【论文解读 WWW 2020 | HGT】Heterogeneous Graph Transformer

论文题目:Heterogeneous Graph Transformer
论文来源:WWW 2020
论文链接:https://arxiv.org/abs/2003.01332
代码链接:https://github.com/acbull/pyHGT
关键字:GNN,HIN,表示学习,图嵌入,Graph Attention,动态图
文章目录
- 1 摘要
- 2 引言
- 2 定义
- 3 相关工作
- 4 HGT
- 4.1 HGT整体框架
- 4.2 Heterogeneous Mutual Attention
- 4.3 Heterogeneous Message Passing
- 4.4 Target-Specific Aggregation
- 4.5 Relative Temporal Encoding
- 5 Web-scale的HGT训练
- 5.1 HGSamling
- 5.2 Inductive Timestamp Assignment
- 6 实验
- 7 总结
- 参考文献
1 摘要
本文提出异质图转换架构(Heterogeneous Graph Transformer, HGT),用于建模Web-scale的异质图。并且无需人工构建元路径。
为了对异质的节点和边进行建模,作者设计了和节点类别、边类别有关的参数,来表征在每个边上的异质性的注意力。这使得HGT可以为不同类型的节点和边生成专用的表示。
HGT还可以处理动态的异质图。作者在HGT中引入相对时间编码技术,可以捕获到任意时间段内的动态结构依赖关系。
为了能够处理Web-scale的图数据,还设计了mini-batch图采样算法——HGSampling,实现高效并可扩展的训练。
在多个下游任务的实验中(Open Academic Graph of 179 million nodes and 2 billion edges)超越使用GNN的state-of-the-art方法。
2 引言
现有的GNN方法的不足:
以HAN, GTNs, HetGNN等方法为例。
(1)大多数方法需要为异质图设计元路径(GTNs除外);
(2)要不就是假定不同类别的节点/边共享相同的特征和表示空间,要不就是单独为某一类型的节点和边设计不同的不可共享的参数。这样的话不能充分捕获异质图的属性信息;
(3)大多数方法都没有考虑异质图的动态特征;
(4)不能建模Web-scale的异质图。
鉴于以上挑战,作者进行了异质图神经网络的研究,目的是:(1)保留节点和边类型的有依赖关系的特征;(2)捕获网络的动态信息;(3)避免自定义元路径;(4)并且可扩展到大规模(Web-scale)的图上。

作者提出:
提出HGT架构解决上述所有问题,具体解决方法如下:
(1)为了解决图的异质性问题,引入节点类型和边类型有依赖的注意力机制。
HGT中的异质相互注意力不是参数化每种类别的边,而是根据元关系三元组将每个边 e = ( s , t ) e=(s, t) e=(s,t)分解来定义。(例如
使用元关系参数化权重矩阵,用于计算每条边的注意力系数。
因此,不同类型的节点和边就可以维护其特定的表示空间。同时,通过不同的边相连的节点仍然可以交互、传递、聚合信息,并且不受它们之间分布差异的限制。
HGT的天然结构,让其可以通过跨层的信息传递来合并不同类型的高阶邻居的信息,这可以看作是**“软”元路径**(“soft” meta paths)。
也就是说,尽管HGT只将一跳的边作为输入并且不人为设计元路径,本文提出的注意力机制可以针对具体的下游任务自动地、隐式地学习并抽取出更重要的“元路径”。
