linux 下载 命令 wget 和 curl
From:http://www.jb51.net/LINUXjishu/86326.html
From :Linux curl 命令详解 - http://www.cnblogs.com/duhuo/p/5695256.html
Linux curl 命令参数详解:http://www.aiezu.com/system/linux/linux_curl_syntax.html
Linux下使用 curl :http://www.cnblogs.com/xd502djj/archive/2012/06/12/2546737.html
Linux curl 命令详解:http://www.linuxdiyf.com/linux/2800.html
wget 和 curl
curl 和 wget 基础功能有诸多重叠,如 下载 等。
wget 和 cURL 都可以下载内容。它们的核心就是这么设计的。它们都可以向互联网发送请求并返回请求项。这可以是文件、图片或者是其他诸如网站的原始 HTML 之类。
这两个程序都可以进行 HTTP POST 请求。这意味着它们都可以向网站发送数据,比如说填充表单什么的。
由于这两者都是命令行工具,它们都被设计成可脚本化。wget 和 cURL 都可以写进你的 Bash 脚本 ,自动与新内容交互,下载所需内容。
curl 和 wget 区别:
- 1. curl 是 libcurl 这个库支持的,wget 是一个纯粹的命令行命令。
- 2. curl 在指定要下载的链接时能够支持 URL 的序列或集合,而 wget 则不能这样;
- 3. wget 支持 递归下载,而 curl 则没有这个功能。
- 4. curl 由于可自定义各种请求参数,所以在 模拟 web 请求 方面更擅长;cURL是一个多功能工具。当然,它可以下载网络内容,但同时它也能做更多别的事情。cURL 技术支持库是:libcurl。这就意味着你可以基于 cURL 编写整个程序,允许你基于 libcurl 库中编写图形环境的下载程序,访问它所有的功能。cURL 宽泛的网络协议支持可能是其最大的卖点。cURL 支持访问 HTTP 和 HTTPS 协议,能够处理 FTP 传输。它支持 LDAP 协议,甚至支持 Samba 分享。实际上,你还可以用 cURL 收发邮件。cURL 也有一些简洁的安全特性。cURL 支持安装许多 SSL/TLS 库,也支持通过网络代理访问,包括 SOCKS。这意味着,你可以越过 Tor 来使用cURL。cURL 同样支持让数据发送变得更容易的 gzip 压缩技术。
- 5. wget 由于支持 ftp 和 Recursive(递归)下载, 所以在下载文件方面更擅长。wget 简单直接。这意味着你能享受它超凡的下载速度。wget 是一个独立的程序,无需额外的资源库,更不会做其范畴之外的事情。wget 是专业的直接下载程序,支持递归下载。同时,它也允许你下载网页中或是 FTP 目录中的任何内容。wget 拥有智能的默认设置。它规定了很多在常规浏览器里的事物处理方式,比如 cookies 和重定向,这都不需要额外的配置。可以说,wget 简直就是无需说明,开罐即食!
类比的话,可以把 curl 看做是一个精简的命令行网页浏览器。它支持几乎你能想到的所有协议,curl 宽泛的网络协议支持可能是其最大的卖点(curl支持更多的协议。curl supports FTP, FTPS, HTTP, HTTPS, SCP, SFTP, TFTP, TELNET, DICT, LDAP, LDAPS, FILE, POP3, IMAP, SMTP and RTSP at the time of this writing. Wget supports HTTP, HTTPS and FTP.)。curl 支持访问 HTTP 和 HTTPS 协议,能够处理 FTP 传输。它支持 LDAP 协议,甚至支持 Samba 分享。实际上,你还可以用 cURL 收发邮件。curl 可以交互访问几乎所有在线内容。唯一和浏览器不同的是,curl 不会渲染接收到的相应信息。
而 wget 可以看做是 迅雷9 。
那你应该使用 cURL 还是使用 wget?
