Center and Scale Prediction: A Box-free Approach for Object Detection
Center and Scale Prediction: A Box-free Approach for Object Detection
中心和尺度预测:一种 box-free 的物体检测方法
无锚框的物体检测方法
Wei Liu, Shengcai Liao, Irtiza Hasan
Computer Science,CS:计算机科学
Computer Vision,CV:计算机视觉
noname:n. 没有名字,无名
manuscript ['mænjʊskrɪpt]:n. 手稿,原稿 adj. 手写的
National University of Defense Technology,NUDT:中国人民解放军国防科技大学,国防科技大学
The United Arab Emirates,UAE:阿拉伯联合酋长国,阿拉伯联合大公国,阿联酋
Abu Dhabi:阿布扎比,阿拉伯联合酋长国首都,阿拉伯联合酋长国阿布扎比酋长国首府
Inception Institute of Artificial Intelligence,IIAI:起源人工智能研究院
electronic [ɪˌlekˈtrɒnɪk]:adj. 电子的 n. 电子电路,电子器件
automatic target recognition,ATR:自动目标识别
corresponding author:通讯作者
High-level Semantic Feature Detection: A New Perspective for Pedestrian Detection
An extension of the paper accepted by CVPR 2019, the title is changed to “Center and Scale Prediction: A Box-free Approach for Object Detection”.
arXiv (archive - the X represents the Greek letter chi [χ]) is a repository of electronic preprints approved for posting after moderation, but not full peer review.
Code and models will be available at GitHub: https://github.com/liuwei16/CSP
Abstract
Object detection generally requires sliding-window classifiers in tradition or anchor box based predictions in modern deep learning approaches. However, either of these approaches requires tedious configurations in boxes. In this paper, we provide a new perspective where detecting objects is motivated as a high-level semantic feature detection task. Like edges, corners, blobs and other feature detectors, the proposed detector scans for feature points all over the image, for which the convolution is naturally suited. However, unlike these traditional low-level features, the proposed detector goes for a higher-level abstraction, that is, we are looking for central points where there are objects, and modern deep models are already capable of such a highlevel semantic abstraction. Besides, like blob detection, we also predict the scales of the central points, which is also a straightforward convolution. Therefore, in this paper, object detection is simplified as a straightforward center and scale prediction task through convolutions. This way, the proposed method enjoys a box-free setting. Though structurally simple, it presents competitive accuracy on several challenging benchmarks, including pedestrian detection and face detection. Furthermore, a cross-dataset evaluation is performed, demonstrating a superior generalization ability of the proposed method.
物体检测通常需要传统的滑动窗口分类器或现代深度学习方法中基于锚框的预测。但是,这些方法中的任何一种都需要在 boxes 上进行繁琐的配置。在本文中,我们提供了一个新的视角,其中检测物体被明确为高级语义特征检测任务。类似边缘、角落、斑点和其他特征检测器,本文提出的检测器扫描整个图像上的特征点,卷积自然适合这类任务。然而,与这些传统的低级特征不同,所提出的检测器用于更高级别的抽象,即我们正在寻找存在物体的中心点,并且现代深度模型已经能够进行如此高级的语义抽象。此外,像斑点检测一样,我们也预测中心点的尺度,这也是一个简单的卷积。因此,在本文中,物体检测通过卷积简化为简单的中心和尺度预测任务。这样,所提出的方法具有 box-free 设置。虽然结构简单,但它在几个具有挑战性的基准数据集测试中提供了有竞争力的准确性,包括行人检测和面部检测。此外,进行交叉数据集评估,证明了所提出方法的优异的泛化能力。
tedious ['tiːdɪəs]:adj. 沉闷的,冗长乏味的
semantic [sɪ'mæntɪk]:adj. 语义的,语义学的 (等于 semantical)
superior [suːˈpɪərɪə]:adj. 上级的,优秀的,出众的,高傲的 n. 上级,长官,优胜者,高手,长者
blob [blɒb]:n. 一滴,一抹,难以名状的一团 vt. 弄脏,把...做错 vi. 得零分,弄错
目标检测通常采用传统的密集滑窗方式或者当前主流的铺设锚框 (anchor) 方式,不管哪种方式都不可避免地需要针对特定数据集设计甚至优化滑窗或者锚框超参数,增加了训练难度并限制了检测器的通用性。
本文把目标检测当作一个具有高阶语义的特征检测任务,为目标检测提供了一个新的视角。像边缘、角点、斑点或感兴趣区域等低层特征检测,本文方法也扫描全图寻找感兴趣特征点,卷积是自然胜任的。但跟传统的底层特征不一样的是,本文进一步寻找具有高阶语义的抽象特征点,如行人、面部等,而当今的深度卷积神经网络已经具备这种高阶语义的抽象能力。此外,类似斑点或感兴趣区域检测,本文同时为每个中心点预测出目标的尺度,这也是一个直接的卷积式预测。本文以行人检测为例将目标检测简化为一个直接的全卷积式的中心点和尺度预测任务,CSP (Center and Scale Prediction) 检测器结构简单。
一般认为深度学习提取的特征具有高级语义特性。传统的目标检测大多基于滑动窗体或者先验框方式,而无论哪个方法都需要繁杂的配置。CSP 放弃传统的窗体检测方式,通过卷积操作直接预测行人的中心位置和尺度大小。
Keywords
Object detection, Convolutional neural networks, Feature detection, Box-free, Anchor-free
1. Introduction
Feature detection1 is one of the most fundamental problems in computer vision. It is usually viewed as a low-level technique, with typical tasks including edge detection (e.g. Canny [4], Sobel [42]), corner (or interest point) detection (e.g. SUSAN [41], FAST [38]), and blob (or region of interest point) detection (e.g. LoG [25], DoG [31], MSER [33]). Feature detection is of vital importance to a variety of computer vision tasks ranging from image representation, image matching to 3D scene reconstruction, to name a few.
特征检测1是计算机视觉中最基本的问题之一。它通常被视为低级技术,典型任务包括边缘检测 (e.g. Canny [4], Sobel [42])、角点 (或兴趣点) 检测 (e.g. SUSAN [41], FAST [38]) 和斑点 (或感兴趣区域) 检测 (e.g. LoG [25], DoG [31], MSER [33])。特征检测对于各种计算机视觉任务至关重要,从图像表示、图像匹配到 3D 场景重建,仅举几个例子。
1https://en.wikipedia.org/wiki/Feature_detection_(computer_vision)
Generally speaking, a feature is defined as an “interesting” part of an image, and so feature detection aims to compute abstractions of image information and make local decisions at every image point whether there is an image feature of a given type at that point or not. Regarding abstraction of image information, with the rapid development for computer vision tasks, deep convolutional neural networks (CNN) are believed to be of very good capability to learn high-level image abstractions. Therefore, it has also been applied for feature detection, and demonstrates attractive successes even in low-level feature detections. For example, there is a recent trend of using CNN to perform edge detection [40, 50, 2, 29], which has substantially advanced this field. It shows that clean and continuous edges can be obtained by deep convolutions, which indicates that CNN has a stronger capability to learn higher-level abstraction of natural images than traditional methods. This capability may not be limited to low-level feature detection; it may open up many other possibilities of high-level feature detection.
一般来说,特征被定义为图像的“有趣”部分,因此特征检测旨在计算图像信息的抽象,并在每个图像点做出本地决策,无论在该点是否存在给定类型的图像特征。关于图像信息的抽象,随着计算机视觉任务的快速发展,深度卷积神经网络 (CNN) 被认为具有非常好的学习高级图像抽象的能力。因此,它也已经应用于特征检测,并且即使在低级特征检测中也展示了有吸引力的成功。例如最近有使用 CNN 进行边缘检测的趋势 [40, 50, 2, 29],这已经大大推进了这一领域。它表明,通过深度卷积可以获得干净和连续的边缘,这表明 CNN 比传统方法具有更强的学习更高层次的自然图像抽象的能力。此功能可能不限于低级特征检测,它可能会开辟许多其他高级特征检测的可能性。
vital ['vaɪt(ə)l]:adj. 至关重要的,生死攸关的,有活力的
substantially [səb'stænʃ(ə)lɪ]:adv. 实质上,大体上,充分地
在传统的计算机视觉领域,特征点检测是一个非常基础且重要的任务。通常,它被当成是一种低级视觉技术,包括边缘检测、角点 (或关键点) 检测和感兴趣区域检测等。一般而言,一个特征点通常是图像的一个感兴趣部分,特征点检测是指抽取图像信息并给出每个像素点上是否存在给定的一种特征的决策。而对于图像信息的抽取,当今的深度卷积神经网络 (CNN) 被认为具有对图像的高度抽象能力,因此 CNN 也被广泛应用于特征点检测,并取得了非常有吸引力的结果。近些年基于 CNN 的边缘检测方法取得了很大的进展,它们揭示了 CNN 可以获得非常连续且光滑的边缘,也说明 CNN 比传统方法具有更强的抽象能力。这种高度的抽象能力不应被局限于低级视觉特征点的检测,它应该具有很大的潜力能够检测更高层的抽象的语义特征点。
Therefore, in this paper, we provide a new perspective where detecting objects is motivated as a high-level semantic feature detection task. Like edges, corners, blobs and other feature detectors, the proposed detector scans for feature points all over the image, for which the convolution is naturally suited. However, unlike these traditional low-level feature detectors, the proposed detector goes for a higher-level abstraction, that is, we are looking for central points where there are objects. Besides, similar to the blob detection, we also predict the scales of the central points. However, instead of processing an image pyramid to determine the scale as in traditional blob detection, we predict object scale with also a straightforward convolution in one pass upon a fully convolution network (FCN) [30], considering its strong capability. As a result, object detection is simply formulated as a straightforward center and scale prediction task via convolution. The overall pipeline of the proposed method, denoted as Center and Scale Prediction (CSP) based detector, is illustrated in Fig. 1.
因此,在本文中,我们提供了一个新的视角,其中检测目标被明确为高级语义特征检测任务。像边缘、角落、斑点和其他特征检测器一样,所提出的检测器扫描整个图像上的特征点,卷积自然适合这类任务。然而,与这些传统的低级特征检测器不同,所提出的检测器用于更高级别的抽象,即我们正在寻找存在物体的中心点。此外,类似于斑点检测,我们还预测中心点的尺度。然而,考虑到其强大的能力,我们不是像传统的斑点检测那样处理图像金字塔以确定尺度,而是在全卷积网络 (FCN) [30] 的一次通过中预测物体尺度和直接卷积。结果,通过卷积将物体检测简单地表述为直接的中心和尺度预测任务。所提出的方法的总体流水线,表示为基于中心和尺度预测 (CSP) 的检测器,在图 1 中示出。
straightforward [streɪt'fɔːwəd]:adj. 简单的,坦率的,明确的,径直的 adv. 直截了当地,坦率地
dot [dɒt]:n. 点,圆点,嫁妆 vi. 打上点 vt. 加小点于
关键点检测器通过扫描整张图像以发现存在关键点的位置,显然这种操作正是共享卷积运算所擅长的。但和传统的低层关键点检测不同的是,目标检测需要更加高层的抽象,也即需要寻找到每个目标的中心点,这是深度模型具备的。此外,和传统的感兴趣区域检测类似的是,目标检测还需要为每个中心点预测一个尺度,这也是卷积预测可以胜任的。基于以上两点考虑,本文提出在全卷积网络的基础上,将目标检测构建为一个目标中心点检测和目标尺度预测的任务。首先将一张图像输入全卷积网络,基于网络提取的特征图预测两个映射图,一个以热图的方式呈现目标的中心点位置,一个负责预测目标的尺度。在此基础上,便可以将两者映射到原图上并解译成目标检测框:中心点热图的位置对应检测框的中心位置,预测的尺度大小对应检测框的大小,而中心点热图上的置信度则对应检测框的得分。
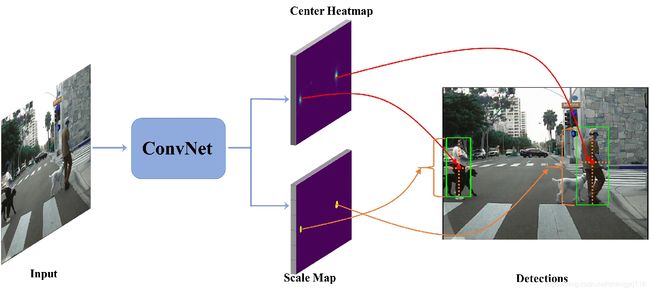
Fig. 1 The overall pipeline of the proposed CSP detector. The final convolutions have two channels, one is a heatmap indicating the locations of the centers (red dots), and the other serves to predict the scales (yellow dotted lines) for each detected center.
As for general object detection, starting from the pioneer work of the Viola-Jones detector [47], it generally requires sliding-window classifiers in tradition or anchor box based predictions in CNN-based methods. These detectors are essentially local classifiers used to judge the pre-defined boxes (windows or anchor boxes) as being objects or not. However, either of these approaches requires tedious configurations in boxes. Generally speaking, object detection is to tell where the object is, and how big it is. Traditional methods combines the “where” and “how” subproblems into a single one through the overall judgement of various scales of boxes. In contrast, the proposed CSP detector separates the “where” and “how” subproblems into two different convolutions. This makes detection a more natural way, and enjoys a box-free (short for window-free or anchor-box-free) setting, significantly reducing the difficulty in training.
