C++复习二-默认参数-内联函数-头文件处理-类与对象
目录
1.头文件处理记住:
2.内联函数:
3.C++函数的默认参数详解
4.C++函数重载
5.类与对象
块内容-命名空间
块内容-函数调用惯例(stdcall,cdecl,pascal等解释)
块内容-C语言const的用法详解
块内容-二维数组指针
6.构造函数和析构函数
默认构造函数初始化列表:
析构函数的执行时机
封闭类和对象
成员对象的消亡
this指针
7.C++ static静态成员变量与函数
8.const成员变量、函数、对象
const成员变量
const成员函数(常成员函数)
C++ const对象(常对象)
9.C++友元函数和友元类(C++ friend关键字)
友元函数
友元类
10.类其实也是一种作用域
需要记住C++ class和struct到底有什么区别:
1.头文件处理记住:
全局变量最好在.c文件里直接声明和定义,如果其他文件需要引用,直接extern。
extern不要定义了,否则就重复了。
函数extern或者include貌似都没什么问题。
2.内联函数:
内联函数inline标志符是用来实现的,不是用来声明的;
内联函数虽然叫做函数,在定义和声明的语法上也和普通函数一样,但它已经失去了函数的本质。函数是一段可以重复使用的代码,它位于虚拟地址空间中的代码区,也占用可执行文件的体积,而内联函数的代码在编译后就被消除了,不存在于虚拟地址空间中,没法重复使用。
函数调用是有时间和空间开销的。程序在执行一个函数之前需要做一些准备工作,要将实参、局部变量、返回地址以及若干寄存器都压入栈中,然后才能执行函数体中的代码;函数体中的代码执行完毕后还要清理现场,将之前压入栈中的数据都出栈,才能接着执行函数调用位置以后的代码。
如果函数体代码比较多,需要较长的执行时间,那么函数调用机制占用的时间可以忽略;如果函数只有一两条语句,那么大部分的时间都会花费在函数调用机制上,这种时间开销就就不容忽视。
使用内联函数的缺点也是非常明显的,编译后的程序会存在多份相同的函数拷贝,如果被声明为内联函数的函数体非常大,那么编译后的程序体积也将会变得很大,所以再次强调,一般只将那些短小的、频繁调用的函数声明为内联函数。
由于内联函数比较短小,我们通常的做法是省略函数原型,将整个函数定义(包括函数头和函数体)放在本应该提供函数原型的地方。
宏定义是一项“细思极密”的工作,一不小心就会踩坑,而且不一定在编译和运行时发现,给程序埋下隐患。
如果我们将宏替换为内联函数,情况就没有那么复杂了,程序员就会游刃有余,
3.C++函数的默认参数详解
所谓默认参数,指的是当函数调用中省略了实参时自动使用的一个值,这个值就是给形参指定的默认值。
#include
using namespace std;
//带默认参数的函数
void func(int n, float b=1.2, char c='@'){
cout< 默认参数除了使用数值常量指定,也可以使用表达式指定;
float d = 10.8;
void func(int n, float b=d+2.9, char c='@'){
cout<C++规定,默认参数只能放在形参列表的最后,而且一旦为某个形参指定了默认值,那么它后面的所有形参都必须有默认值。实参和形参的传值是从左到右依次匹配的,默认参数的连续性是保证正确传参的前提。
我们在函数定义处指定了默认参数。除了函数定义,你也可以在函数声明处指定默认参数。不过当出现函数声明时情况会变得稍微复杂。
因为C++ 规定,在给定的作用域中只能指定一次默认参数。
C和C++语言有四种作用域,分别是函数原型作用域、局部作用域(函数作用域)、块作用域、文件作用域(全局作用域)。
所以函数原型定义在一个文件,函数声明在另一个文件就好了,两个文件的函数默认参数都可以指定,以发起调用的主函数的为主。
默认参数划重点部分:多次声明默认参数(同一函数);
4.C++函数重载
在实际开发中,有时候我们需要实现几个功能类似的函数,只是有些细节不同。例如希望交换两个变量的值,这两个变量有多种类型,可以是 int、float、char、bool 等,我们需要通过参数把变量的地址传入函数内部。在C语言中,程序员往往需要分别设计出三个不同名的函数,其函数原型与下面类似:
void swap1(int *a, int *b); //交换 int 变量的值
void swap2(float *a, float *b); //交换 float 变量的值
void swap3(char *a, char *b); //交换 char 变量的值
void swap4(bool *a, bool *b); //交换 bool 变量的值但在C++中,这完全没有必要。C++ 允许多个函数拥有相同的名字,只要它们的参数列表不同就可以,这就是函数的重载(Function Overloading)。借助重载,一个函数名可以有多种用途。
参数列表又叫参数签名,包括参数的类型、参数的个数和参数的顺序,只要有一个不同就叫做参数列表不同。
函数返回值也不能作为重载的依据。
后面直接用模板类解决更方便。
5.类与对象
类只是一个模板(Template),编译后不占用内存空间,所以在定义类时不能对成员变量进行初始化,因为没有地方存储数据。只有在创建对象以后才会给成员变量分配内存,这个时候就可以赋值了。
创建对象:
Student stu1;
stu1.name="test";
int a=1234;
char name[]="test";
Student*stu2=new Student(name,a);
Student*stu3=new Student;
delete stu2;
delete stu3;
Student*stu4=&stu1;::被称为域解析符(也称作用域运算符或作用域限定符),用来连接类名和函数名,指明当前函数属于哪个类。
成员函数必须先在类体中作原型声明,然后在类外定义,也就是说类体的位置应在函数定义之前。
在类体中和类体外定义成员函数是有区别的:在类体中定义的成员函数会自动成为内联函数,在类体外定义的不会。当然,在类体内部定义的函数也可以加 inline 关键字,但这是多余的,因为类体内部定义的函数默认就是内联函数。
内联函数一般不是我们所期望的,它会将函数调用处用函数体替代,所以我建议在类体内部对成员函数作声明,而在类体外部进行定义,这是一种良好的编程习惯,实际开发中大家也是这样做的。
C++通过 public、protected、private 三个关键字来控制成员变量和成员函数的访问权限,它们分别表示公有的、受保护的、私有的,被称为成员访问限定符。所谓访问权限,就是你能不能使用该类中的成员。
Java、 C# 程序员注意,C++ 中的 public、private、protected 只能修饰类的成员,不能修饰类,C++中的类没有共有私有之分。
成员变量大都以m_开头,这是约定成俗的写法,不是语法规定的内容。以m_开头既可以一眼看出这是成员变量,又可以和成员函数中的形参名字区分开。
以 setname() 为例,如果将成员变量m_name的名字修改为name,那么 setname() 的形参就不能再叫name了,得换成诸如name1、_name这样没有明显含义的名字,否则name=name;这样的语句就是给形参name赋值,而不是给成员变量name赋值。
根据C++软件设计规范,实际项目开发中的成员变量以及只在类内部使用的成员函数(只被成员函数调用的成员函数)都建议声明为 private,而只将允许通过对象调用的成员函数声明为 public。
另外还有一个关键字 protected,声明为 protected 的成员在类外也不能通过对象访问,但是在它的派生类内部可以访问。
在一个类体中,private 和 public 可以分别出现多次。每个部分的有效范围到出现另一个访问限定符或类体结束时(最后一个右花括号)为止。但是为了使程序清晰,应该养成这样的习惯,使每一种成员访问限定符在类定义体中只出现一次。
类是创建对象的模板,不占用内存空间,不存在于编译后的可执行文件中;而对象是实实在在的数据,需要内存来存储。对象被创建时会在栈区或者堆区分配内存。
直观的认识是,如果创建了 10 个对象,就要分别为这 10 个对象的成员变量和成员函数分配内存。
编译器会将成员变量和成员函数分开存储:分别为每个对象的成员变量分配内存,但是所有对象都共享同一段函数代码。