(2)为了处理动态图,在HGT中引入相对时间编码(RTE)技术。
并不是将输入图按不同的时间戳分片处理,而是将在不同时间出现的所有的边看成一个整体。设计RTE策略,建模任意时间长度的结构性的时间依赖关系,甚至包含不可见的和未来的时间戳。
通过端到端的训练,RTE使得HGT自动学习到异质图的时序依赖关系以及异质图随时间的演化。
(3)为了处理Web-scale的图数据,作者设计了第一个异质的子图采样算法——HGSampling,用于mini-batch的GNN训练。
以往的在同质图上的GNN采样方法(例如 GraphSage, FastGCN, LADIES)会导致节点和边类型的高度不平衡,HGSampling可以使得采样的不同类型的节点有着相似的分布。
同时,该方法还可以保持采样子图的密度,以最小化信息损失。
使用HGSampling的采样方法,所有的GNN模型,包括本文的HGT模型,都可以在任意大小的异质图上进行训练和推断。
2 定义
(1)异质图
G = ( V , E , A , R ) G=(V,E,A,R) G=(V,E,A,R),类型映射函数: τ ( v ) : V → A , ϕ ( e ) : E → R \tau(v): V\rightarrow A, \phi(e): E\rightarrow R τ(v):V→A,ϕ(e):E→R。
(2)元关系
对于从 s s s到 t t t的连边 e = ( s , t ) e=(s, t) e=(s,t),它的元关系定义为 < τ ( s ) , ϕ ( e ) , τ ( t ) > <\tau(s), \phi(e), \tau(t)> <τ(s),ϕ(e),τ(t)>, ϕ ( e ) − 1 \phi(e)^{-1} ϕ(e)−1表示 ϕ ( e ) \phi(e) ϕ(e)的逆。
经典的元路径范式就是这种元关系组成的序列。
(3)动态异质图
在时间戳为 T T T时有边 e = ( s , t ) e=(s, t) e=(s,t),说明在 T T T时刻节点 s s s连向了节点 t t t。若 s s s是第一次出现,则将 T T T分配给 s s s, s s s可以和很多个时间戳相关联。
假定边的时间戳是不变的,表示该边创建的时间。但是可以给节点分配不同的时间戳。
3 相关工作
普遍的GNN框架
令 H l [ t ] H^l[t] Hl[t]为节点 t t t在第 l l l层GNN的节点表示,从 l − 1 l-1 l−1层到 l l l层的更新过程如下:
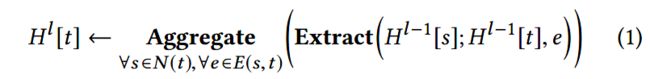
先抽取信息,再聚和信息。例如GCN, GraphSAGE, GAT。
异质的GNNs
(1)已有的一些方法
建模知识图谱的关系图卷积网络(RGCN),为每种类型的边都维护了一个线性的映射权重。
HetGNN为不同类型的节点应用不同的RNNs来整合多模的特征。
HAN为不同的元路径定义的边维护了不同的权重,同时使用了语义级别的注意力机制,有区分性地聚合来源于不同元路径的信息。
(2)这些方法的不足
尽管这些方法都比GCN和GAT表现好,但是它们都没有充分利用异质图的属性信息。都是为边类型和节点类型单独地分配GNN权重矩阵。
但是不同类型的节点数目和不同类型的边的数目差别很大,对于那些共现次数不多的关系类型,就很难为它们学习到准确的权重。
(3)考虑参数共享以实现更好的泛化