至于一般物体检测,从 Viola-Jones 检测器 [47] 的先驱工作开始,它通常需要传统的滑动窗口分类器或基于 CNN 的方法中基于锚框的预测。这些检测器本质上是局部分类器,用于判断预定义的盒子 (窗户或锚框) 是否为物体。但是,这些方法中的任何一种都需要在 boxes 上进行繁琐的配置。一般来说,物体检测是指物体的位置和物体的大小。传统方法通过各种尺度的盒子的整体判断将 where 和 how 子问题组合成单个子问题。相比之下,所提出的 CSP 检测器将 where 和 how 子问题分成两个不同的卷积。这使得检测成为一种更自然的方式,并且享受 box-free (无窗口或无锚框) 的设置,显著减少了训练中的困难。
pioneer [paɪə'nɪə]:n. 先锋,拓荒者 vt. 开辟,倡导,提倡 vi. 作先驱
对目标检测而言,从开创性的 Viola-Jones 检测器开始,均采用的是密集滑动窗口分类器的形式。即使是当前基于卷积神经网络的主流检测器,不管是两阶段的 Faster R-CNN 系列,还是单阶段的 SSD 系列,其采用铺设锚点框的检测方法,本质上仍然是子窗口分类器的形式。这些检测器本质上都是在训练一个局部分类器用于判断预设的子窗口或锚框内是否存在目标。然而这些方法都不可避免地需要针对特定数据集设计甚至优化滑窗或锚框超参数,从而增加了训练难度并限制检测器的通用性。这些滑窗或锚框超参数包括:窗口数目、窗口大小、长宽比例、与标注框的重叠率阈值等。这些超参数通常是检测任务和数据集相关的,难以调优也难以通用。一般而言,目标检测涉及两个方面:目标在哪里 (where),以及目标有多大 (how)。这些已有方法把这两方面绑定在一个窗口或锚框里,并通过局部分类器一次性判断各种不同大小、不同比例的窗口或锚框是否是目标。这种绑定就造成了超参数的各种组合问题。而本文提出的 CSP 检测器通过两个直接的卷积解离了这两个子问题,以更自然的方式实现目标检测,从而规避了锚框超参数的各种组合配置,简化了检测器的训练。
There is another line of research which inspires us a lot. Previously, FCN has already been applied to and made a success in multi-person pose estimation [5, 35], where several keypoints are firstly detected merely through responses of full convolutions, and then they are further grouped into complete poses of individual persons. In view of this, recently two inspirational works, CornerNet [18] and TLL [43], successfully go free from windows and anchor boxes, which perform object detection as convolutional keypoint detections and their associations. Though the keypoint association require additional computations, sometimes complex as in TLL, the keypoint prediction by FCN inspires us to go a step further, achieving center and scale prediction based object detection in full convolutions.
还有另一种研究方法激励了我们。以前 FCN 已经应用于多人姿态估计并在其中取得了成功 [5, 35],其中几个关键点仅通过全卷积的响应首先被检测到,然后它们被进一步分组为个人的完整姿势。鉴于此,最近两个鼓舞人心的作品,CornerNet [18] 和 TLL [43] 成功地从窗口和锚框中解脱出来,它们将目标检测作为卷积关键点检测及其关联来执行。虽然关键点关联需要额外的计算,有时像 TLL 一样复杂,FCN 的关键点预测激励我们更进一步,实现基于全卷积的中心和尺度预测的物体检测。
inspire [ɪn'spaɪə]:vt. 激发,鼓舞,启示,产生,使生灵感
inspirational [ɪnspɪ'reɪʃ(ə)n(ə)l]:adj. 鼓舞人心的,带有灵感的,给予灵感的
受启发于传统的特征点检测任务和最近的全卷积关键点检测和配对的工作,本文提出了一种无需密集滑窗或锚框的全卷积预测目标中心点和尺度大小的行人检测方法,为目标检测提供了一个新的视角。
本文工作也受启发于近些年的一些关键点检测和配对的工作。在已有工作中,全卷积神经网络 (FCN) 已被成功地应用于多人姿态估计,首先全卷积检测人体关键点,然后进行组合配对的方式。CornerNet 和 TLL 通过一对对角点检测或上下顶点检测并两两配对的方式,成功地抛弃了锚框,实现目标检测 (第一代 YOLO 不使用锚框)。虽然多个关键点需要额外的配对策略,有些配对方法较为复杂,这一系列工作启发了本文实现简单的全卷积预测中心和尺度的检测器。
In summary, the main contributions of this work are as follows: (i) We show a new possibility that object detection can be simplified as a straightforward center and scale prediction task through convolutions, which bypasses the limitations of anchor box based detectors and gets rid of the complex post-processing of recent keypoint pairing based detectors. (ii) The proposed CSP detector achieves the new state-of-the-art performance on two challenging pedestrian detection benchmarks, CityPersons [55] and Caltech [8], it also achieves competitive performance on one of the most popular face detection benchmark-WiderFace [51]. (iii) The proposed CSP detector presents good generalization ability when cross-dataset evaluation is performed.
总之,这项工作的主要贡献如下:(i) 我们展示了一种新的可能性,即物体检测可以通过卷积简化为简单的中心和尺度预测任务,绕过基于锚框的检测器的限制并摆脱最近基于关键点配对的检测器的复杂后处理。(ii) 提出的 CSP 检测器在两个具有挑战性的行人检测基准数据集上 (CityPersons [55] and Caltech [8]) 实现了新的最佳性能。它也在最流行的面部检测基准数据集之一 WiderFace [51] 上实现了竞争性的表现。(iii) 当进行交叉数据集评估时,所提出的 CSP 检测器具有良好的泛化能力。
bypass ['baɪpɑːs]:n. 旁路,支路,旁通管,分流术 v. 绕过,避开,忽视,不顾,设旁路,迂回
This work is built upon our preliminary work recently accepted by the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2019. The major new content is additional experiments on face detection to demonstrate CSP’s capability in detecting objects with various aspect ratios. Besides, we also conduct comparative experiments and analysis to demonstrate the generalization ability of the proposed detector. In summary, main changes contained in this paper are as follows:
这项工作建立在最近由 IEEE 计算机视觉和模式识别会议 (CVPR) 2019 接受的初步工作的基础上。主要的新内容是面部检测的额外实验,以证明 CSP 能够检测具有各种宽高比的物体。此外,我们还进行了对比实验和分析,以证明所提出的检测器的泛化能力。总之,本文所包含的主要变化如下:
preliminary [prɪ'lɪmɪn(ə)rɪ]:adj. 初步的,开始的,预备的 n. 初步行动,准备工作,预赛,预试
additional [ə'dɪʃ(ə)n(ə)l]:adj. 附加的,额外的
-
We evaluate the proposed method for face detection on one of the most popular face detection benchmarks, i.e. WiderFace [51]. The model is trained on the official training subset and evaluated on both the validation and test subsets. Comparable performance to other state-of-the-art face detectors on this benchmark are reported and thus demonstrates the proposed method’s capability and competitiveness on face detection.
-
我们在最流行的面部检测基准数据集之一,即 WiderFace [51] 上评估了所提出的面部检测方法。该模型在官方训练子集上进行训练,并在验证子集和测试子集上进行评估。在基准数据集测试中显示了与其他最先进的面部检测器相当的性能,从而证明了所提出的方法在面部检测方面的能力和竞争力。
-
To further evaluate the generalization ability of the proposed CSP detector, we also conduct two cross-dataset evaluation experiments. For pedestrian detection, we compare the proposed CSP detector with the state-of-the-art anchor box based pedestrian detector (ALFNet [28]). Both of the two detectors are trained on the CityPersons [55] training set and then are directly tested on Caltech [8]. For face detection, we compare the proposed CSP detector with the state-of-the-art anchor box based face detector (DSFD [19]). Both of the two detectors are trained on the WiderFace [51] training set and then are directly tested on FDDB [14], UCCS [1] and DarkFace [49]. Experimental results show that the proposed CSP detector has a superior generalization ability than the compared methods.
-
为了进一步评估所提出的 CSP 检测器的泛化能力,我们还进行了两个跨数据集评估实验。对于行人检测,我们将提出的 CSP 检测器与最先进的基于锚框的行人检测器 (ALFNet [28]) 进行比较。两个检测器都在 CityPersons [55] 训练集上训练,然后在 Caltech [8] 上直接测试。对于面部检测,我们将提出的 CSP 检测器与最先进的基于锚点的面部检测器 (DSFD [19]) 进行比较。两个检测器都在 WiderFace [51] 训练集上训练,然后直接在 FDDB [14], UCCS [1] and DarkFace [49] 上测试。实验结果表明,所提出的 CSP 检测器具有比比较方法更强的泛化能力。
competitiveness [kəm'petətɪvnɪs]:n. 竞争力,好竞争
2 Related Works
2.1 Anchor box based object detection
One key component of anchor box based detectors is the anchor boxes of pre-defined scales and aspect ratios. In this way, detection is performed by classifying and regressing these anchor boxes. Faster R-CNN [37] is known as a two-stage detector, which generates objectness proposals and further classifies and refines these proposals in a single framework. In contrast, singe-stage detectors, popularized by SSD [27], remove the proposal generation step and achieve comparable accuracy while are more efficient than two-stage detectors.
基于锚框的检测器的一个关键组件是预定义尺度和宽高比的锚框。以这种方式,通过对这些锚框进行分类和回归来执行检测。Faster R-CNN [37] 被称为两阶段检测器,它生成候选区域和进一步的分类,并在单一框架中重新定义这些候选区域。相比之下,由 SSD [27] 推广的单级检测器取消了候选区域生成步骤并实现了相当的精度,同时比两级检测器更高效。
popularize ['pɑpjələraɪz]:vt. 普及,使通俗化 vi. 通俗化
region proposal:候选区域
In terms of pedestrian detection, Faster R-CNN has become the predominant framework. For example, RPN+BF [52] adapts the RPN and re-scores these proposals via boosted forests. MS-CNN [3] also applies the Faster R-CNN framework but generates proposals on multi-scale feature maps. Zhang et al. [55] contribute five strategies to adapt the plain Faster R-CNN for pedestrian detection. RepLoss [48] and OR-CNN [56] design two novel regression losses to tackle the occluded pedestrian detection in crowded scenes. Bi-Box [59] proposes an auxiliary sub-network to predict the visible part of a pedestrian instance. Most recently, single-stage detectors also present competitive performance. For example, ALFNet [28] proposes the asymptotic localization fitting strategy to evolve the default anchor boxes step by step into precise detection results, and [21] focuses on the discriminative feature learning based on the original SSD architecture.
在行人检测方面,Faster R-CNN 已成为主流框架。例如 RPN+BF [52] 调整 RPN 并通过 boosted forests 重新评分这些候选区域。MS-CNN [3] 也应用了 Faster R-CNN 框架,但在多尺度特征图上生成了候选区域。Zhang et al. [55] 提供五种策略来适应普通的 Faster R-CNN 进行行人检测。RepLoss [48] and OR-CNN [56] 设计了两个新的回归损失,以解决拥挤场景中被遮挡的行人检测问题。Bi-Box [59] 提出了一个辅助子网络来预测行人实例的可见部分。最近,单级检测器也具有竞争性能。例如 ALFNet [28] 提出了渐近定位配置策略,逐步将默认锚框演化为精确的检测结果,[21] 侧重于基于原始 SSD 架构的判别特征学习。
predominant [prɪ'dɒmɪnənt]:adj. 主要的,卓越的,支配的,有力的,有影响的
tackle ['tæk(ə)l]:n. 滑车,装备,用具,扭倒 vt. 处理,抓住,固定,与...交涉 vi. 扭倒,拦截抢球
auxiliary [ɔːɡˈzɪljərɪ]:adj. 辅助的,副的,附加的,备用的 n. 助动词,辅助者,辅助物,附属机构,志愿队,辅助舰队
asymptotic [,æsɪmp'tɒtɪk]:adj. 渐近的,渐近线的
discriminative [dɪs'krɪmɪnətɪv]:adj. 区别的,歧视的,有识别力的
boost [buːst]:vt. 促进,增加,支援 vi. 宣扬,偷窃 n. 推动,帮助,宣扬
forest ['fɒrɪst]:n. 森林,林区,一丛,皇家林地,御猎场 v. 植林于,被森林覆盖
For face detection, it is dominated by the single-stage framework in recent years. Most of the advanced face detectors focus on the anchor box design and matching strategies, because faces in the wild exhibits a large variation in size. For example, FaceBoxes [57] introduces an anchor box densification strategy to ensure anchor boxes of different sizes have the same density on an image, and in [58, 60], the authors propose different anchor box matching threshold to ensure a certain number of training examples for tiny faces, further DSFD [19] proposes an improved anchor box matching strategy to provide better initialization for the regressor. In SSH [34], anchor boxes with two neighboring sizes share the same detection feature map. PyramidBox [44] designs novel PyramidAnchors to help contextual feature learning.
对于面部检测,近年来它由单级框架主导。大多数先进的面部检测器都专注于锚框设计和匹配策略,因为野外的面部大小变化很大。例如 FaceBoxes [57] 引入了一个锚框密度策略,以确保不同大小的锚框在图像上具有相同的密度,并且在 [58, 60] 中,作者提出不同的锚框匹配阈值以确保一定的数量对于微小面孔的训练样例,DSFD [19] 提出了一种改进的锚框匹配策略,以便为回归器提供更好的初始化。在 SSH [34] 中,具有两个相邻大小的锚框共享相同的检测特征图。PyramidBox [44] 设计新颖的 PyramidAnchors 来帮助上下文特征学习。
dominate ['dɒmɪneɪt]:vt. 控制,支配,占优势,在...中占主要地位 vi. 占优势,处于支配地位
wild [waɪld]:adj. 野生的,野蛮的,狂热的,荒凉的 n. 荒野 adv. 疯狂地,胡乱地
densification [,densifi'keiʃən]:n. 密实化,封严,稠化
pyramid ['pɪrəmɪd]:n. 金字塔,角锥体 vi. 渐增,上涨,成金字塔状 vt. 使...渐增,使...上涨,使...成金字塔状
2.2 Box-free object detection
Box-free detectors bypass the requirement of anchor boxes and detect objects directly from an image. DeNet [46] proposes to generate proposals by predict the confidence of each location belonging to four corners of objects. Following the two-stage pipeline, DeNet also appends another sub-network to re-score these proposals. Within the single-stage framework, YOLO [36] appends fully-connected layers to parse the final feature maps of a network into class confidence scores and box coordinates. Densebox [13] devises a unified FCN that directly regresses the classification scores and distances to the boundary of a ground truth box on all pixels, and demonstrates improved performance with landmark localization via multi-task learning. However, DenseBox resizes objects to a single scale during training, thus requiring image pyramids to detect objects of various sizes by multiple network passes during inference. Besides, Densebox defines the central area for each object and thus requires four parameters to measure the distances of each pixel in the central area to the object’s boundaries. In contrast, the proposed CSP detector defines a single central point for each object, therefore two parameters measuring the object’s scale are enough to get a bounding box, and sometimes one scale parameter is enough given uniform aspect ratio in the task of pedestrian detection. Most recently, CornerNet [18] also applies a FCN but to predict objects’ top-left and bottom-right corners and then group them via associative embedding [35]. Enhanced by the novel corner pooling layer, CornerNet achieves superior performance on MS COCO object detection benchmark [22]. Similarly, TLL [43] proposes to detect an object by predicting the top and bottom vertexes. To group these paired keypoints into individual instances, it also predicts the link edge between them and employs a post-processing scheme based on Markov Random Field. Applying on pedestrian detection, TLL achieves significant improvement on Caltech [8], especially for small-scale pedestrians.
