python 爬虫 9 (scrapy实例:翻页爬取、爬个人页、存入mysql、redis)
文章目录
- 写在前面
- 1、新片场翻页爬取
- 1.1、模仿登录
- 1.2、访问上限
- 2、爬取个人详情页
- 3、存入mysql
- 4、存入redis
写在前面
本篇笔记接【python 爬虫
7】:https://blog.csdn.net/a__int__/article/details/104762424
1、新片场翻页爬取
查看每页连接
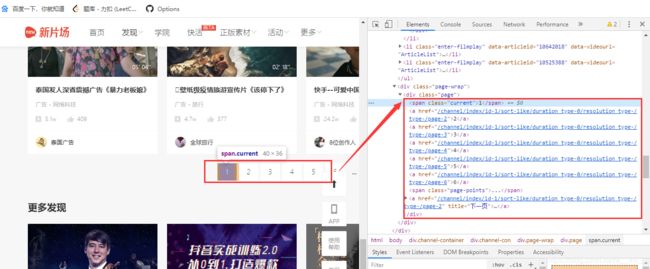
爬取连接
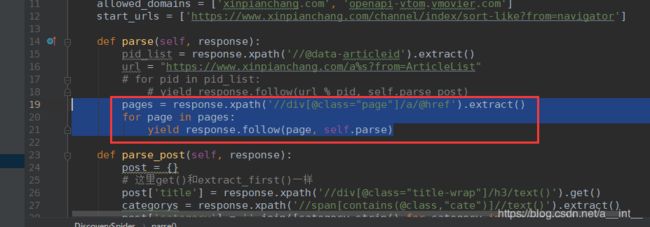
pages = response.xpath('//div[@class="page"]/a/@href').extract()
for page in pages:
yield response.follow(page, self.parse)
我们发现最多只能爬取到第22页
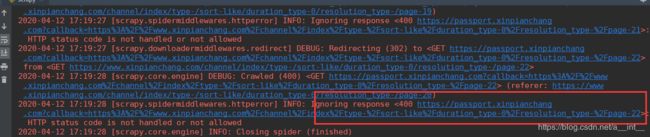
爬22页后面的内容需要登录
1.1、模仿登录
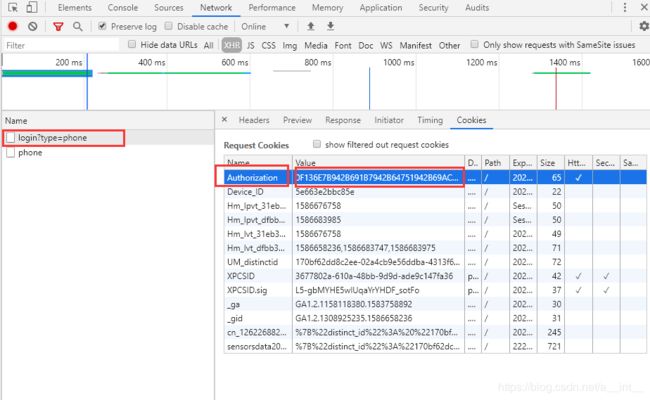
点击登录,抓取cookie
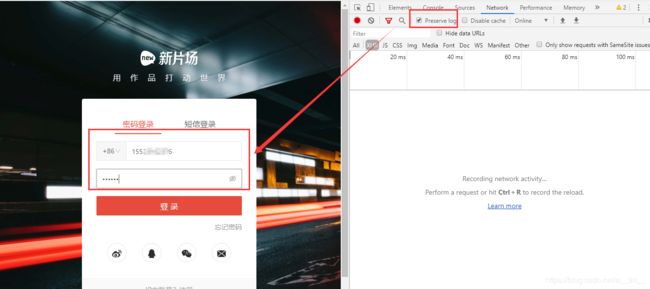
把这串证书复制下来
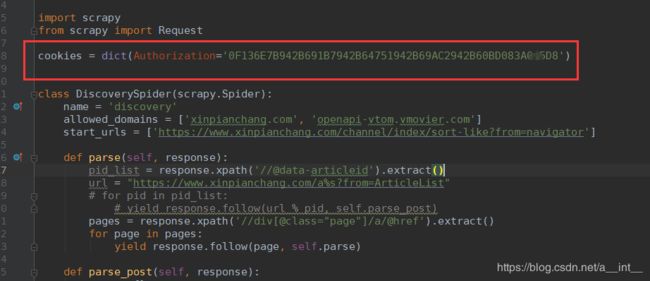
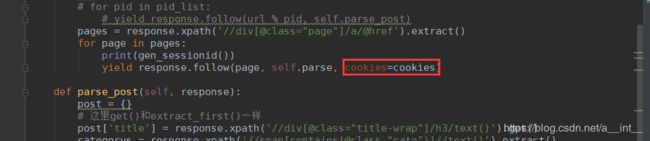
settings:
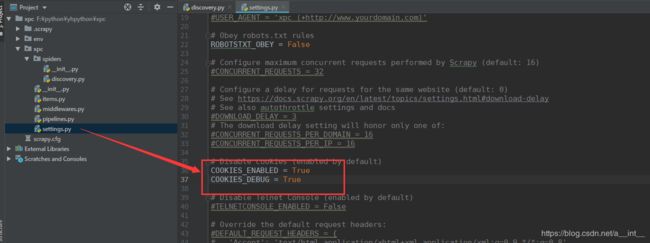
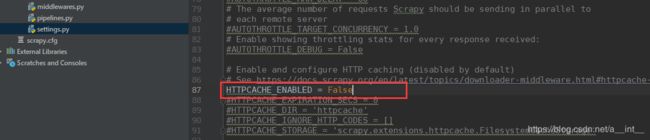
重新执行,发现抓取到100多条的时候就停止了。
1.2、访问上限
找到PHPSESSID
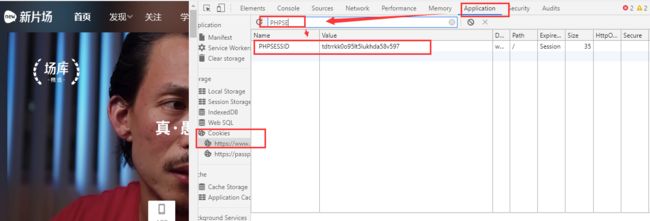
查看这串字符,长度为26

我们写一个PHPSESSID生成器
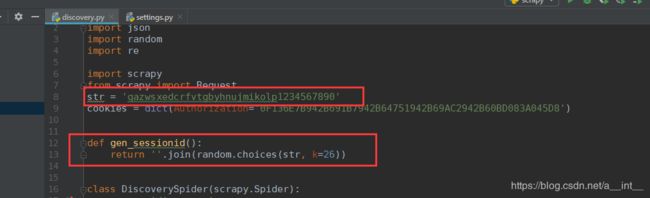
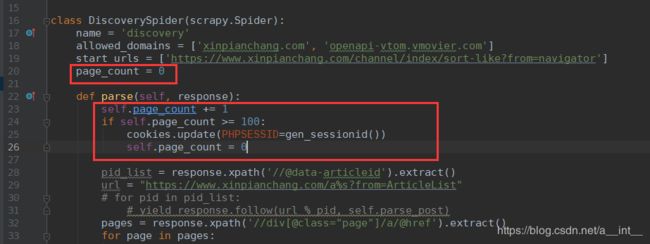
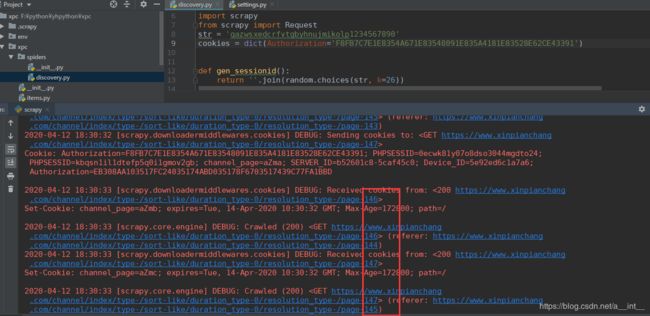
现在就能成功访问多条数据了
2、爬取个人详情页
把爬取视频详情页 打开
打开详情页发现每个用户详情页地址通过data-userid变化