为了解决上述问题,提出参数共享。对于给定的边 e = ( s , t ) e=(s, t) e=(s,t),其元关系为 < τ ( s ) , ϕ ( e ) , τ ( t ) > <\tau(s), \phi(e), \tau(t)> <τ(s),ϕ(e),τ(t)>。若使用三个交互矩阵分别建模 τ ( s ) , ϕ ( e ) , τ ( t ) \tau(s), \phi(e), \tau(t) τ(s),ϕ(e),τ(t)这三个元素,则主要参数就可以共享。
例如“第一作者”和“第二作者”这两种关系的源节点都是author,目标节点都是paper。从一种关系学习到的author和paper的知识可以快速转换并应用到另一种关系中。
将这种想法整合到Transformer-like的注意力框架中,从而提出了HGT。
(4)HGT和现有方法的主要不同
-
与单独处理节点类型和边类型不同,作者使用元关系 τ ( s ) , ϕ ( e ) , τ ( t ) \tau(s), \phi(e), \tau(t) τ(s),ϕ(e),τ(t)来分解交互矩阵和转换矩阵,使得HGT在使用等量的参数甚至更少的参数的情况下,捕获不同关系中普通的和特定的信息。
-
不需要预先定义好元路径,使用神经网络框架聚合高阶的异质邻居的信息,自动地学习到元路径的重要性程度。
-
大多数以往的方法没有考虑到动态图,HGT使用相对时间编码技术考虑到了时序信息。
-
现有的异质GNN方法都不能应用在Web-scale的图上,本文提出的HGSampling采样方法可以用于Web-scale图(十亿级别)的训练。
4 HGT
使用异质图中的元关系参数化权重矩阵,以用于异质的互注意力、消息传递。
4.1 HGT整体框架

图2展示了HGT的整体框架。给定采样的异质子图,HGT抽取出了所有有连边的点对, s s s和 t t t通过 e e e相连。
HGT的目的是从源节点聚合信息,获得目标节点的上下文表示。这一过程可被分解成3个部分:(1)异质互注意力(Heterogeneous Mutual Attention);(2)异质消息传递(Heterogeneous Message Passing );(3)针对特定任务的聚合(Target-Specific Aggregation)。
堆叠 L L L层,得到整个图的节点表示 H ( L ) H^{(L)} H(L),然后用于端到端的训练或者输入给下游任务。
4.2 Heterogeneous Mutual Attention
第一步是计算源节点 s s s和目标节点 t t t的注意力系数。基于注意力的GNNs可以看成如下的形式:

可以总结为3个基本的操作:
(1)Attention:评估每个源节点的重要性
(2)Message:从源节点 s s s抽取出信息
(3)Aggregate:使用注意力系数作为权重,聚合邻居的信息
GAT只有一个权重矩阵 W W W,也就是假定 s s s和 t t t有相同的特征分布,这不适合于异质图,异质图中不同类的节点可能有它自己的特征分布。
因此设计了异质的互注意力机制(Heterogeneous Mutual Attention)。给定一个目标节点 t t t,其所有邻居 s ∈ N ( t ) s\in N (t) s∈N(t)可能属于不同的分布,要根据它们的元关系计算它们的相互注意力。
受Transformer的启发,作者将目标节点 t t t映射成Query向量,将源节点 s s s映射成Key向量,计算两者的点积当做attention。
与Transformer的区别在于:Transformer为所有的单词使用一组映射;而本文的方法中,每个元关系都有一组不同的映射矩阵。
在保留不同关系的特性的基础上,为了最大程度地实现参数共享,作者提出将交互操作的权重矩阵参数化为:源节点映射,边映射,目标节点映射。为每个边 e = ( s , t ) e=(s, t) e=(s,t)计算 h − h e a d h-head h−head的注意力,如图2(1)所示。计算过程如下:

