实战:Shardingsphere分库分表
前言
由于关系型数据库大多采用B+树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的IO次数增加,进而导致查询性能的下降;同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。
项目介绍
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere 定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。它通过关注不变,进而抓住事物本质。
官方地址:http://shardingsphere.apache.org
本文目标
本文将以springboot进行集成演示,以订单表为例,演示shardingsphere分库分表的基本原理及配置。
项目产生的demo地址见尾部。
实战
数据库脚本
id主键不设置为自增,分别在db0和db1创建t_order_2019、t_order_2020三个表
CREATE TABLE `t_order` (
`id` bigint(20) NOT NULL,
`order_sn` varchar(255) DEFAULT NULL COMMENT '订单编号',
`member_id` varchar(255) DEFAULT NULL COMMENT '用户id',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`status` int(11) DEFAULT NULL COMMENT '订单状态',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
maven依赖
4.0.0-RC2
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
${sharding-sphere.version}
配置文件
配置db0和db1两个数据库,定义数据库路由规则为member_id除以2取余。
每个数据库创建t_order_0、t_order_1、t_order_2三张表,定义表的路由规则为member_id除以3取余。
mybatis.mapper-locations=classpath:mybatis/*Mapper.xml
logging.level.com.lzn.shardingsphere.dao=debug
spring.shardingsphere.datasource.names = db0,db1
spring.shardingsphere.datasource.db0.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db0.driver-class-name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db0.jdbc-url = jdbc:mysql://192.168.202.128:3306/sharding?characterEncoding=utf8&useSSL=false
spring.shardingsphere.datasource.db0.username = root
spring.shardingsphere.datasource.db0.password = 123qwe
spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db1.jdbc-url = jdbc:mysql://192.168.202.128:3307/sharding?characterEncoding=utf8&useSSL=false
spring.shardingsphere.datasource.db1.username = root
spring.shardingsphere.datasource.db1.password = 123qwe
# 分库策略 根据id取模确定数据进哪个数据库
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column = member_id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression = db$->{member_id % 2}
# 分表策略
# 节点 db0.t_order_0,db0.t_order_1,db0.t_order_2,db1.t_order_0,db1.t_order_1,db1.t_order_2
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = db$->{0..1}.t_order_$->{0..2}
# 分表字段member_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = member_id
# 分表策略 根据member_id取模,确定数据最终落在那个表中
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{member_id % 3}
# 使用SNOWFLAKE算法生成主键
spring.shardingsphere.sharding.tables.t_order.key-generator.column = id
spring.shardingsphere.sharding.tables.t_order.key-generator.type = SNOWFLAKE
数据库持久层
使用mybatis-generator生成
实体类
 image-20200615171558278
image-20200615171558278
Dao接口
 image-20200615171449030
image-20200615171449030
sql文件
 image-20200615172144593
image-20200615172144593
启动项目
 image-20200615152237950
image-20200615152237950
测试验证
插入测试:准备member_id分别为 100,101,102,103的
预期结果:依次在db0.t_order_1、db1.t_order_2、db0.t_order_0、db1.order_1
单元测试类
@Test
void TestInsertOrder(){
List orderList = new ArrayList<>();
orderList.add(new Order("111111",100L,new Date(),1));
orderList.add(new Order("222222",101L,new Date(),1));
orderList.add(new Order("333333",102L,new Date(),1));
orderList.add(new Order("444444",103L,new Date(),1));
