Neo4j图数据库简介和底层原理
http://www.cnblogs.com/bonelee/p/6211290.html
现实中很多数据都是用图来表达的,比如社交网络中人与人的关系、地图数据、或是基因信息等等。RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘。NoSQL数据库的兴起,很好地解决了海量数据的存放问题,图数据库也是NoSQL的一个分支,相比于NoSQL中的其他分支,它很适合用来原生表达图结构的数据。
下面一张图说明,相比于其他NoSQL,图数据库存放的数据规模有所下降,但是更能够表达复杂的数据。
id="iframe_0.5484260382358499" src="data:text/html;charset=utf8,%3Cstyle%3Ebody%7Bmargin:0;padding:0%7D%3C/style%3E%3Cimg%20id=%22img%22%20src=%22http://qinxuye.me/static/uploads/nosql.jpg?_=6211290%22%20style=%22border:none;max-width:933px%22%3E%3Cscript%3Ewindow.onload%20=%20function%20()%20%7Bvar%20img%20=%20document.getElementById('img');%20window.parent.postMessage(%7BiframeId:'iframe_0.5484260382358499',width:img.width,height:img.height%7D,%20'http://www.cnblogs.com');%7D%3C/script%3E" frameborder="0" scrolling="no" style="border-width: initial; border-style: none; width: 429px; height: 346px;">
通常来说,一个图数据库存储的结构就如同数据结构中的图,由顶点和边组成。
Neo4j是图数据库中一个主要代表,其开源,且用Java实现。经过几年的发展,已经可以用于生产环境。其有两种运行方式,一种是服务的方式,对外提供REST接口;另外一种是嵌入式模式,数据以文件的形式存放在本地,可以直接对本地文件进行操作。
Neo4j简介
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注。
图形数据结构
在一个图中包含两种基本的数据类型:Nodes(节点) 和 Relationships(关系)。Nodes 和 Relationships 包含key/value形式的属性。Nodes通过Relationships所定义的关系相连起来,形成关系型网络结构。
从这几个方面来说,Neo4j是一个合适的选择。Neo4j……
- 自带一套易于学习的查询语言(名为Cypher)
- 不使用schema,因此可以满足你的任何形式的需求
- 与关系型数据库相比,对于高度关联的数据(图形数据)的查询快速要快上许多
- 它的实体与关系结构非常自然地切合人类的直观感受
- 支持兼容ACID的事务操作
- 提供了一个高可用性模型,以支持大规模数据量的查询,支持备份、数据局部性以及冗余
- 提供了一个可视化的查询控制台,你不会对它感到厌倦的
什么时候不应使用Neo4j?
作为一个图形NoSQL数据库,Neo4j提供了大量的功能,但没有什么解决方案是完美的。在以下这些用例中,Neo4j就不是非常适合的选择:
- 记录大量基于事件的数据(例如日志条目或传感器数据)
- 对大规模分布式数据进行处理,类似于Hadoop
- 二进制数据存储
- 适合于保存在关系型数据库中的结构化数据
neo4j存储模型
id="iframe_0.02215085003283357" src="data:text/html;charset=utf8,%3Cstyle%3Ebody%7Bmargin:0;padding:0%7D%3C/style%3E%3Cimg%20id=%22img%22%20src=%22http://sunxiang0918.cn/img/2015/06/27/1.jpg?_=6211290%22%20style=%22border:none;max-width:933px%22%3E%3Cscript%3Ewindow.onload%20=%20function%20()%20%7Bvar%20img%20=%20document.getElementById('img');%20window.parent.postMessage(%7BiframeId:'iframe_0.02215085003283357',width:img.width,height:img.height%7D,%20'http://www.cnblogs.com');%7D%3C/script%3E" frameborder="0" scrolling="no" style="border-width: initial; border-style: none; width: 300px; height: 237px;">
The node records contain only a pointer to their first property and their first relationship (in what is oftentermed the _relationship chain). From here, we can follow the (doubly) linked-list of relationships until we find the one we’re interested in, the LIKES relationship from Node 1 to Node 2 in this case. Once we’ve found the relationship record of interest, we can simply read its properties if there are any via the same singly-linked list structure as node properties, or we can examine the node records that it relates via its start node and end node IDs. These IDs, multiplied by the node record size, of course give the immediate offset of both nodes in the node store file.
上面的英文摘自
通过上述存储模型,从一个Node-A开始,可以方便的遍历以该Node-A为起点的图。下面给个示例,来帮助理解上面的存储模型,存储文件的具体格式在第2章详细描述。
示例1
id="iframe_0.26670357935809874" src="data:text/html;charset=utf8,%3Cstyle%3Ebody%7Bmargin:0;padding:0%7D%3C/style%3E%3Cimg%20id=%22img%22%20src=%22http://sunxiang0918.cn/img/2015/06/27/2.png?_=6211290%22%20style=%22border:none;max-width:933px%22%3E%3Cscript%3Ewindow.onload%20=%20function%20()%20%7Bvar%20img%20=%20document.getElementById('img');%20window.parent.postMessage(%7BiframeId:'iframe_0.26670357935809874',width:img.width,height:img.height%7D,%20'http://www.cnblogs.com');%7D%3C/script%3E" frameborder="0" scrolling="no" style="border-width: initial; border-style: none; width: 300px; height: 235px;">
在这个例子中,A~E表示Node 的编号,R1~R7 表示 Relationship 编号,P1~P10 表示Property 的编号。
- Node 的存储示例图如下,每个
Node保存了第1个Property和 第1个Relationship:
id="iframe_0.5332255684423048" src="data:text/html;charset=utf8,%3Cstyle%3Ebody%7Bmargin:0;padding:0%7D%3C/style%3E%3Cimg%20id=%22img%22%20src=%22http://sunxiang0918.cn/img/2015/06/27/3.png?_=6211290%22%20style=%22border:none;max-width:933px%22%3E%3Cscript%3Ewindow.onload%20=%20function%20()%20%7Bvar%20img%20=%20document.getElementById('img');%20window.parent.postMessage(%7BiframeId:'iframe_0.5332255684423048',width:img.width,height:img.height%7D,%20'http://www.cnblogs.com');%7D%3C/script%3E" frameborder="0" scrolling="no" style="border-width: initial; border-style: none; width: 181px; height: 262px;"> - 关系的存储示意图如下:
id="iframe_0.7491599933713313" src="data:text/html;charset=utf8,%3Cstyle%3Ebody%7Bmargin:0;padding:0%7D%3C/style%3E%3Cimg%20id=%22img%22%20src=%22http://sunxiang0918.cn/img/2015/06/27/4.png?_=6211290%22%20style=%22border:none;max-width:933px%22%3E%3Cscript%3Ewindow.onload%20=%20function%20()%20%7Bvar%20img%20=%20document.getElementById('img');%20window.parent.postMessage(%7BiframeId:'iframe_0.7491599933713313',width:img.width,height:img.height%7D,%20'http://www.cnblogs.com');%7D%3C/script%3E" frameborder="0" scrolling="no" style="border-width: initial; border-style: none; width: 300px; height: 263px;">
从示意图可以看出,从 Node-B 开始,可以通过关系的 next 指针,遍历Node-B 的所有关系,然后可以到达与其有关系的第1层Nodes,在通过遍历第1层Nodes的关系,可以达到第2层Nodes,…
neo4j graph db的存储文件介绍
当我们下载neo4j-community-2.1.0-M01 并安装,然后拿 neo4j embedded-example 的EmbeddedNeo4j 例子跑一下,可以看到在target/neo4j-hello-db下会生成如下neo4j graph db 的存储文件。
-rw-r–r– 11 04-11 13:28 active_tx_log
drwxr-xr-x 4096 04-11 13:28 index
-rw-r–r– 23740 04-11 13:28 messages.log
-rw-r–r– 78 04-11 13:28 neostore
-rw-r–r– 9 04-11 13:28 neostore.id
-rw-r–r– 22 04-11 13:28 neostore.labeltokenstore.db
-rw-r–r– 9 04-11 13:28 neostore.labeltokenstore.db.id
