利用pandas求表格分组频率
利用pandas可以根据表中的一列来进行分组,之后可以利用.mean()分组求平均,.count分组求和,但碰到了一个特殊情况需要求每组里每个数出现的频率,没有找到现成的方法,就自己写了一个。
思路:
1、先利用groupby分组;
2、遍历每个分组,得到每个组的表内容;
3、在每个分组表里利用value_counts()统计不同值的出现次数,然后利用to_dict()转换成词典(数值:出现次数);
4、计算每个组的值个数,就是求频率时要用到的总数;
5、利用每个值的次数除以总数,这里要注意一下,因为需要与表格里每个值的顺序对应,所以这里根据列中值出现的顺序来对应提取词典里的出现次数,然后做成一个list。
6、遍历求频率;
原始表:

根据A分组,对分组后的C求频率,例如A的值分为1和2,当A=1时,C的值有1,4,1,2四个;当A=2时,C的值有4,4,1,3四个,这样在A=1时,C=1出现的频数C_count=2,C=1的频率C_freq=2/4=0.5:
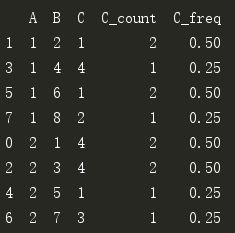
import pandas as pd
# t1=data.index.values
# t2=data.sort_index(axis=1,ascending=True)
# t3=data.sort_values(by='D')
# t4=data.loc[:,['A','B']]
# t5=data.loc[['a','c'],['A','B']]
# t6=data.loc['a','D']
# t7=data.at['a','D']
# t8=data.iloc[1,1]
# t9=data['A']
# t10=data[1:2]
def cal_freq(data,group_by_name,var):
'''
分组计算组内各值频率,并作为新的列插入;
:param data: DataFrame对象;
:param group_by_name: 分组依据列;
:param var: 需要计算频率的列;
:return: new data
'''
new_data=None
group=data.groupby(group_by_name)
for group_name, group_data in group:
val_count=group_data[var].value_counts().to_dict() # 词典{值:频数}
sum = len(list(group_data[var])) # 计算每一组的个数
count=[val_count[_] for _ in group_data[var]] # 每个值出现的次数list,顺序对应var
freq=[_/sum for _ in count] # 每个出现的频率
group_data[var+'_count']=count
group_data[var+'_freq']=freq
if new_data is None:
new_data=group_data
else:
new_data=new_data.append(group_data)
return new_data
if __name__=='__main__':
#data = pd.read_excel('11.xlsx', 'Sheet1')
data=pd.DataFrame({
'A':[2,1,2,1,2,1,2,1],
'B':[1,2,3,4,5,6,7,8],
'C':[4,1,4,4,1,1,3,2]
})
new_data=cal_freq(data,'A','C')
print(data)
print(new_data)