解释如下:
(1)首先,对于第 i i i个attention head A T T − h e a d i ( s , e , t ) ATT-head^i(s, e, t) ATT−headi(s,e,t),将类别为 τ ( s ) \tau(s) τ(s)的源节点 s s s使用线性映射 K − L i n e a r τ ( s ) i : R d → R d h K-Linear^i_{\tau(s)} : \mathbb{R}^d \rightarrow \mathbb{R}^{\frac{d}{h}} K−Linearτ(s)i:Rd→Rhd,映射成第 i i i个Key向量 K i ( s ) K^i(s) Ki(s)。
其中 h h h是attention head的数量, d h \frac{d}{h} hd是每个head的向量维度。
注意,$K-Linear^i_{\tau(s)} $以源节点的类型作为索引,表示每种类型的节点都有一个线性映射,以实现最大程度建模不同类型节点的分布差异性。
同样的,对目标节点 t t t也使用线性映射 Q − L i n e a r τ ( t ) i Q-Linear^i_{\tau(t)} Q−Linearτ(t)i,将其映射成第 i i i个Query向量。
(2)接着,计算 Q ( t ) i , K ( s ) i Q^i_{(t)},K^i_{(s)} Q(t)i,K(s)i间的相似度。由于异质图中边类型多样(一对节点之间可能有不同类型的边),所以不同于原始的Transformer直接对Query和Key向量进行内积操作,而是为每种类型的边 ϕ ( e ) \phi(e) ϕ(e)维护不同的矩阵 W ϕ ( e ) A T T ∈ ( R ) d h × d h W^{ATT}_{\phi(e)}\in \mathbb(R)^{\frac{d}{h}\times \frac{d}{h}} Wϕ(e)ATT∈(R)hd×hd。这样,就可以捕获节点对之间不同的语义关联。
然而,不同类型的边对目标节点的贡献度不同,所以添加一个先验的张量 μ ∈ R ∣ A ∣ × ∣ R ∣ × ∣ A ∣ \mu\in \mathbb{R}^{|A|\times |R|\times |A|} μ∈R∣A∣×∣R∣×∣A∣表示对每个元关系三元组的一般化的重要性,作为对attention的adaptive scaling。
(3)最后,将 h h h个attention heads拼接起来得到每个节点对的注意力向量。对于每个目标节点 t t t,聚合它所有邻居的注意力向量,并通过一层softmax,使得每个head的注意力系数和为1。
4.3 Heterogeneous Message Passing
从源节点向目标节点传递信息,这一步是和互注意力的计算并行的,如图2(2)所示。
目标是将不同边的元关系合并到消息传递过程中,来缓解不同类型的节点和边分布的差异性。
对于节点对 e = ( s , t ) e=(s, t) e=(s,t),multi-head的Message可以计算为:
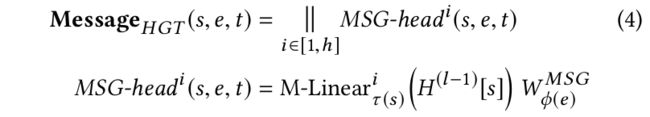
为了得到 M S G − h e a d i ( s , e , t ) MSG-head^i(s, e, t) MSG−headi(s,e,t),首先使用线性映射 M − L i n e a r τ ( s ) i : R d → R d h M-Linear^i_{\tau(s)}: \mathbb{R}^d \rightarrow \mathbb{R}^{\frac{d}{h}} M−Linearτ(s)i:Rd→Rhd 将类型为 τ ( s ) \tau(s) τ(s)的源节点 s s s映射成第 i i i个message向量。