-rw-r–r– 64 04-11 13:28 neostore.labeltokenstore.db.names
-rw-r–r– 9 04-11 13:28 neostore.labeltokenstore.db.names.id
-rw-r–r– 61 04-11 13:28 neostore.nodestore.db
-rw-r–r– 9 04-11 13:28 neostore.nodestore.db.id
-rw-r–r– 93 04-11 13:28 neostore.nodestore.db.labels
-rw-r–r– 9 04-11 13:28 neostore.nodestore.db.labels.id
-rw-r–r– 307 04-11 13:28 neostore.propertystore.db
-rw-r–r– 153 04-11 13:28 neostore.propertystore.db.arrays
-rw-r–r– 9 04-11 13:28 neostore.propertystore.db.arrays.id
-rw-r–r– 9 04-11 13:28 neostore.propertystore.db.id
-rw-r–r– 61 04-11 13:28 neostore.propertystore.db.index
-rw-r–r– 9 04-11 13:28 neostore.propertystore.db.index.id
-rw-r–r– 216 04-11 13:28 neostore.propertystore.db.index.keys
-rw-r–r– 9 04-11 13:28 neostore.propertystore.db.index.keys.id
-rw-r–r– 410 04-11 13:28 neostore.propertystore.db.strings
-rw-r–r– 9 04-11 13:28 neostore.propertystore.db.strings.id
-rw-r–r– 69 04-11 13:28 neostore.relationshipgroupstore.db
-rw-r–r– 9 04-11 13:28 neostore.relationshipgroupstore.db.id
-rw-r–r– 92 04-11 13:28 neostore.relationshipstore.db
-rw-r–r– 9 04-11 13:28 neostore.relationshipstore.db.id
-rw-r–r– 38 04-11 13:28 neostore.relationshiptypestore.db
-rw-r–r– 9 04-11 13:28 neostore.relationshiptypestore.db.id
-rw-r–r– 140 04-11 13:28 neostore.relationshiptypestore.db.names
-rw-r–r– 9 04-11 13:28 neostore.relationshiptypestore.db.names.id
-rw-r–r– 82 04-11 13:28 neostore.schemastore.db
-rw-r–r– 9 04-11 13:28 neostore.schemastore.db.id
-rw-r–r– 4 04-11 13:28 nioneo_logical.log.active
-rw-r–r– 2249 04-11 13:28 nioneo_logical.log.v0
drwxr-xr-x 4096 04-11 13:28 schema
-rw-r–r– 0 04-11 13:28 store_lock
-rw-r–r– 800 04-11 13:28 tm_tx_log.1
存储 node 的文件
- 存储节点数据及其序列Id
neostore.nodestore.db: 存储节点数组,数组的下标即是该节点的IDneostore.nodestore.db.id:存储最大的ID 及已经free的ID
- 存储节点label及其序列Id
neostore.nodestore.db.labels:存储节点label数组数据,数组的下标即是该节点label的IDneostore.nodestore.db.labels.id
存储 relationship 的文件
- 存储关系数据及其序列Id
neostore.relationshipstore.db存储关系 record 数组数据neostore.relationshipstore.db.id
- 存储关系组数据及其序列Id
neostore.relationshipgroupstore.db存储关系 group数组数据neostore.relationshipgroupstore.db.id
- 存储关系类型及其序列Id
neostore.relationshiptypestore.db存储关系类型数组数据neostore.relationshiptypestore.db.id
- 存储关系类型的名称及其序列Id
neostore.relationshiptypestore.db.names存储关系类型 token 数组数据neostore.relationshiptypestore.db.names.id
存储 label 的文件
- 存储label token数据及其序列Id
neostore.labeltokenstore.db存储lable token 数组数据neostore.labeltokenstore.db.id
- 存储label token名字数据及其序列Id
neostore.labeltokenstore.db.names存储 label token 的 names 数据neostore.labeltokenstore.db.names.id
存储 property 的文件
- 存储属性数据及其序列Id
neostore.propertystore.db存储 property 数据neostore.propertystore.db.id
- 存储属性数据中的数组类型数据及其序列Id
neostore.propertystore.db.arrays存储 property (key-value 结构)的Value值是数组的数据。neostore.propertystore.db.arrays.id
- 属性数据为长字符串类型的存储文件及其序列Id
neostore.propertystore.db.strings存储 property (key-value 结构)的Value值是字符串的数据。neostore.propertystore.db.strings.id
- 属性数据的索引数据文件及其序列Id
neostore.propertystore.db.index存储 property (key-value 结构)的key 的索引数据。neostore.propertystore.db.index.id
- 属性数据的键值数据存储文件及其序列Id
neostore.propertystore.db.index.keys存储 property (key-value 结构)的key 的字符串值。neostore.propertystore.db.index.keys.id
其他的文件
- 存储版本信息
neostoreneostore.id
- 存储 schema 数据
neostore.schemastore.dbneostore.schemastore.db.id
- 活动的逻辑日志
nioneo_logical.log.active
- 记录当前活动的日志文件名称
active_tx_log
neo4j存储结构
neo4j 中,主要有4类节点,属性,关系等文件是以数组作为核心存储结构;同时对节点,属性,关系等类型的每个数据项都会分配一个唯一的ID,在存储时以该ID 为数组的下标。这样,在访问时通过其ID作为下标,实现快速定位。所以在图遍历等操作时,可以实现 free-index。
neo4j 的 store 部分类图
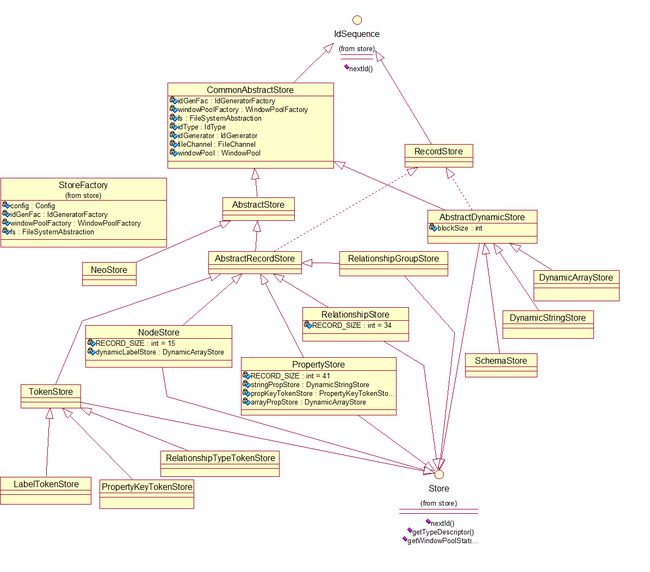
3.1.1 CommonAbstractStore.javaCommonAbstractStore 是所有 Store 类的基类,下面的代码片段是 CommonAbstractStore 的成员变量,比较重要的是飘红的几个,特别是IdGenerator,每种Store 的实例都有自己的 id 分配管理器; StoreChannel 是负责Store文件的读写和定位;WindowsPool 是与Store Record相关的缓存,用来提升性能的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
public abstract class CommonAbstractStore implements IdSequence { public static abstract class Configuration { public static final Setting store_dir = InternalAbstractGraphDatabase.Configuration.store_dir; public static final Setting neo_store = InternalAbstractGraphDatabase.Configuration.neo_store; public static final Setting read_only = GraphDatabaseSettings.read_only; public static final Setting backup_slave = GraphDatabaseSettings.backup_slave; public static final Setting use_memory_mapped_buffers = GraphDatabaseSettings.use_memory_mapped_buffers; } public static final String ALL_STORES_VERSION = "v0.A.2"; public static final String UNKNOWN_VERSION = "Uknown"; protected Config configuration; private final IdGeneratorFactory idGeneratorFactory; private final WindowPoolFactory windowPoolFactory; protected FileSystemAbstraction fileSystemAbstraction; protected final File storageFileName; protected final IdType idType; protected StringLogger stringLogger; private IdGenerator idGenerator = null; private StoreChannel fileChannel = null; private WindowPool windowPool; private boolean storeOk = true; private Throwable causeOfStoreNotOk; private FileLock fileLock; private boolean readOnly = false; private boolean backupSlave = false; private long highestUpdateRecordId = -1; |
neo4j 的db文件及对应的存储格式类型
| 文件名 | 文件存储格式 |
|---|---|
| neostore.labeltokenstore.db | LabelTokenStore(TokenStore) |
| neostore.labeltokenstore.db.id | ID 类型 |
| neostore.labeltokenstore.db.names | StringPropertyStore (AbstractDynamicStore, NAME_STORE_BLOCK_SIZE = 30) |
| neostore.labeltokenstore.db.names.id | ID 类型 |
| neostore.nodestore.db | NodeStore |
| neostore.nodestore.db.id | ID 类型 |
| neostore.nodestore.db.labels | ArrayPropertyStore (AbstractDynamicStorelabel_block_size=60) |