这个比较得看实际用途。如果你想快速下载并且没有担心参数标识的需求,那你应该使用轻便有效的 wget。如果你想做一些更复杂的使用,直觉告诉你,你应该选择 cRUL。
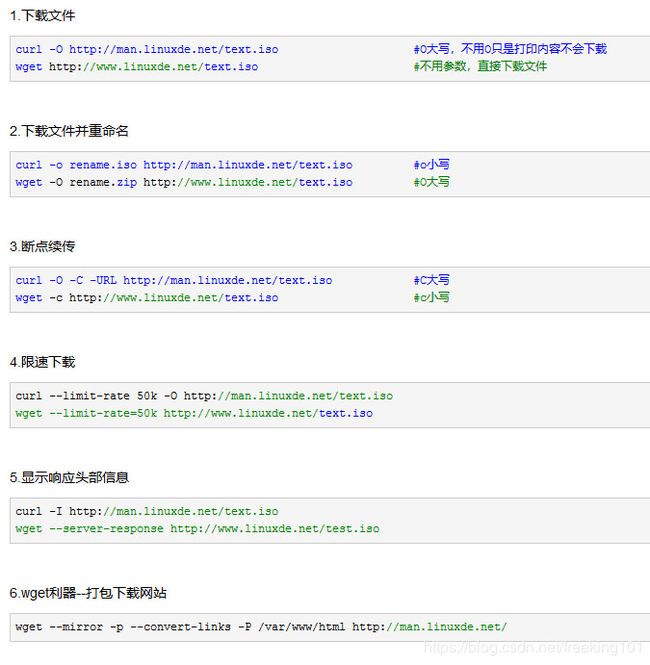
curl 与 wget 高级用法:https://jingyan.baidu.com/article/eb9f7b6d63f092869264e856.html
wget 命令
wget 是在 Linux 下开发的开放源代码的软件,作者是Hrvoje Niksic,后来被移植到包括 Windows 在内的各个平台上。 wget 是一个下载文件的工具,它用在命令行下。对于 Linux 用户是必不可少的工具,尤其对于网络管理员,经常要下载一些软件或从远程服务器恢复备份到本地服务器。
wget 工具体积小但功能完善,它支持断点下载功能,同时支持 FTP 和 HTTP下载方式,支持代理服务器和设置起来方便简单。
它有以下功能和特点:
- (1)支持断点下传功能;这一点,也是网络蚂蚁和FlashGet当年最大的卖点,现在,Wget也可以使用此功能,那些网络不是太好的用户可以放心了;
- (2)同时支持FTP和HTTP下载方式;尽管现在大部分软件可以使用HTTP方式下载,但是,有些时候,仍然需要使用FTP方式下载软件;
- (3)支持代理服务器;对安全强度很高的系统而言,一般不会将自己的系统直接暴露在互联网上,所以,支持代理是下载软件必须有的功能;
- (4)设置方便简单;可能,习惯图形界面的用户已经不是太习惯命令行了,但是,命令行在设置上其实有更多的优点,最少,鼠标可以少点很多次,也不要担心是否错点鼠标;
- (5)程序小,完全免费;程序小可以考虑不计,因为现在的硬盘实在太大了;完全免费就不得不考虑了,即使网络上有很多免费软件,但是,这些软件的广告不是我们喜欢的;
wget 参数
更多参数:man wget
wget -h 或者 wget --help
命令格式:
wget [参数列表] [目标软件、网页的网址] // 用法: wget [选项]... [URL]...
长选项所必须的参数在使用短选项时也是必须的。
启动:
-V, --version 显示 Wget 的版本信息并退出
-h, --help 打印此帮助
-b, --background 启动后转入后台
-e, --execute=命令 运行一个“.wgetrc”风格的命令
日志和输入文件:
-o, --output-file=文件 将日志信息写入 FILE
-a, --append-output=文件 将信息添加至 FILE
-d, --debug 打印大量调试信息
-q, --quiet 安静模式 (无信息输出)
-v, --verbose 详尽的输出 (此为默认值)
-nv, --no-verbose 关闭详尽输出,但不进入安静模式
--report-speed=类型 以 <类型> 报告带宽。类型可以是 bits
-i, --input-file=文件 下载本地或外部 <文件> 中的 URL
-F, --force-html 把输入文件当成 HTML 文件
-B, --base=URL 解析相对于 URL 的 HTML 输入文件链接 (-i -F)
--config=文件 指定要使用的配置文件
--no-cookies 不读取任何配置文件
--rejected-log=文件 将拒绝 URL 的原因写入 <文件>。
下载:
-t, --tries=数字 设置重试次数为 <数字> (0 代表无限制)
--retry-connrefused 即使拒绝连接也是重试
-O, --output-document=文件 将文档写入 FILE
-nc, --no-clobber 不要下载已存在将被覆盖的文件
-c, --continue 断点续传下载文件
--start-pos=偏移量 从由零计数的 <偏移量> 开始下载
--progress=类型 选择进度条类型
--show-progress 在任意啰嗦状态下都显示进度条
-N, --timestamping 只获取比本地文件新的文件
--no-if-modified-since 不要在时间戳 (timestamping) 模式下使用
if-modified-since get 条件请求
--no-use-server-timestamps don't set the local file's timestamp by
the one on the server
-S, --server-response 打印服务器响应
--spider 不下载任何文件
-T, --timeout=SECONDS 将所有超时设为 SECONDS 秒
--dns-timeout=SECS 设置 DNS 查寻超时为 SECS 秒
--connect-timeout=SECS 设置连接超时为 SECS 秒
--read-timeout=SECS 设置读取超时为 SECS 秒
-w, --wait=SECONDS 等待间隔为 SECONDS 秒
--waitretry=SECONDS 在获取文件的重试期间等待 1..SECONDS 秒
--random-wait 获取多个文件时,每次随机等待间隔 (0.5~1.5)*WAIT 秒
--no-proxy 禁止使用代理
-Q, --quota=数字 设置获取配额为 <数字> 字节
--bind-address=ADDRESS 绑定至本地主机上的 ADDRESS (主机名或是 IP)
--limit-rate=RATE 限制下载速率为 RATE
--no-dns-cache 关闭 DNS 查询缓存
--restrict-file-names=系统 限定文件名中的字符为 <系统> 允许的字符
--ignore-case 匹配文件/目录时忽略大小写