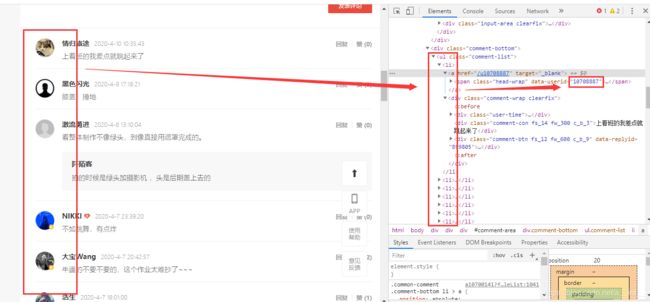
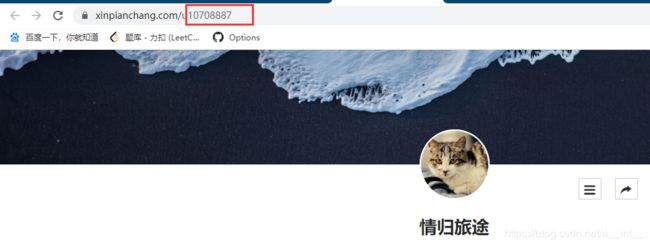
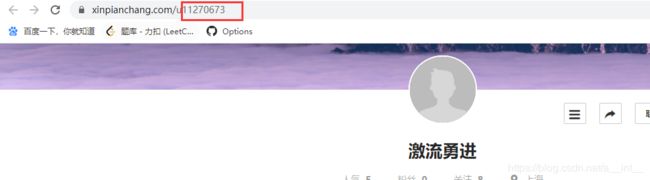
爬取用户id
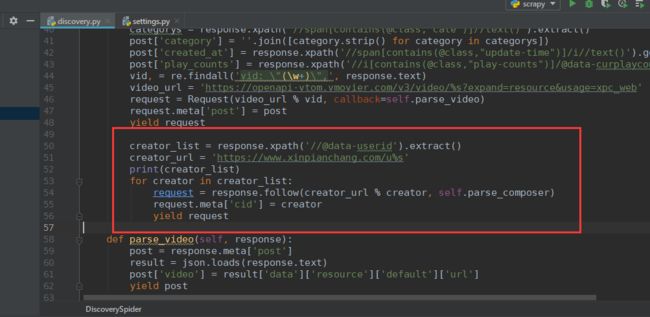
creator_list = response.xpath('//@data-userid').extract()
creator_url = 'https://www.xinpianchang.com/u%s'
print(creator_list)
for creator in creator_list:
request = response.follow(creator_url % creator, self.parse_composer)
request.meta['cid'] = creator
yield request
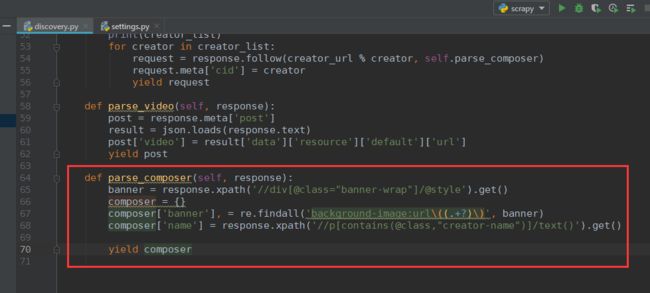
def parse_composer(self, response):
banner = response.xpath('//div[@class="banner-wrap"]/@style').get()
composer = {}
composer['banner'], = re.findall('background-image:url\((.+?)\)', banner)
composer['name'] = response.xpath('//p[contains(@class,"creator-name")]/text()').get()
yield composer
运行之后其他的都没问题,visit_userid_10037339=1; 这个值会被迭代
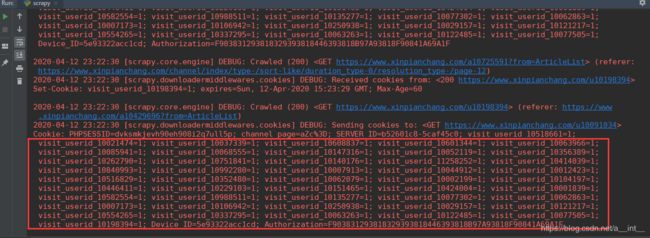
访问网页发现,这个值在每次切换个人详情页的时候,就会被设置一次,每隔30几秒会自动删除,这30几秒内连续访问会迭代
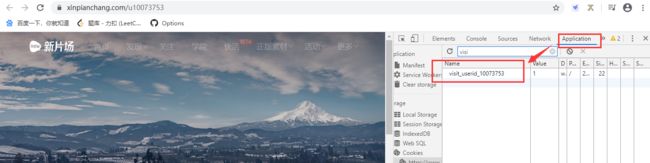
退出登录后访问发现,访问个人详情页是不需要登录的,所以我们关掉这个页面访问时的cookie
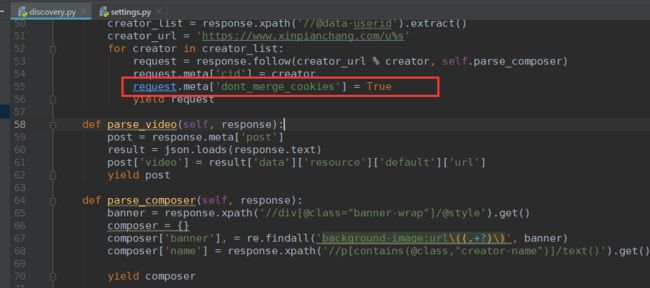
再次抓取就没有这个问题了
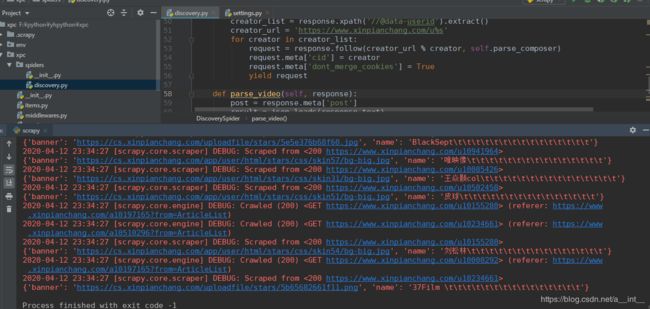