| neostore.nodestore.db.labels.id | ID 类型 |
| neostore.propertystore.db | PropertyStore |
| neostore.propertystore.db.arrays | ArrayPropertyStore (AbstractDynamicStorearray_block_size=120) |
| neostore.propertystore.db.arrays.id | ID 类型 |
| neostore.propertystore.db.id | ID 类型 |
| neostore.propertystore.db.index | PropertyIndexStore |
| neostore.propertystore.db.index.id | ID 类型 |
| neostore.propertystore.db.index.keys | StringPropertyStore (AbstractDynamicStore, NAME_STORE_BLOCK_SIZE = 30) |
| neostore.propertystore.db.index.keys.id | ID 类型 |
| neostore.propertystore.db.strings | StringPropertyStore (AbstractDynamicStorestring_block_size=120) |
| neostore.propertystore.db.strings.id | ID 类型 |
| neostore.relationshipgroupstore.db | RelationshipGroupStore |
| neostore.relationshipgroupstore.db.id | ID 类型 |
| neostore.relationshipstore.db | RelationshipStore |
| neostore.relationshipstore.db.id | ID 类型 |
| neostore.relationshiptypestore.db | RelationshipTypeTokenStore(TokenStore) |
| neostore.relationshiptypestore.db.id | ID 类型 |
| neostore.relationshiptypestore.db.names | StringPropertyStore (AbstractDynamicStore, NAME_STORE_BLOCK_SIZE = 30) |
| neostore.relationshiptypestore.db.names.id | ID 类型 |
| neostore.schemastore.db | SchemaStore(AbstractDynamicStore, BLOCK_SIZE = 56) |
| neostore.schemastore.db.id | ID 类型 |
通用的Store 类型
id 类型
下面是 neo4j db 中,每种Store都有自己的ID文件(即后缀.id 文件),它们的格式都是一样的。
[test00]$ls -lh target/neo4j-test00.db/ |grep .id
-rw-r–r–9 04-11 13:28 neostore.id
-rw-r–r–9 04-11 13:28 neostore.labeltokenstore.db.id
-rw-r–r–9 04-11 13:28 neostore.labeltokenstore.db.names.id
-rw-r–r–9 04-11 13:28 neostore.nodestore.db.id
-rw-r–r–9 04-11 13:28 neostore.nodestore.db.labels.id
-rw-r–r–9 04-11 13:28 neostore.propertystore.db.arrays.id
-rw-r–r–9 04-11 13:28 neostore.propertystore.db.id
-rw-r–r–9 04-11 13:28 neostore.propertystore.db.index.id
-rw-r–r–9 04-11 13:28 neostore.propertystore.db.index.keys.id
-rw-r–r–9 04-11 13:28 neostore.propertystore.db.strings.id
-rw-r–r–9 04-11 13:28 neostore.relationshipgroupstore.db.id
-rw-r–r–9 04-11 13:28 neostore.relationshipstore.db.id
-rw-r–r–9 04-11 13:28 neostore.relationshiptypestore.db.id
-rw-r–r–9 04-11 13:28 neostore.relationshiptypestore.db.names.id
-rw-r–r–9 04-11 13:28 neostore.schemastore.db.id
3.3.1.1. ID类型文件的存储格式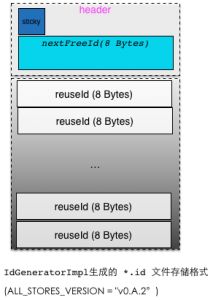
neo4j 中后缀为 “.id”的文件格式如上图所示,由文件头(9 Bytes)和 long类型 数组 2部分构成:
sticky(1 byte): if sticky the id generator wasn’t closed properly so it has to berebuilt (go through the node, relationship, property, rel type etc files).nextFreeId(long): 保存最大的ID,该值与对应类型的存储数组的数组大小相对应。reuseId(long):用来保存已经释放且可复用的ID值。通过复用ID ,可以减少资源数组的空洞,提高磁盘利用率。
3.3.1.2. IdGeneratorImpl.java
每一种资源类型的ID 分配 neo4j 中是通过 IdGeneratorImpl 来实现的,其功能是负责ID管理分配和回收复用。对于节点,关系,属性等每一种资源类型,都可以生成一个IdGenerator 实例来负责其ID管理分配和回收复用。
3.3.1.2.1. 读取id 文件进行初始化
下面是 IdGeneratorImpl.java 中, 读取id 文件进行初始化的过程,IdGeneratorImpl 会从 id 文件中读取grabSize 个可复用的ID (reuseId) 到idsReadFromFile(LinkedList中,在需要申请id 时优先分配 idsReadFromFile中的可复用ID。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 |
private synchronized void initGenerator() { try { fileChannel = fs.open(fileName, "rw"); ByteBuffer buffer = ByteBuffer.allocate(HEADER_SIZE); readHeader(buffer); markAsSticky(buffer); fileChannel.position(HEADER_SIZE); maxReadPosition = fileChannel.size(); defraggedIdCount = (int) (maxReadPosition - HEADER_SIZE) / 8; readIdBatch(); } catch (IOException e) { throw new UnderlyingStorageException( "Unable to init id generator " + fileName, e); } } private void readHeader(ByteBuffer buffer) throws IOException { readPosition = fileChannel.read(buffer); if (readPosition != HEADER_SIZE) { fileChannel.close(); throw new InvalidIdGeneratorException( "Unable to read header, bytes read: " + readPosition); } buffer.flip(); byte storageStatus = buffer.get(); if (storageStatus != CLEAN_GENERATOR) { fileChannel.close(); throw new InvalidIdGeneratorException("Sticky generator[ " + fileName + "] delete this id file and build a new one"); } this.highId.set(buffer.getLong()); } private void readIdBatch() { if (!canReadMoreIdBatches()) return; try { int howMuchToRead = (int) Math.min(grabSize * 8, maxReadPosition - readPosition); ByteBuffer readBuffer = ByteBuffer.allocate(howMuchToRead); fileChannel.position(readPosition); int bytesRead = fileChannel.read(readBuffer); assert fileChannel.position() <= maxReadPosition; readPosition += bytesRead; readBuffer.flip(); assert (bytesRead % 8) == 0; int idsRead = bytesRead / 8; defraggedIdCount -= idsRead; for (int i = 0; i < idsRead; i++) { long id = readBuffer.getLong(); if (id != INTEGER_MINUS_ONE) { idsReadFromFile.add(id); } } } catch (IOException e) { throw new UnderlyingStorageException( "Failed reading defragged id batch", e); } } |
3.3.1.2.2. 释放id(freeId)
用户释放一个 id 后,会先放入 releasedIdList (LinkedList,当releasedIdList 中回收的 id 个数超过 grabSize 个时, 写入到 id 文件的末尾。所以可见,对于一个 IdGeneratorImpl, 最多有 2 * grabSize 个 id 缓存(releasedIdList 和 idsReadFromFile)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
// initialize the id generator and performs a simple validation /** * Frees the |
3.3.1.2.3. 申请id ( nextId)
当用户申请一个 id 时,IdGeneratorImpl 在分配时,有2种分配策略:“正常的分配策略” 和“激进分配策略”(aggressiveReuse),可以根据配置进行选择。
- “正常的分配策略”:
- 首先从idsReadFromFile 中分配; 如果 idsReadFromFile 为空,则先从对应的 id 文件中读取已释放且可复用的 id 到idsReadFromFile.
- 如果 idsReadFromFile 及 id 文件中没有已释放且可复用的 id了,则分配全新的id,即id = highId.get() 并将highId 加1;
- “激进分配策略”(aggressiveReuse):
- 首先从releasedIdList(刚回收的ID List)中分配。
- releasedIdList分配光了,则从idsReadFromFile 中分配; 如果 idsReadFromFile 为空,则先从对应的 id 文件中读取已释放且可复用的 id 到idsReadFromFile.