-4, --inet4-only 仅连接至 IPv4 地址
-6, --inet6-only 仅连接至 IPv6 地址
--prefer-family=地址族 首先连接至指定家族(IPv6,IPv4 或 none)的地址
--user=用户 将 ftp 和 http 的用户名均设置为 <用户>
--password=密码 将 ftp 和 http 的密码均设置为 <密码>
--ask-password 提示输入密码
--no-iri 关闭 IRI 支持
--local-encoding=ENC 使用 ENC 作为 IRI (国际化资源标识符) 的本地编码
--remote-encoding=ENC 使用 ENC 作为默认远程编码
--unlink 覆盖前移除文件
目录:
-nd, --no-directories 不创建目录
-x, --force-directories 强制创建目录
-nH, --no-host-directories 不要创建主 (host) 目录
--protocol-directories 在目录中使用协议名称
-P, --directory-prefix=前缀 保存文件到 <前缀>/..
--cut-dirs=数字 忽略远程目录中 <数字> 个目录层。
HTTP 选项:
--http-user=用户 设置 http 用户名为 <用户>
--http-password=密码 设置 http 密码为 <密码>
--no-cache 不使用服务器缓存的数据。
--default-page=NAME 改变默认页 (通常是“index.html”)。
-E, --adjust-extension 以合适的扩展名保存 HTML/CSS 文档
--ignore-length 忽略头部的‘Content-Length’区域
--header=字符串 在头部插入 <字符串>
--max-redirect 每页所允许的最大重定向
--proxy-user=用户 使用 <用户> 作为代理用户名
--proxy-password=密码 使用 <密码> 作为代理密码
--referer=URL 在 HTTP 请求头包含‘Referer: URL’
--save-headers 将 HTTP 头保存至文件。
-U, --user-agent=代理 标识自己为 <代理> 而不是 Wget/VERSION。
--no-http-keep-alive 禁用 HTTP keep-alive (持久连接)。
--no-cookies 不使用 cookies。
--load-cookies=文件 会话开始前从 <文件> 中载入 cookies。
--save-cookies=文件 会话结束后保存 cookies 至 FILE。
--keep-session-cookies 载入并保存会话 (非永久) cookies。
--post-data=字符串 使用 POST 方式;把 <字串>作为数据发送。
--post-file=文件 使用 POST 方式;发送 <文件> 内容。
--method=HTTP方法 在请求中使用指定的 。
--post-data=字符串 把 <字串> 作为数据发送,必须设置 --method
--post-file=文件 发送 <文件> 内容,必须设置 --method
--content-disposition 当选择本地文件名时允许 Content-Disposition
头部 (实验中)。
--content-on-error 在服务器错误时输出接收到的内容
--auth-no-challenge 不先等待服务器询问就发送基本 HTTP 验证信息。
HTTPS (SSL/TLS) 选项:
--secure-protocol=PR 选择安全协议,可以是 auto、SSLv2、
SSLv3、TLSv1、PFS 中的一个。
--https-only 只跟随安全的 HTTPS 链接
--no-check-certificate 不要验证服务器的证书。
--certificate=文件 客户端证书文件。
--certificate-type=类型 客户端证书类型,PEM 或 DER。
--private-key=文件 私钥文件。
--private-key-type=类型 私钥文件类型,PEM 或 DER。
--ca-certificate=文件 带有一组 CA 证书的文件。
--ca-directory=DIR 保存 CA 证书的哈希列表的目录。
--ca-certificate=文件 带有一组 CA 证书的文件。
--pinnedpubkey=FILE/HASHES Public key (PEM/DER) file, or any number
of base64 encoded sha256 hashes preceded by
'sha256//' and seperated by ';', to verify
peer against
HSTS 选项:
--no-hsts 禁用 HSTS
--hsts-file HSTS 数据库路径(将覆盖默认值)
FTP 选项:
--ftp-user=用户 设置 ftp 用户名为 <用户>。
--ftp-password=密码 设置 ftp 密码为 <密码>
--no-remove-listing 不要删除‘.listing’文件
--no-glob 不在 FTP 文件名中使用通配符展开
--no-passive-ftp 禁用“passive”传输模式
--preserve-permissions 保留远程文件的权限
--retr-symlinks 递归目录时,获取链接的文件 (而非目录)
FTPS 选项:
--ftps-implicit 使用隐式 FTPS(默认端口 990)
--ftps-resume-ssl 打开数据连接时继续控制连接中的 SSL/TLS 会话