3、存入mysql
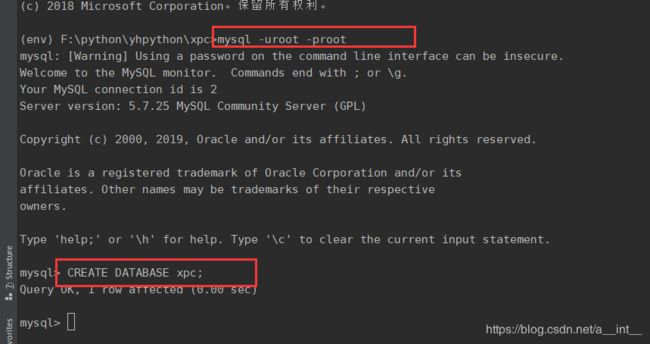
创建数据库xpc: CREATE DATABASE xpc;
新建表composer
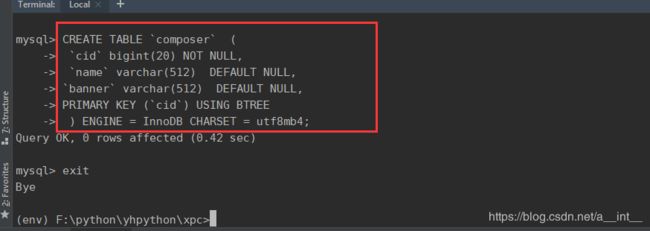
CREATE TABLE `composer` (
`cid` bigint(20) NOT NULL,
`name` varchar(512) DEFAULT NULL,
`banner` varchar(512) DEFAULT NULL,
PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARSET = utf8mb4;
items.py
import scrapy
from scrapy import Field
class ComposerItem(scrapy.Item):
"""保存个人详情页信息"""
table_name = 'composer'
cid = Field()
banner = Field()
name = Field()
settings.py
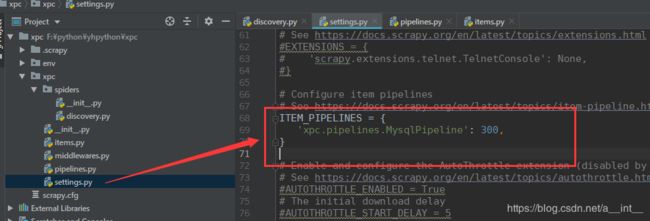
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
import redis
from scrapy.exceptions import DropItem
class RedisPipeline(object):
def open_spider(self, spider):
self.r = redis.Redis(host='127.0.0.1')
def process_item(self, item, spider):
if self.r.sadd(spider.name, item['name']):
return item
# 如果添加name失败就自动删除item,并停止执行process_item
raise DropItem
class MysqlPipeline(object):
def open_spider(self, spider):
self.conn = pymysql.connect(
host="127.0.0.1",
port=3306,
db="xpc",
user="root",
password="root",
charset="utf8",
)