无 box 检测器绕过锚框的要求并直接从图像中检测物体。DeNet [46] 提出通过预测属于物体四个角的每个位置的置信度来生成候选区域。在两阶段管道之后,DeNet 还附加了另一个子网络来重新评分这些候选区域。在单阶段框架内,YOLO [36] 附加全连接层,以将网络的最终特征图解析为类别置信度得分和框坐标。Densebox [13] 设计了一个统一的 FCN,它直接回归分类得分和所有像素到 ground truth box 边界的距离,并通过多任务学习展示了具有里程碑式定位的改进性能。但是 DenseBox 在训练期间将物体缩放为单一尺度,因此需要图像金字塔在推理期间通过多个网络传递来检测各种大小的物体。此外 Densebox 定义了每个物体的中心区域,因此需要四个参数来测量中心区域中每个像素到物体边界的距离。相比之下,所提出的 CSP 检测器为每个物体定义了一个中心点,因此测量物体尺度的两个参数足以得到一个边界框,在统一宽高比的行人检测任务中有时一个尺度参数是足够的。最近 CornerNet [18] 也应用 FCN 但预测物体的左上角和右下角,然后通过关联嵌入对它们进行分组 [35]。通过新颖的 corner pooling layer,CornerNet 在 MS COCO 物体检测基准数据集上实现了卓越的性能 [22]。类似地,TLL [43] 提议通过预测顶部和底部顶点来检测物体。为了将这些成对的关键点分组为单个实例,它还预测它们之间的链接边缘,并采用基于马尔可夫随机场的后处理方案。应用于行人检测,TLL 在 Caltech [8] 上取得了显着的进步,特别是对于小尺度的行人。
Our work also falls in the box-free object detection, but with significant differences to all above methods. We try to answer to what extent a single FCN can be simplified for object detection, and demonstrate that a single center point is feasible for object localization. Along with the scale prediction, CSP is able to generate bounding boxes in a single pass of FCN without any requirements of extra postprocessing schemes except the Non-Maximum Suppression (NMS).
我们的工作也属于 box-free 物体检测,但与上述所有方法有显著差异。我们试图回答单个 FCN 在多大程度上可以简化物体检测,并证明单个中心点对于物体定位是可行的。除了尺度预测之外,CSP 还能够在 FCN 的单次传递中生成边界框,而不需要额外的后处理方案,除了非极大值抑制 (NMS)。
feasible ['fiːzɪb(ə)l]:adj. 可行的,可能的,可实行的
devise [dɪ'vaɪz]:vt. 设计,想出,发明,图谋,遗赠给 n. 遗赠
associative [ə'səʊʃɪətɪv; -sɪ-]:adj. 联想的,联合的,组合的
vertex ['vɜːteks]:n. 顶点,头顶,天顶
landmark ['læn(d)mɑːk]:n. 陆标,地标,界标,里程碑,纪念碑,地界标,划时代的事 adj. 有重大意义或影响的
2.3 Feature detection
Feature detection is a long-standing problem in computer vision with extensive literatures. Generally speaking, it mainly includes edge detection [4, 42], corner detection [38, 39], blob detection [33, 6] and so on. Traditional leading methods [4, 42] mainly focus on the utilization of local cues, such as brightness, colors, gradients and textures. With the development of CNN, a series of CNN-based method are proposed that significantly push forward the state of the arts in the task of feature detection. For example, there is a recent trend of using CNN to perform edge detection [40, 50, 2, 29], which have substantially advanced this field. However, different from these low-level feature points like edge, corners and blobs, the proposed method goes for a higher-level abstraction task, that is, we focus on detecting central points where there are pedestrians, for which modern deep models are already capable of.
特征检测是计算机视觉中长期存在的问题,具有广泛的文献。一般来说,它主要包括边缘检测 [4, 42]、角点检测 [38, 39]、斑点检测 [33, 6] 等。传统的主导方法 [4, 42] 主要关注局部线索的使用,例如亮度、颜色、渐变和纹理。随着 CNN 的发展,提出了一系列基于 CNN 的方法,在特征检测任务中显著推进了现有技术的发展。例如,最近有使用 CNN 进行边缘检测的趋势 [40, 50, 2, 29],这些已经大大推进了这一领域。然而与边缘、角落和斑点等低级特征点不同,所提出的方法用于更高级别的抽象任务,即我们专注于检测有行人的中心点,现代深层模型已经具备这样的能力。
3 Proposed Method
3.1 Preliminary
preliminary [prɪ'lɪmɪn(ə)rɪ]:adj. 初步的,开始的,预备的 n. 初步行动,准备工作,预赛,预试
aspect ratio [ˈæspekt reɪʃiəʊ]:纵横比,屏幕高宽比,宽高比
anchor box:锚框
feature map:特征图,特征映射
The CNN-based object detectors often rely on a backbone network (e.g. ResNet [11]). Taking an image I I I as input, the network may generate several feature maps with different resolutions, which can be defined as follows:
ϕ i = f i ( ϕ i − 1 ) = f i ( f i − 1 ( . . . f 2 ( f 1 ( I ) ) ) ) , (1) \phi_{i} = f_{i}(\phi_{i−1}) = f_{i}(f_{i-1}(...f_{2}(f_{1}(I)))), \tag{1} ϕi=fi(ϕi−1)=fi(fi−1(...f2(f1(I)))),(1)
where ϕ i \phi_{i} ϕi represents feature maps output by the i i ith layer. These feature maps decrease in size progressively and are generated by f i ( . ) f_{i}(.) fi(.), which may be a combination of convolution or pooling, etc. Given a network with N N N layers, all the generated feature maps can be denoted as Φ = { ϕ 1 , ϕ 2 , . . . , ϕ N } \Phi = \{\phi_{1}, \phi_{2}, ..., \phi_{N}\} Φ={ϕ1,ϕ2,...,ϕN}, which is further utilized by detection heads.
基于 CNN 的物体检测器通常依赖于骨干网络 (e.g. ResNet [11])。将图像 I I I 作为输入,网络可以生成具有不同分辨率的若干特征图,其可以如下定义:
ϕ i = f i ( ϕ i − 1 ) = f i ( f i − 1 ( . . . f 2 ( f 1 ( I ) ) ) ) , (1) \phi_{i} = f_{i}(\phi_{i−1}) = f_{i}(f_{i-1}(...f_{2}(f_{1}(I)))), \tag{1} ϕi=fi(ϕi−1)=fi(fi−1(...f2(f1(I)))),(1)
其中 ϕ i \phi_{i} ϕi 表示第 i i i 层输出的特征图。这些特征图的尺寸逐渐减小,并由 f i ( . ) f_{i}(.) fi(.) 生成,它可能是卷积或池化等的组合。给定具有 N N N 层的网络,所有生成的特征图可以表示为 Φ = { ϕ 1 , ϕ 2 , . . . , ϕ N } \Phi = \{\phi_{1}, \phi_{2}, ..., \phi_{N}\} Φ={ϕ1,ϕ2,...,ϕN},其被检测头进一步使用。
Generally speaking, the CNN-based object detectors differ in how to utilize Φ \Phi Φ. We denote these feature maps that are responsible for detection as Φ d e t \Phi_{det} Φdet. In RPN [37], only the final feature map ϕ N \phi_{N} ϕN is used to perform detection, thus the final set of feature maps for detection is Φ d e t = { ϕ N } \Phi_{det} = \{\phi_{N}\} Φdet={ϕN}. While in SSD [27], the detection feature maps can be represented as Φ d e t = { ϕ L , ϕ L + 1 , . . . , ϕ N } \Phi_{det} = \{\phi_{L}, \phi_{L+1}, ..., \phi_{N}\} Φdet={ϕL,ϕL+1,...,ϕN}, where 1 < L < N 1 < L < N 1<L<N. Further, in order to enrich the semantic information of shallower layers for detecting small-scale objects, FPN [23] and DSSD [9] utilize the lateral connection to combine feature maps of different resolutions, resulting in Φ d e t = { ϕ L ′ , ϕ L + 1 ′ , . . . , ϕ N ′ } \Phi_{det} = \{\phi_{L}^{'}, \phi_{L+1}^{'}, ..., \phi_{N}^{'}\} Φdet={ϕL′,ϕL+1′,...,ϕN′}, where ϕ i ′ ( i = L , L + 1 , . . . , N ) \phi_{i}^{'}(i = L, L + 1, ..., N) ϕi′(i=L,L+1,...,N) is a combination of ϕ i ( i = L , L + 1 , . . . , N ) \phi_{i}(i = L, L + 1, ..., N) ϕi(i=L,L+1,...,N).
一般而言,基于 CNN 的物体检测器在如何利用 Φ \Phi Φ 方面不同。我们将这些负责检测的特征图表示为 Φ d e t \Phi_{det} Φdet。在 RPN [37] 中,只有最终的特征图用于执行检测,因此用于检测的最终特征图集是 Φ d e t = { ϕ N } \Phi_{det} = \{\phi_{N}\} Φdet={ϕN}。在 SSD [27] 中,检测特征图可以表示为 Φ d e t = { ϕ L , ϕ L + 1 , . . . , ϕ N } \Phi_{det} = \{\phi_{L}, \phi_{L+1}, ..., \phi_{N}\} Φdet={ϕL,ϕL+1,...,ϕN},其中 1 < L < N 1 < L < N 1<L<N。此外,为了丰富用于检测小尺度物体的较浅层的语义信息,FPN [23] and DSSD [9] 利用横向连接来组合不同分辨率的特征图,从而产生 Φ d e t = { ϕ L ′ , ϕ L + 1 ′ , . . . , ϕ N ′ } \Phi_{det} = \{\phi_{L}^{'}, \phi_{L+1}^{'}, ..., \phi_{N}^{'}\} Φdet={ϕL′,ϕL+1′,...,ϕN′},其中 ϕ i ′ ( i = L , L + 1 , . . . , N ) \phi_{i}^{'}(i = L, L + 1, ..., N) ϕi′(i=L,L+1,...,N) 是 ϕ i ( i = L , L + 1 , . . . , N ) \phi_{i}(i = L, L + 1, ..., N) ϕi(i=L,L+1,...,N) 组合。
lateral ['læt(ə)r(ə)l]:adj. 侧面的,横向的 n. 侧部,边音 vt. 横向传球
Besides Φ d e t \Phi_{det} Φdet, in anchor box based detectors, another key component is called anchor boxes (denoted as B \mathcal{B} B). Given Φ d e t \Phi_{det} Φdet and B \mathcal{B} B in hand, detection can be formulated as:
D e t s = H ( Φ d e t , B ) = { c l s ( Φ d e t , B ) , r e g r ( Φ d e t , B ) } , (2) Dets = \mathcal{H(\Phi_{det}, \mathcal{B})} = \{cls(\Phi_{det}, \mathcal{B}), regr(\Phi_{det}, \mathcal{B})\}, \tag{2} Dets=H(Φdet,B)={cls(Φdet,B),regr(Φdet,B)},(2)
where B \mathcal{B} B is pre-defined according to the corresponding set of feature maps Φ d e t \Phi_{det} Φdet, and H ( . ) \mathcal{H(.)} H(.) represents the detection head. Generally, H ( . ) \mathcal{H(.)} H(.) contains two elements, namely c l s ( . ) cls(.) cls(.) which predicts the classification scores, and r e g r ( . ) regr(.) regr(.) which predicts the scaling and offsets of the anchor boxes.
除了 Φ d e t \Phi_{det} Φdet 之外,在基于锚框的检测器中,另一个关键组件称为锚框 (表示为 B \mathcal{B} B)。给定 Φ d e t \Phi_{det} Φdet and B \mathcal{B} B,检测可以表示为:
D e t s = H ( Φ d e t , B ) = { c l s ( Φ d e t , B ) , r e g r ( Φ d e t , B ) } , (2) Dets = \mathcal{H(\Phi_{det}, \mathcal{B})} = \{cls(\Phi_{det}, \mathcal{B}), regr(\Phi_{det}, \mathcal{B})\}, \tag{2} Dets=H(Φdet,B)={cls(Φdet,B),regr(Φdet,B)},(2)
其中 B \mathcal{B} B 是根据相应的特征图集 Φ d e t \Phi_{det} Φdet 预定义的,而 H ( . ) \mathcal{H(.)} H(.) 代表检测头。通常 H ( . ) \mathcal{H(.)} H(.) 包含两个元素,即预测分类分数的 c l s ( . ) cls(.) cls(.),以及预测锚框缩放和偏移的 r e g r ( . ) regr(.) regr(.)。
While in box-free detectors, detection is performed merely on the set of feature maps Φ d e t \Phi_{det} Φdet, that is,
D e t s = H ( Φ d e t ) (3) Dets = \mathcal{H(\Phi_{det})} \tag{3} Dets=H(Φdet)(3)
在 box-free 检测器中,仅在特征图集 Φ d e t \Phi_{det} Φdet 上执行检测,即
D e t s = H ( Φ d e t ) (3) Dets = \mathcal{H(\Phi_{det})} \tag{3} Dets=H(Φdet)(3)
3.2 Overall architecture
The overall architecture of the proposed CSP detector is illustrated in Fig. 2. The backbone network are truncated from a standard network pretrained on ImageNet [7] (e.g. ResNet-50 [11] and MobileNet [12]).