--ftps-clear-data-connection 只加密控制信道;数据传输使用明文
--ftps-fallback-to-ftp 回落到 FTP,如果目标服务器不支持 FTPS
WARC 选项:
--warc-file=文件名 在一个 .warc.gz 文件里保持请求/响应数据
--warc-header=字符串 在头部插入 <字符串>
--warc-max-size=数字 将 WARC 的最大尺寸设置为 <数字>
--warc-cdx 写入 CDX 索引文件
--warc-dedup=文件名 不要记录列在此 CDX 文件内的记录
--no-warc-compression 不要 GZIP 压缩 WARC 文件
--no-warc-digests 不要计算 SHA1 摘要
--no-warc-keep-log 不要在 WARC 记录中存储日志文件
--warc-tempdir=目录 WARC 写入器的临时文件目录
递归下载:
-r, --recursive 指定递归下载
-l, --level=数字 最大递归深度 (inf 或 0 代表无限制,即全部下载)。
--delete-after 下载完成后删除本地文件
-k, --convert-links 让下载得到的 HTML 或 CSS 中的链接指向本地文件
--convert-file-only convert the file part of the URLs only (usually known as the basename)
--backups=N 写入文件 X 前,轮换移动最多 N 个备份文件
-K, --backup-converted 在转换文件 X 前先将它备份为 X.orig。
-m, --mirror -N -r -l inf --no-remove-listing 的缩写形式。
-p, --page-requisites 下载所有用于显示 HTML 页面的图片之类的元素。
--strict-comments 用严格方式 (SGML) 处理 HTML 注释。
递归接受/拒绝:
-A, --accept=列表 逗号分隔的可接受的扩展名列表
-R, --reject=列表 逗号分隔的要拒绝的扩展名列表
--accept-regex=REGEX 匹配接受的 URL 的正则表达式
--reject-regex=REGEX 匹配拒绝的 URL 的正则表达式
--regex-type=类型 正则类型 (posix|pcre)
-D, --domains=列表 逗号分隔的可接受的域名列表
--exclude-domains=列表 逗号分隔的要拒绝的域名列表
--follow-ftp 跟踪 HTML 文档中的 FTP 链接
--follow-tags=列表 逗号分隔的跟踪的 HTML 标识列表
--ignore-tags=列表 逗号分隔的忽略的 HTML 标识列表
-H, --span-hosts 递归时转向外部主机
-L, --relative 仅跟踪相对链接
-I, --include-directories=列表 允许目录的列表
--trust-server-names 使用重定向 URL 的最后一段作为本地文件名
-X, --exclude-directories=列表 排除目录的列表
-np, --no-parent 不追溯至父目录
wget 使用示例
wget 虽然功能强大,但是使用起来还是比较简单的,基本的语法是:wget [参数列表] URL
下面就结合具体的例子来说明一下wget的用法。
1、使用 wget 下载单个文件
以下的例子是从网络下载一个文件并保存在当前目录
wget http://cn.wordpress.org/wordpress-3.1-zh_CN.zip
在下载的过程中会显示进度条,包含(下载完成百分比,已经下载的字节,当前下载速度,剩余下载时间)。
2、使用 wget -O 下载并以不同的文件名保存
wget默认会以最后一个符合”/”的后面的字符来命令,对于动态链接的下载通常文件名会不正确。
错误:下面的例子会下载一个文件并以名称download.php?id=1080保存
wget http://www.centos.bz/download?id=1
即使下载的文件是zip格式,它仍然以download.php?id=1080命令。
正确:为了解决这个问题,我们可以使用参数-O来指定一个文件名:
wget -O wordpress.zip http://www.centos.bz/download.php?id=1080
3、使用 wget --limit -rate 限速下载
当你执行wget的时候,它默认会占用全部可能的宽带下载。但是当你准备下载一个大文件,而你还需要下载其它文件时就有必要限速了。
wget –limit-rate=300k http://cn.wordpress.org/wordpress-3.1-zh_CN.zip
4、使用 wget -c 断点续传
当文件特别大或者网络特别慢的时候,往往一个文件还没有下载完,连接就已经被切断,此时就需要断点续传。
wget的断点续传是自动的,只需要使用 -c 参数。使用断点续传要求服务器支持断点续传。
例如: wget -c http://the.url.of/incomplete/file
-t 参数表示重试次数,例如需要重试100次,那么就写-t 100,如果设成-t 0,那么表示无穷次重试,直到连接成功。
-T 参数表示超时等待时间,例如-T 120,表示等待120秒连接不上就算超时。
5、使用 wget -b 后台下载
对于下载非常大的文件的时候,我们可以使用参数-b进行后台下载。
wget -b http://cn.wordpress.org/wordpress-3.1-zh_CN.zip
Continuing in background, pid 1840.