self.cur = self.conn.cursor()
def close_spider(self, spider):
self.cur.close()
self.conn.close()
def process_item(self, item, spider):
keys, values = zip(*item.items())
sql = "insert into {} ({}) values ({})" \
" ON DUPLICATE KEY UPDATE {};".format(
item.table_name,
','.join(keys),
','.join(["'%s'"] * len(values)),
','.join(["{}='%s'".format(k) for k in keys])
)
sqlp = (sql % (values*2))
self.cur.execute(sqlp)
self.conn.commit()
# 显示sql语句
print(self.cur._last_executed)
return item
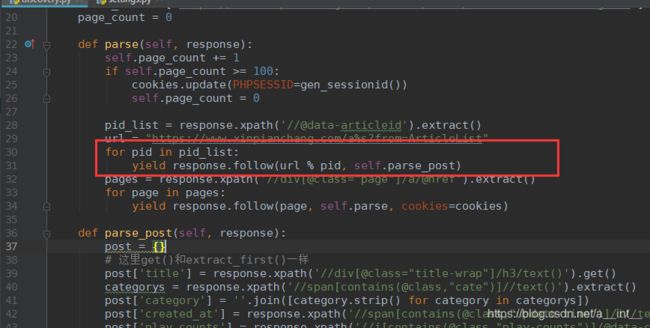
修改discovery.py
# -*- coding: utf-8 -*-
import json
import random
import re
import scrapy
from scrapy import Request
from xpc.items import ComposerItem
str = 'qazwsxedcrfvtgbyhnujmikolp1234567890'
cookies = dict(Authorization='F8FB7C7E1E8354A671E83548091E835A4181E83528E62CE43391')
def gen_sessionid():
return ''.join(random.choices(str, k=26))
class DiscoverySpider(scrapy.Spider):
name = 'discovery'
allowed_domains = ['xinpianchang.com', 'openapi-vtom.vmovier.com']
start_urls = ['https://www.xinpianchang.com/channel/index/sort-like?from=navigator']
page_count = 0
