本文观点来自对《如何成为一位数据科学家——大数据时代的统计学思考》(Rachel Schutt, Cathy O'Neil)的阅读。
文中并没有给出数据科学家的定义,但是给出了其应具有的技能:统计学、线性代数、编程技能、数据预处理、数据再加工、数据建模、可视化和有效沟通。而该篇文章只对统计学进行了介绍。
一、统计推断
“数据就是现实世界运转留下来的痕迹。而这些痕迹会被如何展示出来,则取决于我们采用什么样的数据收集和样本采集方法”。作为数据科学家,其任务是将现实世界转化为抽象数据,然后从抽象数据中发现知识,再将该知识应用于现实世界。这个过程可能不是一次性的,更可能是迭代的。因为未必一次发现的知识就是完全正确的。可能还要将该知识在现实世界中再进行验证,然后根据验证结果再进行一轮现实世界——数据抽象——现实世界的过程。这一从现实世界到数据,再从数据到现实世界的流程就是统计推断的领域。这门学科关注从过程产生的数据中提取信息,包含流程、方法和理论。由于整个过程中人(数据科学家)的存在,因此这并不是像人们想的那样是客观的,而是明显主观的。例如可以选择不同的过程,以及通过不同的方式采集得到不同的数据。
二、总体和样本
这个比较好理解,总体就是全部的观察对象,样本就是总体中的选取的一个子集。但这涉及到如何选取这个子集,即采样方法的问题。如果采样方法存在偏差,那么通过对样本的研究得出的结论也是有偏差的。
这里,作者提到了大数据。即如果有能力对所有数据进行分析,还需要进行采样分析吗?作者也并没有直接回答这个问题,而是指出即使在谷歌,数据科学家和统计学家都在用到采样来处理大数据。而且是否采样也取决于个人想实际解决的问题。
我的理解是,大数据技术(Hadoop,Spark等)提供了更有力量的一个手段来帮助人们进行更全面的分析,但它也有相应的代价,包括人力成本、计算成本和时间成本。就像杀鸡是否要用牛刀一样,不同问题还是适合用不同的工具来解决。因此采样统计仍然是解决问题的一个可选手段。
三、偏差
这里举了个有趣的例子,微软研究院的Kate Crawford女士提到,如果对飓风桑迪前后对推特数据进行分析,会得到如下结论:人们在飓风来临前在购物,飓风过后在聚会。这里的购物可不是为了应对飓风而大采购。好像这个结论告诉大家飓风对人们没什么影响。但实际上,由于分析的样本就不对,结论自然不对。推特的重度用户是纽约人,他们的确是完全不受飓风影响的,但那些受飓风影响的人们却不怎么发推特。这就是采样导致的偏差的一个例子。
四、新的数据类型
由于互联网的快速发展,要分析的数据类型也从原来简单的数据(数字、分类变量和二进制变量)发展为更加丰富的数据类型,包括:
文字:电子邮件、微博、网站上的文章等;
记录:用户数据、带有时间戳的事件记录和JSON格式的日志文件;
地理位置信息数据;
网络:这里应该指的是例如朋友关联、人际关系等事物之间连接关系构成的网络或图;
多媒体信息:包括图片、音频和视频等。
这些新数据类型的出现使得数据科学家在选择数据时应更谨慎,并且需要研究不同类型的分析方法。
作者还给出了其对“大数据”的理解:大数据是大是相对的,20世纪70年代的大数据概念和现在的大数据概念是不一样的。当用一台机器无法处理时,就可以称为“大数据”。
另外,作者并不认同库克耶和迈尔-舍恩伯格的文章“The Rise of Big Data”中的观点:接受数据中存在杂乱噪声;重视结论,放弃探究产生结果的原因。他们提出这观点的原因是,认为总体就是全部,有了全部,就能够得出正确的结论。但本文作者认为总体并不等于全部。因为总体其实也取决于数据科学家的判断,一旦判断出错,认为是全体研究对象产生了这些数据,但实际上只是部分研究对象产生的,就会发生错误。正如同上述的通过推特用户研究飓风影响的例子。也正因为此,作者提出“数据是不客观的”。