然后再对特定类型的边维护一个参数矩阵 W ϕ ( e ) M S G ∈ R d h × d h W^{MSG}_{\phi(e)}\in \mathbb{R}^{\frac{d}{h}\times \frac{d}{h}} Wϕ(e)MSG∈Rhd×hd。
最后将 h h h个message heads相拼接得到每个节点对的 M e s s a g e H G T ( s , e , t ) Message_{HGT}(s, e, t) MessageHGT(s,e,t)。
4.4 Target-Specific Aggregation
如图2(3)所示,聚合上两步得到的信息。
使用attention向量作为权重,对来自源节点的相应信息进行平均,得到更新后的向量:
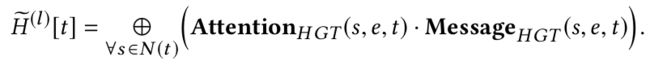
最后一步是以目标节点的类别 τ ( t ) \tau(t) τ(t)为索引,将目标节点 t t t的向量映射回到对应类别的分布。具体来说,对更新后的向量 H ~ ( l ) [ t ] \tilde{H}^{(l)}[t] H~(l)[t] 使用线性映射 A − L i n e a r τ ( t ) A-Linear_{\tau(t)} A−Linearτ(t),然后还有前一层的 t t t的原始向量作为残差连接:
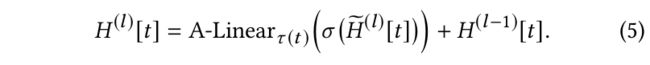
这样,就得到了目标节点 t t t在第 l l l层HGT的输出 H ( l ) [ t ] H^{(l)}[t] H(l)[t]。
堆叠 L L L层( L L L是一个很小的值)就可以为每个节点得到有丰富信息的上下文表示 H ( L ) H^{(L)} H(L)。 H ( L ) H^{(L)} H(L)可作为下游任务的输入,例如图节点分类和链接预测任务。
整个框架中,高度依赖于元关系—— < τ ( s ) , ϕ ( e ) , τ ( t ) > <\tau(s), \phi(e), \tau(t)> <τ(s),ϕ(e),τ(t)>来参数化权重矩阵。和现有的维每个元路径维护一个矩阵的方法相比,HGT的三元组参数可以更好地利用异质图的schema来实现参数共享。
一方面,这样的参数共享有助于利用出现频次较少的类型的边,从而实现快速的自适应和泛化。
另一方面,使用较少的参数,仍然实现了保留不同类型边的特征。
4.5 Relative Temporal Encoding
提出相对时间编码(RTE)技术处理动态图。
传统的方法是为每个小时间片(time slot)构建图,但这种方法会丢失大量的不同时间片间的结构依赖信息。
因此,受Transformer的位置编码(position embedding)启发,作者提出RTE机制,建模异质图上的动态依赖关系。

给定源节点 s s s和目标节点 t t t,以及它们对应的时间戳 T ( s ) , T ( t ) T(s), T(t) T(s),T(t)。定义相对时间间隔为 Δ T ( t , s ) = T ( t ) − T ( s ) \Delta T(t, s)=T(t)-T(s) ΔT(t,s)=T(t)−T(s),作为得到相对时间编码 R T E ( Δ T ( t , s ) ) RTE(\Delta T(t,s)) RTE(ΔT(t,s))的索引。
