CentOS8 安装 Hadoop3.2.1 独立模式、伪分布模式
本文以root用户安装,开发测试使用。生产环境可以考虑用其他用户安装,比如hadoop或hdfs,yarn
下载地址:
https://hadoop.apache.org/releases.html
安装文档:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
Hadoop安装模式
1.独立模式
2.伪分布模式
3.全分布式模式
4.全分布式-HA
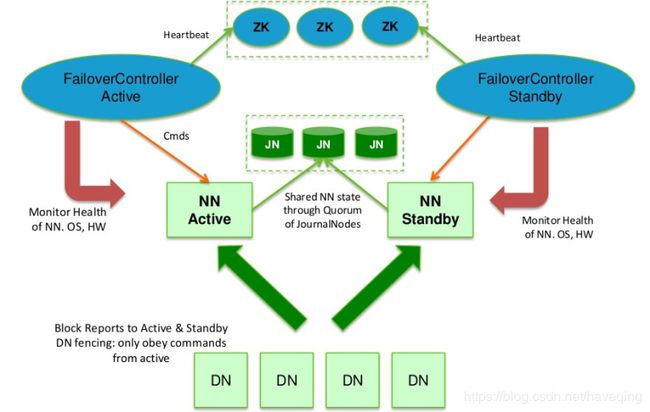
HDFS High Availability Using the Quorum Journal Manager
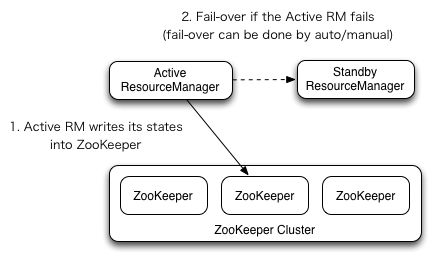
ResourceManager High Availability
一、安装准备
安装软件
如果您的群集没有必需的软件,则需要安装它。
安装ssh和pdsh
[root@dev1 ~]# ssh (如果有就不用装了)
yum install openssh-server
配置文件/etc/ssh/sshd_config,保持默认即可
配置开机自启动
systemctl enable sshd
systemctl start sshd
pdsh (parallel distributed shell 可以在多台服务器上一起执行命令,非必需,事后再来吧)
pdsh使用前要先配ssh免密
下载地址
https://sourceforge.net/projects/pdsh/
[root@dev1 opt]# tar -jxvf pdsh-2.26.tar.bz2
[root@dev1 opt]# cd pdsh-2.26
[root@dev1 pdsh-2.26]# ./configure \
--without-rsh \
--with-ssh \
--with-machines=/etc/pdsh/machines \
--with-dshgroups \
--with-netgroup \
--with-timeout=10
有哪些配置请参考pdsh-2.26/README文件。
[root@dev1 pdsh-2.26]# make && make install
[root@dev11 pdsh-2.26]# pdsh -V
pdsh-2.26
rcmd modules: ssh,exec (default: ssh)
misc modules: machines
相关文件
mkdir /etc/pdsh
vi /etc/pdsh/machines (pdsh要一起操作的机器名)
dev10
dev11
dev12
dev13
/usr/local/bin/pdsh
/usr/local/lib/pdsh
pdsh 样例
[root@dev10 pdsh-2.26]# pdsh -a date
dev10: 2020年 05月 16日 星期六 13:52:18 CST
dev12: 2020年 05月 16日 星期六 13:52:18 CST
dev11: 2020年 05月 16日 星期六 13:52:18 CST
dev13: 2020年 05月 16日 星期六 13:52:18 CST
[root@dev10 pdsh-2.26]# pdsh -a "cd /opt; tar -zxvf jdk-8u192-linux-x64.tar.gz"
准备启动Hadoop集群
解压缩下载的Hadoop发行版。 在发行版中,编辑文件etc/hadoop/hadoop-env.sh以定义一些参数,如下所示:
# export JAVA_HOME=
export JAVA_HOME=/opt/jdk1.8.0_192
安装配置jdk8
cd /opt
tar -zxvf jdk-8u192-linux-x64.tar.gz
配置/etc/profile,加入
export JAVA_HOME=/opt/jdk1.8.0_192
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
[root@dev1 opt]# java -version
java version "1.8.0_192"
Java(TM) SE Runtime Environment (build 1.8.0_192-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.192-b12, mixed mode)
配置好jdk后,就不用在hadoop-env.sh中配置了
[root@dev1 opt]# tar -zxvf hadoop-3.2.1.tar.gz
[root@dev1 opt]# cd hadoop-3.2.1
[root@dev1 hadoop-3.2.1]# bin/hadoop
二、独立操作
默认情况下,Hadoop被配置为以非分布式模式作为单个Java进程运行。 这对于调试很有用。
下面的示例复制解压缩的conf目录以用作输入,然后查找并显示给定正则表达式的每个匹配项。 输出被写入给定的输出目录。
[root@dev1 hadoop-3.2.1]# mkdir input
[root@dev1 hadoop-3.2.1]# cp etc/hadoop/*.xml input