五、建模
作为一名数据科学家,建模是不可避免的研究数据的手段。通过建模找出数据的规律,并采用模型表示这些规律,以及用于在现实世界中进行进一步验证。模型有很多表达方式,在不同的学科和领域有不同的形式,比如建筑学中用蓝图和三维立体模型,分子生物学中用连接氨基酸的三维图像表示蛋白质结构,数据科学家用函数来描述数据的规律。
那么等于一堆看起来杂乱无章的数据,应该怎么建模呢?应该怎么选择模型呢?作者认为模型的选择一半是艺术,一半是科学。无非还是需要依靠假设、从最简单模型起步、探索性分析、反复尝试以及模型复杂度(建模代价)与模型准确率之间的权衡等方式。接着作者对建模时用到的最基本的概率分布进行了介绍。这些就是概率书本上的一些经典概率分布,这里直接引用了原文中的图:

另外,要避免建模过程中出现过拟合问题。所谓过拟合,也就是模型对于样本数据特别符合,但对于样本之外的数据却并不能准确描述。也就是说建立的模型失去了其普适性,往往是因为对于样本数据过于调优所致。
六、数据科学的工作流程
这里也直接引用原文中的图:
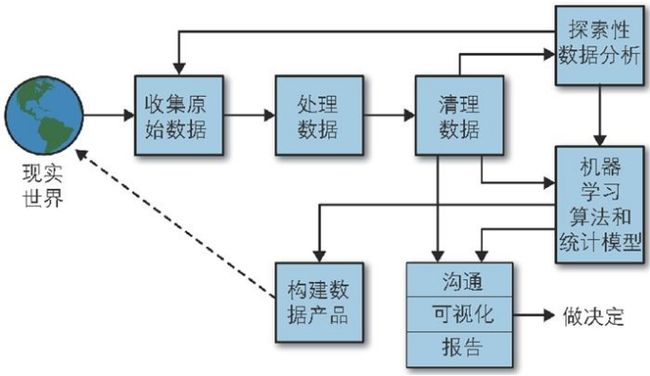
该流程中的几个活动从字面上都比较能直观地理解其含义。但可以看到几个特点:
活动之间有迭代。从探索性数据分析可能会回到收集原始数据,再进行一次迭代。因为探索性分析就有可能出现分析错误,所以需要再次进行从头开始。
活动不是按照固定步骤进行。没有固定的流程,有些活动是可以跳过的。例如清理数据后,可以选择机器学习算法训练模型,然后再进行沟通、可视化和报告,也可以清理数据结束就进入到沟通、可视化和报告。还有就是机器学习之后可以进入到构建数据产品。其实这些活动往往取决于此次数据分析的目的,有时候可以跳过某些活动,有时候这些活动可以并行执行。
模型结果要反馈回现实世界。就是图中的虚线箭头。因为一次分析往往只是对采样样本进行研究得到模型,但是否能够适用于更广大的未采样样本,还需要进一步验证。另外,得到了数据模型,往往是需要依据该模型进行决策,调整系统,然后将调整的系统再次在现实世界中运行,看是否能够达到调整预期。例如,根据对网站用户行为的建模,调整了推荐系统的推荐策略,实施后是否真的提升了网站的产品销售量,就需要进一步验证研究了。
七、数据科学家在数据科学工作流程中的角色
这里也引用了原文中的图:

其实,大家要注意,这张图只是举例这几个环节需要数据科学家做哪些活动,但并不是说数据科学家仅仅参与这几个环节,其实很容易想到他们肯定还要参与所有后续活动,如探索性数据分析、机器学习、沟通和构建数据产品等。
以上,就是基于原文对数据科学家的一个简单介绍。原文对几个观点的质疑还是比较中肯。例如对2008年《Wired》杂志主编Chris Anderson在杂志上发表的文章“The End of Theory: The Data Deluge Makes the Scientific Method Obsolete”中所认为的,数据即信息,有了数据就不需要哦行了,了解相关性就够了。并且说以海量数据为例,“谷歌根本没有使用模型”。显然上述说法明显是有问题的。还有就是对库克耶和迈尔-舍恩伯格提的“N=全部”观点的质疑。因此意见领袖由于不是该行业的专家,因此只是向广大群众介绍了相关概念和问题,但其说法并不一定准确。因此要对意见领袖的话保持自己一定的判断。
参考文献
1. 如何成为一位数据科学家——大数据时代的统计学思考, Rachel Schutt, Cathy O'Neil