本文提出的 CSP 检测器的整体框架如图 2 所示。骨干网络是从 ImageNet [7] 上预训练的标准网络中截断的 (e.g. ResNet-50 [11] and MobileNet [12])。
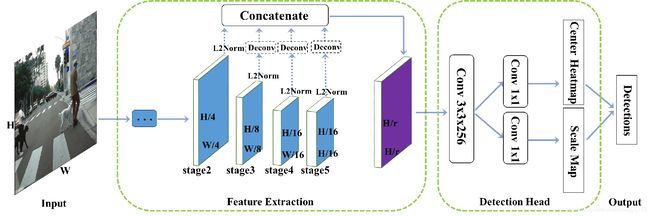
Fig. 2 Overall architecture of CSP, which mainly comprises two components, i.e. the feature extraction module and the detection head. The feature extraction module concatenates feature maps of different resolutions into a single one. The detection head merely contains a 3x3 convolutional layer, followed by two prediction layers, one for the center location and the other for the corresponding scale.
图 2 CSP 的整体框架,主要包含两个模块:特征提取模块和检测头模块。特征提取模块将不同分辨率的特征图连接成一个特征图。检测头仅包含 3x3 卷积层,后面是两个预测层,一个用于中心位置,另一个用于相应的尺寸。
Feature Extraction. Taking ResNet-50 as an example, its Conv layers can be divided into five stages, in which the output feature maps are downsampled by 2, 4, 8, 16, 32 w.r.t. the input image. As a common practice [48,43], the dilated convolutions are adopted in stage 5 to keep its output as 1/16 of the input image size. We denote the output of stage 2, 3, 4 and 5 as ϕ 2 \phi_{2} ϕ2, ϕ 3 \phi_{3} ϕ3, ϕ 4 \phi_{4} ϕ4 and ϕ 5 \phi_{5} ϕ5, in which the shallower feature maps can provide more precise localization information, while the coarser ones contain more semantic information with increasing the sizes of receptive fields. Therefore, we fuse these multi-scale feature maps from each stage into a single one in a simple way, that is, a deconvolution layer is adopted to make multi-scale feature maps with the same resolution before concatenation. Since the feature maps from each stage have different scales, we use L2-normalization to rescale their norms to 10, which is similar to [21]. To investigate the optimal combination from these multiscale feature maps, we conduct an ablative experiment in Sec. 4.2 and demonstrate that Φ d e t = { ϕ 3 , ϕ 4 , ϕ 5 } \Phi_{det} = \{\phi_{3}, \phi_{4}, \phi_{5}\} Φdet={ϕ3,ϕ4,ϕ5} is the best choice. Given an input image of size H × W H \times W H×W, the size of final concatenated feature maps is H / r × W / r H/r \times W/r H/r×W/r, where r r r is the downsampling factor. Similarly to [43], r = 4 r = 4 r=4 gives the best performance as demonstrated in our experiments, because a larger r r r means coarser feature maps which struggle on accurate localization, while a smaller r r r brings more computational burdens. Note that more complicated feature fusion strategies like [23,15,17] can be explored to further improve the detection performance, but it is not in the scope of this work.
特征提取模块 以 ResNet-50 为例,其 Conv 层可以分为五个阶段,其中输出特征图相对于输入图像下采样 2, 4, 8, 16, 32。作为一种常见的做法 [48,43],在第 5 阶段采用扩张卷积使其输出保持为输入图像尺寸的 1/16。我们将阶段 2, 3, 4 and 5 的输出表示为 ϕ 2 \phi_{2} ϕ2, ϕ 3 \phi_{3} ϕ3, ϕ 4 \phi_{4} ϕ4 and ϕ 5 \phi_{5} ϕ5,其中较浅的特征图可以提供更精确的定位信息,而随着感受野尺寸的增加,较粗的特征图包含更多的语义信息。因此,我们以简单的方式将这些多尺度特征图从每个阶段融合为单个特征图,在连接之前采用反卷积层来获得具有相同分辨率的多尺度特征图。由于每个阶段的特征图具有不同的尺度,我们使用 L2-normalization 将其 norms 重新调整为 10,这类似于 [21]。为了研究这些多尺度特征图的最佳组合,我们在 Sec. 4.2 中进行了一个销蚀实验,并证明 Φ d e t = { ϕ 3 , ϕ 4 , ϕ 5 } \Phi_{det} = \{\phi_{3}, \phi_{4}, \phi_{5}\} Φdet={ϕ3,ϕ4,ϕ5} 是最佳选择。给定大小为 H × W H \times W H×W 的输入图像,最终连接的特征图的大小为 H / r × W / r H/r \times W/r H/r×W/r,其中 r r r 是下采样因子。与 [43] 类似, r = 4 r = 4 r=4 提供了最佳性能,如我们的实验所示,因为较大的 r r r 意味着较粗糙的特征图在精确定位上性能下降,而较小的 r r r 则带来更多的计算负担。请注意,可以探索更复杂的特征融合策略,如 [23,15,17],以进一步提高检测性能,但这不在本研究的范围内。
concatenation [kənkætə'neɪʃn]:n. 一系列相互关联的事,连结
ablative ['æblətɪv]:adj. 离格的,消融的 n. 烧蚀材料,离格
concatenate [kən'kætɪneɪt]:v. 连接,连结,使连锁 adj. 连接的,连结的,连锁的
coarser:adj. 粗糙的,粗俗的,下等的
coarse [kɔːs]:adj. 粗糙的,粗俗的,下等的
struggle ['strʌg(ə)l]:vi. 奋斗,努力,挣扎 n. 努力,奋斗,竞争 vt. 使劲移动,尽力使得
burden ['bɜːd(ə)n]:n. 负担,责任,船的载货量 vt. 使负担,烦扰,装货于
with respect to, with regard to or with reference to,w.r.t., w/r/t, wrt or WRT
normalization [,nɔːməlaɪ'zeɪʃən]:n. 正常化,标准化,正规化,常态化
norm [nɔːm]:n. 标准,规范
低层的特征图拥有较高的空间分辨率,能提供更多的定位信息,而高层的特征图则包含更多的语义信息,为此可以把低层和高层的特征图融合成一个特征图用于检测任务。出于减少算法复杂度的考虑,采用一种最简单的特征融合方式:首先对所有要融合的特征图进行 L2 归一化,再利用反卷积层将第 3、4 和 5 级的特征图分辨率提升到和第 2 级的特征图分辨率一致,即原图的 1/4,然后再将这些特征图在通道维度上拼接起来,得到最终用于检测的特征图 (Fig. 2 紫色部分)。给定输入图像,其大小为 H × W H \times W H×W,用于检测的特征图的大小为 H / r × W / r H/r \times W/r H/r×W/r,其中 r r r 代表降采样率,较大的 r r r 意味着特征图分辨率较小进而导致检测器定位性能下降,而较小的 r r r 则会带来更多的计算负担。浅层含有更加准确的位置信息,深层拥有更多的语义信息。
Detection Head. Upon the concatenated feature maps Φ d e t \Phi_{det} Φdet, a detection head is appended to parse it into detection results. As stated in [26], the detection head plays a significant role in top performance, which has been extensively explored in the literature [9, 26, 20, 19]. In this work, we firstly attach a single 3x3 Conv layer on Φ d e t \Phi_{det} Φdet to reduce its channel dimensions to 256, and then two sibling 1x1 Conv layers are appended to produce the center heatmap and scale map, respectively. Also, we do this for simplicity and any improvement of the detection head [9, 26, 20, 19] can be flexibly incorporate into this work to be a better detector.
检测头模块 在连接特征图时,附加检测头以将其解析为检测结果。如 [26] 中所述,检测头在最佳性能中起着重要作用,这已在文献 [9, 26, 20, 19] 中得到广泛研究。在这项工作中,我们首先在 Φ d e t \Phi_{det} Φdet 上附加单个 3x3 Conv 层以将其通道尺寸减小到 256,然后是两个并联 1x1 Conv 层附加以分别产生中心热图和尺度图。此外,我们这样做不仅简单,并且检测头 [9, 26, 20, 19] 的任何改进都可以灵活地结合到这项工作中,以成为更好的检测器。
A drawback from the downsampled feature maps is the problem of poor localization. Optionally, to slightly adjust the center location, an extra offset prediction branch can be appended in parallel with the above two branches.
下采样特征图的缺点是定位不良的问题。可选地,为了稍微调整中心位置,可以与上述两个分支并行地附加额外的偏移预测分支。
simplicity [sɪm'plɪsɪtɪ]:n. 朴素,简易,天真,愚蠢
sibling ['sɪblɪŋ]:n. 兄弟姊妹,民族成员
基于上述特征图,检测头负责将特征图解译成检测结果。在检测头模块中,首先接上一个 3x3 卷积层将输入特征图的维度压缩到 256,然后接上两个并联的 1x1 卷积层产生目标中心点热图和目标尺度预测图,这样相较于 R-CNN 及 SSD 等工作而言极大地简化了检测头模块。实验表明中心点检测和尺度预测已经足以胜任行人检测任务。但采用降采样的特征图会影响目标定位性能,为了弥补这一缺陷,在中心点以及尺度预测之外,还可以额外添加一个偏移预测分支,用以进一步预测中心点到真实目标中心的偏移。

Fig. 3 (a) is the bounding box annotations commonly adopted by anchor box based detectors. (b) is the center and scale ground truth generated automatically from (a). Locations of all objects’ center points are assigned as positives, and negatives otherwise. Each pixel is assigned a scale value of the corresponding object if it is a positive point, or 0 otherwise. We only show the height information of the two positives for clarity. (c) is the overall Gaussian mask map M defined in Eq.4 to reduce the ambiguity of these negatives surrounding the positives.
图 3 (a) 是基于锚框的检测器通常采用的边界框标注。(b) 是 (a) 自动生成的中心和尺度 ground truth。所有物体的中心点的位置都被指定为正数,否则指定为负数。如果像素是一个正点,则为其分配相应物体的尺度值,否则为 0。为了清晰起见,我们只显示这两个正样本的高度信息。(c) 是等式 4 中定义的整体高斯掩模图 M,以减少围绕着正样本的这些负样本的模糊性。
ambiguity [æmbɪ'gjuːɪtɪ]:n. 含糊,不明确,暧昧,模棱两可的话
clarity ['klærɪtɪ]:n. 清楚,明晰,透明
(b) 给出了中心点和尺度的生成示例:对于中心点,当目标中心落在哪个位置,则在该位置赋值 1 (即正样本),其它位置赋值 0 (即负样本)。对于尺度图,当目标中心落在哪个位置,则在该位置赋值尺度的 log 值,其它位置赋值 0。取 log 函数是为了将分布范围较大的原始尺度压缩在一定的范围内,并且误差是尺度无关的,以有利于检测器的训练。考虑到单一中心点的不确定性,在图 (c) 中我们还定义了一个高斯掩码,用以降低中心点周围负样本的权重。
3.3 Training
Ground Truth. The predicted heatmaps are with the same size as the concatenated feature maps (i.e. H / r × W / r H/r \times W/r H/r×W/r). Given the bounding box annotations, we can generate the center and scale ground truth automatically. Taking pedestrian detection as an example, an illustration example is depicted in Fig. 3 (b). For the center ground truth, the location where an object’s center point falls is assigned as positive while all others are negatives.
Ground Truth. 预测的热图与级联特征图具有相同的大小 (i.e. H / r × W / r H/r \times W/r H/r×W/r)。给定边界框标注,我们可以自动生成中心和缩放 ground truth。以行人检测为例,Fig. 3 (b) 描述了一个示例。对于中心 ground truth,物体中心点落下的位置被指定为正,而所有其他位置都是负数。
Scale can be defined as the height and/or width of objects. Towards high-quality ground truth for pedestrian detection, line annotation is first proposed in [54,55], where tight bounding boxes are automatically generated with a uniform aspect ratio of 0.41. In accordance to this annotation, we can merely predict the height of each pedestrian instance and generate the bounding box with the predetermined aspect ratio. For the scale ground truth, the k k kth positive location is assigned with the value of l o g ( h k ) log(h_{k}) log(hk) corresponding to the k k kth object. To reduce the ambiguity, l o g ( h k ) log(h_{k}) log(hk) is also assigned to the negatives within a radius 2 of the positives, while all other locations are assigned as zeros. Alternatively, we can also predict the width or height+width but with slightly poor performance for pedestrian detection as demonstrated in our experiments (Sec. 4.2). However, both height and width prediction is required for face detection, because face objects in the wild exhibit a large variation in aspect ratios.
尺度可以定义为物体的高度和/或宽度。为了获得行人检测的高质量 ground truth,首先在 [54,55] 中提出了线条标注,其中自动生成具有 0.41 的统一宽高比的紧定边界框。根据该标注,我们可以仅预测每个行人实例的高度并生成具有预定宽高比的边界框。对于尺度 ground truth,第 k k k 个正位置被赋予对应于第 k k k 个物体的 l o g ( h k ) log(h_{k}) log(hk) 的值。为了减少模糊性, l o g ( h k ) log(h_{k}) log(hk) 也被分配给正样本的半径为 2 内的负样本,而所有其他位置都被指定为零。我们也可以预测宽度或高度+宽度,但行人检测的性能稍差,如我们的实验 (Sec. 4.2) 所示。然而,面部检测需要高度和宽度预测,因为野外的面部物体在宽高比方面表现出很大的变化。
目标尺度可以定义为目标高度和/或宽度。对于行人检测而言,为了得到更紧致的目标包围框,近期的研究均采用人体中轴线标注,即确定行人的上顶点和下顶点并形成连线得到行人高度,然后采用固定的宽高比 0.41 直接确定行人宽度,进而生成目标包围框。基于此,CSP 行人检测器可以只预测目标高度,然后根据固定宽高比 0.41 生成检测框用于后续评估,这是由行人直立行走的特性决定的。但对于其他非行人目标而言,CSP 的尺度预测就需要同时预测目标高度和宽度。
When the offset prediction branch is appended, the ground truth for the offsets of those centers can be defined as ( x k r − ⌊ x k r ⌋ , y k r − ⌊ y k r ⌋ ) (\frac{x_{k}}{r} - \lfloor \frac{x_{k}}{r} \rfloor, \frac{y_{k}}{r} - \lfloor \frac{y_{k}}{r} \rfloor) (rxk−⌊rxk⌋,ryk−⌊ryk⌋).