- 如果 idsReadFromFile 及 id 文件中没有已释放且可复用的 id了,则分配全新的id,即id = highId.get() 并将highId 加1;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
/** * Returns the next "free" id. If a defragged id exist it will be returned * * else the next free id that hasn't been used yet is returned. If no id * * exist the capacity is exceeded (all values <= max are taken) and a * * {@link UnderlyingStorageException} will be thrown. */ @Override public synchronized long nextId() { assertStillOpen(); long nextDefragId = nextIdFromDefragList(); if (nextDefragId != -1) return nextDefragId; long id = highId.get(); if (id == INTEGER_MINUS_ONE) { // Skip the integer -1 (0xFFFFFFFF) because it represents // special values, f.ex. the end of a relationships/property chain. id = highId.incrementAndGet(); } assertIdWithinCapacity(id); highId.incrementAndGet(); return id; } |
DynamicStore 类型
3.3.2.1. AbstractDynamicStore 的存储格式
neo4j 中对于字符串等变长值的保存策略是用一组定长的 block 来保存,block之间用单向链表链接。类 AbstractDynamicStore 实现了该功能,下面是其注释说明。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
/**
* An abstract representation of a dynamic store. The difference between a
* normal AbstractStore and a AbstractDynamicStore is
* that the size of a record/entry can be dynamic.
* Instead of a fixed record this class uses blocks to store a record. If a
* record size is greater than the block size the record will use one or more
* blocks to store its data.
* A dynamic store don’t have a IdGenerator because the position of a
* record can’t be calculated just by knowing the id. Instead one should use a
* AbstractStore and store the start block of the record located in the
* dynamic store. Note: This class makes use of an id generator internally for
* managing free and non free blocks.
* Note, the first block of a dynamic store is reserved and contains information
* about the store.
*/
|
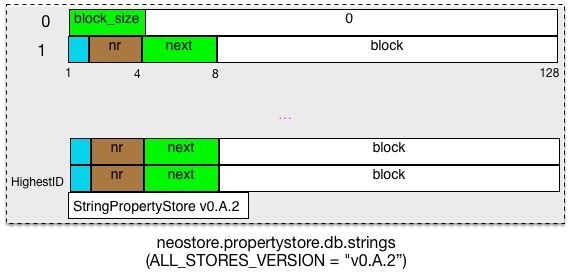
AbstractDynamicStore类对应的存储文件格式如上图所示, 整个文件是有一个block_size=BLOCK_HEADER_SIZE(8Bytes)+block_content_size的定长数组和一个字符串“StringPropertyStore v0.A.2”或“ArrayPropertyStore v0.A.2”或“SchemaStore v0.A.2”(文件类型描述TYPE_DESCRIPTOR和 neo4j 的 ALL_STORES_VERSION构成)。访问时,可以通过 id 作为数组的下标进行访问。其中,文件的第1个 record 中前4 字节用来保存 block_size。文件的第2个 record开始保存实际的block数据,它由8个字节的block_header和定长的 block_content(可配置)构成. block_header 结构如下:
- inUse(1 Byte):第1字节,共分成3部分
[x__ , ] 0: start record, 1: linked record
[ x, ] inUse
[ ,xxxx] high next block bits- 第1~4 bit 表示
next_block的高4位 - 第5 bit表示
block是否在 use; - 第8 bit 表示
block是否是单向链表的第1个 block;0表示第1个block,1表示后续 block.
- 第1~4 bit 表示
- nr_of_bytes(3Bytes):本 block 中保存的数据的长度。
- next_block(4Bytes): next_block 的低 4 个字节,加上
inUse的第1~4 位,next_block的实际长度共 36 bit。以数组方式存储的单向链表的指针,指向保存同一条数据的下一个 block 的id.
3.3.2.2. AbstractDynamicStore.java
下面看一下 AbstractDynamicStore.java 中 getRecord() 和readAndVerifyBlockSize() 成员函数,可以帮助理解 DynamicStore 的存储格式。
- getRecord( long blockId, PersistenceWindow window, RecordLoad load )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 |
private DynamicRecord getRecord( long blockId, PersistenceWindow window, RecordLoad load )
{
DynamicRecord record = new DynamicRecord( blockId );
Buffer buffer = window.getOffsettedBuffer( blockId );
/*
* First 4b
* [x , ][ , ][ , ][ , ] 0: start record, 1: linked record
* [ x, ][ , ][ , ][ , ] inUse
* [ ,xxxx][ , ][ , ][ , ] high next block bits
* [ , ][xxxx,xxxx][xxxx,xxxx][xxxx,xxxx] nr of bytes in the data field in this record
*
*/
long firstInteger = buffer.getUnsignedInt();
boolean isStartRecord = (firstInteger & 0x80000000) == 0;
long maskedInteger = firstInteger & ~0x80000000;
int highNibbleInMaskedInteger = (int) ( ( maskedInteger ) >> 28 );
boolean inUse = highNibbleInMaskedInteger == Record.IN_USE.intValue();
if ( !inUse && load != RecordLoad.FORCE )
{
throw new InvalidRecordException( "DynamicRecord Not in use, blockId[" + blockId + "]" );
}
int dataSize = getBlockSize() - BLOCK_HEADER_SIZE;
int nrOfBytes = (int) ( firstInteger & 0xFFFFFF );
/*
* Pointer to next block 4b (low bits of the pointer)
*/
long nextBlock = buffer.getUnsignedInt();
long nextModifier = ( firstInteger & 0xF000000L ) << 8;
long longNextBlock = longFromIntAndMod( nextBlock, nextModifier );
boolean readData = load != RecordLoad.CHECK;
if ( longNextBlock != Record.NO_NEXT_BLOCK.intValue()
&& nrOfBytes < dataSize || nrOfBytes > dataSize )
{
readData = false;
if ( load != RecordLoad.FORCE )
{
throw new InvalidRecordException( "Next block set[" + nextBlock
+ "] current block illegal size[" + nrOfBytes + "/" + dataSize + "]" );
}
}
record.setInUse( inUse );
record.setStartRecord( isStartRecord );
record.setLength( nrOfBytes );
record.setNextBlock( longNextBlock );
/*
* Data 'nrOfBytes' bytes
*/
if ( readData )
{
byte byteArrayElement[] = new byte[nrOfBytes];
buffer.get( byteArrayElement );
record.setData( byteArrayElement );
}
return record;
}
|
- readAndVerifyBlockSize()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
protected void readAndVerifyBlockSize() throws IOException { ByteBuffer buffer = ByteBuffer.allocate( 4 ); getFileChannel().position( 0 ); getFileChannel().read( buffer ); buffer.flip(); blockSize = buffer.getInt(); if ( blockSize <= 0 ) { throw new InvalidRecordException( "Illegal block size: " + blockSize + " in " + getStorageFileName() ); } } |
3.3.2.3 类DynamicArrayStore, DynamicStringStore
类SchemaStore,DynamicArrayStore(ArrayPropertyStore), DynamicStringStore(StringPropertyStore)都是继承成自类AbstractDynamicStore,所以与类DynamicArrayStore, DynamicStringStore和 SchemaStore对应文件的存储格式,都是遵循AbstractDynamicStore的存储格式,除了block块的大小(block_size)不同外。
| db 文件 | 存储类型 | block_size |
|---|---|---|
| neostore.labeltokenstore.db.names | StringPropertyStore | NAME_STORE_BLOCK_SIZE=30 |
| neostore.propertystore.db.index.keys | StringPropertyStore | NAME_STORE_BLOCK_SIZE=30 |