Output will be written to `wget-log’.
你可以使用以下命令来察看下载进度
tail -f wget-log
6、使用代理服务器(proxy) 和 伪装代理(user-agent)名称下载
如果用户的网络需要经过代理服务器,那么可以让 wget 通过代理服务器进行文件的下载。
此时需要在当前用户的目录下创建一个 .wgetrc 文件。
文件中可以设置代理服务器:
http-proxy = 111.111.111.111:8080
ftp-proxy = 111.111.111.111:8080
分别表示http的代理服务器和ftp的代理服务器。
如果代理服务器需要密码,则使用这两个参数:
–proxy-user=USER 设置代理用户
–proxy-passwd=PASS 设置代理密码
使用参数 –proxy=on/off 使用或者关闭代理。
有些网站能通过根据判断代理名称不是浏览器而拒绝你的下载请求。不过你可以通过 --user-agent 参数伪装。
wget --user-agent=”Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.204 Safari/534.16″ 下载链接
wget 还有很多有用的功能,需要用户去挖掘。
7、使用 wget --spider 测试下载链接
当你打算进行定时下载,你应该在预定时间测试下载链接是否有效。我们可以增加–spider参数进行检查。
wget –spider URL
如果下载链接正确,将会显示
wget –spider URL
Spider mode enabled. Check if remote file exists.
HTTP request sent, awaiting response… 200 OK
Length: unspecified [text/html]
Remote file exists and could contain further links,
but recursion is disabled — not retrieving.
这保证了下载能在预定的时间进行,但当你给错了一个链接,将会显示如下错误
wget –spider url
Spider mode enabled. Check if remote file exists.
HTTP request sent, awaiting response… 404 Not Found
Remote file does not exist — broken link!!!
你可以在以下几种情况下使用spider参数:
定时下载之前进行检查
间隔检测网站是否可用
检查网站页面的死链接
8、使用 wget --tries 增加重试次数
如果网络有问题或下载一个大文件也有可能失败。wget默认重试20次连接下载文件。如果需要,你可以使用–tries增加重试次数。
wget –tries=40 URL
9、使用 wget -i 下载多个文件 (批量下载)
如果有多个文件需要下载,那么可以生成一个文件,把每个文件的 URL 写一行。
例如,生成文件 download.txt,然后用命令:wget -i download.txt
这样就会把download.txt里面列出的每个URL都下载下来。(如果列的是文件就下载文件,如果列的是网站,那么下载首页)
首先,保存一份下载链接文件
cat > filelist.txt
url1
url2
url3
url4
接着使用这个文件和参数-i下载
wget -i filelist.txt
10、使用 wget --mirror 镜像网站
下面的例子是下载整个网站到本地。
wget –mirror -p –convert-links -P ./LOCAL URL
–miror:开户镜像下载
-p:下载所有为了html页面显示正常的文件
–convert-links:下载后,转换成本地的链接
-P ./LOCAL:保存所有文件和目录到本地指定目录
11、使用 wget --reject 过滤指定格式下载
可以指定让 wget 只下载一类文件,或者不下载什么文件。
例如:
wget -m –reject=gif http://target.web.site/subdirectory
表示下载 http://target.web.site/subdirectory,但是忽略gif文件。
–accept=LIST 可以接受的文件类型,
–reject=LIST 拒绝接受的文件类型。
你想下载一个网站,但你不希望下载图片,你可以使用以下命令。
wget –reject=gif url
12、使用 wget -o 把下载信息存入日志文件
你不希望下载信息直接显示在终端而是在一个日志文件,可以使用以下命令:
wget -o download.log URL
13、使用 wget -Q 限制总下载文件大小
当你想要下载的文件超过5M而退出下载,你可以使用以下命令:
wget -Q5m -i filelist.txt
注意:这个参数对单个文件下载不起作用,只能递归下载时才有效。
14、使用 wget -r -A 下载指定格式文件
可以在以下情况使用该功能
下载一个网站的所有图片
下载一个网站的所有视频
下载一个网站的所有PDF文件
wget -r -A.pdf url
15、下载整个 http 或者 wget FTP 下载
wget http://place.your.url/here
这个命令可以将 http://place.your.url/here 首页下载下来。
使用 -x 会强制建立服务器上一模一样的目录,
如果使用 -nd 参数,那么服务器上下载的所有内容都会加到本地当前目录。
wget -r http://place.your.url/here
这个命令会按照递归的方法,下载服务器上所有的目录和文件,实质就是下载整个网站。
这个命令一定要小心使用,因为在下载的时候,被下载网站指向的所有地址同 样会被下载,
因此,如果这个网站引用了其他网站,那么被引用的网站也会被下载下来!