当附加偏移预测分支时,这些中心偏移 ground truth 可以定义为 ( x k r − ⌊ x k r ⌋ , y k r − ⌊ y k r ⌋ ) (\frac{x_{k}}{r} - \lfloor \frac{x_{k}}{r} \rfloor, \frac{y_{k}}{r} - \lfloor \frac{y_{k}}{r} \rfloor) (rxk−⌊rxk⌋,ryk−⌊ryk⌋)。
accordance [ə'kɔːd(ə)ns]:n. 按照,依据,一致,和谐
predetermine [priːdɪ'tɜːmɪn]:vt. 预先确定,预先决定,预先查明
radius ['reɪdɪəs]:n. 半径,半径范围,桡骨,辐射光线,有效航程
中心点偏移量的训练目标的定义与尺度类似,卷积预测的通道包含两层,分别负责水平方向和垂直方向的偏移量,假设目标 k k k 的中心点坐标为 ( x k , y k ) (x_{k}, y_{k}) (xk,yk),则在标签图中目标中心所在的位置赋值为 ( x k r − ⌊ x k r ⌋ , y k r − ⌊ y k r ⌋ ) (\frac{x_{k}}{r} - \lfloor \frac{x_{k}}{r} \rfloor, \frac{y_{k}}{r} - \lfloor \frac{y_{k}}{r} \rfloor) (rxk−⌊rxk⌋,ryk−⌊ryk⌋),其中 ⌊ . ⌋ \lfloor . \rfloor ⌊.⌋ 代表取整函数,其它位置赋值为 0。
Loss Function. For the center prediction branch, we formulate it as a classification task via the cross-entropy loss. Note that it is difficult to decide an ’exact’ center point, thus the hard-designation of positives and negatives brings more difficulties for training. In order to reduce the ambiguity of these negatives surrounding the positives, we also apply a 2D Gaussian mask G ( . ) G(.) G(.) centered at the location of each positive, which is similar in [18,43]. An illustration example of the overall mask map M M M is depicted in Fig. 3 (c). Formally, it is formulated as:
M i j = m a x k = 1 , 2 , . . . , K G ( i , j ; x k , y k , σ w k , σ h k ) , G ( i , j ; x k , y k , σ w k , σ h k ) = e − ( ( i − x ) 2 2 σ w 2 + ( j − y ) 2 2 σ h 2 ) , (4) \begin{aligned} & M_{ij} = \underset{k=1, 2, ..., K}{max} G(i, j; x_{k}, y_{k}, \sigma_{w_{k}}, \sigma_{h_{k}}), \\ & G(i, j; x_{k}, y_{k}, \sigma_{w_{k}}, \sigma_{h_{k}}) = e^{-\left(\frac{(i - x)^2}{2 \sigma^{2}_w} + \frac{(j - y)^2}{2 \sigma^{2}_h}\right)}, \tag{4} \end{aligned} Mij=k=1,2,...,KmaxG(i,j;xk,yk,σwk,σhk),G(i,j;xk,yk,σwk,σhk)=e−(2σw2(i−x)2+2σh2(j−y)2),(4)
Loss Function. 对于中心预测分支,我们通过交叉熵损失将其表示为分类任务。请注意,很难确定“确切”的中心点,因此正样本和负样本的难以指定会给训练带来更多困难。为了减少围绕正样本的这些负样本的模糊性,我们在每个正样本位置为中心应用 2D 高斯掩模 G ( . ) G(.) G(.),类似 [18,43]。Fig. 3 (c) 中描绘了整体掩模图 M M M 的图示示例。它被表述为:
M i j = m a x k = 1 , 2 , . . . , K G ( i , j ; x k , y k , σ w k , σ h k ) , G ( i , j ; x k , y k , σ w k , σ h k ) = e − ( ( i − x ) 2 2 σ w 2 + ( j − y ) 2 2 σ h 2 ) , (4) \begin{aligned} & M_{ij} = \underset{k=1, 2, ..., K}{max} G(i, j; x_{k}, y_{k}, \sigma_{w_{k}}, \sigma_{h_{k}}), \\ & G(i, j; x_{k}, y_{k}, \sigma_{w_{k}}, \sigma_{h_{k}}) = e^{-\left(\frac{(i - x)^2}{2 \sigma^{2}_w} + \frac{(j - y)^2}{2 \sigma^{2}_h}\right)}, \tag{4} \end{aligned} Mij=k=1,2,...,KmaxG(i,j;xk,yk,σwk,σhk),G(i,j;xk,yk,σwk,σhk)=e−(2σw2(i−x)2+2σh2(j−y)2),(4)
formulate ['fɔːmjʊleɪt]:vt. 规划,用公式表示,明确地表达
cross-entropy:互熵,交叉熵
where K K K is the number of objects in an image, ( x k , y k , σ w k , σ h k ) (x_{k}, y_{k}, \sigma_{w_{k}}, \sigma_{h_{k}}) (xk,yk,σwk,σhk) is the center coordinates, width and height of the k k kth object, and the variances ( σ w k , σ h k ) (\sigma_{w}^{k}, \sigma_{h}^{k}) (σwk,σhk) of the Gaussian mask are proportional to the height and width of individual objects. If these masks have overlaps, we choose the maximum values for the overlapped locations. To combat the extreme positive-negative imbalance problem, the focal weights [24] on hard examples are also adopted. Thus, the classification loss can be formulated as:
其中 K K K 是图像中目标的数量, ( x k , y k , σ w k , σ h k ) (x_{k}, y_{k}, \sigma_{w_{k}}, \sigma_{h_{k}}) (xk,yk,σwk,σhk) 是第 k k k 个目标的中心坐标、宽度和高度,以及高斯掩模的方差 ( σ w k , σ h k ) (\sigma_{w}^{k}, \sigma_{h}^{k}) (σwk,σhk) 与各个目标的高度和宽度成比例。如果这些掩模有重叠,我们会选择重叠位置的最大值。为了对抗极端的正负不平衡问题,还采用了关于难分样本的 focal weights [24]。因此,分类损失可以表述为:
L c e n t e r = − 1 K ∑ i = 1 W / r ∑ j = 1 H / r α i j ( 1 − p ^ i j ) γ l o g ( p ^ i j ) , (5) L_{center} = - \frac{1}{K} \sum_{i=1}^{W/r} \sum_{j=1}^{H/r} \alpha_{ij}(1 - \hat{p}_{ij})^{\gamma} log(\hat{p}_{ij}), \tag{5} Lcenter=−K1i=1∑W/rj=1∑H/rαij(1−p^ij)γlog(p^ij),(5)
where
p ^ i j = { p i j if y i j = 1 1 − p i j otherwise, α i j = { 1 if y i j = 1 ( 1 − M i j ) β otherwise. (6) \begin{aligned} & \hat{p}_{ij} = \begin{cases} {p}_{ij} &\text{if } {y}_{ij} = 1\\ 1 - {p}_{ij} &\text{otherwise,} \end{cases} \\ & \alpha_{ij} = \begin{cases} 1 &\text{if } {y}_{ij} = 1\\ (1 - M_{ij})^{\beta} &\text{otherwise.} \end{cases} \end{aligned} \tag{6} p^ij={pij1−pijif yij=1otherwise,αij={1(1−Mij)βif yij=1otherwise.(6)
proportional [prə'pɔːʃ(ə)n(ə)l]:adj. 比例的,成比例的,相称的,均衡的 n. 比例项
imbalance [ɪm'bæl(ə)ns]:n. 不平衡,不安定
In the above, p i j ∈ [ 0 , 1 ] p_{ij} \in [0, 1] pij∈[0,1] is the network’s estimated probability indicating whether there is an object’s center or not in the location ( i , j ) (i, j) (i,j), and y i j ∈ { 0 , 1 } y_{ij} \in \{0, 1\} yij∈{0,1} specifies the ground truth label, where y i j = 1 y_{ij} = 1 yij=1 represents the positive location. α i j \alpha_{ij} αij and γ \gamma γ are the focusing hyper-parameters, we experimentally set γ = 2 \gamma = 2 γ=2 as suggested in [24].To reduce the ambiguity from those negatives surrounding the positives, the α i j \alpha_{ij} αij according to the Gaussian mask M M M is applied to reduce their contributions to the total loss, in which the hyper-parameter β \beta β controls the penalty. Experimentally, β = 4 \beta = 4 β=4 gives the best performance, which is similar to the one in [18]. For positives, α i j \alpha_{ij} αij is set as 1.
在上面, p i j ∈ [ 0 , 1 ] p_{ij} \in [0, 1] pij∈[0,1] 是网络估计的概率,表示在 ( i , j ) (i, j) (i,j) 中是否存在物体的中心, y i j ∈ { 0 , 1 } y_{ij} \in \{0, 1\} yij∈{0,1} 指定ground truth label,其中 y i j = 1 y_{ij} = 1 yij=1 表示正样本。 α i j \alpha_{ij} αij and γ \gamma γ 是聚焦超参数,我们实验设置 γ = 2 \gamma = 2 γ=2,如 [24] 中所建议的那样。为了减少围绕着正样本的这些负样本的模糊性,根据高斯掩模 M M M 的 α i j \alpha_{ij} αij 用于减少它们对总损失的贡献,其中超参数 β \beta β 控制惩罚项。在实验上, β = 4 \beta = 4 β=4 给出了最佳性能,这与 [18] 中的类似。对于正样本, α i j \alpha_{ij} αij 设置为 1。
penalty ['pen(ə)ltɪ]:n. 罚款,罚金,处罚
For scale prediction, we formulate it as a regression task via the smooth L1 loss [10]:
对于尺度预测,我们通过平滑的 L1 损失将其表示为回归任务 [10]:
L s c a l e = 1 K ∑ k = 1 K S m o o t h L 1 ( s k , t k ) , (7) L_{scale} = \frac{1}{K} \sum_{k=1}^{K} SmoothL1(s_{k}, t_{k}), \tag{7} Lscale=K1k=1∑KSmoothL1(sk,tk),(7)
where s k s_{k} sk and t k t_{k} tk represents the network’s prediction and the ground truth of each positive, respectively.
其中 s k s_{k} sk and t k t_{k} tk 分别代表网络的预测和 the ground truth of each positive。
If the offset prediction branch is appended, the similar smooth L1 loss in Eq. 7 is adopted (denoted as L o f f s e t L_{offset} Loffset).
如果附加了偏移预测分支,则等式中的类似平滑 L1 损失。采用 Eq. 7 (denoted as L o f f s e t L_{offset} Loffset)。
To sum up, the full optimization objective is:
总而言之,完整的优化目标是:
L = λ c L c e n t e r + λ s L s c a l e + λ o L o f f s e t , (8) L = \lambda_{c}L_{center} + \lambda_{s}L_{scale} + \lambda_{o}L_{offset}, \tag{8} L=λcLcenter+λsLscale+λoLoffset,(8)
where λ c \lambda_{c} λc, λ s \lambda_{s} λs and λ o \lambda_{o} λo are the weights for center classification, scale regression and offset regression losses, which are experimentally set as 0.01, 1 and 0.1, respectively.
其中 λ c \lambda_{c} λc, λ s \lambda_{s} λs and λ o \lambda_{o} λo 是中心分类、尺度回归和偏移回归损失的权重,分别通过实验设置为 0.01, 1 和 0.1。
预测中心点位置的损失函数、预测维度大小的损失函数。
对于尺度大小的预测,本文将其视为回归任务。在预测中心点位置时,本文将其视为一个分类问题。由于很难预测到一个准确的像素点,这样在训练中,positive 点附近的点就会带来较多的误差,不利于网络的训练。为了减少这种不确定性带,作者采用了在 positive 点上添加二维高斯掩膜。
目标中心点预测是一个二分类问题,判断热图的每个位置是否存在目标中心点,是中心点则为正样本,否则为负样本。然而通常情况下一个完美的目标中心点是很难定义的。由于正样本周围的负样本距离中心点非常近,很容易被标注误差所干扰,因此直接将其指定为负样本会给检测器的训练带来困扰。对此,本文在每个正样本及其周围采用一个高斯掩码,该高斯掩码以目标中心点为中心坐标,其水平/垂直方差与目标的宽度/高度成正比。如果两个目标的高斯掩码之间存在重合,则择取二者中的最大值。为了应对正负样本数量极端不平衡的问题,对难分样本赋予更大的权重。结合高斯掩码和 focal weights [24],一是难分样本的权重得到了增强,二是在正样本周围的负样本的权重得到了降低。最后,目标的尺度预测可以构建为一个回归问题,由经典的平滑 L1 损失给出。
p i j ∈ [ 0 , 1 ] p_{ij} \in [0, 1] pij∈[0,1] 是预测当前像素点是中心点的可能性, y i j ∈ { 0 , 1 } y_{ij} \in \{0, 1\} yij∈{0,1} 是 ground truth 标签。 y i j = 1 y_{ij} = 1 yij=1 代表该像素点被标记为 positive, y i j = 0 y_{ij} = 0 yij=0 表示该点为 negative。通过参数 α i j \alpha_{ij} αij 减少 positive 附近的 negative 点对总体损失函数的影响,经过多次实验将 γ \gamma γ 设置为 2,将 β \beta β 设置为 4。网络把 positive 点附近的各个 negative 预测为 positive 的可能性很大,这样所有点加起来就会贡献较大的误差,网络的拟合效果不佳。而使用高斯掩膜之后会减少附近 negative 点所带来的误差影响,有利于网络训练。
3.4 Inference
During testing, CSP simply involves a single forward of FCN with several predictions. Specifically, locations with confidence score above 0.01 in the center heatmap are kept, along with their corresponding scale in the scale map. Then bounding boxes are generated automatically and remapped to the original image size, followed by NMS. If the offset prediction branch is appended, the centers are adjusted accordingly before remapping.
