如果真要做全面介绍的话,有可能是一部专著的篇幅。即使是做综述性的介绍,一篇三五十页的论文也可以写成了。所以我一直想怎么能从头到尾把这个问题logically串连起来。正好这段时间我在修改我做的交易策略里面关于聚类的部分,趁脑子热的时候顺手写下。
就我的理解而言,如果想全面的了解聚类算法并对其进行区别和比较的话,最好能把聚类的具体算法放到整个聚类分析的语境中理解。那我接下来主要谈谈我的理解,就不搬弄教科书里的概念了。
聚类分析其实思路很简单,粗略来看就是以下2个(或3个)环节。
1、相似性衡量(similarity measurement)
相似性衡量又可以细分为直接法和间接法(答主自己取的名字,求轻拍):直接法是直接求取input data的相似性,间接法是求取data中提取出的features的相似性。但无论是求data还是feature的相似性,方法都是这么几种:
距离。距离主要就是指Minkovski距离。这个名字虽然听起来陌生,但其算法就是Lp norm的算法,如果是L1 norm,那就是绝对值/曼哈顿距离(Manhattan distance);如果是L2 norm,那就是著名的欧式距离(Euclidean distance)了,也是应用最广泛的;如果
,supremum距离,好像也有叫切比雪夫距离的,但就很少有人用了。另外,还有Mahalanobis距离,目前来看主要应用于Gaussian Mixture Model(GMM),还有Lance&Williams距离等等,但几乎没见过求距离的时候会专门用这个的。
相似系数。主要有夹角余弦和相关系数。相关系数的应用也非常广泛,其主要优势是它不受原线性变换的影响,而且可以轻松地转换为距离,但其运算速度要比距离法慢得多,当维数很高的时候。
核函数K(x,y)。定义在
上的二元函数,本质上也是反映x和y的距离。核函数的功能就是把数据从低维空间投影(project)到高维空间去。
DTW(dynamic time warping)。之所以把DTW单独拿出来,是因为它是一种非常特殊的距离算法,它可以计算两个不同长度的向量的距离,也可以对两对向量中不同时间段内的数据做匹配,比如你发现2015年上半年的上证指数走势和SP5002012年的走势非常相似。DTW主要用在时间序列的部分场合里,在这里就不做具体分析了。
2、聚类算法(clustering algorithm)
Hierarchical methods:该主要有两种路径:agglomerative和divisive,也可以理解为自下而上法(bottom-up)和自上而下法(top-down)。自下而上法就是一开始每个个体(object)都是一个类,然后根据linkage寻找同类,最后形成一个“类”。自上而下法就是反过来,一开始所有个体都属于一个“类”,然后根据linkage排除异己,最后每个个体都成为一个“类”。这两种路径本质上没有孰优孰劣之分,只是在实际应用的时候要根据数据特点以及你想要的“类”的个数,来考虑是自上而下更快还是自下而上更快。至于根据Linkage判断“类”的方法就是楼上所提到的最短距离法、最长距离法、中间距离法、类平均法等等(其中类平均法往往被认为是最常用也最好用的方法,一方面因为其良好的单调性,另一方面因为其空间扩张/浓缩的程度适中)。Hierarchical methods中比较新的算法有BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies)主要是在数据体量很大的时候使用,而且数据类型是numerical;ROCK(A Hierarchical Clustering Algorithm for Categorical Attributes)主要用在categorical的数据类型上;Chameleon(A Hierarchical Clustering Algorithm Using Dynamic Modeling)里用到的linkage是kNN(k-nearest-neighbor)算法,并以此构建一个graph,Chameleon的聚类效果被认为非常强大,比BIRCH好用,但运算复杂的发很高,O(n^2)。看个Chameleon的聚类效果图,其中一个颜色代表一类,可以看出来是可以处理非常复杂的形状的。