成员变量在堆区或栈区分配内存,成员函数在代码区分配内存。
//在栈上创建对象
Student stu;
cout<Student 类包含三个成员变量,它们的类型分别是 char *、int、float,都占用 4 个字节的内存,加起来共占用 12 个字节的内存。通过 sizeof 求得的结果等于 12,恰好说明对象所占用的内存仅仅包含了成员变量。
类可以看做是一种复杂的数据类型,也可以使用 sizeof 求得该类型的大小。从运行结果可以看出,在计算类这种类型的大小时,只计算了成员变量的大小,并没有把成员函数也包含在内。
对象的大小只受成员变量的影响,和成员函数没有关系。
假设 stu 的起始地址为 0X1000,那么该对象的内存分布如下图所示: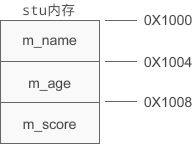
块内容-命名空间
块内容-函数调用惯例(stdcall,cdecl,pascal等解释)
{
| 调用惯例 | 参数传递方式 | 参数出栈方式 | 名字修饰 |
|---|---|---|---|
| cdecl | 按照从右到左的顺序入栈 | 调用方 | 下划线+函数名, 如函数 max() 的修饰名为 _max |
| stdcall | 按照从右到左的顺序入栈 | 函数本身 (被调用方) |
下划线+函数名+@+参数的字节数, 如函数 int max(int m, int n) 的修饰名为 _max_@8 |
| fastcall | 将部分参数放入寄存器, 剩下的参数按照从右到左的顺序入栈 |
函数本身 (被调用方) |
@+函数名+@+参数的字节数 |
| pascal | 按照从左到右的顺序入栈 | 函数本身 (被调用方) |
较为复杂,这里不再展开讨论 |
}
块内容-C语言const的用法详解
块内容-二维数组指针
{
#include
int main(){
int a[3][4] = { {0, 1, 2, 3}, {4, 5, 6, 7}, {8, 9, 10, 11} };
int (*p)[4] = a;
printf("%d\n", sizeof(*(p+1)));
return 0;
} 运行结果:16
*(p+1)相当于代表a的第二个小数组的数组名,也就是说是个地址;就像一维数组的名字,在定义时或者和 sizeof、& 一起使用时才表示整个数组,出现在表达式中就会被转换为指向数组第 0 个元素的指针。
a+i == p+i
a[i] == p[i] == *(a+i) == *(p+i)
a[i][j] == p[i][j] == *(a[i]+j) == *(p[i]+j) == *(*(a+i)+j) == *(*(p+i)+j)
}
6.构造函数和析构函数
构造函数必须是 public 属性的,否则创建对象时无法调用。
构造函数没有返回值,因为没有变量来接收返回值,即使有也毫无用处,这意味着:
- 不管是声明还是定义,函数名前面都不能出现返回值类型,即使是 void 也不允许;
- 函数体中不能有 return 语句。
构造函数一旦自行设置创建对象就一定要调用,因为自行设置后系统提供的默认构造函数失效了。
调用没有参数的构造函数也可以省略括号。在栈上创建对象可以写作Student stu()或Student stu,在堆上创建对象可以写作Student *pstu = new Student()或Student *pstu = new Student,它们都会调用构造函数 Student()。
默认构造函数初始化列表:
//采用初始化列表
Student::Student(char *name, int age, float score): m_name(name), m_age(age), m_score(score){
//TODO:
}注意,成员变量的初始化顺序与初始化列表中列出的变量的顺序无关,它只与成员变量在类中声明的顺序有关。
Demo::Demo(int b): m_b(b), m_a(m_b){ }
在初始化列表中,我们将 m_b 放在了 m_a 的前面,看起来是先给 m_b 赋值,再给 m_a 赋值,其实不然!
