【初学者系列】02-算法实例Jupyter转换为Python流程
作者·黄崇远
『数据虫巢』
全文共3349字
题图ssyer.com
“ 掌握了基本数据挖掘Python流程,意味着你已经踏出了最基本的一步。”
本系列适合以下人员:
数据开发/分析师、或者后台开发等但对对数据挖掘感兴趣。
计算机专业相关初学者,有志于从事数据相关工作。
本文为该系列第二篇,承接自第一篇《【初学者系列】01-机器学习入门教程,启发式实例》,核心内容将第一篇中简单基于jupyter的机器学习实例,转化为相对流程化的Python代码以及基本的阶段化流程。
所以,看本文之前,建议先看第一篇。


01
目的以及实验环境
项目目的
由于jupyter只适合作为实验过程,真正的在线过程,或者在线生产环境是使用python来执行。所以,我们基于01,如何把jupyter转换为流程化的python。
环境准备
我们先在01的数据基础上,模拟出来训练数据,以及假设我们要预测的待预测数据。我们在01教程输入数据的基础上,切割出两份没有交叉的数据。
+先把需要的目录创建好

(1) data中放之前我们的那份数据,先把01教程的数据丢进去
(2) model将存储模型文件
(3) predict将存放预测结果
02
数据切分
创建一个python文件,命名为01_split_data.py,实在不行,你用文本编辑器创建,写代码,再上传也行。
或者直接在linux上创建一个:
touch 01_split_data.py
然后使用vim在上面写代码:
#!/user/bin/env python3
# -*- coding: utf-8 -*-
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
file = './data/train_subset_1000000.csv'
df = pd.read_csv(file)
##截取部分当成训练集
df_click_1 = df[df["click"] == 1].iloc[:10000,:]
df_click_0 = df[df["click"] == 0].iloc[:52400,:]
#然后合并回去(行合并),作为新的df_train
df_train=pd.concat([df_click_1, df_click_0])
##截取部分当成预测集
df_click_1 = df[df["click"] == 1].iloc[10001:20000,:]
df_click_0 = df[df["click"] == 0].iloc[52401:100000,:]
#然后合并回去(行合并),作为新的df_train
df_predict=pd.concat([df_click_1, df_click_0])
#保存数据
df_train.to_csv('./data/df_train.csv')
df_predict.to_csv('./data/df_predict.csv')
给予执行权限:
chmod +x 01_split_data.py
执行数据分割程序:
python 01_split_data.py
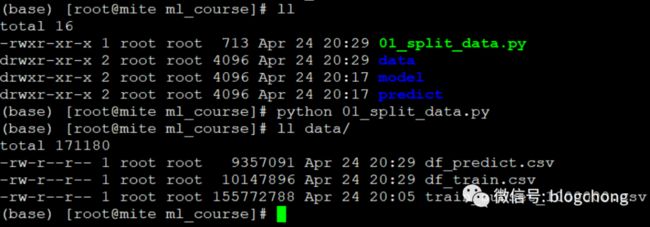
可以看到data下已经多出来了两份文件,分别用于train和predict.
在实际的工作场景中,同样,我们需要准备好训练数据和预测数据,真实差异在哪呢?