在测试期间,CSP 只包含 FCN 的单个前向运算,具有多个预测。具体而言,保留中心热图中置信度得分大于 0.01 的位置,以及它们在尺度图中的相应尺度。然后自动生成边界框并重新映射到原始图像大小,然后是 NMS。如果附加了偏移预测分支,则在重新映射之前相应地调整中心。
remap ['rimæp]:n. 重测图,再交换
4 Experiments
4.1 Experiment settings
4.1.1 Datasets
To demonstrate the effectiveness of the proposed method, we evaluate it on several challenging benchmarks, including pedestrian detection and face detection.
为了证明提出方法的有效性,我们在几个具有挑战性的基准数据集上进行评估,包括行人检测和面部检测。
For pedestrian detection, we choose two of the largest pedestrian detection benchmarks, i.e. Caltech [8] and CityPersons [55]. Caltech comprises approximately 2.5 hours of autodriving video with extensively labelled bounding boxes. Following [55, 32, 48, 28, 56], we use the training data augmented by 10 folds (42782 frames) and test on the 4024 frames in the standard test set, all experiments are conducted on the new annotations provided by [53]. CityPersons is a more challenging large-scale pedestrian detection dataset with various occlusion levels. We train the models on the official training set with 2975 images and test on the validation set with 500 images. One reason we choose these two datasets lies in that they provide bounding boxes via central body line annotation and normalized aspect ratio, this annotation procedure is helpful to ensure the boxes align well with the centers of pedestrians. Evaluation follows the standard Caltech evaluation metric [8], that is log-average Miss Rate over False Positive Per Image (FPPI) ranging in [10-2, 100] (denoted as M R − 2 MR^{-2} MR−2). Tests are only applied on the original image size without enlarging for speed consideration.
对于行人检测,我们选择两个最大的行人检测基准数据集,i.e. Caltech [8] and CityPersons [55]。Caltech 包括大约 2.5 小时的自动驾驶视频和广泛标注的边界框。在 [55, 32, 48, 28, 56] 之后,我们将训练数据增广了 10 倍 (42782 帧),并在标准测试集的 4024 帧上进行测试,所有实验都在 [53] 提供的新标注上进行。CityPersons 是一个具有各种遮挡比例的更具挑战性的大型行人检测数据集。我们在具有 2975 个图像的官方训练集上训练模型,并在具有 500 个图像的验证集上进行测试。我们选择这两个数据集的一个原因在于它们通过中心体线标注和标准化宽高比提供边界框,这个标注程序有助于确保框与行人中心很好地对齐。评估遵循标准的 Caltech 评估指标 [8],that is log-average Miss Rate over False Positive Per Image (FPPI) 范围为 [10-2, 100] (表示为 M R − 2 MR^{-2} MR−2)。测试仅适用于原始图像尺寸,而不会考虑速度。
其中标注是采用的基于中心线的紧致标注。
False Positive Per Image,FPPI:单图虚检
log-average miss rate:对数平均漏检率
For face detection, we choose one of the most challenging face detection benchmark, i.e. WiderFace [51], which contains 32203 images and 393703 annotated face bounding boxes with variations in pose, scale, aspect ratio, occlusion and illumination conditions. The main reason we choose this dataset is due to its large variability of aspect ratios and occlusions. The dataset is split into 40%, 10% and 50% for training, validation and testing, respectively, and defines three levels of difficulty by the detection rate of EdgeBox [61]: Easy, Medium and Hard. Similar to other state-of-the-art face detectors, the proposed CSP is only trained on the training subset while tested on both validation and testing subsets. Evaluation follows the official evaluation metric that is the Average Precision (AP).
对于面部检测,我们选择最具挑战性的面部检测基准数据集之一 WiderFace [51],其包含 32203 个图像和 393703 个带标注的面部边界框,其具有姿势、尺度、宽高比、遮挡和照明条件的变化。我们选择此数据集的主要原因是由于其宽高比和遮挡的变化很大。数据集划分为 40%、10% 和 50% 用于训练,验证和测试,并通过 EdgeBox [61] 的检测率来定义三个难度级别:Easy、Medium 和 Hard。与其他最先进的面部检测器类似,建议的 CSP 仅在训练子集上进行训练,同时在验证和测试子集上进行测试。评估遵循平均精度 (AP) 的官方评估指标。
We conduct the ablative study on the Caltech dataset, and compare the proposed CSP detector with the state of the arts on all the above benchmarks.
我们对 Caltech 数据集进行了销蚀研究,并将所提出的 CSP 检测器与上述所有基准数据集测试中的现有技术进行了比较。
enlarge [ɪn'lɑːdʒ; en-]:vi. 扩大,放大,详述 vt. 扩大,使增大,扩展
4.1.2 Training details
We implement the proposed method in Keras2. The backbone is ResNet-50 [11] pretrained on ImageNet [7] unless otherwise stated. Adam [16] is applied to optimize the network. We also apply the strategy of moving average weights proposed in [45] to achieve more stable training. To increase the diversity of the training data, we adopt standard data augmentation techniques including random color distortion, random horizontal flip, random scaling and random crop, finally, the input resolutions of the network during training are 336x448, 640x1280 and 704x704 pixels for Caltech, CityPersons and WiderFace, respectively.
我们在 Keras2 中实现了所提出的方法。除非另有说明,否则骨干网是在 ImageNet [7] 上预训练的ResNet-50 [11]。Adam [16] 用于优化网络。我们还应用 [45] 中提出的移动平均权重策略来实现更稳定的训练。为了增加训练数据的多样性,我们采用标准数据增强技术,包括随机颜色失真、随机水平翻转、随机缩放和随机裁剪,最终,训练期间网络的输入分辨率为 336x448、640x1280 和 704x704 像素,分别用于 Caltech, CityPersons and WiderFace。
diversity [daɪ'vɜːsɪtɪ; dɪ-]:n. 多样性,差异
2https://github.com/keras-team/keras
For Caltech, a mini-batch contains 16 images with one GPU (GTX 1080Ti), the learning rate is set as 10-4 and training is stopped after 15K iterations. Following [55, 48,28,56], we also include experiments with the model initialized from CityPersons [55], which is trained with the learning rate of 2 × \times × 10-5. For CityPersons, we optimize the network on 4 GPUs with 2 images per GPU for a mini-batch, the learning rate is set as 2 × \times × 10-4 and training is stopped after 37.5K iterations. For WiderFace, we optimize the network on 8 GPUs with 2 images per GPU for a mini-batch, the learning rate is set as 2 × \times × 10-4 and training is stopped after 99.5K iterations. We also adopt the similar data-augmentation strategy in PyramidBox [44] to increase the proportion of small faces during training.
对于 Caltech,mini-batch 包含 16 张图像和一个 GPU (GTX 1080Ti),学习率设置为 10-4,训练在 15K 迭代后停止。在 [55,48,28,56] 之后,我们还执行从 CityPersons [55] 初始化的模型的实验,该模型使用的 2 × \times × 10-5 学习率进行训练。对于 CityPersons,我们在 4 个 GPU 上优化网络,每个 GPU 有 2 个图像用于 mini-batch,学习率设置为 2 × \times × 10-4,并且在 37.5K 迭代后停止训练。对于 WiderFace,我们在 8 个 GPU 上优化网络,每个 GPU 有 2 个图像用于 mini-batch,学习率设置为 2 × \times × 10-4,并且在 99.5K 迭代后停止训练。我们还在 PyramidBox [44] 中采用类似的数据增强策略来增加训练期间小脸的比例。
4.2 Ablation Study
In this section, an ablative analysis of the proposed CSP detector is conducted on the Caltech dataset, evaluations are based on the new annotations provided by [53].
在本节中,对 Caltech 数据集进行了所提出的 CSP 检测器的销蚀分析,评估基于 [53] 提供的新标注。
Why is the Center Point? As a kind of high-level feature point, the center point is capable of locating an individual object. A question comes in that how about other high-level feature points. To answer this, we choose two other high-level feature points as adopted in [43], i.e. the top and bottom vertexes. Comparisons are reported in Table. 1. It is shown that both the two vertexes can succeed in detection but underperform the center point by approximately 2%-3% under IoU=0.5, and the performance gap is even larger under the stricter IoU=0.75. This is probably because the center point is advantageous to perceive the full body information and thus is easier for training.
Why is the Center Point? 作为一种高级特征点,中心点能够定位单个物体。一个问题是其他高级特征点如何。为了回答这个问题,我们选择了 [43] 中采用的另外两个高级特征点,即顶部和底部顶点。比较报告在 Table. 1。结果表明,在 IoU=0.5 的情况下,两个顶点都可以成功检测,但相较于中心点的表现差约 2%-3%,在更严格的 IoU=0.75 下性能差距更大。这可能是因为中心点有利于感知全身信息,因此更容易进行训练。
Table 1 Comparisons of different high-level feature points. Bold number indicates the best result.

perceive [pə'siːv]:vt. 察觉,感觉,理解,认知 vi. 感到,感知,认识到
bold [bəʊld]:adj. 大胆的,英勇的,黑体的,厚颜无耻的,险峻的
How important is the Scale Prediction? Scale prediction is another indispensable component for bounding box generation. In practice, we merely predict the height for each detected center in accordance to the line annotation in [54, 55]. To demonstrate the generality of CSP, we have also tried to predict Width or Height+Width for comparison. For Height+Width, the only difference in network architecture lies in that the scale prediction branch has two channels responsible for the height and width respectively. It can be observed in Table 2 that Width and Height+Width prediction can also achieve comparable but suboptimal results to Height prediction. This result may be attributed to the line annotation adopted in [54, 55] which provides accurate height information with less noise during training. Besides, the ground truth for width is automatically generated by the annotated height information, thus is not able to provide additional information for training. With the comparable performance from Height +Width prediction, it makes CSP potentially feasible for other object detection tasks requiring both height and width, which will be demonstrated in the following experiments for face detection.
How important is the Scale Prediction? 尺度预测是边界框生成的另一个不可或缺的组成部分。在实践中,我们仅根据 [54, 55] 中的线标注预测每个检测到的中心的高度。为了证明 CSP 的通用性,我们还尝试预测宽度或高度+宽度进行比较。对于高度+宽度,网络架构的唯一区别在于,尺度预测分支具有分别负责高度和宽度的两个通道。在表 2 中可以观察到,宽度和高度+宽度预测也可以实现与高度预测相当但次优的结果。该结果可归因于 [54, 55] 中采用的线标注,其提供准确的高度信息,在训练期间具有较少的噪声。此外,宽度的 ground truth 由标注的高度信息自动生成,因此无法为训练提供额外的信息。通过高度+宽度预测的性能,它使得 CSP 对于需要高度和宽度的其他物体检测任务可能是可行的,这将在以下面部检测实验中得到证明。
Table 2 Comparisons of different definitions for scale prediction. Bold number indicates the best result.

How important is the Feature Resolution? In the proposed method, the final set of feature maps (denoted as Φ d e t r \Phi_{det}^{r} Φdetr) is downsampled by r r r w.r.t the input image. To explore the influence from r r r, we train the models with r r r = 2, 4, 8, 16 respectively. For r r r = 2, Φ d e t 2 \Phi_{det}^{2} Φdet2 are up-sampled from Φ d e t 4 \Phi_{det}^{4} Φdet4 by deconvolution. To remedy the issue of poor localization from downsampling, the offset prediction branch is alternatively appended for r r r = 4, 8, 16 to adjust the center location. Evaluations under IoU=0.75 are included to verify the effectiveness of additional offset prediction when stricter localization quality is required. As can be seen from Table. 3, without offset prediction, Φ d e t 4 \Phi_{det}^{4} Φdet4 presents the best result under IoU=0.5, but performs poorly under IoU=0.75 when compared with Φ d e t 2 \Phi_{det}^{2} Φdet2, which indicates that finer feature maps are beneficial for precise localization. Though Φ d e t 2 \Phi_{det}^{2} Φdet2 performs the best under IoU=0.75, it does not bring performance gain under IoU=0.5 though with more computational burdens. Not surprisingly, a larger r r r witnesses a significant performance drop, which is mainly due to that coarser feature maps lead to poor localization. In this case, the offset prediction plays a significant role. Notably, additional offset prediction can substantially improve the detector upon Φ d e t 16 \Phi_{det}^{16} Φdet16 by 12.86% and 41.30% under the IoU threshold of 0.5 and 0.75, respectively. It can also achieve an improvement of 7.67% under IoU=0.75 for the detector upon Φ d e t 4 \Phi_{det}^{4} Φdet4, even though the performance gain is saturating under IoU=0.5. It is worth noting that the extra computation cost from the offset prediction is negligible, with approximately 1ms per image of 480x640 pixels.
