一、搭建时的环境:
kafka_2.10-0.9.0.1.tgz
zookeeper-3.4.6.tar.gz
jdk-7u25-linux-x64.gz
CentOS 6.5
二、搭建zookeeper集群启动起来
大家可以参考我之前的博客
zookeeper集群搭建实战:https://my.oschina.net/u/2489417/blog/778600
三、搭建kafka集群
1:下载解压
下载 kafka_2.10-0.9.0.1.tgz ,官网下载Kafka地址http://kafka.apache.org/downloads.html
(注意这里最好下载scala2.10版本的kafka,因为scala2.10版本的兼容性比较好和2.11版本差别太大)

解压命令:
tar -zxvf kafka_2.10-0.9.0.1.tgz
2:修改配置文件
cd /usr/local/kafka_2.10-0.9.0.1/config/
vim server.properties
配置broker.id从0开始,后面其他节点配置1,2,3,4等等
事先启动zookeeper集群,这里配置zookeeper集群的地址
zookeeper.connect=wbx1:2181,wbx2:2181,wbx3:2181
修改见如下图:
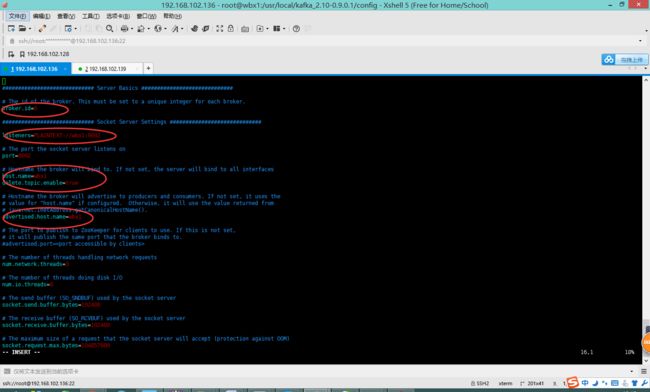

这里注意其它机器修改

3:启动kafka
修改完配置以后在每个节点启动kafka
bin目录下启动
./kafka-server-start.sh -daemon ../config/server.properties
这时 每台机器打上 jps命令 都可以看到kafka进程

4:新建一个topic,准备测试
a:新建一个topic
topic名为test ,一个拥有2个副本5个分区的topic:(副本数量不能超过broker的个数)
bin目录 运行下面指令
./kafka-topics.sh -zookeeper wbx1:2181,wbx2:2181,wbx3:2181 -topic test -replication-factor 2 -partitions 5 -create
![]()
b:查看每个节点的信息
现在我们搭建了一个集群,怎么知道每个节点的信息呢?运行“"describe topics”命令就可以了:
./kafka-topics.sh --describe --zookeeper wbx1:2181 --topic test
下面解释一下这些输出。第一行是对所有分区的一个描述,然后每个分区都会对应一行。
- Leader:负责处理消息的读和写,leader是从所有节点中随机选择的.
- Replicas:列出了所有的副本节点,不管节点是否在服务中.
- Isr:是正在服务中的节点.
c:查看当前的topic
bin目录下执行下面命令
./kafka-topics.sh -zookeeper wbx1:2181,wbx2:2181,wbx3:2181 -list![]()
5:测试 向topic发送消息
a:在provider输入信息
在一个节点创建一个provider 这里在wbx3创建
./kafka-console-producer.sh --broker-list wbx1:9092,wbx2:9092,wbx3:9092 --topic test
b:在consumer能接收到信息
在另外一个节点创建一个consumer 这里在wbx2里创建 wbx1也可以创建 也可以收到信息
./kafka-console-consumer.sh --zookeeper wbx:2181,wbx2:2181,wbx3:2181 --from-beginning -topic test![]()
6:kafka监控工具
详情可见博客:http://www.cnblogs.com/Leo_wl/p/4564699.html
a:下载
在安装KafkaOffsetMonitor管理平台时,我们需要先下载其安装包,其资源可以在Github上找到
源码地址:
https://github.com/quantifind/KafkaOffsetMonitor
jar包地址:
https://github.com/quantifind/KafkaOffsetMonitor/releases/tag/v0.2.1
b:编写启动脚本
新建一个启动脚本,执行如下命令:
touch start.sh
赋予权限 命令:
chmod +x start.sh
编辑脚本:
vim start.sh
java -cp KafkaOffsetMonitor-assembly-0.2.0.jar \
com.quantifind.kafka.offsetapp.OffsetGetterWeb \
--zk wbx1:2181,wbx2:2181,wbx3:2181 \
--port 8089 \
--refresh 10.seconds \
--retain 1.days
c:启动kafkaMonitor
./start.sh

d:访问web
http://192.168.102.136:8089/
四、kafka原理详解
1: 基本概念
节点服务器(Broker):或缓存代理,Kafka集群包含一个或多个服务器,这种服务器被称为broker。
主题(Topic):一个主题类似新闻中的体育、娱乐等分类概念,实际工程中一个业务一个主题。
分区(Partition):一个topic中的消息数据按照多个分区组织,分区是kafka消息队列的最小单位,一个分区可以看做是一个FIFO的队列。将topic下的message存储到不同的partition下,目的是为了提高并行性.
偏移量(offset):kafka集群会将每个topic进行分区,每个分区都是一个排序且不可改变的队列,新的消息会进入队尾并分配一个唯一ID,官方称之为偏移量(offset,即元信息在topic中的位置)。
Leader:负责此partition的读写操作,每个broker都有可能成为某partition的leader
Replicas:副本,即此partition在那几个broker上有备份,不管broker是否存活
Isr:存活的replicas
作为Leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定。
2:工作原理
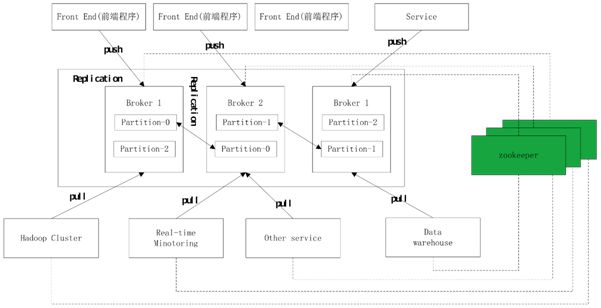
A 每个partition会创建3个备份replica,并分配到broker集群中; --replication-factor3
B 用zookeeper来管理,consumer、producer、broker的活动状态;
C分配的每个备份replica的id和broker的id保持一致;
D 对每个partition,会选择一个broker作为集群的leader。
3:kafka特性