训练集和待预测数据的差异在于,训练数据是带标的,即是有click这个字段的,而预测集中同样带属性,但没有click标志。
而训练的目的就是给predict数据集打上这个click标志,所以一般train数据集是历史数据,而predict数据是待预测的数据。
03
模型训练
建一个训练文件02_train_data.py:
#!/user/bin/env python3
# -*- coding: utf-8 -*-
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
##导入XGB相关的库
from xgboost import XGBClassifier
from sklearn import metrics
from sklearn.externals import joblib
import time
##接下来对特征进行处理,先将类别特征进行编码
#针对类型类的特征,先进行编码,编码之前构建字典
def label_encode(field,df):
dic = []
df_field = df[field]
list_field = df_field.tolist()
#构建field字典
for i in list_field:
if i not in dic:
dic.append(i)
label_field = preprocessing.LabelEncoder()
label_field.fit(dic)
df_field_enconde_tmp = label_field.transform(df_field)
df_field_enconde = pd.DataFrame(df_field_enconde_tmp, index=df.index, columns=[(field+'_enconde')])
return df_field_enconde
#数据准备
def encode_data():
# 读入我们切割好的训练文件
file = './data/df_train.csv'
df = pd.read_csv(file)
print(f'--All data:{df.id.count()}')
y_1_nums = df[df["click"] == 1].id.count()
y_0_nums = df[df["click"] == 0].id.count()
print(f'--1 data:{y_1_nums}')
print(f'--0 data:{y_0_nums}')
print(f'--0 VS 1 => {round(y_0_nums / y_1_nums, 2)}:1')
# 特征编码
df_site_id_enconde = label_encode('site_id', df)
df_site_domain_enconde = label_encode('site_domain', df)
df_site_category_enconde = label_encode('site_category', df)
df_app_id_enconde = label_encode('app_id', df)
df_app_domain_enconde = label_encode('app_domain', df)
df_app_category_enconde = label_encode('app_category', df)
df_device_id_enconde = label_encode('device_id', df)
df_device_ip_enconde = label_encode('device_ip', df)
df_device_model_enconde = label_encode('device_model', df)
#特征拼接
df_input = pd.concat([df[['click','banner_pos','device_type','device_conn_type'
,'C1','C14','C15','C16','C17','C18','C19','C20','C21']]
,df_site_id_enconde
,df_site_domain_enconde
,df_site_category_enconde
,df_app_id_enconde
,df_app_domain_enconde
,df_app_category_enconde
,df_device_id_enconde
,df_device_ip_enconde
,df_device_model_enconde], axis=1)
return df_input
#效果输出函数
def func_print_score(x_data, y_data, data_type, model_x):
y_pred = model_x.predict(x_data)
print(f'==============({data_type})===================')
confusion = metrics.confusion_matrix(y_data, y_pred)
print(confusion)
print('------------------------')
auc = metrics.roc_auc_score(y_data, y_pred)
print(f'AUC: {auc}')
print('------------------------')
accuracy = metrics.accuracy_score(y_data, y_pred)
print(f'Accuracy: {accuracy}')
print('------------------------')
report = metrics.classification_report(y_data, y_pred)
print(report)
print('=============================================')
#训练模型
def train_data(df_input):
#对数据进行分割,分割为训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(df_input.iloc[:,1:],df_input["click"],test_size=0.3, random_state=123)
begin_time = time.time()
print(f'Begin Time : {time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(begin_time))}')
##受限于机器的资源,这里就不做gridsearch调参了,直接凑合着来(按最小资源消耗来设置参数)
model = XGBClassifier(learning_rate=0.1
,n_estimators=10
,max_depth=3
,objective='binary:logistic'
)
model.fit(x_train, y_train, eval_metric="auc")
end_time = time.time()
print(f'End Time : {time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(end_time))}')
if __name__=='__main__':
df_input=encode_data()
model=train_data(df_input)