基于这个原因,这个参数不常用。
可以用 -l number 参数来指定下载的层次。例如只下载两层,那么使用-l 2。
要是您想制作镜像站点,那么可以使用 -m 参数,
例如:wget -m http://place.your.url/here
这时 wget 会自动判断合适的参数来制作镜像站点。
此时,wget会登录到服务器上,读入robots.txt 并按 robots.txt的规定来执行。
使用 wget 匿名ftp 下载
wget ftp -url
使用 wget 用户名 和 密码认证的 ftp 下载
wget –ftp-user=USERNAME –ftp-password=PASSWORD url
16、密码和认证
wget 可以处理利用 用户名/密码 方式限制访问的网站,可以利用两个参数:
--http-user=用户 设置 http 用户名为 <用户>
--http-password=密码 设置 http 密码为 <密码>
对于需要证书做认证的网站,就只能利用其他下载工具了,例如 curl
中文文件名在平常的情况下会被编码, 但是在 –cut-dirs 时又是正常的,
wget -r -np -nH –cut-dirs=3 ftp://host/test/
测试.txt
wget -r -np -nH -nd ftp://host/test/
%B4%FA%B8%D5.txt
wget “ftp://host/test/*”
%B4%FA%B8%D5.txt
由于不知名的原因,可能是为了避开特殊文件名, wget 会自动将抓取文件名的部分用 encode_string 处理过,
所以该 patch 就把被 encode_string 处理成 “%3A” 这种东西, 用 decode_string 还原成 “:”,并套用在目录与文件名称的部分,
decode_string 是 wget 内建的函式。
wget -t0 -c -nH -x -np -b -m -P /home/sunny/NOD32view/ http://downloads1.kaspersky-labs.com/bases/ -o wget.log
curl 命令
linux 的 curl 是 一个强大的 网络传输工具。
linux 的 curl 是通过 url 语法 在命令行下上传或下载文件的工具软件,它支持 http、https、ftp,、ftps、telnet 等多种协议,常被用来抓取网页 和 监控Web服务器状态。
curl 命令是一个功能强大的网络工具,它能够通过 http、ftp 等方式下载文件,也能够上传文件。其实 curl 远不止前面所说的那些功能,大家可以通过 man curl 阅读手册页获取更多的信息。类似的工具还有 wget。
curl 命令使用了 libcurl 库来实现,libcurl 库常用在 C程序 中用来处理 HTTP 请求,curlpp 是 libcurl 的一个 C++ 封装,这几个东西可以用在抓取网页、网络监控等方面的开发,而 curl 命令可以帮助来解决开发过程中遇到的问题。
curl 常用参数
语法:# curl [option] [url]
-A/--user-agent 设置用户代理发送给服务器
-b/--cookie cookie字符串或文件读取位置
-c/--cookie-jar 操作结束后把cookie写入到这个文件中
-C/--continue-at 断点续转
-d/--data/--data-ascii 指定POST的内容
-D/--dump-header 把header信息写入到该文件中
-e/--referer 来源网址
-f/--fail 连接失败时不显示http错误
-H/--header 指定请求头参数
-I/--head 仅返回头部信息,使用HEAD请求
-m/--max-time 指定处理的最大时长
-o/--output 把输出写到该文件中
-O/--remote-name 把输出写到该文件中,保留远程文件的文件名
-r/--range 检索来自HTTP/1.1或FTP服务器字节范围
-s/--silent 静音模式。不输出任何东西
-T/--upload-file 指定上传文件路径
-u/--user 设置服务器的用户和密码
-v/--verbose 小写的v参数,用于打印更多信息,包括发送的请求信息,这在调试脚本是特别有用。
-w/--write-out [format] 什么输出完成后
-x/--proxy 指定代理服务器地址和端口,端口默认为1080
-#/--progress-bar 进度条显示当前的传送状态
--connect-timeout 指定尝试连接的最大时长
--retry 指定重试次数
使用示例:
1、基本用法
# curl http://www.linux.com执行后,www.linux.com 的html就会显示在屏幕上了
Ps:由于安装linux的时候很多时候是没有安装桌面的,也意味着没有浏览器,因此这个方法也经常用于测试一台服务器是否可以到达一个网站
2、保存访问的网页
2.1:使用linux的重定向功能保存
# curl http://www.linux.com >> linux.html2.2:可以使用curl的内置option:-o(小写)保存网页
$ curl -o linux.html http://www.linux.com执行完成后会显示如下界面,显示100%则表示保存成功
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 79684 0 79684 0 0 3437k 0 --:--:-- --:--:-- --:--:-- 7781k2.3:可以使用curl的内置option:-O(大写)保存网页中的文件。
要注意这里后面的 url 要具体到某个文件,不然抓不下来
# curl -O http://www.linux.com/hello.sh
3、测试网页返回值
# curl -o /dev/null -s -w %{http_code} www.linux.comPs:在脚本中,这是很常见的测试网站是否正常的用法
4、指定proxy服务器以及其端口