How important is the Feature Resolution? 在提出的方法中,最终的特征图集 (denoted as Φ d e t r \Phi_{det}^{r} Φdetr) 是输入图像的 r r r 下采样。为了探索 r r r 的影响,我们分别用 r r r = 2, 4, 8, 16 训练模型。对于 r r r = 2, Φ d e t 2 \Phi_{det}^{2} Φdet2 通过反卷积从 Φ d e t 4 \Phi_{det}^{4} Φdet4 上采样。为了解决下采样导致定位不良的问题,可附加偏移预测分支以用于 r r r = 4, 8, 16 来调整中心位置。当需要更严格的定位准确率时,在 IoU=0.75 下的评估以验证附加偏移预测的有效性。从 Table. 3 中可以看出,没有偏移预测, Φ d e t 4 \Phi_{det}^{4} Φdet4 在 IoU=0.5 下呈现最佳结果,但与 Φ d e t 2 \Phi_{det}^{2} Φdet2 相比,在 IoU=0.75 下表现不佳,这表明更精细的特征图有利于精确定位。尽管 Φ d e t 2 \Phi_{det}^{2} Φdet2 在 IoU=0.75 下表现最佳,但在 IoU=0.5 的情况下不会带来性能提升,而且计算负担更多。毫不奇怪,更大的 r r r 见证了显著的性能下降,这主要是由于较粗糙的特征图导致了较差的定位。在这种情况下,偏移预测起着重要作用。值得注意的是,在 IoU 阈值分别为 0.5 和 0.75 时,额外的偏移预测可以在 Φ d e t 16 \Phi_{det}^{16} Φdet16 上显着改善检测器 12.86% 和 41.30%。即使在 IoU=0.5 下性能增益饱和,对于检测器,在 Φ d e t 4 \Phi_{det}^{4} Φdet4 下,它也可以在 IoU=0.75 下实现 7.67% 的改善。值得注意的是,来自偏移预测的额外计算成本可以忽略不计,每个 480x640 像素图像大约 1ms。
remedy ['remɪdɪ]:vt. 补救,治疗,纠正 n. 补救,治疗,赔偿
beneficial [benɪ'fɪʃ(ə)l]:adj. 有益的,有利的,可享利益的
Table 3 Comparisons of different downsampling factors of the feature maps, which are denoted as Φ d e t r \Phi_{det}^{r} Φdetr downsampled by r r r w.r.t the input image. Test time is evaluated on the image with size of 480x640 pixels. Δ M R − 2 \Delta MR^{-2} ΔMR−2 means the improvement from the utilization of the offset prediction. Bold numbers indicate the best result.
表 3 不同下采样因子的特征图比较,其由输入图像下采样 r r r 表示为 Φ d e t r \Phi_{det}^{r} Φdetr。在尺寸为 480x640 像素的图像上评估测试时间。 Δ M R − 2 \Delta MR^{-2} ΔMR−2 表示利用偏移预测的改进。粗体数字表示最佳结果。

How important is the Feature Combination? It has been revealed in [43] that multi-scale representation is vital for pedestrian detection of various scales. In this part, we conduct an ablative experiment to study which combination of the multiscale feature maps from the backbone is the optimal one. As the much lower layer has limited discriminant information, in practice we choose the output of stage 2 ( ϕ 2 \phi_{2} ϕ2) as a start point and the downsampling factor r r r is fixed as 4. In spite of the ResNet-50 [11] with stronger feature representation, we also choose a light-weight network like MobileNetV1 [12] as the backbone. The results in Table 4 shows that the much shallower feature maps like ϕ 2 \phi_{2} ϕ2 result in poorer accuracy, while deeper feature maps like ϕ 4 \phi_{4} ϕ4 and ϕ 5 \phi_{5} ϕ5 are of great importance for superior performance, and the middle-level feature maps ϕ 3 \phi_{3} ϕ3 are indispensable to achieve the best results. For ResNet-50, the best performance comes from the combination of { ϕ 3 , ϕ 4 , ϕ 5 } \{\phi_{3}, \phi_{4}, \phi_{5}\} {ϕ3,ϕ4,ϕ5}, while { ϕ 3 , ϕ 4 } \{\phi_{3}, \phi_{4}\} {ϕ3,ϕ4} is the optimal one for MobileNetV1.
How important is the Feature Combination? [43] 揭示了多尺度表示对于各种尺度的行人检测至关重要。在这一部分,我们进行了一个销蚀实验,研究骨干多尺度特征图的哪种组合是最优的。由于较低层的判别信息有限,实际上我们选择阶段 2 的输出 ( ϕ 2 \phi_{2} ϕ2) 作为起点,下采样因子 r r r 固定为 4。尽管 ResNet-50 [11] 具有更强的特征表示,我们还选择像 MobileNetV1 [12] 这样的轻量级网络作为主干。表 4 中的结果显示,像 ϕ 2 \phi_{2} ϕ2 这样更浅的特征图导致精度更差,而更深层的特征图如 ϕ 4 \phi_{4} ϕ4 and ϕ 5 \phi_{5} ϕ5 是至关重要的,以及中级特征图 ϕ 3 \phi_{3} ϕ3 是实现最佳效果不可或缺的。对于 ResNet-50,最佳性能来自 { ϕ 3 , ϕ 4 , ϕ 5 } \{\phi_{3}, \phi_{4}, \phi_{5}\} {ϕ3,ϕ4,ϕ5} 的组合,而 { ϕ 3 , ϕ 4 } \{\phi_{3}, \phi_{4}\} {ϕ3,ϕ4} 是 MobileNetV1 的最佳选择。
reveal [rɪ'viːl]:vt. 显示,透露,揭露,泄露 n. 揭露,暴露,门侧,窗侧
Table 4 Comparisons of different combinations of multi-scale feature representations defined in Sec. 3.2. ϕ 2 \phi_{2} ϕ2, ϕ 3 \phi_{3} ϕ3, ϕ 4 \phi_{4} ϕ4 and ϕ 5 \phi_{5} ϕ5 represent the output of stage 2, 3, 4 and 5 of a backbone network, respectively. Bold numbers indicate the best results.

4.3 Comparison with the State of the Arts
4.3.1 Pedestrian Detection
Caltech. The proposed method are extensively compared with the state of the arts on three settings: Reasonable, All and Heavy Occlusion. As shown in Fig. 4, CSP achieves M R − 2 MR^{-2} MR−2 of 4.5% on the Reasonable setting, which outperforms the best competitor (5.0 of RepLoss [48]) by 0.4%. When the model is initialized from CityPersons[55], CSP also achieves a new state of the art of 3.8%, compared to 4.0% of RepLoss [48], 4.1% of OR-CNN [56], and 4.5% of ALFNet [28]. It presents the superiority on detecting pedestrians of various scales and occlusion levels as demonstrated in Fig . 4 (b). Moreover, Fig. 4 (c) shows that CSP also performs very well for heavily occluded pedestrians, outperforming RepLoss [48] and OR-CNN [56] which are explicitly designed for occlusion cases.
Caltech. 提出的方法在三个设置上与现有技术进行了广泛的比较:Reasonable、全部和严重遮挡。如图 4 所示,CSP 在合理设置下达到 4.5% 的 M R − 2 MR^{-2} MR−2,优于最佳竞争者 (5.0 of RepLoss [48]) 0.4%。当模型从 CityPersons [55] 初始化时,CSP 也达到了 3.8% 的新技术水平,相比之下,RepLoss [48] 的 4.0%、OR-CNN [56] 的 4.1% 和 ALFNet [28] 的4.5%。它具有检测不同尺度和遮挡水平的行人的优势,如 Fig . 4 (b) 所示。此外,Fig. 4 (c) 显示 CSP 对于严重遮挡的行人也表现得非常好,优于 RepLoss [48] 和 OR-CNN [56],它们明确地设计用于遮挡情况。
superiority [suː,pɪərɪ'ɒrɪtɪ; sjuː-]:n. 优越,优势,优越性
occlusion [ə'kluːʒ(ə)n]:n. 闭塞,吸收,锢囚锋
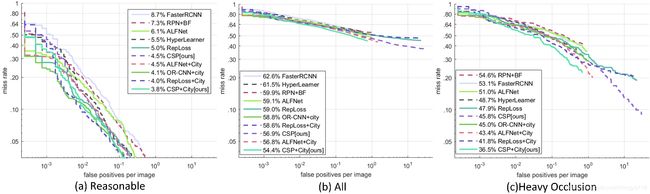
Fig. 4 Comparisons with the state of the arts on Caltech using new annotations.
CityPersons. Table 5 shows the comparisons with previous state of the arts on CityPersons. Besides the reasonable subset, following [48], we also evaluate on three subsets with different occlusion levels, and following [55], results on three subsets with various scale ranges are also included. It can be observed that CSP beats the competitors and performs fairly well on occlusion cases even without any specific occlusion-handling strategies [48,56]. On the Reasonable subset, CSP with offset prediction achieves the best performance, with a gain of 1.0% M R − 2 MR^{-2} MR−2 upon the closest competitor (ALFNet [28]), while the speed is comparable on the same running environment with 0.33 second per image of 1024x2048 pixels.
CityPersons. Table 5 shows the comparisons with previous state of the arts on CityPersons. 除了 reasonable subset,在 [48] 之后,我们还评估了具有不同遮挡水平的三个子集,并且在 [55] 之后,还包括具有不同尺度范围的三个子集的结果。可以观察到,即使没有任何特定的遮挡处理策略,CSP 也能击败竞争对手并在遮挡情况下表现相当好 [48,56]。 在 Reasonable subset 上,具有偏移预测的 CSP 实现了最佳性能,相比最接近的竞争对手 (ALFNet [28]) 的增益为 1.0% M R − 2 MR^{-2} MR−2,而速度在相同的运行环境中具有可比性,每个 1024x2048 像素的图像运行 0.33 秒。
bare [beə]:adj. 空的,赤裸的,无遮蔽的 vt. 露出,使赤裸
Table 5 Comparison with the state of the arts on CityPersons [55]. Results test on the original image size (1024x2048 pixels) are reported. Red and green indicate the best and second best performance.

4.3.2 Face Detection
WiderFace. The model trained on the training subset of WiderFace are evaluated on both the validation and test subsets, and the multi-scale testing is also performed in a similar way as in [44]. Comparisons with the state-of-the-art face detectors on WiderFace are shown in Fig. 5. It can be seen that the proposed CSP detector achieves competitive performance among the state-of-the-art face detectors across the three subsets, i.e. 90.7% (Hard), 95.2% (Medium) and 96.1% (Easy) on validation subset, and 89.9% (Hard), 94.4% (Medium) and 94.9% (Easy) on test subset. Note that most of these face detectors are anchor box based. Therefore, the results indicate a superiority of the proposed CSP detector when complex default anchor box design and anchor box matching strategies are abandoned.
WiderFace. 在验证和测试子集上评估在 WiderFace 的训练子集上训练的模型,并且还以与 [44] 中类似的方式执行多尺度测试。与 WiderFace 上最先进的面部检测器的比较如图 5 所示。可以看出,所提出的 CSP 检测器在三个子集中与最先进的面部检测器之间实现了相近性能,即验证子集为 90.7% (难),95.2% (中) 和 96.1% (易),测试子集为 89.9% (难),94.4% (中) 和 94.9% (易)。请注意,大多数这些面部检测器都是基于锚框的。因此,结果表明,当放弃复杂的默认锚框设计和锚框匹配策略时,所提出的 CSP 检测器具有优越性。
abandon [ə'bænd(ə)n]:v. 遗弃,离开,放弃,终止,陷入 n. 放任,狂热

Fig. 5 Precision-recall curves on WIDER FACE validation and testing subsets
curve [kɜːv]:n. 曲线,弯曲,曲线球,曲线图表 vt. 弯,使弯曲 vi. 成曲形 adj. 弯曲的,曲线形的
4.4 Generalization ability of the proposed method
To further demonstrate the generalization ability of the proposed CSP detector, we perform cross-dataset evaluation on two tasks, i.e. pedestrian detection and face detection. Specifically, models trained on the source dataset are directly tested on the target dataset without further finetuning.
为了进一步证明所提出的 CSP 检测器的泛化能力,我们对两个任务进行交叉数据集评估,即行人检测和面部检测。 具体而言,在源数据集上训练的模型直接在目标数据集上进行测试,而无需进一步微调。
4.4.1 Cross-dataset evalutaion for Pedestrian Detection
For pedestrian detection, we compare the proposed CSP detector with the state-of-the-art anchor box based pedestrian detector (ALFNet [28]). Both of the two detectors are trained on the CityPersons [55] training subset and then are directly tested on the Caltech [8] test subset. For ALFNet [28], we use the source code and models provided by the authors 3. Results shown in Table 6 are based on the reasonable setting, and the evaluation metric is Miss Rate (MR). It can be seen that the gap between the two detectors on the source dataset (CityPersons) is merely 1%, but the gap on the target dataset (Caltech) increases to 5.9%, which gives the evidence that the proposed CSP detector generalizes better to another dataset than the anchor box based competitor, i.e. ALFNet [28].
对于行人检测,我们将提出的 CSP 检测器与最先进的基于锚框的行人检测器 (ALFNet [28]) 进行比较。两个检测器都在 CityPersons [55] 训练子集上训练,然后直接在 Caltech [8] 测试子集上进行测试。对于 ALFNet [28],我们使用作者提供的源代码和模型3。表 6 中显示的结果基于合理的设置,评估度量是 Miss Rate (MR)。可以看出,源数据集 (CityPersons) 上两个检测器之间的差距仅为 1%,但目标数据集 (Caltech) 上的差距增加到 5.9%,这证明了相比于基于锚框的 ALFNet [28],所提出的 CSP 检测器更好地推广到另一个数据集。
Table 6 Comparisons of the generalization ability for pedestrian detection (Evaluation metric: Miss Rate; the lower, the better).

3https://github.com/liuwei16/ALFNet
4.4.2 Cross-dataset evalutation for Face Detection
For face detection, models trained on the WiderFace [51] training subset are directly tested on three other face detection datasets, i.e. FDDB [14], UCCS [1] and DarkFace [49]. Detailed statistics about these three datasets for testing are listed in Table 7. It can be seen that these three datasets exhibit a large difference in the mean size of face objects.
对于面部检测,在 WiderFace [51] 训练子集上训练的模型直接在三个其他面部检测数据集上进行测试,即 FDDB [14],UCCS [1] 和 DarkFace [49]。表 7 中列出了关于这三个测试数据集的详细统计数据。可以看出,这三个数据集在面部目标的平均大小上表现出很大的差异。
exhibit [ɪg'zɪbɪt; eg-]:vt. 展览,显示,提出 n. 展览品,证据,展示会 vi. 展出,开展览会
Table 7 Statistics of three face detection datasets for cross-dataset evaluation.