def parse(self, response):
self.page_count += 1
if self.page_count >= 100:
cookies.update(PHPSESSID=gen_sessionid())
self.page_count = 0
pid_list = response.xpath('//@data-articleid').extract()
url = "https://www.xinpianchang.com/a%s?from=ArticleList"
for pid in pid_list:
yield response.follow(url % pid, self.parse_post)
pages = response.xpath('//div[@class="page"]/a/@href').extract()
for page in pages:
yield response.follow(page, self.parse, cookies=cookies)
def parse_post(self, response):
# post = {}
# 这里get()和extract_first()一样
# post['title'] = response.xpath('//div[@class="title-wrap"]/h3/text()').get()
# categorys = response.xpath('//span[contains(@class,"cate")]//text()').extract()
# post['category'] = ''.join([category.strip() for category in categorys])
# post['created_at'] = response.xpath('//span[contains(@class,"update-time")]/i//text()').get()
# post['play_counts'] = response.xpath('//i[contains(@class,"play-counts")]/@data-curplaycounts').get()
# vid, = re.findall('vid: \"(\w+)\",', response.text)
# video_url = 'https://openapi-vtom.vmovier.com/v3/video/%s?expand=resource&usage=xpc_web'
# request = Request(video_url % vid, callback=self.parse_video)
# request.meta['post'] = post
# yield request
creator_list = response.xpath('//@data-userid').extract()
creator_url = 'https://www.xinpianchang.com/u%s'
for creator in creator_list:
request = response.follow(creator_url % creator, self.parse_composer)
request.meta['cid'] = creator
request.meta['dont_merge_cookies'] = True
yield request
# def parse_video(self, response):
# # post = response.meta['post']
# result = json.loads(response.text)
# if 'resource' in result['data']:
# post['video'] = result['data']['resource']['default']['url']
# else:
# d = result['data']['third']['data']
# post['video'] = d.get('iframe_url', d.get('swf', ''))
# yield post
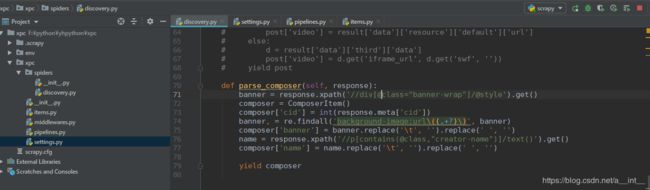
def parse_composer(self, response):
banner = response.xpath('//div[@class="banner-wrap"]/@style').get()
composer = ComposerItem()
composer['cid'] = int(response.meta['cid'])
banner, = re.findall('background-image:url\((.+?)\)', banner)
composer['banner'] = banner.replace('\t', '').replace(' ', '')