for(Order order:orderList){
orderService.createOrder(order);
}
}
 image-20200615172440925
image-20200615172440925
插入验证
member_id = 100 路由到db0.t_order_1
 image-20200615173904768
image-20200615173904768
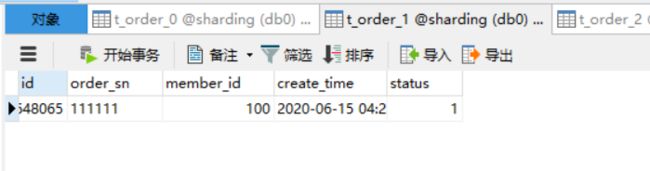 image-20200615172702673
image-20200615172702673
member_id = 101 路由到 db1.t_order_2
 image-20200615174037627
image-20200615174037627
 image-20200615172833384
image-20200615172833384
member_id = 102 路由到 db0.t_order_0
 image-20200615174754591
image-20200615174754591
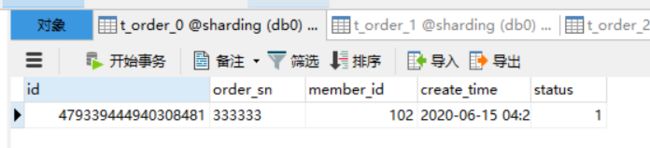 image-20200615172639393
image-20200615172639393
member_id = 103 路由到 db1.t_order_1
 image-20200615175039272
image-20200615175039272
 image-20200615172746566
image-20200615172746566
查询验证
不带分片键的查询
@Test
void TestListOrder(){
OrderExample orderExample = new OrderExample();
List orderList= orderService.listOrder(orderExample);
for (Order o:orderList){
System.out.println(o.toString());
}
}
此时会全库全表查询,并将结果汇总
2020-06-15 18:00:59.099 INFO 948 --- [ main] ShardingSphere-SQL : Actual SQL: db0 ::: select
id, order_sn, member_id, create_time, status
from t_order_0
2020-06-15 18:00:59.099 INFO 948 --- [ main] ShardingSphere-SQL : Actual SQL: db0 ::: select
id, order_sn, member_id, create_time, status
from t_order_1
2020-06-15 18:00:59.099 INFO 948 --- [ main] ShardingSphere-SQL : Actual SQL: db0 ::: select
id, order_sn, member_id, create_time, status
from t_order_2
2020-06-15 18:00:59.099 INFO 948 --- [ main] ShardingSphere-SQL : Actual SQL: db1 ::: select
id, order_sn, member_id, create_time, status
from t_order_0
2020-06-15 18:00:59.099 INFO 948 --- [ main] ShardingSphere-SQL : Actual SQL: db1 ::: select
id, order_sn, member_id, create_time, status
from t_order_1
2020-06-15 18:00:59.100 INFO 948 --- [ main] ShardingSphere-SQL : Actual SQL: db1 ::: select
id, order_sn, member_id, create_time, status
from t_order_2
Order(id=479339444940308481, orderSn=333333, memberId=102, createTime=Mon Jun 15 17:23:47 CST 2020, status=1)
Order(id=479339438946648065, orderSn=111111, memberId=100, createTime=Mon Jun 15 17:23:45 CST 2020, status=1)
Order(id=479339445393293312, orderSn=444444, memberId=103, createTime=Mon Jun 15 17:23:47 CST 2020, status=1)
Order(id=479339444424409088, orderSn=222222, memberId=101, createTime=Mon Jun 15 17:23:47 CST 2020, status=1)
带有member_id的分片条件
@Test
void TestListOrder2(){
OrderExample orderExample = new OrderExample();
OrderExample.Criteria criteria = orderExample.createCriteria();
criteria.andMemberIdEqualTo(101L);
List orderList= orderService.listOrder(orderExample);
for (Order o:orderList){
System.out.println(o.toString());
}
}
会自动路由到对应表
2020-06-15 18:06:18.346 INFO 19768 --- [ main] ShardingSphere-SQL : Actual SQL: db1 ::: select
id, order_sn, member_id, create_time, status
from t_order_2
WHERE ( member_id = ? ) ::: [101]
Order(id=479339444424409088, orderSn=222222, memberId=101, createTime=Mon Jun 15 17:23:47 CST 2020, status=1)
总结
shardingsphere分库分表可以解决单库单表的数据库的性能瓶颈问题,开发者使用起来也比较简单,只需定义好分片的规则和算法,shardingsphere会自动路由、改写sql、将结果合并返回。但分库分表也会增加系统的复杂度,例如跨库的join问题,事务问题,成本问题等,需要综合考虑是否有分库分表的必要。
项目demo地址
https://github.com/pengziliu/GitHub-code-practice