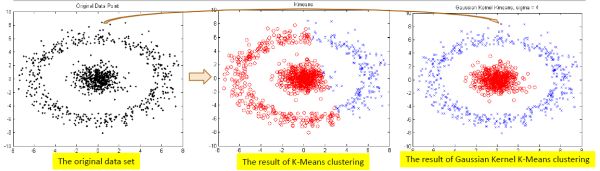
Partition-based methods:其原理简单来说就是,想象你有一堆散点需要聚类,想要的聚类效果就是“类内的点都足够近,类间的点都足够远”。首先你要确定这堆散点最后聚成几类,然后挑选几个点作为初始中心点,再然后依据预先定好的启发式算法(heuristic algorithms)给数据点做迭代重置(iterative relocation),直到最后到达“类内的点都足够近,类间的点都足够远”的目标效果。也正是根据所谓的“启发式算法”,形成了k-means算法及其变体包括k-medoids、k-modes、k-medians、kernel k-means等算法。k-means对初始值的设置很敏感,所以有了k-means++、intelligent k-means、genetic k-means;k-means对噪声和离群值非常敏感,所以有了k-medoids和k-medians;k-means只用于numerical类型数据,不适用于categorical类型数据,所以k-modes;k-means不能解决非凸(non-convex)数据,所以有了kernel k-means。另外,很多教程都告诉我们Partition-based methods聚类多适用于中等体量的数据集,但我们也不知道“中等”到底有多“中”,所以不妨理解成,数据集越大,越有可能陷入局部最小。下图显示的就是面对非凸,k-means和kernel k-means的不同效果。
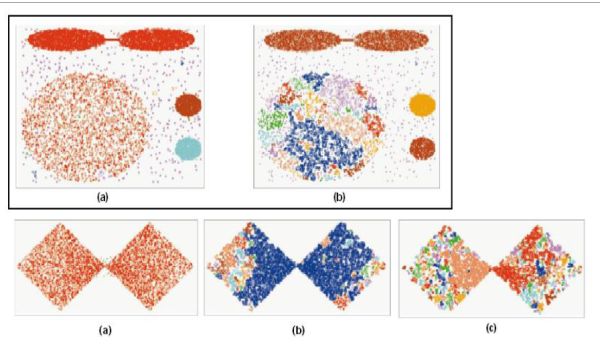
Density-based methods:上面这张图你也看到了,k-means解决不了这种不规则形状的聚类。于是就有了Density-based methods来系统解决这个问题。该方法同时也对噪声数据的处理比较好。其原理简单说画圈儿,其中要定义两个参数,一个是圈儿的最大半径,一个是一个圈儿里最少应容纳几个点。最后在一个圈里的,就是一个类。DBSCAN(Density-Based Spatial Clustering of Applications with Noise)就是其中的典型,可惜参数设置也是个问题,对这两个参数的设置非常敏感。DBSCAN的扩展叫OPTICS(Ordering Points To Identify Clustering Structure)通过优先对高密度(high density)进行搜索,然后根据高密度的特点设置参数,改善了DBSCAN的不足。下图就是表现了DBSCAN对参数设置的敏感,你们可以感受下。
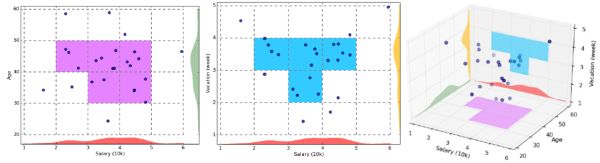
Grid-based methods:这类方法的原理就是将数据空间划分为网格单元,将数据对象集映射到网格单元中,并计算每个单元的密度。根据预设的阈值判断每个网格单元是否为高密度单元,由邻近的稠密单元组形成”类“。该类方法的优点就是执行效率高,因为其速度与数据对象的个数无关,而只依赖于数据空间中每个维上单元的个数。但缺点也是不少,比如对参数敏感、无法处理不规则分布的数据、维数灾难等。STING(STatistical INformation Grid)和CLIQUE(CLustering In QUEst)是该类方法中的代表性算法。下图是CLIQUE的一个例子:
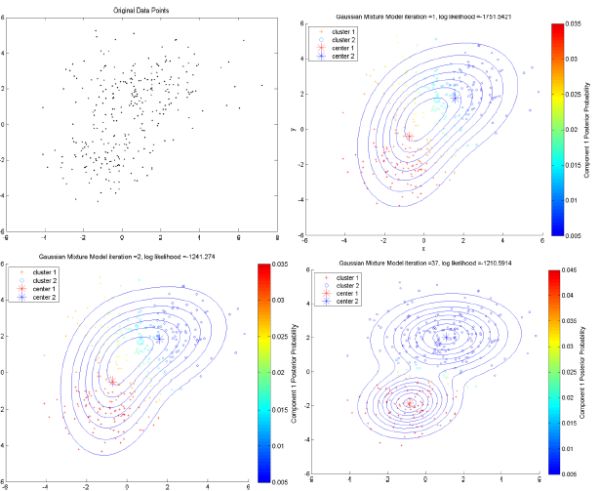