成员变量的赋值顺序由它们在类中的声明顺序决定,在 Demo 类中,我们先声明的 m_a,再声明的 m_b,
所以构造函数和下面的代码等价:
Demo::Demo(int b): m_b(b), m_a(m_b){
m_a = m_b;
m_b = b;
}初始化 const 成员变量的唯一方法就是使用初始化列表。
class VLA{
private:
const int m_len;
int *m_arr;
public:
VLA(int len);
};
//必须使用初始化列表来初始化 m_len
VLA::VLA(int len): m_len(len){
m_arr = new int[len];
}析构函数(Destructor)也是一种特殊的成员函数,没有返回值,不需要程序员显式调用(程序员也没法显式调用),而是在销毁对象时自动执行。
析构函数的执行时机
析构函数在对象被销毁时调用,而对象的销毁时机与它所在的内存区域有关。不了解内存分区的读者请阅读《C语言内存精讲》专题。
在所有函数之外创建的对象是全局对象,它和全局变量类似,位于内存分区中的全局数据区,程序在结束执行时会调用这些对象的析构函数。
在函数内部创建的对象是局部对象,它和局部变量类似,位于栈区,函数执行结束时会调用这些对象的析构函数。
new 创建的对象位于堆区,通过 delete 删除时才会调用析构函数;如果没有 delete,析构函数就不会被执行。
#include
#include
using namespace std;
class Demo{
public:
Demo(string s);
~Demo();
private:
string m_s;
};
Demo::Demo(string s): m_s(s){ }
Demo::~Demo(){ cout< 封闭类和对象
#include
using namespace std;
//轮胎类
class Tyre{
public:
Tyre(int radius, int width);
void show() const;
private:
int m_radius; //半径
int m_width; //宽度
};
Tyre::Tyre(int radius, int width) : m_radius(radius), m_width(width){ }
void Tyre::show() const {
cout << "轮毂半径:" << this->m_radius << "吋" << endl;
cout << "轮胎宽度:" << this->m_width << "mm" << endl;
}
//引擎类
class Engine{
public:
Engine(float displacement = 2.0);
void show() const;
private:
float m_displacement;
};
Engine::Engine(float displacement) : m_displacement(displacement) {}
void Engine::show() const {
cout << "排量:" << this->m_displacement << "L" << endl;
}
//汽车类
class Car{
public:
Car(int price, int radius, int width);
void show() const;
private:
int m_price; //价格
Tyre m_tyre;
Engine m_engine;
};
Car::Car(int price, int radius, int width): m_price(price), m_tyre(radius, width)/*指明m_tyre对象的初始化方式*/{ };
void Car::show() const {
cout << "价格:" << this->m_price << "¥" << endl;
this->m_tyre.show();
this->m_engine.show();
}
int main()
{
Car car(200000, 19, 245);
car.show();
return 0;
}
运行结果:
价格:200000¥
轮毂直径:19吋
轮胎宽度:245mm
排量:2L
Car 是一个封闭类,它有两个成员对象:m_tyre 和 m_engine。在编译第 51 行时,编译器需要知道 car 对象中的 m_tyre 和 m_engine 成员对象该如何初始化。
编评器已经知道这里的 car 对象是用第 42 行的 Car(int price, int radius, int width) 构造函数初始化的,那么 m_tyre 和 m_engine 该如何初始化,就要看第 42 行后面的初始化列表了。该初始化列表表明:
- m_tyre 应以 radius 和 width 作为参数调用 Tyre(int radius, int width) 构造函数初始化。
- 但是这里并没有说明 m_engine 该如何处理。在这种情况下,编译器就认为 m_engine 应该用 Engine 类的无参构造函数初始化。而 Engine 类确实有一个无参构造函数(因为设置了默认参数),因此,整个 car 对象的初始化问题就都解决了。
总之,生成封闭类对象的语句一定要让编译器能够弄明白其成员对象是如何初始化的,否则就会编译错误。
在上面的程序中,如果 Car 类的构造函数没有初始化列表,那么第 51 行就会编译出错,因为编译器不知道该如何初始化 car.m_tyre 对象,因为 Tyre 类没有无参构造函数,而编译器又找不到用来初始化 car.m_tyre 对象的参数。
成员对象的消亡
封闭类对象生成时,先执行所有成员对象的构造函数,然后才执行封闭类自己的构造函数。成员对象构造函数的执行次序和成员对象在类定义中的次序一致,与它们在构造函数初始化列表中出现的次序无关。
当封闭类对象消亡时,先执行封闭类的析构函数,然后再执行成员对象的析构函数,成员对象析构函数的执行次序和构造函数的执行次序相反,即先构造的后析构,这是 C++ 处理此类次序问题的一般规律。
this指针
this 代表着当前调用类的对象的地址,只能用在类的内部。