| neostore.relationshiptypestore.db.names | StringPropertyStore | NAME_STORE_BLOCK_SIZE=30 |
| neostore.propertystore.db.strings | StringPropertyStore | string_block_size=120 |
| neostore.nodestore.db.labels | ArrayPropertyStore | label_block_size=60 |
| neostore.propertystore.db.arrays | ArrayPropertyStore | array_block_size=120 |
| neostore.schemastore.db | SchemaStore | BLOCK_SIZE=56 |
block_size 通过配置文件或缺省值来设置的,下面的代码片段展示了neostore.propertystore.db.strings 文件的创建过程及block_size 的大小如何传入。
GraphDatabaseSettings.java
1 2 3
public static final Setting string_block_size = setting("string_block_size", INTEGER, "120",min(1)); public static final Setting array_block_size = setting("array_block_size", INTEGER, "120",min(1)); public static final Setting label_block_size = setting("label_block_size", INTEGER, "60",min(1));
StoreFactory.java的Configuration 类
1 2 3 4 5 6
public static abstract class Configuration{ public static final Setting string_block_size = GraphDatabaseSettings.string_block_size; public static final Setting array_block_size = GraphDatabaseSettings.array_block_size; public static final Setting label_block_size = GraphDatabaseSettings.label_block_size; public static final Setting dense_node_threshold = GraphDatabaseSettings.dense_node_threshold; }
StoreFactory.java的createPropertyStore 函数
1 2 3 4 5 6 7 8
public void createPropertyStore( File fileName ){ createEmptyStore( fileName, buildTypeDescriptorAndVersion( PropertyStore.TYPE_DESCRIPTOR )); int stringStoreBlockSize = config.get( Configuration.string_block_size ); int arrayStoreBlockSize = config.get( Configuration.array_block_size ) createDynamicStringStore(new File( fileName.getPath() + STRINGS_PART), stringStoreBlockSize, IdType.STRING_BLOCK); createPropertyKeyTokenStore( new File( fileName.getPath() + INDEX_PART ) ); createDynamicArrayStore( new File( fileName.getPath() + ARRAYS_PART ), arrayStoreBlockSize ); }
StoreFactory.java的createDynamicStringStore函数
1 2 3
private void createDynamicStringStore( File fileName, int blockSize, IdType idType ){ createEmptyDynamicStore(fileName, blockSize, DynamicStringStore.VERSION, idType); }
StoreFactory.java的createEmptyDynamicStore 函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
/** * Creates a new empty store. A factory method returning an implementation * should make use of this method to initialize an empty store. Block size * must be greater than zero. Not that the first block will be marked as * reserved (contains info about the block size). There will be an overhead * for each block of
AbstractDynamicStore.BLOCK_HEADER_SIZEbytes. */ public void createEmptyDynamicStore( File fileName, int baseBlockSize, String typeAndVersionDescriptor, IdType idType) { int blockSize = baseBlockSize; // sanity checks … blockSize += AbstractDynamicStore.BLOCK_HEADER_SIZE; // write the header try { FileChannel channel = fileSystemAbstraction.create(fileName); int endHeaderSize = blockSize + UTF8.encode( typeAndVersionDescriptor ).length; ByteBuffer buffer = ByteBuffer.allocate( endHeaderSize ); buffer.putInt( blockSize ); buffer.position( endHeaderSize - typeAndVersionDescriptor.length() ); buffer.put( UTF8.encode( typeAndVersionDescriptor ) ).flip(); channel.write( buffer ); channel.force( false ); channel.close(); } catch ( IOException e ) { throw new UnderlyingStorageException( "Unable to create store " + fileName, e ); } idGeneratorFactory.create( fileSystemAbstraction, new File( fileName.getPath() + ".id"), 0 ); // TODO highestIdInUse = 0 works now, but not when slave can create store files. IdGenerator idGenerator = idGeneratorFactory.open(fileSystemAbstraction, new File( fileName.getPath() + ".id"),idType.getGrabSize(), idType, 0 ); idGenerator.nextId(); // reserve first for blockSize idGenerator.close(); }
Property 的存储
下面是neo4j graph db 中,Property数据存储对应的文件:
neostore.propertystore.db
neostore.propertystore.db.arrays
neostore.propertystore.db.arrays.id
neostore.propertystore.db.id
neostore.propertystore.db.index
neostore.propertystore.db.index.id
neostore.propertystore.db.index.keys
neostore.propertystore.db.index.keys.id
neostore.propertystore.db.strings
neostore.propertystore.db.strings.id
neo4j 中, Property 的存储是由 PropertyStore, ArrayPropertyStore, StringPropertyStore 和PropertyKeyTokenStore 4种类型的Store配合来完成的.
类PropertyStore对应的存储文件是neostore.propertystore.db, 相应的用来存储 string/array 类型属性值的文件分别是neostore.propertystore.db.strings (StringPropertyStore) 和 neostore.propertystore.db.arrays(ArrayPropertyStore). 其存储模型示意图如下: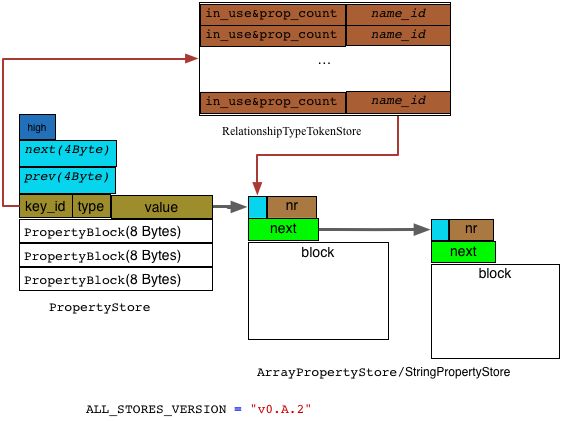
其中PropertyStore是Property最主要的存储结构,当Property的Key-Value对的Value 是字符串或数组类型并且要求的存储空间比较大,在PropertyStore中保存不了,则会存在StringPropertyStore/ ArrayPropertyStore这样的DynamicStore 中。如果长度超过一个block ,则分block存储,并将其在StringPropertyStore/ ArrayPropertyStore中的第1个block 的 block_id 保存到 PropertyStore类型文件相应record 的PropertyBlock字段中。
PropertyKeyTokenStore和StringPropertyStore 配合用来存储Propery的Key部分。Propery的Key是编码的,key 的 id 保存在 PropertyKeyTokenStore (即 neostore.propertystore.db.index),key 的字符串名保存在对应的StringPropertyStore类型文件neostore.propertystore.db.index.keys 中。
ArrayPropertyStore的存储格式见< 3.3.2 DynamicStore 类型>,下面分别介绍一下PropertyStore和PropertyKeyTokenStore(PropertyKeyTokenStore)的文件存储格式。
PropertyStore类型的存储格式
neostore.propertystore.db文件存储格式示意图如下,整个文件是有一个 RECORD_SIZE=41 Bytes 的定长数组和一个字符串描述符“PropertyStore v0.A.2”(文件类型描述TYPE_DESCRIPTOR和 neo4j 的 ALL_STORES_VERSION构成)。访问时,可以通过 prop_id 作为数组的下标进行访问。
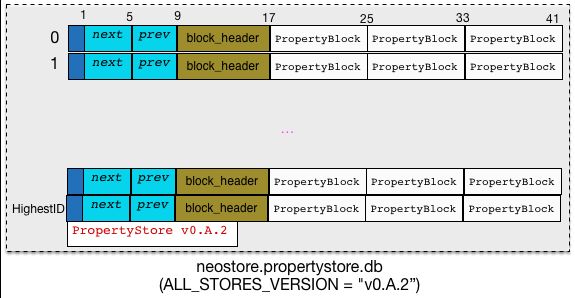
下面介绍一下 property record 中每个字段的含义:
highByte(1 Byte):第1字节,共分成2部分
//[pppp,nnnn] previous, next high bits
byte modifiers = buffer.get();- 第1~4 bit 表示
next的高4位; - 第 5~8 bit表示
prev的高4位
- 第1~4 bit 表示