#保存模型
joblib.dump(model, './model/xgb_model.pkl')
这里简单的封装几个函数,上面split数据的由于太简单了,就直接执行了。
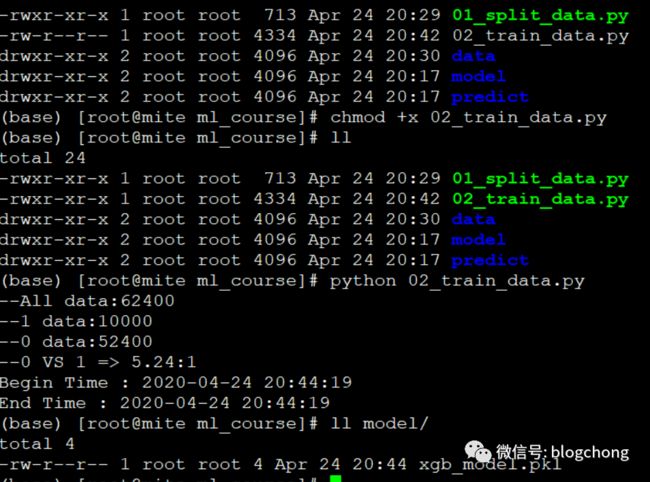
可以看到打印的一些信息和模型已经生成。
有了模型以ready好的预测数据(所谓ready就是预测数据带上了特征),我们可以用这个模型来预测数据了。
04
预测数据
创建一个03_predict_data.py
#!/user/bin/env python3
# -*- coding: utf-8 -*-
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
from sklearn import preprocessing
from sklearn.externals import joblib
from sklearn import metrics
from xgboost import XGBClassifier
##接下来对特征进行处理,先将类别特征进行编码
#针对类型类的特征,先进行编码,编码之前构建字典
def label_encode(field,df):
dic = []
df_field = df[field]
list_field = df_field.tolist()
#构建field字典
for i in list_field:
if i not in dic:
dic.append(i)
label_field = preprocessing.LabelEncoder()
label_field.fit(dic)
df_field_enconde_tmp = label_field.transform(df_field)
df_field_enconde = pd.DataFrame(df_field_enconde_tmp, index=df.index, columns=[(field+'_enconde')])
return df_field_enconde
#数据准备
def encode_data():
# 读入我们切割好的预测文件
file = './data/df_predict.csv'
df = pd.read_csv(file)
# 特征编码
df_site_id_enconde = label_encode('site_id', df)
df_site_domain_enconde = label_encode('site_domain', df)
df_site_category_enconde = label_encode('site_category', df)
df_app_id_enconde = label_encode('app_id', df)
df_app_domain_enconde = label_encode('app_domain', df)
df_app_category_enconde = label_encode('app_category', df)
df_device_id_enconde = label_encode('device_id', df)
df_device_ip_enconde = label_encode('device_ip', df)
df_device_model_enconde = label_encode('device_model', df)
#特征拼接,注意,这里在实际中是没有click数据的
df_input = pd.concat([df[['id','click','banner_pos','device_type','device_conn_type'
,'C1','C14','C15','C16','C17','C18','C19','C20','C21']]
,df_site_id_enconde
,df_site_domain_enconde
,df_site_category_enconde
,df_app_id_enconde
,df_app_domain_enconde
,df_app_category_enconde
,df_device_id_enconde
,df_device_ip_enconde
,df_device_model_enconde], axis=1)
return df_input
if __name__=='__main__':
df_input=encode_data()
#加载模型
model = joblib.load('./model/xgb_model.pkl')
#预测数据
#这里我们先把id和原来的click摘出来,然后一会儿predict出来之后,用来对比一下预测结果
df_id_click=df_input.iloc[:,:2]
df_predict = df_input.iloc[:, 2:]
y_predict = model.predict(df_predict)
#将序列转换成df,原始是这样的array([0, 0, 0, ..., 0, 0, 0]),并字段命名为p_click
df_y_predict = pd.DataFrame(y_predict, columns=["p_click"], index=df_id_click.index)
#我们先把预测数据保存下来,在实际生产过程中,这个结果就可以拿去用了
df_output=pd.concat([df_id_click.iloc[:,:1], df_y_predict], axis=1)
df_output.to_csv('./predict/predict.csv')
#为了验证我们的预测结果,我们看下多少个完全预测对了
#合并新旧数据,click为真实的click,p_predict为预测的click
df_new_id = pd.concat([df_id_click, df_y_predict], axis=1)
df_new_id.to_csv('./predict/predict_pk.csv')
#我们适当打印一下差异
print(f'ALL ID: {df_id_click.id.count()}')
print(f'Disaccord ID: {df_new_id[df_new_id["click"] != df_new_id["p_click"]].id.count()}')
执行之后结果如下:
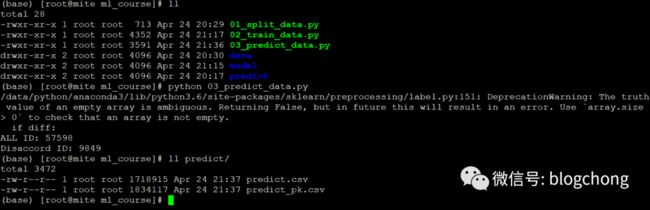
忽略掉告警,可以看到结果文件和PK对比文件已经保存。
预测的准确率=(57598-9849)/57598=82.9%,看着准确率(Accuracy)很高,但实际上是由于数据分布过于一致导致的,在实际生产环境中是不可能这么高的。
05
总结
首先微信看代码不好看,可以看github上的:
https://github.com/blogchong/data_and_advertisement/tree/master/code/ml_course/ml_02_ctr_python
记得给star,不要白嫖~~ 然后就是,如果想更有一个学习氛围,或者更多的参与互动,可以加入俺的知识星球,为初学者或者广告知识爱好者准备的坑,这里只做知识记录。
数据虫巢知识星球
【01】适合数据行业出入者。
【02】适合对于数据挖掘、算法感兴趣的朋友。
【03】适合对于数据方向职业困惑的朋友。
【04】适合对于广告与数据算法相关感兴趣的人。

文章都看完了,还不点个赞来个赏~
OTHER相关系列文章(初学者系列)
《【初学者系列】01-机器学习入门教程,启发式实例》