通过 this 可以访问类的所有成员,包括 private、protected、public 属性的。
本例中成员函数的参数和成员变量重名,只能通过 this 区分。以成员函数setname(char *name)为例,它的形参是name,和成员变量name重名,如果写作name = name;这样的语句,就是给形参name赋值,而不是给成员变量name赋值。而写作this -> name = name;后,=左边的name就是成员变量,右边的name就是形参,一目了然。
注意,this 是一个指针,要用->来访问成员变量或成员函数。
this 虽然用在类的内部,但是只有在对象被创建以后才会给 this 赋值,并且这个赋值的过程是编译器自动完成的,不需要用户干预,用户也不能显式地给 this 赋值。本例中,this 的值和 pstu 的值是相同的。
this 实际上是成员函数的一个形参,在调用成员函数时将对象的地址作为实参传递给 this。不过 this 这个形参是隐式的,它并不出现在代码中,而是在编译阶段由编译器默默地将它添加到参数列表中。
7.C++ static静态成员变量与函数
static 成员变量的内存既不是在声明类时分配,也不是在创建对象时分配,而是在(类外)初始化时分配。
反过来说,没有在类外初始化的 static 成员变量不能使用。
class Student{
public:
Student(char *name, int age, float score);
void show();
public:
static int m_total; //静态成员变量
private:
char *m_name;
int m_age;
float m_score;
};
初始化:
static 成员变量必须在类声明的外部初始化,具体形式为:
type class::name = value;
type 是变量的类型,class 是类名,name 是变量名,value 是初始值。将上面的 m_total 初始化:
int Student::m_total = 0;
静态成员变量在初始化时不能再加 static,但必须要有数据类型。
被 private、protected、public 修饰的静态成员变量都可以用这种方式初始化。
访问:
//通过类类访问 static 成员变量
Student::m_total = 10;
//通过对象来访问 static 成员变量
Student stu("小明", 15, 92.5f);
stu.m_total = 20;
//通过对象指针来访问 static 成员变量
Student *pstu = new Student("李华", 16, 96);
pstu -> m_total = 20;
int main(){
//创建匿名对象
(new Student("小明", 15, 90)) -> show();
(new Student("李磊", 16, 80)) -> show();
(new Student("张华", 16, 99)) -> show();
(new Student("王康", 14, 60)) -> show();
return 0;
}
1) 一个类中可以有一个或多个静态成员变量,所有的对象都共享这些静态成员变量,都可以引用它。
2) static 成员变量和普通 static 变量一样,都在内存分区中的全局数据区分配内存,到程序结束时才释放。这就意味着,static 成员变量不随对象的创建而分配内存,也不随对象的销毁而释放内存。而普通成员变量在对象创建时分配内存,在对象销毁时释放内存。
3) 静态成员变量必须初始化,而且只能在类体外进行。例如:
int Student::m_total = 10;
初始化时可以赋初值,也可以不赋值。如果不赋值,那么会被默认初始化为 0。全局数据区的变量都有默认的初始值 0,而动态数据区(堆区、栈区)变量的默认值是不确定的,一般认为是垃圾值。
4) 静态成员变量既可以通过对象名访问,也可以通过类名访问,但要遵循 private、protected 和 public 关键字的访问权限限制。当通过对象名访问时,对于不同的对象,访问的是同一份内存。
静态成员函数与普通成员函数的根本区别在于:普通成员函数有 this 指针,可以访问类中的任意成员;而静态成员函数没有 this 指针,只能访问静态成员(包括静态成员变量和静态成员函数)。
和静态成员变量类似,静态成员函数在声明时要加 static,在定义时不能加 static。静态成员函数可以通过类来调用(一般都是这样做),也可以通过对象来调用。
#include
using namespace std;
class Student{
public:
Student(char *name, int age, float score);
void show();
public: //声明静态成员函数
static int getTotal();
static float getPoints();
private:
static int m_total; //总人数
static float m_points; //总成绩
private:
char *m_name;
int m_age;
float m_score;
};
int Student::m_total = 0;
float Student::m_points = 0.0;
Student::Student(char *name, int age, float score): m_name(name), m_age(age), m_score(score){
m_total++;
m_points += score;
}
void Student::show(){
cout< show();
(new Student("李磊", 16, 80.5)) -> show();
(new Student("张华", 16, 99.0)) -> show();
(new Student("王康", 14, 60.8)) -> show();
int total = Student::getTotal();
float points = Student::getPoints();