- 高吞吐量是其核心设计之一。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
- 数据磁盘持久化:消息不在内存中cache,直接写入到磁盘,充分利用磁盘的顺序读写性能。
- zero-copy:减少IO操作步骤。
- 支持数据批量发送和拉取。
- 支持数据压缩。
- Topic划分为多个partition,提高并行处理能力。
4:使用场景
A 站点用户活动追踪:页面浏览,搜索,点击;
B 用户/管理员网站操作的监控;
C 日志处理;
5:分布式队列的对比
|
|
ActiveMQ |
RabbitMQ |
Kafka |
| 所属社区/公司 |
Apache |
MozillaPublicLicense |
Apache/LinkedIn |
| 开发语言 |
Java |
Erlang |
Scala |
| 支持的协议 |
AMQP、OpenWire、STOMP、REST、XMPP |
AMQP |
仿AMQP |
| 事务 |
支持 |
不支持 |
不支持 |
| 集群 |
支持 |
支持 |
支持 |
| 负载均衡 |
支持 |
支持 |
支持 |
| 动态扩容 |
不支持 |
不支持 |
支持 |
AMQP协议
Advanced Message Queuing Protocol (高级消息队列协议)
The Advanced Message Queuing Protocol (AMQP):是一个标准开放的应用层的消息中间件(Message Oriented Middleware)协议。AMQP定义了通过网络发送的字节流的数据格式。因此兼容性非常好,任何实现AMQP协议的程序都可以和与AMQP协议兼容的其他程序交互,可以很容易做到跨语言,跨平台。
Kafka与传统消息系统相比,有以下不同:
- 它被设计为一个分布式系统,易于向外扩展;
- 它同时为发布和订阅提供高吞吐量;
- 它支持多订阅者,当失败时能自动平衡消费者;
- 它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。
五:性能优化
配置优化都是修改server.properties文件中参数值。
1网络和io操作线程配置优化
# broker处理消息的最大线程数
num.network.threads=xxx
# broker处理磁盘IO的线程数
num.io.threads=xxx
建议配置:
一般num.network.threads主要处理网络io,读写缓冲区数据,基本没有io等待,配置线程数量为cpu核数加1.
num.io.threads主要进行磁盘io操作,高峰期可能有些io等待,因此配置需要大些。配置线程数量为cpu核数2倍,最大不超过3倍.
2log数据文件刷新策略
为了大幅度提高producer写入吞吐量,需要定期批量写文件。
建议配置:
# 每当producer写入10000条消息时,刷数据到磁盘
log.flush.interval.messages=10000
# 每间隔1秒钟时间,刷数据到磁盘
log.flush.interval.ms=1000
3日志保留策略配置
当kafkaserver被写入海量消息后,会生成很多数据文件,且占用大量磁盘空间,如果不及时清理,可能磁盘空间不够用,
kafka默认是保留7天。
建议配置:
# 保留三天,也可以更短
log.retention.hours=72
# 段文件配置1GB,有利于快速回收磁盘空间,重启kafka加载也会加快(如果文件过小,则文件数量比较多,
# kafka启动时是单线程扫描目录(log.dir)下所有数据文件)
log.segment.bytes=1073741824
在kafka的核心思路中,不需要在内存里缓存数据,因为操作系统的文件缓存已经足够完善和强大,只要不做随机写,顺序读写的性能是非常高效的。kafka的数据只会顺序append,数据的删除策略是累积到一定程度或者超过一定时间再删除。kafka另一个独特的地方是将消费者信息保存在客户端而不是MQ服务器,这样服务器就不用记录消息的投递过程,每个客户端都自己知道自己下一次应该从什么地方什么位置读取消息,消息的投递过程也是采用客户端主动pull的模型,这样大大减轻了服务器的负担。kafka还强调减少数据的序列化和拷贝开销,它会将一些消息组织成MessageSet做批量存储和发送,并且客户端在pull数据的时候,尽量以zero-copy的方式传输,利用sendfile(对应java里的FileChannel.transferTo/transferFrom)这样的高级IO函数来减少拷贝开销。可见,kafka是一个精心设计,特定于某些应用的MQ系统,这种偏向特定领域的MQ系统会越来越多,垂直化的产品策略值的考虑。
只要磁盘没有限制并且不出现损失,kafka可以存储相当长时间的消息(一周),Kafka在提高效率方面做了很大努力。Kafka的一个主要使用场景是处理网站活动日志,吞吐量是非常大的,每个页面都会产生好多次写操作。读方面,假设每个消息只被消费一次,读的量的也是很大的,Kafka也尽量使读的操作更轻量化。
我们之前讨论了磁盘的性能问题,线性读写的情况下影响磁盘性能问题大约有两个方面:太多的琐碎的I/O操作和太多的字节拷贝。I/O问题发生在客户端和服务端之间,也发生在服务端内部的持久化的操作中。
六:实际开发中问题处理
未完待续