[root@dev1 hadoop-3.2.1]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
[root@dev1 hadoop-3.2.1]# cat output/*
1 dfsadmin
三、伪分布操作
Hadoop还可以在伪分布式模式下的单个节点上运行,其中每个Hadoop守护进程在单独的Java进程中运行。
etc/hadoop/core-site.xml
fs.defaultFS
hdfs://localhost:9000
etc/hadoop/hdfs-site.xml
dfs.replication
1
设置无密码SSH(是服务器间的无密码ssh)(与用户相关)
现在检查您是否可以在没有密码的情况下SSH到本地主机:
[root@dev1 hadoop-3.2.1] ssh localhost
如果没有密码就无法SSH到本地主机,请执行以下命令:
[root@dev1 hadoop-3.2.1]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
[root@dev1 hadoop-3.2.1]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[root@dev1 hadoop-3.2.1]# chmod 0600 ~/.ssh/authorized_keys
[root@dev1 hadoop-3.2.1]# ssh localhost
[root@dev1 hadoop-3.2.1]# exit
[root@dev1 hadoop-3.2.1]# ssh dev1
[root@dev1 hadoop-3.2.1]# exit
执行
以下说明是在本地运行MapReduce作业。 如果要在YARN上执行作业,请参阅单节点上的YARN。
1.格式化文件系统:
[root@dev1 hadoop-3.2.1] bin/hdfs namenode -format
2.启动NameNode守护程序和DataNode守护程序:
[root@dev1 hadoop-3.2.1]# sbin/start-dfs.sh
Starting namenodes on [localhost]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [dev1]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
可以在/opt/hadoop-3.2.1/etc/hadoop/hadoop-env.sh头部添加
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root或者在sbin/start-dfs.sh,sbin/stopt-dfs.sh 添加
(对于安全守护程序,这意味着需要定义安全和不安全的环境变量。 例如,HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs)
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root#HDFS_DATANODE_SECURE_USER=hdfs
HDFS_SECONDARYNAMENODE_USER=root
[root@dev1 hadoop-3.2.1]# sbin/start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [dev1]
dev1: Warning: Permanently added 'dev1,192.168.0.201' (ECDSA) to the list of known hosts.
[root@dev1 hadoop-3.2.1]# jps
9619 DataNode
10070 Jps
9884 SecondaryNameNode
9454 NameNode
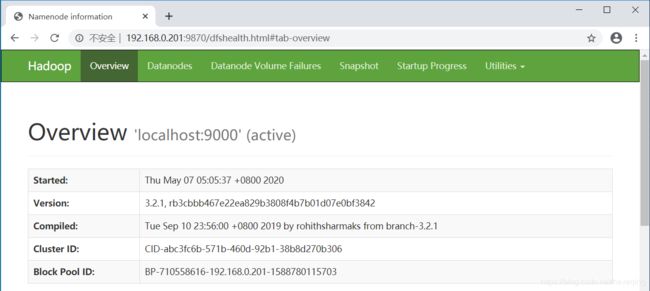
3.浏览Web界面以查找NameNode; 默认情况下,它在以下位置可用:(hdfs控制台)
NameNode - http://192.168.0.201:9870/

hadoop守护程序日志输出将写入$ HADOOP_LOG_DIR目录(默认为$ HADOOP_HOME/logs)。
4.设置执行MapReduce作业所需的HDFS目录:
[root@dev1 hadoop-3.2.1]# bin/hdfs dfs -mkdir /user
[root@dev1 hadoop-3.2.1]# bin/hdfs dfs -mkdir /user/root
[root@dev1 hadoop-3.2.1]# bin/hdfs dfs -mkdir -p /user/root
[root@dev1 hadoop-3.2.1]# bin/hdfs dfs -rm -f -r /user
5.将输入文件复制到分布式文件系统中:
[root@dev1 hadoop-3.2.1]# bin/hdfs dfs -mkdir input
[root@dev1 hadoop-3.2.1]# bin/hdfs dfs -put etc/hadoop/*.xml input