prev(4 Bytes): Node或Relationship 的属性是通过双向链表方式组织的,prev 表示本属性在双向链表中的上一个属性的id。第2~5字节是prev property_id的 低32位. 加上highByte字节的第 5~8 bit作为高4位,构成一个完整的36位property_id。next(4 Bytes): next 表示本属性在双向链表中的下一个属性的id。第6~9字节是next property_id的 低32位. 加上highByte字节的第 1~4 bit作为高4位,构成一个完整的36位property_id。payload: payload 由block_header(8 Bytes)加3个property_block(8 Bytes)组成,共计 32 Bytes. block_header 分成3部分:key_id(24 bits): 第1 ~24 bit , property 的key 的 idtype( 4 bits ): 第25 ~28 bit , property 的 value 的类型,支持 string, Interger,Boolean, Float, Long,Double, Byte, Character,Short, array.payload(36 bits): 第29 ~64 bit, 共计36bit;对于Interger, Boolean, Float, Byte, Character , Short 类型的值,直接保存在payload;对于long,如果36位可以表示,则直接保存在payload,如果不够,则保存到第1个PropertyBlock中;double 类型,保存到第1个PropertyBlock中;对于 array/string ,如果编码后在 block_header及3个PropertyBlock 能保存,则直接保存;否则,保存到ArrayDynamicStore/StringDynamicStore 中, payload 保存其在ArrayDynamicStore中的数组下表。
String 类型属性值的保存过程
下面的代码片段展示了neo4j 中,比较长的 String 类型属性值的保存处理过程,其是如何分成多个 DynamicBlock 来存储的。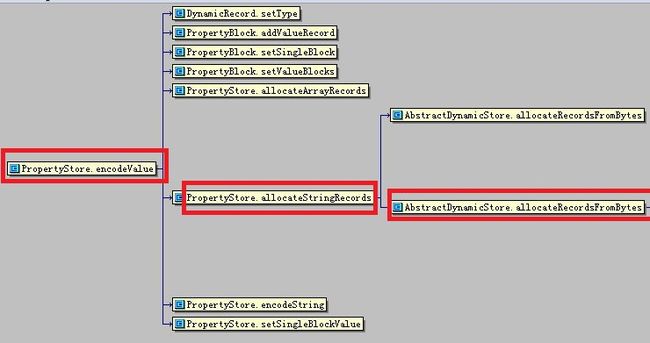
3.5.2.1 encodeValue 函数
encodeValue 函数是 PropertySTore.java 的成员函数, 它实现了不同类型的属性值的编码.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 |
public void encodeValue( PropertyBlock block, int keyId, Object value ) { if ( value instanceof String ) { // Try short string first, i.e. inlined in the property block String string = (String) value; if ( LongerShortString.encode( keyId, string, block, PropertyType.getPayloadSize() ) ) { return; } // Fall back to dynamic string store byte[] encodedString = encodeString( string ); Collection valueRecords = allocateStringRecords( encodedString ); setSingleBlockValue( block, keyId, PropertyType.STRING, first( valueRecords ).getId() ); for ( DynamicRecord valueRecord : valueRecords ) { valueRecord.setType( PropertyType.STRING.intValue() ); block.addValueRecord( valueRecord ); } } else if ( value instanceof Integer ) { setSingleBlockValue( block, keyId, PropertyType.INT, ((Integer) value).longValue() ); } else if ( value instanceof Boolean ) { setSingleBlockValue( block, keyId, PropertyType.BOOL, ((Boolean) value ? 1L : 0L) ); } else if ( value instanceof Float ) { setSingleBlockValue( block, keyId, PropertyType.FLOAT, Float.floatToRawIntBits( (Float) value ) ); } else if ( value instanceof Long ) { long keyAndType = keyId | (((long) PropertyType.LONG.intValue()) << 24); if ( ShortArray.LONG.getRequiredBits( (Long) value ) <= 35 ) { // We only need one block for this value, special layout compared to, say, an integer block.setSingleBlock( keyAndType | (1L << 28) | ((Long) value << 29) ); } else { // We need two blocks for this value block.setValueBlocks( new long[]{keyAndType, (Long) value} ); } } else if ( value instanceof Double ) { block.setValueBlocks( new long[]{ keyId | (((long) PropertyType.DOUBLE.intValue()) << 24), Double.doubleToRawLongBits( (Double) value )} ); } else if ( value instanceof Byte ) { setSingleBlockValue( block, keyId, PropertyType.BYTE, ((Byte) value).longValue() ); } else if ( value instanceof Character ) { setSingleBlockValue( block, keyId, PropertyType.CHAR, (Character) value ); } else if ( value instanceof Short ) { setSingleBlockValue( block, keyId, PropertyType.SHORT, ((Short) value).longValue() ); } else if ( value.getClass().isArray() ) { // Try short array first, i.e. inlined in the property block if ( ShortArray.encode( keyId, value, block, PropertyType.getPayloadSize() ) ) { return; } // Fall back to dynamic array store Collection arrayRecords = allocateArrayRecords( value ); setSingleBlockValue( block, keyId, PropertyType.ARRAY, first( arrayRecords ).getId() ); for ( DynamicRecord valueRecord : arrayRecords ) { valueRecord.setType( PropertyType.ARRAY.intValue() ); block.addValueRecord( valueRecord ); } } else { throw new IllegalArgumentException( "Unknown property type on: " + value + ", " + value.getClass() ); } } |
3.5.2.2 allocateStringRecords 函数allocateStringRecords 函数是 PropertySTore.java 的成员函数.
1 2 3 4 5 6 7 |
private Collection allocateStringRecords( byte[] chars ) { return stringPropertyStore.allocateRecordsFromBytes( chars ); } |
3.5.2.3 allocateRecordsFromBytes 函数allocateRecordsFromBytes 函数是 AbstractDynamicStore .java 的成员函数.
1 2 3 4 5 6 7 8 9 |
protected Collection allocateRecordsFromBytes( byte src[] ) { return allocateRecordsFromBytes( src, Collections.emptyList().iterator(), recordAllocator ); } |
3.5.2.4 allocateRecordsFromBytes 函数allocateRecordsFromBytes 函数是 AbstractDynamicStore .java 的成员函数.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
public static Collection allocateRecordsFromBytes( byte src[], Iterator recordsToUseFirst, DynamicRecordAllocator dynamicRecordAllocator ) { assert src != null : "Null src argument"; List recordList = new LinkedList<>(); DynamicRecord nextRecord = dynamicRecordAllocator.nextUsedRecordOrNew( recordsToUseFirst ); int srcOffset = 0; int dataSize = dynamicRecordAllocator.dataSize(); do { DynamicRecord record = nextRecord; record.setStartRecord( srcOffset == 0 ); if ( src.length - srcOffset > dataSize ) { byte data[] = new byte[dataSize]; System.arraycopy( src, srcOffset, data, 0, dataSize ); record.setData( data ); nextRecord = dynamicRecordAllocator.nextUsedRecordOrNew( recordsToUseFirst ); record.setNextBlock( nextRecord.getId() ); srcOffset += dataSize; } else { byte data[] = new byte[src.length - srcOffset]; System.arraycopy( src, srcOffset, data, 0, data.length ); record.setData( data ); nextRecord = null; record.setNextBlock( Record.NO_NEXT_BLOCK.intValue() ); } recordList.add( record ); assert !record.isLight(); assert record.getData() != null; } while ( nextRecord != null ); return recordList; } |
ShortArray 类型属性值的保存过程
ShortArray.encode( keyId, value, block, PropertyType.getPayloadSize() ), 它是在 kernel/impl/nioneo/store/ShortArray.java 中实现的,下面是其代码片段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