FDDB [14] is also a widely adopted face detection benchmark. Comparisons with other advanced face detectors on this benchmark are reported in Fig. 6, results of other face detectors are from FDDB’s official website4. As shown in Fig. 6, the proposed CSP detector achieves competitive results on both discontinuous and continuous ROC curves, with the true positive rate of 99.2% and 86.0% when the number of false positives equals to 1000, while the results of the most recent anchor box based face detector (DSFD [19]) are 99.1% and 86.2%, respectively. Since face images of both FDDB and WiderFace are obtained from the Internet, they are basically similar. Therefore, both CSP and DSFD detectors trained on WiderFace perform quite good on FDDB, and there is little performance difference between them.
FDDB [14] 也是一种广泛采用的面部检测基准数据集。在该基准数据集上与其他先进面部检测器的比较见图 6,其他面部检测器的结果来自 FDDB 的官方网站4。如图 6 所示,所提出的 CSP 检测器在不连续和连续 ROC 曲线上都获得了有竞争力的结果,当 false positive 等于 1000 时,true positive rate 为 99.2% 和 86.0%,而最近的基于锚框的面部检测器 (DSFD [19]) 分别为 99.1% 和 86.2%。由于 FDDB 和 WiderFace 的面部图像都是从 Internet 获得的,因此它们基本相似。因此,在 WiderFace 上训练的 CSP 和 DSFD 检测器在 FDDB 上表现相当不错,并且它们之间几乎没有性能差异。
WiderFace 人脸检测数据集上实验,尺度采用了高度 + 宽度预测,因为 WiderFace 的人脸标注是包含各种变化的宽高比的。
DSFD 是基于锚框的面部检测器的优秀代表,其一大贡献就是改进了锚点框的匹配策略。但对比跨库测试结果可以看出,在一个库上采用的锚框配置,离开这个库可能会存在已配置好的锚框的适用性问题。而 CSP 是简单地预测目标中心和尺度,无预设的锚框配置,因此相对而言能更好地适应不同的场景或数据集。
4http://vis-www.cs.umass.edu/fddb/results.html
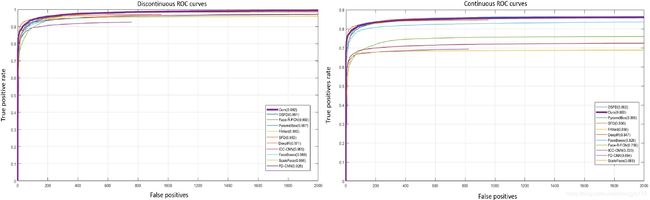
Fig. 6 Comparisons of ROC results on the FDDB dataset.
However, when evaluated on the other two quite different face datasets, UCCS [1] and DarkFace [49], it is interesting to see some difference. UCCS [1], with the full name of UnConstrained College Students (UCCS), is a recently published dataset collected by a long-range high-resolution surveillance camera. The significant difference between UCCS [1] and other face detection datasets is that the data are collected unconstrainedly in surveillance scenes. People walking on the sidewalk did not aware that they were being recorded. As the annotations of the test subset is publicly unavailable, results on the validation subset are reported.
然而,当在另外两个截然不同的面部数据集 UCCS [1] 和 DarkFace [49] 上进行评估时,看到一些差异很有意思。 UCCS [1] 全称为 UnConstrained College Students (UCCS),是由远程高分辨率监控摄像机收集的最近发布的数据集。 UCCS [1] 和其他面部检测数据集之间的显着差异在于,在监控场景中无限制地收集数据。在人行道上行走的人并不知道他们正在被录像。由于测试子集的标注是公开不可用的,因此报告验证子集的结果。
unconstrained [ʌnkən'streɪnd]:adj. 不勉强的,非强迫的,不受约束的
sidewalk ['saɪdwɔːk]:n. 人行道
DarkFace [49] is a recently published face detection dataset collected during nighttime, which exhibits an extreme light condition compared to other face detection datasets. The average size of the face objects in this dataset is merely 16x17 pixels. In the official website5, it totally released 6000 images, on which we test both models and report the results.
DarkFace [49] 是最近发布的夜间面部检测数据集,与其他面部检测数据集相比,它具有极端光照条件。此数据集中面部物体的平均大小仅为 16x17 像素。在官方网站5中,它完全发布了 6000 张图像,我们在其上测试两种模型并报告结果。
5https://flyywh.github.io/CVPRW2019LowLight/
For UCCS [1] and DarkFace [49], we compare the proposed CSP with the state-of-the-art anchor box based face detector (DSFD [19]). For DSFD, we use the source code and models provided by the authors6. Results are given in Table 8, and the evaluation metric is the Average Precision (AP). As can be seen from Table 8, though the proposed CSP slightly underperforms DSFD on the WiderFace test subset, it achieves a significant gain over DSFD on these two cross-dataset evaluations, with 3.7% and 2.1% on UCCS [1] and DarkFace [49], respectively. Due to the substantial domain gaps between UCCS, DarkFace and WiderFace, both models trained on WiderFace perform unsurprisingly poor on UCCS and DarkFace, but the proposed CSP detector still outperforms the anchor box based DSFD, which gives the evidence that CSP generalizes better to unknown domains than the anchor box based competitor. It is possible that the default configurations of anchor boxes in anchor-based detectors can not adapt to new scenes especially when the scales and aspect ratios of objects have a large difference as shown in Table 7. In contrast, the proposed detector simply predicts the centers and scales of objects without any considerations of priors of the objects in the dataset, thus shows a better generalization ability.
对于 UCCS [1] 和 DarkFace [49],我们将提出的 CSP 与最先进的基于锚框的面部检测器 (DSFD [19]) 进行比较。对于 DSFD,我们使用作者提供的源代码和模型6。结果在表 8 中给出,评估度量是平均精度 (AP)。从表 8 中可以看出,尽管提出的 CSP 在 WiderFace 测试子集上略微低于 DSFD,但在这两个交叉验证数据集评估中,它比 DSFD 获得了显著的增益,在 UCCS [1] 和 DarkFace 上分别有 3.7% 和 2.1% [49],分别。由于 UCCS、DarkFace 和 WiderFace 之间存在巨大的领域差距,在 WiderFace 上训练的两个模型在 UCCS 和 DarkFace 上都表现不尽如人意,但是提出的 CSP 检测器仍然优于基于锚框的 DSFD,这证明了 CSP 相比基于锚框的检测器更好地推广到未知领域。基于锚框的检测器中锚定框的默认配置可能无法适应新场景,尤其是当物体的尺度和宽高比具有较大差异时,如表 7 所示。相比之下,所提出的检测器只是预测中心和物体的比例,而不考虑数据集中物体的先验,因此显示出更好的泛化能力。
6https://github.com/TencentYoutuResearch/FaceDetection-DSFD
Table 8 Comparisons on generalization ability of face detectors (Evaluation metric: Average Precision (AP); the higher, the better).

4.5 Discussions
Note that CSP only requires object centers and scales for training, though generating them from bounding box or central line annotations is more feasible since centers are not always easy to annotate. Besides, the model may be puzzled on ambiguous centers during training. To demonstrate this, we also conduct an ablative experiment on Caltech, in which object centers are randomly disturbed in the range of [0, 4] and [0, 8] pixels during training. From the results shown in Table 9, it can be seen that performance drops with increasing annotation noise. For Caltech, we also apply the original annotations but with inferior performance to TLL [43], which is also box-free. A possible reason is that TLL includes a series of post-processing strategies in keypoint pairing. For evaluation with tight annotations based on central lines, as results of TLL on Caltech are not reported in [43], comparison to TLL is given in Table 5 on the CityPersons, which shows the superiority of CSP. Therefore, the proposed method may be limited for annotations with ambiguous centers, e.g. the traditional pedestrian bounding box annotations affected by limbs. In view of this, it may also be not straightforward to apply CSP to generic object detection without further improvement or new annotations.
请注意,CSP 仅需要物体中心和尺度用于训练,尽管从边界框或中心线标注生成它们更加可行,因为中心并不总是易于标注。此外,在训练期间,模型可能会对模糊中心感到困惑。为了证明这一点,我们还对 Caltech 数据集进行了一项销蚀实验,其中物体中心在训练期间随机扰动 [0, 4] 和 [0, 8] 像素范围。从表 9 中所示的结果可以看出,性能随着标注噪声的增加而下降。对于 Caltech 数据集,我们也应用原始标注但性能较差的 TLL [43],也是 box-free 的。可能的原因是 TLL 在关键点配对中包括一系列后处理策略。对于基于中心线的紧密标注的评估,由于 [43] 中没有报道 Caltech 数据集上的 TLL 结果,因此在 CityPersons 数据集的表 5 中给出了与 TLL 的比较,其显示了 CSP 的优越性。因此,所提出的方法可能受限于具有模糊中心的标注,例如,受四肢影响的传统行人边界框标注。鉴于此,在没有进一步改进或新标注的情况下将 CSP 应用于通用物体检测也可能不是直截了当的。
feasible ['fiːzɪb(ə)l]:adj. 可行的,可能的,可实行的
disturb [dɪ'stɜːb]:vt. 打扰,妨碍,使不安,弄乱,使恼怒 vi. 打扰,妨碍
inferior [ɪn'fɪərɪə]:adj. 差的,自卑的,下级的,下等的 n. 下级,次品
limb [lɪm]:n. 肢,臂,分支,枝干 vt. 切断...的手足,从...上截下树枝
disturbance [dɪ'stɜːb(ə)ns]:n. 干扰,骚乱,忧虑
Table 9 Performance drop with disturbances of the centers.

When compared with anchor box based methods, the advantage of CSP lies in two aspects. Firstly, CSP does not require tedious configurations on anchor boxes specifically for each dataset. Secondly, anchor box based methods detect objects by overall classifications of each anchor box where background information and occlusions are also included and will confuse the detector’s training. However, CSP overcomes this drawback by scanning for pedestrian centers instead of boxes in an image, thus is more robust to occluded objects.
与基于锚框的方法相比,CSP 的优势在于两个方面。首先,CSP 不需要专门针对每个数据集的锚框进行繁琐配置。其次,基于锚框的方法通过每个锚框的整体分类来检测物体,其中还包括背景信息和遮挡,并且将使检测器的训练混淆。然而,CSP 通过扫描行人中心而不是图像中的 boxes 来克服这个缺点,因此对于被遮挡的物体更加鲁棒。
CSP 的小目标检测能力得益于大分辨率的特征图。而对于遮挡,传统的基于密集滑窗或者基于 Faster R-CNN、采用感兴趣区域池化 (ROI Pooling) 的检测器,本质上都是对目标区域的一个整体判断的分类器,因此目标区域的遮挡和背景等信息是包含在其整体判断里的。而本文提出的 CSP 对目标在哪里和有多大进行了解离,在热图上只检测中心点,尺度大小是额外预测的,因此受遮挡的影响相对较小。
5 Conclusion
Inspired from the traditional feature detection task, we provide a new perspective where pedestrian detection is motivated as a high-level semantic feature detection task through straightforward convolutions for center and scale predictions. This way, the proposed method enjoys box-free settings and is also free from complex postprocessing strategies as in recent keypoint-pairing based detectors. As a result, the proposed CSP detector achieves the new state-of-the-art performance on two challenging pedestrian detection benchmarks, namely CityPersons and Caltech. Due to the general structure of the CSP detector, we further evaluate it for face detection on the most popular face detection benchmark, i.e. WiderFace. The comparable performance to other advanced anchor box based face detectors also shows the proposed CSP detector’s competitiveness. Besides, experiments on cross-dataset evaluation for both pedestrian detection and face detection further demonstrate CSP’s superior generalization ability over anchor box based detectors. For future possibilities, it is interesting to further explore CSP’s capability in general object detection. Given its superiority on cross-dataset evaluation, it is also interesting to see CSP’s potential when domain adaptation techniques are further explored.
受传统特征检测任务的启发,我们提供了一种新的视角,将行人检测作为高级语义特征检测任务通过直接卷积进行中心和尺度预测。这样,所提出的方法享有 box-free 设置,并且也没有像最近基于关键点配对的检测器那样的复杂后处理策略。因此,提出的 CSP 检测器在两个具有挑战性的行人检测基准数据集上实现了最新的最先进性能,即 CityPersons and Caltech。由于 CSP 检测器的一般结构,我们进一步评估它在最流行的面部检测基准数据集上的面部检测,即 WiderFace。与其他先进的基于锚框的面部检测器相比,其性能也表明了所提出的 CSP 检测器的竞争力。此外,行人检测和面部检测的跨数据集评估实验进一步证明了 CSP 比基于锚框的检测器具有更强的泛化能力。对于未来的可能性,有趣的是进一步探索 CSP 在一般物体检测方面的能力。鉴于其在跨数据集评估方面的优势,当进一步探索领域适应技术时,看到 CSP 的潜力也很有趣。
possibility [,pɒsɪ'bɪlɪtɪ]:n. 可能性,可能发生的事物
grant [grɑːnt]:vt. 授予,允许,承认 vi. 同意 n. 拨款,授予物
Acknowledgements This work was partly supported by the National Key Research and Development Plan (Grant No.2016YFC0801003), the NSFC Project #61672521, the NLPR Independent Research Project #Z-2018008, and the IIAI financial support.
National Natural Science Foundation of China,NSFC:国家自然科学基金委员会
National Laboratory of Pattern Recognition,NLPR:模式识别国家重点实验室
National Key Research and Development Plan:国家重点研发计划
References
[1] https://vast.uccs.edu/Opensetface/
[18] CornerNet: Detecting Objects as Paired Keypoints
[19] [DSFD: Dual Shot Face Detector](DSFD: Dual Shot Face Detector)
[24] Focal Loss for Dense Object Detection
[28] Learning Efficient Single-stage Pedestrian Detectors by Asymptotic Localization Fitting
[43] Small-scale Pedestrian Detection Based on Somatic Topology Localization and Temporal Feature Aggregation
[44] PyramidBox: A Context-assisted Single Shot Face Detector
[49] Deep Retinex Decomposition for Low-Light Enhancement
[53] How Far are We from Solving Pedestrian Detection?
[54] Towards Reaching Human Performance in Pedestrian Detection
[55] CityPersons: A Diverse Dataset for Pedestrian Detection
[61] Edge Boxes: Locating Object Proposals from Edges