请求访问服务器得到返回的真实数据包。
案例:
拉勾网打开拉勾网的某一个工作招聘页,可以看到许许多多的招聘信息数据,点击下一页后发现页面框架不变化,url地址不变,而其中的每个招聘数据发生了变化,通过chrome开发者工具抓包找到了一个叫请求了一个叫做https://www.lagou.com/zhaopin/Java/2/?filterOption=3的网页。打开该网页发现为第二页真正的数据源,通过仿造请求可以抓取每一页的数据。
9.加速乐:
有些网站使用了加速乐的服务,在访问之前先判断客户端的cookie正不正确。如果不正确,返回521状态码,set-cookie并且返回一段js代码通过浏览器执行后又可以生成一个cookie,只有这两个cookie一起发送给服务器,才会返回正确的网页内容。
解决办法:详见https://www.cnblogs.com/micro-chen/p/8676312.html
10.?
注:
很多网页的运维者通过组合以上几种手段,然后形成一套反爬策略,就像之前碰到过一个复杂网络传输+加速乐+cookies时效的反爬手段。
切记,放在requests中访问的headers信息一定要和你操控的浏览器headers信息一致,因为服务器端也会检查cookies与headers信息是否一致。
——————————————————————————
存储数据
采用MongoDB数据存储爬取的漏洞数据。 https://www.jianshu.com/p/ba1bba6670a6