[root@dev1 hadoop-3.2.1]# bin/hdfs dfs -ls input
6.运行提供的一些示例:
先把之前的结果改名
[root@dev1 hadoop-3.2.1]# mv output output1
[root@dev1 hadoop-3.2.1]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
[root@dev1 hadoop-3.2.1]# cat output/*
1 dfsadmin
7.检查输出文件:将输出文件从分布式文件系统复制到本地文件系统并检查它们:
hdfs上的路径是/user/root/output
本地路径是/opt/hadoop-3.2.1/output
[root@dev1 hadoop-3.2.1]# bin/hdfs dfs -get output output
[root@dev1 hadoop-3.2.1]# cat output/*
1 dfsadmin
1 dfs.replication
或者
直接查看分布式文件系统上的输出文件:
[root@dev1 hadoop-3.2.1]# bin/hdfs dfs -cat output/*
1 dfsadmin
1 dfs.replication
8.完成后,使用以下命令停止守护进程:
[root@dev1 hadoop-3.2.1]# sbin/stop-dfs.sh
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [dev1]
三、在单个节点上的YARN
您可以通过设置一些参数并另外运行ResourceManager守护程序和NodeManager守护程序,以伪分布式模式在YARN上运行MapReduce作业。
以下指令假定上述指令的1.〜4.步骤已经执行。
1.如下配置参数:
etc/hadoop/mapred-site.xml:
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
etc/hadoop/yarn-site.xml:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
2.启动ResourceManager守护程序和NodeManager守护程序:
[root@dev1 hadoop-3.2.1]# sbin/start-yarn.sh
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
在/opt/hadoop-3.2.1/etc/hadoop/hadoop-env.sh头部添加(或者yarn-env.sh,或者start-yarn,stop-yarn)
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root[root@dev1 hadoop-3.2.1]# sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[root@dev1 hadoop-3.2.1]# jps
16181 Jps
15671 ResourceManager
15821 NodeManager
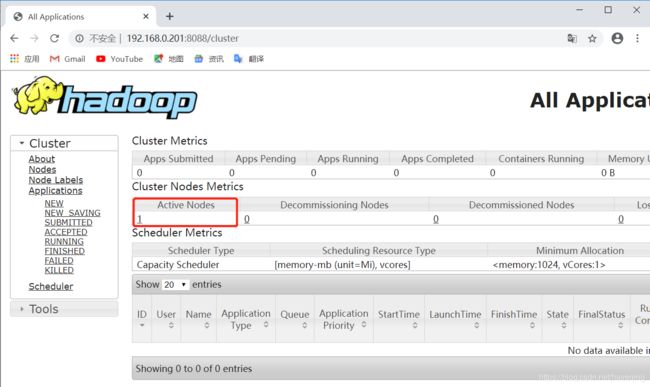
3.浏览Web界面以找到ResourceManager; 默认情况下,它在以下位置可用:(yarn控制台)
ResourceManager - http://192.168.0.201:8088/
4.运行MapReduce作业。
[root@dev1 hadoop-3.2.1]# sbin/start-dfs.sh
[root@dev1 hadoop-3.2.1]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output2 'dfs[a-z.]+'
Name node is in safe mode.
hdfs刚启动,NameNode处于安全模式,等一会就好了。
[root@dev1 hadoop-3.2.1]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output2 'dfs[a-z.]+'
[root@dev1 hadoop-3.2.1]# bin/hdfs dfs -cat output2/*
2020-05-08 04:44:35,210 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
1 dfsadmin
1 dfs.replication
从yarn控制台可以看到MapReduce作业执行信息
5.完成后,使用以下命令停止守护进程:
[root@dev1 hadoop-3.2.1]# sbin/stop-yarn.sh
Stopping nodemanagers
localhost: WARNING: nodemanager did not stop gracefully after 5 seconds: Trying to kill with kill -9
Stopping resourcemanager
四、全分布式操作
有关设置完全分布式、非平凡群集的信息,请参阅群集设置。
CentOS8 安装 hadoop3.2.1 完全分布式