Model-based methods:这一类方法主要是指基于概率模型的方法和基于神经网络模型的方法,尤其以基于概率模型的方法居多。这里的概率模型主要指概率生成模型(generative Model),同一”类“的数据属于同一种概率分布。这中方法的优点就是对”类“的划分不那么”坚硬“,而是以概率形式表现,每一类的特征也可以用参数来表达;但缺点就是执行效率不高,特别是分布数量很多并且数据量很少的时候。其中最典型、也最常用的方法就是高斯混合模型(GMM,Gaussian Mixture Models)。基于神经网络模型的方法主要就是指SOM(Self Organized Maps)了,也是我所知的唯一一个非监督学习的神经网络了。下图表现的就是GMM的一个demo,里面用到EM算法来做最大似然估计。
3、数据简化(data reduction),这个环节optional。其实第二部分提到的有些算法就是对数据做了简化,才得以具备处理大规模数据的能力,比如BIRCH。但其实你可以任意组合,所以理论上把数据简化的方法和上面提到的十几种聚类算法结合使用,可以有上百个算法了。
变换(Data Transformation):离散傅里叶变换(Discrete Fourier Transformation)可以提取数据的频域(frequency domain)信息,离散小波变换(Discrete Wavelet Transformation)除了频域之外,还可以提取到时域(temporal domain)信息。
降维(Dimensionality Reduction):在降维的方法中,PCA(Principle Component Analysis)和SVD(Singular Value Decomposition)作为线性方法,受到最广泛的应用。还有像MDS(Multi-Dimensional Scaling)什么的,不过只是作为PCA的一个扩展,给我的感觉是中看不中用。这几个方法局限肯定是无法处理非线性特征明显的数据。处理非线性降维的算法主要是流形学习(Manifold Learning),这又是一大块内容,里面集中常见的算法包括ISOMAP、LLE(Locally Linear Embedding)、MVU(Maximum variance unfolding)、Laplacian eigenmaps、Hessian eigenmaps、Kernel PCA、Probabilistic PCA等等。流形学习还是挺有趣的,而且一直在发展。关于降维在聚类中的应用,最著名的应该就是
@宋超
在评论里提到的谱聚类(Spectral Clustering),就是先用Laplacian eigenmaps对数据降维(简单地说,就是先将数据转换成邻接矩阵或相似性矩阵,再转换成Laplacian矩阵,再对Laplacian矩阵进行特征分解,把最小的K个特征向量排列在一起),然后再使用k-means完成聚类。谱聚类是个很好的方法,效果通常比k-means好,计算复杂度还低,这都要归功于降维的作用。
抽样(Sampling):最常用的就是随机抽样(Random Sampling)咯,如果你的数据集特别大,随机抽样就越能显示出它的低复杂性所带来的好处。比如CLARA(Clustering LARge Applications)就是因为k-medoids应对不了大规模的数据集,所以采用sampling的方法。至于更加fancy的抽样方法我还真不了解,我就不在这里好为人师而误人子弟了。
PS:以上所有图示均来自于UIUC的韩家炜教授的slides,版权归韩家炜教授所有;
PSS:如果对某个算法感兴趣,还请直接读论文、读教材、写代码;
PSSS:以上三个环节,可以各选择其中一个方法加以组合,放心地试验,放心地玩吧,就像把不同的溶液都往一个烧瓶里倒,这里很安全,不会爆炸的。