name = response.xpath('//p[contains(@class,"creator-name")]/text()').get()
composer['name'] = name.replace('\t', '').replace(' ', '')
yield composer
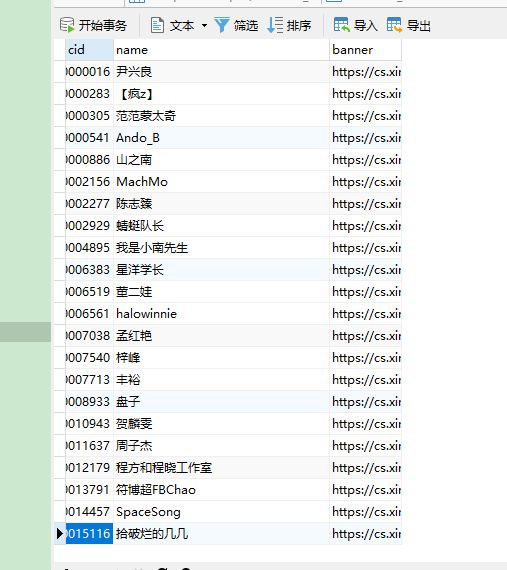
4、存入redis
settings.py
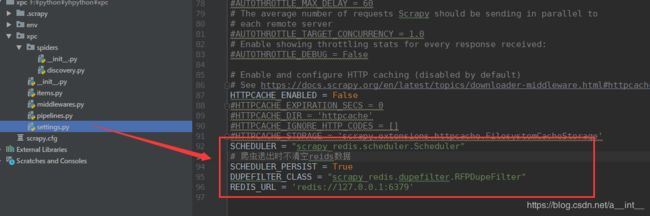
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_URL = 'redis://127.0.0.1:6379'
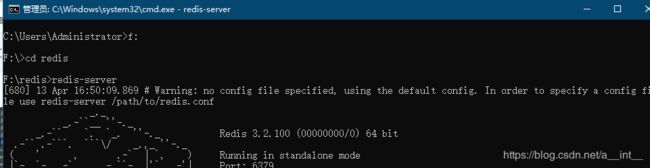
启动redis
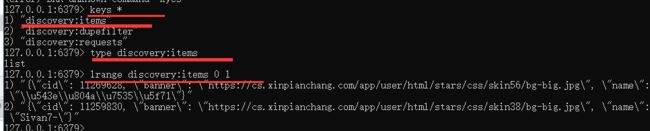
查看redis的key

安装scrapy-redis:pip install scrapy-redis
![]()
启动爬虫
查看redis


查看discovery:dupefilter里面存的内容: srandmember discovery:dupefilter
![]()
zrange discovery:requests 0 0 withscores

在ipython里面解析字符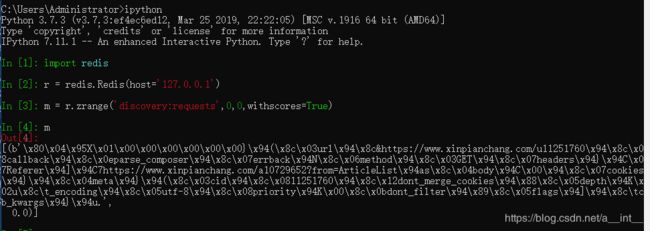
分析这串数据,发现它是列表包含元组这样的结构
![]()
用pickle进行二进制序列化
![]()
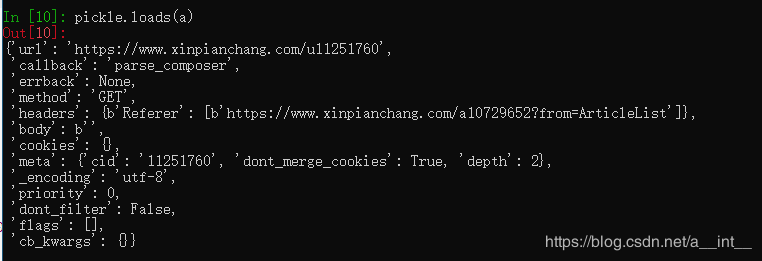
In [1]: import redis
In [2]: r = redis.Redis(host='127.0.0.1')
In [3]: m = r.zrange('discovery:requests',0,0,withscores=True)
In [7]: import pickle
In [9]: (a,b), = m
In [10]: pickle.loads(a)
将数据存入redis(一般不会把redis当数据库用)
settings.py
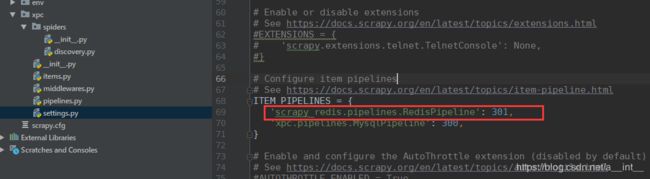
‘scrapy_redis.pipelines.RedisPipeline’: 301,
运行爬虫
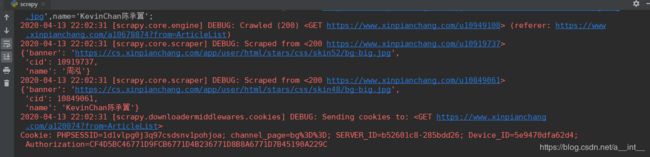
查看redis