很多时候上网需要用到代理服务器(比如是使用代理服务器上网或者因为使用curl别人网站而被别人屏蔽IP地址的时候),幸运的是curl通过使用内置option:-x来支持设置代理
# curl -x 192.168.100.100:1080 http://www.linux.com
5、cookie
有些网站是使用 cookie 来记录 session信息。对于 chrome 这样的浏览器,可以轻易处理 cookie 信息,但在 curl 中只要增加相关参数也是可以很容易的处理 cookie
5.1:保存http的response里面的cookie信息。内置option:-c(小写)
# curl -c cookiec.txt http://www.linux.com执行后cookie信息就被存到了cookiec.txt里面了
5.2:保存http的response里面的header信息。内置option: -D
# curl -D cookied.txt http://www.linux.com执行后cookie信息就被存到了cookied.txt里面了
注意:-c(小写)产生的cookie和-D里面的cookie是不一样的。
5.3:使用cookie
很多网站都是通过监视你的cookie信息来判断你是否按规矩访问他们的网站的,因此我们需要使用保存的cookie信息。内置option: -b
# curl -b cookiec.txt http://www.linux.com
6、模仿浏览器
有些网站需要使用特定的浏览器去访问他们,有些还需要使用某些特定的版本。curl 内置option:-A可以让我们指定浏览器去访问网站
# curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" http://www.linux.com这样服务器端就会认为是使用IE8.0去访问的
7、伪造 referer(盗链)
很多服务器会检查http访问的referer从而来控制访问。比如:你是先访问首页,然后再访问首页中的邮箱页面,这里访问邮箱的referer地址就是访问首页成功后的页面地址,如果服务器发现对邮箱页面访问的referer地址不是首页的地址,就断定那是个盗连了
curl中内置option:-e可以让我们设定referer
# curl -e "www.linux.com" http://mail.linux.com这样就会让服务器其以为你是从www.linux.com点击某个链接过来的
8、下载文件
8.1:利用curl下载文件。
#使用内置option:-o(小写)
# curl -o dodo1.jpg http:www.linux.com/dodo1.JPG#使用内置option:-O(大写)
# curl -O http://www.linux.com/dodo1.JPG这样就会以服务器上的名称保存文件到本地
8.2:循环下载
有时候下载图片可以能是前面的部分名称是一样的,就最后的尾椎名不一样
# curl -O http://www.linux.com/dodo[1-5].JPG这样就会把dodo1,dodo2,dodo3,dodo4,dodo5全部保存下来
8.3:下载重命名
# curl -O http://www.linux.com/{hello,bb}/dodo[1-5].JPG由于下载的hello与bb中的文件名都是dodo1,dodo2,dodo3,dodo4,dodo5。因此第二次下载的会把第一次下载的覆盖,这样就需要对文件进行重命名。
# curl -o #1_#2.JPG http://www.linux.com/{hello,bb}/dodo[1-5].JPG这样在hello/dodo1.JPG的文件下载下来就会变成hello_dodo1.JPG,其他文件依此类推,从而有效的避免了文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置option:-r
# curl -r 0-100 -o dodo1_part1.JPG http://www.linux.com/dodo1.JPG
# curl -r 100-200 -o dodo1_part2.JPG http://www.linux.com/dodo1.JPG
# curl -r 200- -o dodo1_part3.JPG http://www.linux.com/dodo1.JPG
# cat dodo1_part* > dodo1.JPG这样就可以查看dodo1.JPG的内容了
8.5:通过ftp下载文件
curl可以通过ftp下载文件,curl提供两种从ftp中下载的语法
# curl -O -u 用户名:密码 ftp://www.linux.com/dodo1.JPG
# curl -O ftp://用户名:密码@www.linux.com/dodo1.JPG8.6:显示下载进度条
# curl -# -O http://www.linux.com/dodo1.JPG8.7:不会显示下载进度信息
# curl -s -O http://www.linux.com/dodo1.JPG
9、断点续传
在 windows中,我们可以使用迅雷这样的软件进行断点续传。curl可以通过内置 option:-C 同样可以达到相同的效果
如果在下载 dodo1.JPG 的过程中突然掉线了,可以使用以下的方式续传
# curl -C -O http://www.linux.com/dodo1.JPG
10、上传文件
curl 不仅仅可以下载文件,还可以上传文件。通过内置 option:-T 来实现
# curl -T dodo1.JPG -u 用户名:密码 ftp://www.linux.com/img/这样就向ftp服务器上传了文件dodo1.JPG
11、显示抓取错误
# curl -f http://www.linux.com/error其他参数(此处翻译为转载):
-a/--append 上传文件时,附加到目标文件
--anyauth 可以使用“任何”身份验证方法