注意训练集不会覆盖到所有可能的时间间隔,因此RTE要具有泛化到不可见的时间和时间间隔的能力。作者采取了一组固定的正弦函数作为偏置,并使用了可微调的线性映射 T − L i n e a r ∗ : R d → R d T-Linear^{*}: \mathbb{R}^d \rightarrow \mathbb{R}^d T−Linear∗:Rd→Rd,构成RTE:

最后,将相对于目标节点 t t t的时间编码加入到源节点 s s s的表示中:
时间增广的表示 H ^ ( l − 1 ) \hat{H}^{(l-1)} H^(l−1)就可以捕获到源节点 s s s和目标节点 t t t的相对时间信息。RTE的流程如图3所示。
5 Web-scale的HGT训练
5.1 HGSamling
full-batch的GNN训练需要在每层计算所有节点的表示,不能扩展到Web-scale的图上。
本文提出HGSampling方法,可以实现:
(1)对于每种类型的节点和边,采样的数量大致相似;
(2)保持采样的子图的稠密性,以最小化采样方差带来的信息损失。

上图中的算法1展示了HGSampling算法。基本思想是对每个节点类型 τ \tau τ维护一个node budget B [ τ ] B[\tau] B[τ],并使用重要性采样策略,为每个类型采样相等数量的节点,以减小方差。

给定已被采样的节点 t t t,使用算法2将它的一阶邻居加入到对应的budget中,并将 t t t的归一化的度与这些邻居相加(如 算法2的line 8所示),之后将被用于计算采样概率。
这样的归一化等价于累计每个被采样的节点到其邻居的random walk概率,从而避免了采样过多的度数高的节点。
直观来看,这个值越大,和当前被采样节点相关联的节点就越有可能是候选节点,应该被赋予更大的采样概率。
在budget更新后,计算采样概率(如 算法1的line 9所示),使用这种采样概率可以减小采样的方差[1]。
然后使用上面计算得到的概率,采样 n n n个类型为 τ \tau τ的节点。将它们加入到输出的节点集合$OS中,将它们的邻居更新到budget中,并将它们自己从budget中移除。(如 算法1的line12-15所示)
将这个过程重复 L L L次,采样得到深度为 L L L的子图。
最后,利用采样到的节点重构邻接矩阵。
通过使用上述算法,采样到的子图中每个类别都有相似数量的节点(基于各自的node budget),就可以在Web-scale的异质图上训练GNN了。
5.2 Inductive Timestamp Assignment
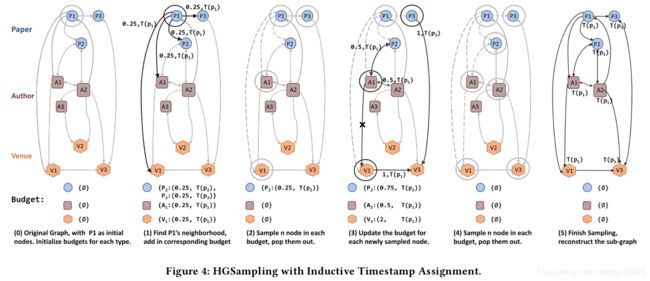
目前为止,作者假定每个节点 t t t都被分配了一个时间戳 T ( t ) T(t) T(t)。然而,在现实世界中许多节点不止和一个时间戳有关,所以需要为及诶单分配不同的时间戳。
例如,WWW会议在1974年和2019年都有举办,这两年的WWW节点有不同的研究主题。异质图中也存在只有一个时间戳的事件节点,比如paper节点,和其发表日期相关。
作者提出归纳式的时间戳分配算法(inductive timestamp assignment algorithm ),基于和节点相连的事件节点,为其分配时间戳。如算法2的line 6所示。思想是:计划节点继承事件节点的时间戳。
首先检查候选的源节点是否是一个事件节点,如果是的话(例如 paper在某一年被发表)则保留它的时间戳用于捕获时序依赖关系;如果不是的话(例如conference可以和任意的时间戳有关),则为其分配相关节点的时间戳(例如conference中的paper发表的年份)。这样就可以在子图采样过程中自适应地为节点分配时间戳。
