用Python看新闻,掌握最新疫情

本文知识点:Python, RSS, gevent,PyQt5
记着十几年前,看新闻还是一件很轻松的事。打开Google Reader,天下新闻尽在我手。各大知名博主每天都在更新高质量的文章。而到了今天,新闻app有十几个,一天能推送几十篇各大小明星的烂事,说好的人工智能呢?
那只能自力更生,自己打造一个了。RSS源虽然不多了,但剩下的都是精品。而且还有爱好者打造的rsshub这样的开源项目, 收集了各大网站的自制RSS源。我们就差一个好的客户端了。
拿出祖传的从feedly导出的opml文件,其它rss服务器应该也有导出功能,它包含了你订阅的所有源。而opml文件只是一个简单的xml文件,用lxml很容易就可以拿到需要的rss网址
with open('feedly.opml', encoding='utf-8') as opml:
feeds = etree.parse(opml)
feeds = feeds.xpath('/opml/body/outline')
return feeds
Python对RSS格式最好的还是feedparser, 依然还在持续更新。
show_rss方法里会调用feedparser解析rss网址
def show_rss(rss):
try:
titles = []
print(f"loading {rss}")
result = feedparser.parse(rss)
print(f"loaded {rss}:{result}")
for e in result.entries:
print(e.title)
titles.append(e.title)
return {rss: titles}
except Exception as e:
pp.pprint(e)
return {rss: titles}
这个opml有上百个RSS源,如果按顺序读取的话,速度就太慢了。就想想用多线程。打开feedparser的源码一看,用的是urllib。那我们就可以上gevent调用纤程加载所有的RSS源,它的monkey补丁可以直接修改urllib成协作式的调度方式。
import gevent
from gevent import monkey
gevent.monkey.patch_all()
for feed in feeds:
for rss in feed.iterchildren():
rsslist.append(rss.get('xmlUrl'))
jobs = [gevent.spawn(show_rss, rss) for rss in rsslist]
gevent.joinall(jobs, timeout=20)
result = [job.value for job in jobs]
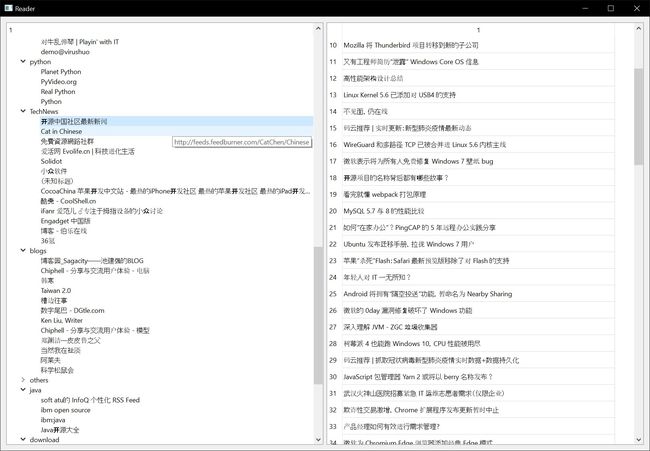
运行后速度飞快,两秒不到全部读完。但基于网速的问题,可能有些站点没有及时响应。可以根据需要修改上面的timeout值。 下来就上个图形界面。PyQt5 用一个QTreeWidget显示RSS源标题列表, 点击事件关联到上面的读取方法后存在QTableWidget里显示所有新闻标题。
虽然我们可以很短时间内读取所有信息,但也没必要每次点击都读取一次,用一个dict缓存一下就好了。
titles = []
if len(self.feeds) == 0:
self.feeds = feed_loader.load()
if feed in self.feeds.keys():
titles = self.feeds[feed]
最后的界面如下,非常简洁吧!(其实是不会设计)