cout<<"当前共有"< 8.const成员变量、函数、对象
const成员变量
const 成员变量的用法和普通 const 变量的用法相似,只需要在声明时加上 const 关键字。初始化 const 成员变量只有一种方法,就是通过构造函数的初始化列表。
const成员函数(常成员函数)
const 成员函数可以使用类中的所有成员变量,但是不能修改它们的值,这种措施主要还是为了保护数据而设置的。const 成员函数也称为常成员函数。
我们通常将 get 函数设置为常成员函数。读取成员变量的函数的名字通常以get开头,后跟成员变量的名字,所以通常将它们称为 get 函数。
常成员函数需要在声明和定义的时候在函数头部的结尾加上 const 关键字,请看下面的例子:
class Student{
public:
Student(char *name, int age, float score);
void show();
//声明常成员函数
char *getname() const;
int getage() const;
float getscore() const;
private:
char *m_name;
int m_age;
float m_score;
};
Student::Student(char *name, int age, float score): m_name(name), m_age(age), m_score(score){ }
void Student::show(){
cout<最后再来区分一下 const 的位置:
- 函数开头的 const 用来修饰函数的返回值,表示返回值是 const 类型,也就是不能被修改,例如
const char * getname()。 - 函数头部的结尾加上 const 表示常成员函数,这种函数只能读取成员变量的值,而不能修改成员变量的值,例如
char * getname() const。
C++ const对象(常对象)
在 C++ 中,const 也可以用来修饰对象,称为常对象。一旦将对象定义为常对象之后,就只能调用类的 const 成员(包括 const 成员变量和 const 成员函数)了。
定义常对象的语法和定义常量的语法类似:
const class object(params);
class const object(params);
当然你也可以定义 const 指针:
const class *p = new class(params);
class const *p = new class(params);
9.C++友元函数和友元类(C++ friend关键字)
友元函数
在 C++ 中,一个类中可以有 public、protected、private 三种属性的成员,通过对象可以访问 public 成员,只有本类中的函数可以访问本类的 private 成员。现在,我们来介绍一种例外情况——友元(friend)。借助友元(friend),可以使得其他类中的成员函数以及全局范围内的函数访问当前类的 private 成员。
在当前类以外定义的、不属于当前类的函数也可以在类中声明,但要在前面加 friend 关键字,这样就构成了友元函数。友元函数可以是不属于任何类的非成员函数,也可以是其他类的成员函数。
友元函数可以访问当前类中的所有成员,包括 public、protected、private 属性的。
1) 将非成员函数声明为友元函数
注意,友元函数不同于类的成员函数,在友元函数中不能直接访问类的成员,必须要借助对象。
#include
using namespace std;
class Student{
public:
Student(char *name, int age, float score);
public:
friend void show(Student *pstu); //将show()声明为友元函数
private:
char *m_name;
int m_age;
float m_score;
};
Student::Student(char *name, int age, float score): m_name(name), m_age(age), m_score(score){ }
//非成员函数
void show(Student *pstu){
cout<m_name<<"的年龄是 "<m_age<<",成绩是 "<m_score< 注意,友元函数不同于类的成员函数,在友元函数中不能直接访问类的成员,必须要借助对象。
下面的写法是错误的:
纯文本复制
void show(){
cout<2) 将其他类的成员函数声明为友元函数
friend 函数不仅可以是全局函数(非成员函数),还可以是另外一个类的成员函数。
注意,友元函数不同于类的成员函数,在友元函数中不能直接访问类的成员,必须要借助对象。请看下面的例子:
#include
using namespace std;
class Address; //提前声明Address类
//声明Student类
class Student{
public:
Student(char *name, int age, float score);
public:
void show(Address *addr);
private:
char *m_name;
int m_age;
float m_score;
};
//声明Address类
class Address{
private:
char *m_province; //省份
char *m_city; //城市
char *m_district; //区(市区)
public:
Address(char *province, char *city, char *district);
//将Student类中的成员函数show()声明为友元函数
friend void Student::show(Address *addr);
};
//实现Student类
Student::Student(char *name, int age, float score): m_name(name), m_age(age), m_score(score){ }
void Student::show(Address *addr){
