std::search算法原理图解
严正声明:本文系作者davidhopper原创,未经许可,不得转载。
一、std::search算法原理
std::search算法定义于头文件C++ 17标准中提出的执行策略,也不考虑使用自定义的二元谓词(binary predicate,即接受两个参数,返回值类型为bool的函数或仿函数,形如:bool pred(const Type1 &a, const Type2 &b);,a和b相等时,返回true),函数模板定义如下:
template< class ForwardIt1, class ForwardIt2 >
ForwardIt1 search( ForwardIt1 first, ForwardIt1 last,
ForwardIt2 s_first, ForwardIt2 s_last );
更为详细的函数模板定义参考std::search网页。
上述函数模板的含义是:在前向迭代器(std::string、std::vector、std::list、std::deque、std::set、std::map等常见容器均满足该条件)容器区间[first, last)(左闭右开,即first是开始位置,last是结束位置的下一个位置)中,寻找子序列[s_first, s_last)首次出现的位置(实际寻找范围为[first, last - (s_last - s_first))),并将该位置以迭代器的形式返回。若找不到这种子序列,则返回 last ;若[s_first, s_last)为空,则返回first。算法的时间复杂度为S*N(最坏情形),其中 S = std::distance(s_first, s_last),而N = std::distance(first, last)。
可能的实现代码如下:
template <class ForwardIt1, class ForwardIt2>
ForwardIt1 search(ForwardIt1 first, ForwardIt1 last, ForwardIt2 s_first,
ForwardIt2 s_last) {
std::size_t s_num = std::distance(s_first, s_last);
for (;; ++first) {
if (std::distance(first, last) < s_num) {
return last;
}
ForwardIt1 it = first;
for (ForwardIt2 s_it = s_first;; ++it, ++s_it) {
if (s_it == s_last) {
return first;
}
if (it == last) {
return last;
}
if (!(*it == *s_it)) {
break;
}
}
}
}
实现代码非常简洁,下面以图解方式进行解释。
先看第一幅图:
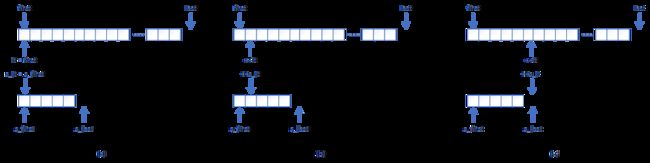
步骤一:
如(a)所示,首先将first指向容器区间[first, last)的首个位置,即容器区间范围为[first, last),若容器区间[first, last)的长度小于std::distance(s_first, s_last),往后搜索已无法满足遍历子序列[s_first, s_last)的要求,此时表明在容器区间[first, last)中找不到匹配的子序列[s_first, s_last),返回last。
将it指向first,s_it指向s_first。若子序列[s_first, s_last)为空,即s_it == s_last,则直接返回first。
比较*it与*s_it,若二者相等,则执行(b),否则表明待搜索位置s_it与容器位置it的值不匹配,立即中断子序列[s_first, s_last)范围内的搜索迭代。
如(b)所示,将it和s_it均向前移一步,比较*it与*s_it,若二者相等,则继续执行(b),否则表明待搜索位置s_it与容器位置it的值不匹配,立即中断子序列[s_first, s_last)范围内的搜索迭代。
不断执行(b),直到如(c)所示,s_it抵达子序列[s_first, s_last)的终点s_last。此时表明子序列已遍历比较完毕,成功匹配,于是返回first即可。或者,s_it尚未抵达终点s_last,但it已抵达终点last,此时表明在容器区间[first, last)中找不到匹配的子序列[s_first, s_last),返回last。
在执行了:
if (std::distance(first, last) < s_num) {
return last;
}
语句后,上述加粗的条件理论上不会触及,但这里仍写出以作为安全冗余设计,下同,不再赘述。
接下图看第二幅图:
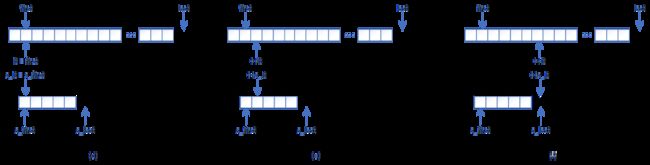
步骤二:
如(d)所示,将first向前移一步,即容器区间范围调整为[first_old+1, last),将it指向first,s_it指向s_first,比较*it与*s_it,若二者相等,则执行( e),否则表明待搜索位置s_it与容器位置it的值不匹配,立即中断子序列[s_first, s_last)范围内的搜索迭代。
如(e)所示,将it和s_it均向前移一步,比较*it与*s_it,若二者相等,则继续执行(e),否则表明待搜索位置s_it与容器位置it的值不匹配,立即中断子序列[s_first, s_last)范围内的搜索迭代。
不断执行(e),直到如(f)所示,s_it抵达子序列[s_first, s_last)的终点s_last。此时表明子序列已遍历比较完毕,成功匹配,于是返回first即可。或者,s_it尚未抵达终点s_last,但it已抵达终点last,此时表明在容器区间[first_old+1, last)中找不到匹配的子序列[s_first, s_last),返回last。
最后看第三幅图:
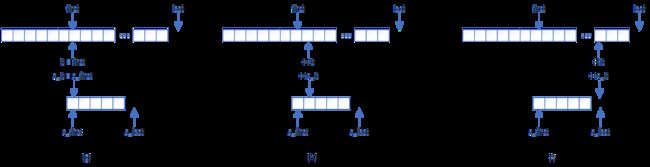
步骤三:
如(g)所示,不断将first向前移一步,即容器区间范围调整为[first_old+n, last),将it指向first,s_it指向s_first,比较*it与*s_it,若二者相等,则执行(h),否则表明待搜索位置s_it与容器位置it的值不匹配,立即中断子序列[s_first, s_last)范围内的搜索迭代。
如(h)所示,将it和s_it均向前移一步,比较*it与*s_it,若二者相等,则继续执行(h),否则表明待搜索位置s_it与容器位置it的值不匹配,立即中断子序列[s_first, s_last)范围内的搜索迭代。
不断执行(h),直到如(i)所示,s_it抵达子序列[s_first, s_last)的终点s_last。此时表明子序列已遍历比较完毕,成功匹配,于是返回first即可。或者,s_it尚未抵达终点s_last,但it已抵达终点last,此时表明在容器区间[first_old+n, last)中找不到匹配的子序列[s_first, s_last),返回last。
整个搜索过程对照示意图就非常容易理解。
二、std::search算法示例
示例参考std::search网页,如下所示:
#include 输出结果为:
true
false
true
false