--basic 使用HTTP基本验证
-B/--use-ascii 使用ASCII文本传输
-d/--data HTTP POST方式传送数据
--data-ascii 以ascii的方式post数据
--data-binary 以二进制的方式post数据
--negotiate 使用HTTP身份验证
--digest 使用数字身份验证
--disable-eprt 禁止使用EPRT或LPRT
--disable-epsv 禁止使用EPSV
--egd-file 为随机数据(SSL)设置EGD socket路径
--tcp-nodelay 使用TCP_NODELAY选项
-E/--cert 客户端证书文件和密码 (SSL)
--cert-type 证书文件类型 (DER/PEM/ENG) (SSL)
--key 私钥文件名 (SSL)
--key-type 私钥文件类型 (DER/PEM/ENG) (SSL)
--pass 私钥密码 (SSL)
--engine 加密引擎使用 (SSL). "--engine list" for list
--cacert CA证书 (SSL)
--capath CA目 (made using c_rehash) to verify peer against (SSL)
--ciphers SSL密码
--compressed 要求返回是压缩的形势 (using deflate or gzip)
--connect-timeout 设置最大请求时间
--create-dirs 建立本地目录的目录层次结构
--crlf 上传是把LF转变成CRLF
--ftp-create-dirs 如果远程目录不存在,创建远程目录
--ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
--ftp-pasv 使用 PASV/EPSV 代替端口
--ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
--ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
--ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
-F/--form 模拟http表单提交数据
-form-string 模拟http表单提交数据
-g/--globoff 禁用网址序列和范围使用{}和[]
-G/--get 以get的方式来发送数据
-h/--help 帮助
-H/--header 自定义头信息传递给服务器
--ignore-content-length 忽略的HTTP头信息的长度
-i/--include 输出时包括protocol头信息
-I/--head 只显示文档信息
-j/--junk-session-cookies 读取文件时忽略session cookie
--interface 使用指定网络接口/地址
--krb4 使用指定安全级别的krb4
-k/--insecure 允许不使用证书到SSL站点
-K/--config 指定的配置文件读取
-l/--list-only 列出ftp目录下的文件名称
--limit-rate 设置传输速度
--local-port 强制使用本地端口号
-m/--max-time 设置最大传输时间
--max-redirs 设置最大读取的目录数
--max-filesize 设置最大下载的文件总量
-M/--manual 显示全手动
-n/--netrc 从netrc文件中读取用户名和密码
--netrc-optional 使用 .netrc 或者 URL来覆盖-n
--ntlm 使用 HTTP NTLM 身份验证
-N/--no-buffer 禁用缓冲输出
-p/--proxytunnel 使用HTTP代理
--proxy-anyauth 选择任一代理身份验证方法
--proxy-basic 在代理上使用基本身份验证
--proxy-digest 在代理上使用数字身份验证
--proxy-ntlm 在代理上使用ntlm身份验证
-P/--ftp-port 使用端口地址,而不是使用PASV
-Q/--quote 文件传输前,发送命令到服务器
--range-file 读取(SSL)的随机文件
-R/--remote-time 在本地生成文件时,保留远程文件时间
--retry 传输出现问题时,重试的次数
--retry-delay 传输出现问题时,设置重试间隔时间
--retry-max-time 传输出现问题时,设置最大重试时间
-S/--show-error 显示错误
--socks4 用socks4代理给定主机和端口
--socks5 用socks5代理给定主机和端口
-t/--telnet-option Telnet选项设置
--trace 对指定文件进行debug
--trace-ascii Like --跟踪但没有hex输出
--trace-time 跟踪/详细输出时,添加时间戳
--url Spet URL to work with
-U/--proxy-user 设置代理用户名和密码
-V/--version 显示版本信息
-X/--request 指定什么命令
-y/--speed-time 放弃限速所要的时间。默认为30
-Y/--speed-limit 停止传输速度的限制,速度时间'秒
-z/--time-cond 传送时间设置
-0/--http1.0 使用HTTP 1.0
-1/--tlsv1 使用TLSv1(SSL)
-2/--sslv2 使用SSLv2的(SSL)
-3/--sslv3 使用的SSLv3(SSL)
--3p-quote like -Q for the source URL for 3rd party transfer
--3p-url 使用url,进行第三方传送
--3p-user 使用用户名和密码,进行第三方传送
-4/--ipv4 使用IP4
-6/--ipv6 使用IP6
转自:http://www.linuxdiyf.com/linux/2800.html