知识储备
- 情感分析定义
文本情感分析(也称为意见挖掘)是指自然语言处理、文本挖掘以及计算机语言学等方法来识别和提取原素材中的主观信息。(摘自《维基百科》)
使用到的第三方库文件:
snownlp TextBlob(英文) SnowNLP(中文)TextBlob github:TextBlob
SnowNLP github :SnowNLP
朴素贝叶斯定义
朴素贝叶斯是基于贝叶斯定理与特征条件独立假设的分类方法。贝叶斯分类器基于一个简单的假定:给定目标值时属性之间相互条件独立(摘自《百度百科》)
- 停用词定义
在信息检索中,为节省存储空间和提高效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些词或字,这些词或字即被称为Stop Word(停用词)(摘自《维基百科》)
目前有很多比较成熟的停用词表,可以参考这个github项目
- 混淆矩阵
混淆矩阵中的4个数字,分别代表:
- TP: 本来是正向,预测也是正向的;
- FP: 本来是负向,预测却是正向的;
- FN: 本来是正向,预测却是负向的;
- TN: 本来是负向,预测也是负向的。
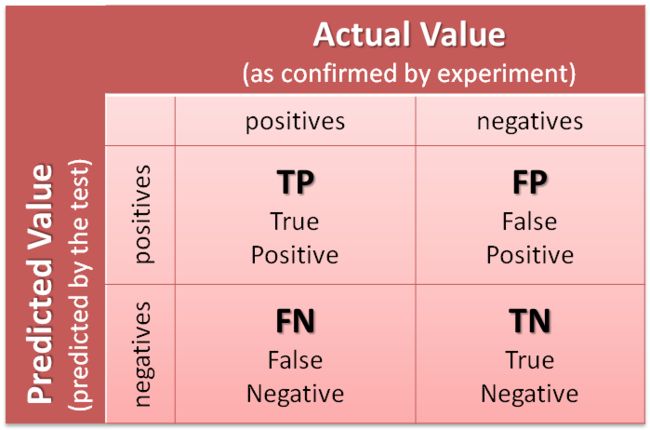
混淆矩阵数字含义
开始干活吧
- 文本文件读入
import pandas as pd
# 读入文本文件
df = pd.read_csv()
- 定义函数将星级评分大于3分的,当成正向情感,取值为1,反之取值为0
def make_label(df):
df["sentiment"] =df['comment_ratting'].apply(lambda x: 1 if x>3 else 0)
- 拆分特征和标签
# 提取全部特征值
X = df[['comment']]
y = df.sentiment
- 中文分词
# 结巴分词工具做分词操作
import jieba
def chinese_word_cut(content):
return ' '.join([word for word in jieba.cut(content,cut_all=False) if len(word)>=2])
# apply函数,对每行评论进行分词
X['cutted_comment'] = X.comment_infos.apply(chinese_word_cut)
- 训练集和测试集拆分
from sklearn.model_selection import train_test_split
# from sklearn.cross_validation import train_test_split (sklearn版本低于0.18,请使用该行)
# random_state 保证随机数在不同环境中保持一致,以便验证模型效果
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
- 中文停用词处理
def get_custom_stopwords(stop_words_file):
with open(stop_words_file) as f:
stopwords = f.read()
stopwords_list = stopwords.split('\n')
custom_stopwords_list = [i for i in stopwords_list]
return custom_stopwords_list
stop_word_file = '中文停用词文件'
stopwords = get_custom_stopwords(stop_words_file)
- 特征向量化
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer(
max_df = 0.8,# 在超过这一比例的文档中出现的关键词(过于平凡),去除掉。
min_df = 3, # 在低于这一数量的文档中出现的关键词(过于独特),去除掉。
token_pattern=u'(?u)\\b[^\\d\\W]\\w+\\b', #取出数字特征
stop_words=frozenset(stopwords))
)
# 向量化工具转化分词后的训练集语句,并转换为DataFrame对象
term_matrix = pd.DataFrame(vect.fit_transform(X_train.cutted_comment).toarray(), columns=vect.get_feature_names())
- 利用生成矩阵训练模型
# 朴素贝叶斯分类
from sklearn.naive_bayes import MultinomialNB
nb = MultinomialNB()
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(vect, nb)
# 将未特征向量化的训练集内容输入,做交叉验证,计算模型分类准确率
from sklearn.cross_validation import cross_val_score
print (cross_val_score(pipe, X_train.cutted_comment, y_train, cv=5, scoring='accuracy').mean())
结果输出:0.819563608026
- 验证模型准确度
# 模型拟合
pipe.fit(X_train.cutted_comment, y_train)
# 在测试集上,对情感分类进行预测
y_pred = pipe.predict(X_test.cutted_comment)
# 引入sklearn测量工具集
from sklearn import metrics
print (metrics.accuracy_score(y_test, y_pred))
结果输出:0.80612244898
- 混淆矩阵验证
print (metrics.confusion_matrix(y_test, y_pred))
结果输出:[[67 3][16 12]]
- SnowNLP进行情感分析
from snownlp import SnowNLP
def get_sentiment(text):
return SnowNLP(text).sentiments
# 测试数据集 利用SnowNLP处理
y_pred_snownlp = X_test.comment_infos.apply(get_sentiment)
# 当我们查看结果就会发现SnowNLP输出结果为[0-1]之间的小数值
# 所以我们将大于0.5的结果作为正向,小于0.5的结果作为负向y_pred_snownlp_normalized = y_pred_snownlp.apply(lambda x: 1 if x>0.5 else 0)
# 查看模型的准确率
print (metrics.accuracy_score(y_test, y_pred_snownlp_normalized))
结果输出:0.489795918367 结果很糟糕哦!
小结
- 如何利用停用词、词频阀值和标记模式(token_pattern)移除无关的特征词汇,降低模型复杂度
- 选用合适的机器学习分类模型,对词语特征矩阵分类的重要性
- 如何使用管道模式,归并和简化机器学习步骤流程
- 如何选择合适的性能测试工具,对模型的效果作出评估和对比
相关阅读 请移步
影视评论分析(四)-- 舆情分析
初步学习有很多不足之处,希望大家多多指教
代码和数据集会在整理后及时更新