cout<m_province<<"省"<m_city<<"市"<m_district<<"区"< show(paddr);
return 0;
} 几点注意:
① 程序第 4 行对 Address 类进行了提前声明,是因为在 Address 类定义之前、在 Student 类中使用到了它,如果不提前声明,编译器会报错,提示'Address' has not been declared。类的提前声明和函数的提前声明是一个道理。
② 程序将 Student 类的声明和实现分开了,而将 Address 类的声明放在了中间,这是因为编译器从上到下编译代码,show() 函数体中用到了 Address 的成员 province、city、district,如果提前不知道 Address 的具体声明内容,就不能确定 Address 是否拥有该成员(类的声明中指明了类有哪些成员)。
这里简单介绍一下类的提前声明。一般情况下,类必须在正式声明之后才能使用;但是某些情况下(如上例所示),只要做好提前声明,也可以先使用。
但是应当注意,类的提前声明的使用范围是有限的,只有在正式声明一个类以后才能用它去创建对象。如果在上面程序的第4行之后增加如下所示的一条语句,编译器就会报错:
Address addr; //企图使用不完整的类来创建对象
因为创建对象时要为对象分配内存,在正式声明类之前,编译器无法确定应该为对象分配多大的内存。编译器只有在“见到”类的正式声明后(其实是见到成员变量),才能确定应该为对象预留多大的内存。在对一个类作了提前声明后,可以用该类的名字去定义指向该类型对象的指针变量(本例就定义了 Address 类的指针变量)或引用变量(后续会介绍引用),因为指针变量和引用变量本身的大小是固定的,与它所指向的数据的大小无关。
③ 一个函数可以被多个类声明为友元函数,这样就可以访问多个类中的 private 成员。
友元类
不仅可以将一个函数声明为一个类的“朋友”,还可以将整个类声明为另一个类的“朋友”,这就是友元类。友元类中的所有成员函数都是另外一个类的友元函数。
例如将类 B 声明为类 A 的友元类,那么类 B 中的所有成员函数都是类 A 的友元函数,可以访问类 A 的所有成员,包括 public、protected、private 属性的。
更改上例的代码,将 Student 类声明为 Address 类的友元类:
#include
using namespace std;
class Address; //提前声明Address类
//声明Student类
class Student{
public:
Student(char *name, int age, float score);
public:
void show(Address *addr);
private:
char *m_name;
int m_age;
float m_score;
};
//声明Address类
class Address{
public:
Address(char *province, char *city, char *district);
public:
//将Student类声明为Address类的友元类
friend class Student;
private:
char *m_province; //省份
char *m_city; //城市
char *m_district; //区(市区)
};
//实现Student类
Student::Student(char *name, int age, float score): m_name(name), m_age(age), m_score(score){ }
void Student::show(Address *addr){
cout<m_province<<"省"<m_city<<"市"<m_district<<"区"< show(paddr);
return 0;
} 关于友元,有两点需要说明:
- 友元的关系是单向的而不是双向的。如果声明了类 B 是类 A 的友元类,不等于类 A 是类 B 的友元类,类 A 中的成员函数不能访问类 B 中的 private 成员。
- 友元的关系不能传递。如果类 B 是类 A 的友元类,类 C 是类 B 的友元类,不等于类 C 是类 A 的友元类。
除非有必要,一般不建议把整个类声明为友元类,而只将某些成员函数声明为友元函数,这样更安全一些。
10.类其实也是一种作用域
#include
using namespace std;
class A{
public:
typedef int INT;
static void show();
void work();
};
void A::show(){ cout<<"show()"< 对的:
void A::show(PCHAR str){
cout<
需要记住C++ class和struct到底有什么区别:
C++中的 struct 和 class 基本是通用的,唯有几个细节不同:
- 使用 class 时,类中的成员默认都是 private 属性的;而使用 struct 时,结构体中的成员默认都是 public 属性的。
- class 继承默认是 private 继承,而 struct 继承默认是 public 继承(《C++继承与派生》一章会讲解继承)。
- class 可以使用模板,而 struct 不能(《模板、字符串和异常》一章会讲解模板)。
在编写C++代码时,我强烈建议使用 class 来定义类,而使用 struct 来定义结构体,这样做语义更加明确。
但是下面看下C++的struct结构体变化:
#include
using namespace std;
struct Student{
Student(char *name, int age, float score);
void show();
char *m_name;
int m_age;
float m_score;
};
Student::Student(char *name, int age, float score): m_name(name), m_age(age), m_score(score){ }
void Student::show(){
cout< show();
return 0;
}