6 实验
Web-Scale数据集:
Open Academic Graph (OAG) ,包含178 million个节点和2.236 billion条边。

实验任务:
一共四个:Paper-Field( L 1 L_1 L1)的预测,Paper-Field( L 2 L_2 L2)的预测,Paper-Venue的预测,作者消歧的预测
前三个节点分类任务是预测每个paper属于的正确的领域 L 1 , L 2 L_1, L_2 L1,L2,或者是该paper发表在了哪个venue上。
使用不同的GNN方法得到paper的上下文节点表示,并使用softmax输出层得到它的类别标签。
对于作者消歧,选择所有同名的作者以及他们的papers。任务是对这些papers和候选的作者进行链接预测。
使用GNN方法得到paper和作者的节点表示后,使用Neural Tensor Network得到每个author-paper对连接的概率。
对比方法:
- GCN
- GAT
- RGCN
- HetGNN
- HAN
实验结果:
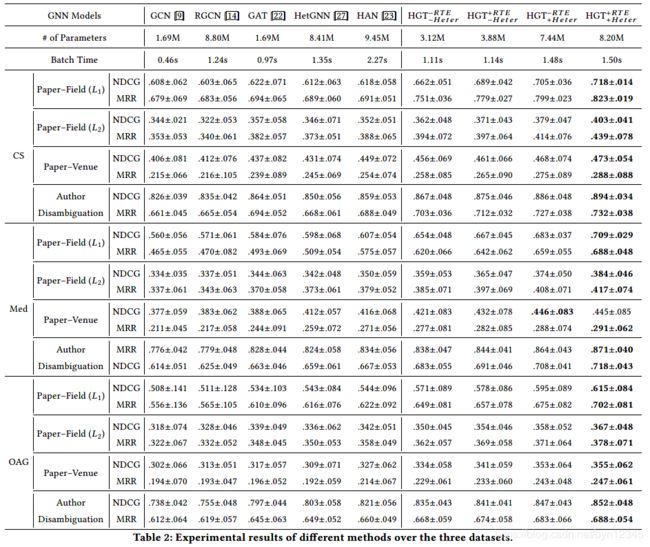
(1)上述四个任务的实验结果
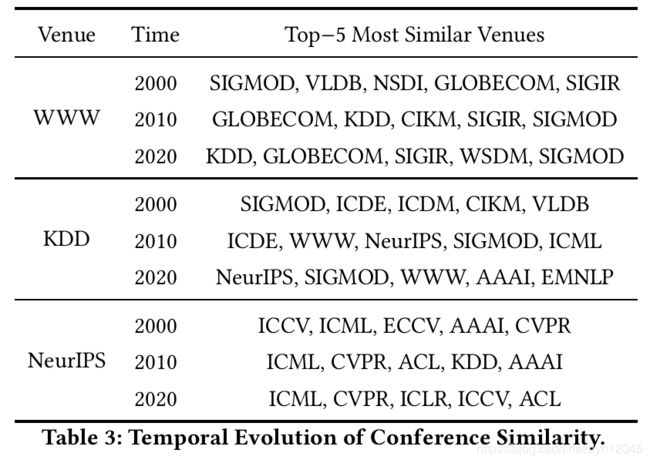
(2)引入时间信息的会议相似性
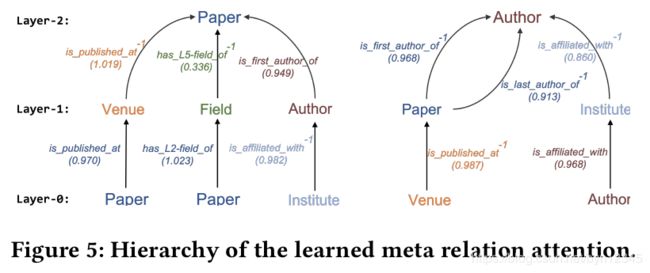
(3)元关系注意力可视化
下图的左半部分可以看出元路径PAP, PFP, IAP是最重要的元路径,并且重要性系数是自动学习得到的,不需要人工操作。
7 总结
本文提出了HGT架构,用于建模Web-scale的异质图以及动态图。
(1)为了建模异质性,使用了元关系 < τ ( s ) , ϕ ( e ) , τ ( t ) > <\tau(s), \phi(e), \tau(t)> <τ(s),ϕ(e),τ(t)>分解交互和转换矩阵,使得在资源很少的情况下模型也能有可接受的建模能力。
(2)为了捕获图的动态性特征,提出相对时间编码(RTE)技术,使用有限的计算资源合并时间信息。
(3)为了使得HGT可扩展到Web-scale的数据上,设计了异质的mini-batch图采样算法——HGSampling。
未来的工作:探究HGT是否能生成异质图,例如预测新papers和其标题。以及HGT是否可用于预训练,以对标注数据很少的任务带来帮助。
本文的工作非常有新意,论文中的很多部分都是受Transformer的启发。
不需要人为定义元路径,而是使用注意力机制,自动地学习到重要性较大的元路径,这个思路和GTNs很像。
受Transformer启发的地方一共有两个:
(1)异质的互注意力计算和Transformer的attention类似:将目标节点映射成Query向量,源节点映射为Key向量,还使用了多头注意力机制(multi-head attention)。
(2)相对时间编码技术(RTE)和Transformer的位置编码类似。
另外,作者在未来展望中还提到要研究HGT是否能用于图的预训练,从而对标注数据不多的任务带来帮助。这一点可以让人联想到这几年NLP领域大放异彩的预训练技术,图上的预训练也让人期待啊。
参考文献
[1] Difan Zou, Ziniu Hu, Yewen Wang, Song Jiang, Yizhou Sun, and Quanquan Gu. 2019. Layer-Dependent Importance Sampling for Training Deep and Large Graph Convolutional Networks. In NeurIPS’19.