public static boolean encode( int keyId, Object array, PropertyBlock target, int payloadSizeInBytes ) { /* * If the array is huge, we don't have to check anything else. * So do the length check first. */ int arrayLength = Array.getLength( array ); if ( arrayLength > 63 )/*because we only use 6 bits for length*/ { return false; } ShortArray type = typeOf( array ); if ( type == null ) { return false; } int requiredBits = type.calculateRequiredBitsForArray( array, arrayLength ); if ( !willFit( requiredBits, arrayLength, payloadSizeInBytes ) ) { // Too big array return false; } final int numberOfBytes = calculateNumberOfBlocksUsed( arrayLength, requiredBits ) * 8; if ( Bits.requiredLongs( numberOfBytes ) > PropertyType.getPayloadSizeLongs() ) { return false; } Bits result = Bits.bits( numberOfBytes ); // [][][ ,bbbb][bbll,llll][yyyy,tttt][kkkk,kkkk][kkkk,kkkk][kkkk,kkkk] writeHeader( keyId, type, arrayLength, requiredBits, result ); type.writeAll( array, arrayLength, requiredBits, result ); target.setValueBlocks( result.getLongs() ); return true; } private static void writeHeader( int keyId, ShortArray type, int arrayLength, int requiredBits, Bits result ) { result.put( keyId, 24 ); result.put( PropertyType.SHORT_ARRAY.intValue(), 4 ); result.put( type.type.intValue(), 4 ); result.put( arrayLength, 6 ); result.put( requiredBits, 6 ); } |
PropertyKeyTokenStore的文件存储格式
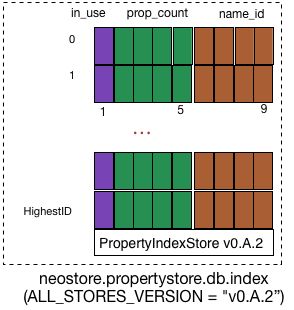
类PropertyTypeTokenStore对应的存储文件名是neostore.propertystore.db.index,其对应的存储格式如上图所示: 是一个长度为 RECORD_SIZE=9Bytes 的 record 数组和和一个字符串“PropertyIndexStore v0.A.2”(文件类型描述TYPE_DESCRIPTOR和 neo4j 的 ALL_STORES_VERSION构成)。访问时,可以通过 token_id 作为数组的下标进行访问。
record 是由 in_use(1 Byte) ,prop_count(4 Bytes), name_id(4 Bytes)构成。
Node 数据存储
neo4j 中, Node 的存储是由 NodeStore 和 ArrayPropertyStore 2中类型配合来完成的. node 的label 内容是存在ArrayPropertyStore这样的DynamicStore 中,如果长度超过一个block ,则分block存储,并将其在ArrayPropertyStore中的第1个block 的 block_id 保存到 NodeStore类型文件相应record 的labels字段中。
下面是neo4j graph db 中,Node数据存储对应的文件:
neostore.nodestore.db
neostore.nodestore.db.id
neostore.nodestore.db.labels
neostore.nodestore.db.labels.id
ArrayPropertyStore的存储格式见< 3.3.2 DynamicStore 类型>,下面介绍一下 NodeStore 的文件存储格式。
NodeStore的主文件存储格式
NodeStore的主文件是neostore.nodestore.db, 其文件存储格式示意图如下,整个文件是有一个 RECORD_SIZE=15Bytes 的定长数组和一个字符串描述符“NodeStore v0.A.2”(文件类型描述TYPE_DESCRIPTOR和 neo4j 的 ALL_STORES_VERSION) 构成。访问时,可以通过 node_id 作为数组的下标进行访问。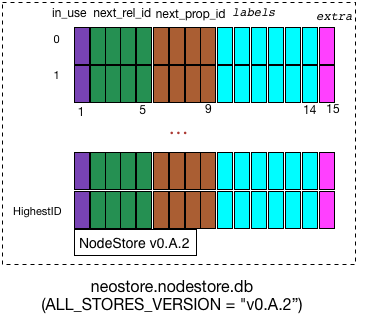
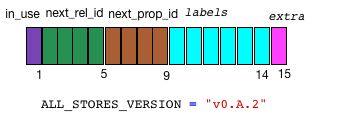
1 2 3 |
// in_use(byte)+next_rel_id(int)+next_prop_id(int)+labels(5)+extra(byte) public static final int RECORD_SIZE = 15; |
下面介绍一下 node record 中每个字段的含义:
inUse(1 Byte):第1字节,共分成3部分- 第1 bit 表示 record 是否在 use;
- 第2~4 bit 表示 node 的第1个 relationship_id 的 高3位;
- 第 5~8 bit表示 node 的第1个property_id 的 高4位
next_rel_id(4 Bytes): 第2~5字节是node 的第1个 relationship_id 的 低32位. 加上inUse 字节的第 2~4 bit作为高3位,构成一个完整的35位relationship_id。next_prop_id(4 Bytes): 第6~9字节是node 的第1个 property_id 的 低32位. 加上inUse 字节的第 5~8 bit作为高4位,构成一个完整的36 位 property_id。labels(5 Bytes): 第10~14字节是node 的label field。extra(1 Byte): 第15字节是 extra , 目前只用到第 1 bit ,表示该node 是否 dense, 缺省的配置是 该 node 的 relationshiop 的数量超过 50 个,这表示是 dense.
NodeStore.java
neo4j 中与neostore.nodestore.db文件相对应的类是NodeStore,负责NodeRecord在neostore.nodestore.db文件中的读写。
下面看一下 NodeStore.java 中 getRecord 成员函数,可以帮助理解 Node Record 的存储格式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
private NodeRecord getRecord(long id, PersistenceWindow window, RecordLoad load) { Buffer buffer = window.getOffsettedBuffer(id); // [ , x] in use bit // [ ,xxx ] higher bits for rel id // [xxxx, ] higher bits for prop idlong inUseByte = buffer.get(); boolean inUse = (inUseByte & amp; 0x1)==Record.IN_USE.intValue(); if (!inUse) { switch (load) { case NORMAL: throw new InvalidRecordException("NodeRecord[" + id + "] not in use"); case CHECK: return null; case FORCE: break; } } long nextRel = buffer.getUnsignedInt(); long nextProp = buffer.getUnsignedInt(); long relModifier = (inUseByte & amp; 0xEL)<<31; long propModifier = (inUseByte & amp; 0xF0L)<<28; long lsbLabels = buffer.getUnsignedInt(); long hsbLabels = buffer.get() & 0xFF; // so that a negative byte won't fill the "extended" bits with ones.long labels = lsbLabels | (hsbLabels << 32);byte extra = buffer.get();boolean dense = (extra & 0x1) > 0;NodeRecord nodeRecord = new NodeRecord( id, dense, longFromIntAndMod( nextRel, relModifier ),longFromIntAndMod( nextProp, propModifier ) );nodeRecord.setInUse( inUse );nodeRecord.setLabelField( labels, Collections.<DynamicRecord>emptyList() );return nodeRecord;} } |
Relationship 的存储
下面是neo4j graph db 中,Relationship数据存储对应的文件:
neostore.relationshipgroupstore.db
neostore.relationshipgroupstore.db.id
neostore.relationshipstore.db
neostore.relationshipstore.db.id
neostore.relationshiptypestore.db
neostore.relationshiptypestore.db.id
neostore.relationshiptypestore.db.names
neostore.relationshiptypestore.db.names.id
neo4j 中, Relationship 的存储是由 RelationshipStore , RelationshipGroupStore, RelationshipTypeTokenStore和StringPropertyStore 4种类型的Store配合来完成的. 其中RelationshipStore 是Relationship最主要的存储结构;当一个Node 的关系数达到一定的阀值时,才会对关系分组(group), RelationshipGroupStore 用来保存关系分组数据;RelationshipTypeTokenStore和StringPropertyStore 配合用来存储关系的类型。
关系的类型的字符串描述值是存在StringPropertyStore这样的DynamicStore 中,如果长度超过一个block ,则分block存储,并将其在StringPropertyStore中的第1个block 的 block_id 保存到 RelationshipTypeTokenStore类型文件相应record 的name_id字段中。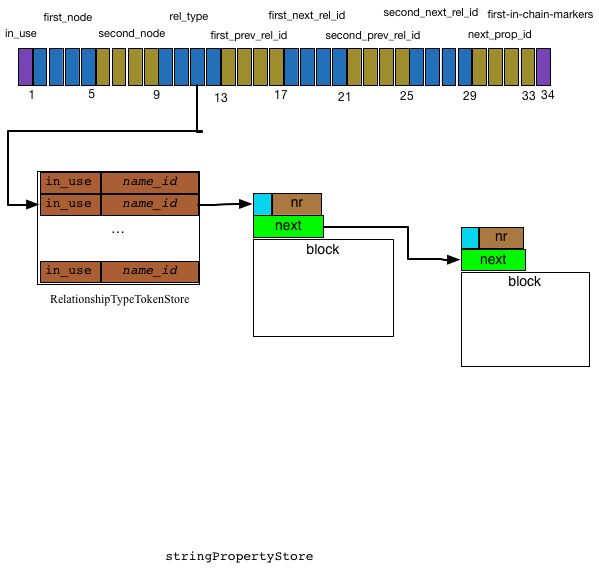
ArrayPropertyStore的存储格式见< 3.3.2 DynamicStore 类型>,下面分别介绍一下RelationshipTypeTokenStore, RelationshipStore和RelationshipStore的文件存储格式。
RelationshipTypeTokenStore的主文件存储格式

类RelationshipTypeTokenStore对应的存储文件是neostore.relationshiptypestore.db,其对应的存储格式如上图所示:是一个长度为 RECORD_SIZE=5 Bytes 的 record 数组和和一个字符串描述符“RelationshipTypeStore v0.A.2”(文件类型描述TYPE_DESCRIPTOR和 neo4j 的 ALL_STORES_VERSION) 构成。访问时,可以通过 token_id 作为数组的下标进行访问。
record 是有 1Byte的 in_use 和 4Bytes 的 name_id 构成。
RelationshipStore的文件存储格式
类RelationshipTypeTokenStore对应的存储文件是neostore.relationshipstore.db,其文件存储格式示意图如下,整个文件是有一个 RECORD_SIZE=34Bytes 的定长数组和一个字符串描述符“RelationshipStore v0.A.2”(文件类型描述TYPE_DESCRIPTOR和 neo4j 的 ALL_STORES_VERSION构成)。访问时,可以通过 node_id 作为数组的下标进行访问。
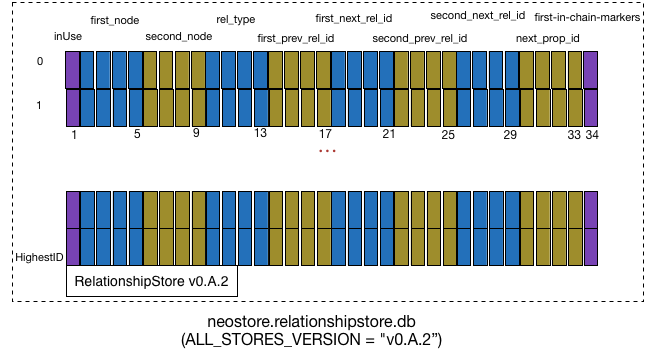
1 2 3 4 5 6 7 8 9 |
// record header size // directed|in_use(byte)+first_node(int)+second_node(int)+rel_type(int)+ // first_prev_rel_id(int)+first_next_rel_id+second_prev_rel_id(int)+ // second_next_rel_id+next_prop_id(int)+first-in-chain-markers(1) public static final int RECORD_SIZE = 34; |
下面介绍一下 relationship record 中每个字段的含义:
in_use(1 Byte): 第 1 字节, 分成3部分.- 第1 bit 表示 record 是否在 use;
- 第2~4 bit 表示first_node的node_id的高3位;
- 第 5~8 bit表示 next_prop_id 的property_id 的 高4位
first_node(4 Bytes): 第2~5字节是RelationShip的from_node 的node_id 的低32位. 加上inUse 字节的第 2~4 bit 作为高3位,构成一个完整的35位node_id。second_node(4 Bytes): 第6~9字节是RelationShip的to_node 的node_id 的低32位. 加上rel_type的第29~31 bit作为高3位,构成一个完整的35位node_id。rel_type(4 Bytes): 第 10~13 字节, 分成6部分;- 第29~31 位是second_node 的node_id高3位;
- 第26~28 位是first_next_rel_id 的 relationship_id高3位;
- 第23~25 位是first_next_rel_id 的relationship_id高3位;
- 第20~22 位是second_prev_rel_id 的relationship_id高3位;
- 第17~19 位是second_next_rel_id 的relationship_id高3位;
- 第 1~16 位 表示 RelationShipType;
first_prev_rel_id(4 Bytes): 第14~17字节是from_node 的排在本RelationShip 前面一个RelationShip的 relationship_id 的低32位. 加上rel_type的第 26~28 bit 作为高3位,构成一个完整的35位relationship_id。first_next_rel_id(4 Bytes): 第18~21字节是from_node 的排在本RelationShip 前面一个RelationShip的 relationship_id 的低32位. 加上rel_type的第 23~25 bit 作为高3位,构成一个完整的35位relationship_id。second_prev_rel_id(4 Bytes): 第22~25字节是from_node 的排在本RelationShip 前面一个RelationShip的 relationship_id 的低32位. 加上rel_type的第 20~22 bit 作为高3位,构成一个完整的35位relationship_id。second_next_rel_id(4 Bytes): 第26~29字节是from_node 的排在本RelationShip 前面一个RelationShip的 relationship_id 的低32位. 加上rel_type的第 17~19 bit 作为高3位,构成一个完整的35位relationship_id。next_prop_id(4 Bytes): 第30~33字节是本RelationShip第1个Property的property_id 的低32位. 加上in_use的第 5~8 bit 作为高3位,构成一个完整的36 位property_id。first-in-chain-markers(1 Byte): 目前只用了第1位和第2位,其作用笔者还没搞清楚。
3.7.2.1 RelationshipStore.java
与neostore.relationshipstore.db文件相对应的类是RelationshipStore,负责RelationshipRecord从neostore.relationshipstore.db文件的读写。下面看一下 neostore.relationshipstore.db 中 getRecord 成员函数,可以帮助理解 Relationship Record 的存储格式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
private RelationshipRecord getRecord( long id, PersistenceWindow window,RecordLoad load ) { Buffer buffer = window.getOffsettedBuffer( id ); // [ , x] in use flag // [ ,xxx ] first node high order bits // [xxxx, ] next prop high order bits long inUseByte = buffer.get(); boolean inUse = (inUseByte & 0x1) == Record.IN_USE.intValue(); if ( !inUse ) { switch ( load ) { case NORMAL: throw new InvalidRecordException( "RelationshipRecord[" + id + "] not in use" ); case CHECK: return null; } } long firstNode = buffer.getUnsignedInt(); long firstNodeMod = (inUseByte & 0xEL) << 31; long secondNode = buffer.getUnsignedInt(); // [ xxx, ][ , ][ , ][ , ] second node high order bits, 0x70000000 // [ ,xxx ][ , ][ , ][ , ] first prev rel high order bits, 0xE000000 // [ , x][xx , ][ , ][ , ] first next rel high order bits, 0x1C00000 // [ , ][ xx,x ][ , ][ , ] second prev rel high order bits, 0x380000 // [ , ][ , xxx][ , ][ , ] second next rel high order bits, 0x70000 // [ , ][ , ][xxxx,xxxx][xxxx,xxxx] type long typeInt = buffer.getInt(); long secondNodeMod = (typeInt & 0x70000000L) << 4; int type = (int)(typeInt & 0xFFFF); RelationshipRecord record = new RelationshipRecord( id, longFromIntAndMod( firstNode, firstNodeMod ), longFromIntAndMod( secondNode, secondNodeMod ), type ); record.setInUse( inUse ); long firstPrevRel = buffer.getUnsignedInt(); long firstPrevRelMod = (typeInt & 0xE000000L) << 7; record.setFirstPrevRel( longFromIntAndMod( firstPrevRel, firstPrevRelMod ) ); long firstNextRel = buffer.getUnsignedInt(); long firstNextRelMod = (typeInt & 0x1C00000L) << 10; record.setFirstNextRel( longFromIntAndMod( firstNextRel, firstNextRelMod ) ); long secondPrevRel = buffer.getUnsignedInt(); long secondPrevRelMod = (typeInt & 0x380000L) << 13; record.setSecondPrevRel( longFromIntAndMod( secondPrevRel, secondPrevRelMod ) ); long secondNextRel = buffer.getUnsignedInt(); long secondNextRelMod = (typeInt & 0x70000L) << 16; record.setSecondNextRel( longFromIntAndMod( secondNextRel, secondNextRelMod ) ); long nextProp = buffer.getUnsignedInt(); long nextPropMod = (inUseByte & 0xF0L) << 28; byte extraByte = buffer.get(); record.setFirstInFirstChain( (extraByte & 0x1) != 0 ); record.setFirstInSecondChain( (extraByte & 0x2) != 0 ); record.setNextProp( longFromIntAndMod( nextProp, nextPropMod ) ); return record; } |
RelationshipGroupStore类型的存储格式
当Node的Relationship数量超过一个阀值时,neo4j 会对 Relationship 进行分组,以便提供性能。neo4j 中用来实现这一功能的类是 RelationshipGroupStore.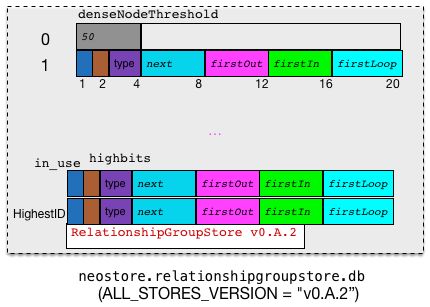
其对应的文件存储格式如下:
整个文件是有一个 RECORD_SIZE=20Bytes 的定长数组和一个字符串“RelationshipGroupStore v0.A.2”(文件类型描述TYPE_DESCRIPTOR和 neo4j 的 ALL_STORES_VERSION构成)。访问时,可以通过 id 作为数组的下标进行访问。数组下标为0的 record 前4 Bytes 保存Relationship分组的阀值。
RelationshipGroupStore 的record 的格式如下:
inUse(1 Byte):第1字节,共分成4部分第1 bit: 表示 record 是否在 use;第2~4 bit: 表示 next 的高3位;第 5~7 bit:表示 firstOut高3位第8 bit:没有用。
highByte(1 Byte):第1字节,共分成4部分第1 bit:没有用;第2~4 bit: 表示 firstIn 的高3位;第 5~7 bit:表示 firstLoop高3位第8 bit:没有用。
next:firstOutfirstInfirstLoop
示例1:neo4j_exam
下面看一个简单的例子,然后看一下几个主要的存储文件,有助于理解<3–neo4j存储结构>描述的neo4j 的存储格式。
neo4j_exm 代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 |