mybatis-Plus 实践篇之CRUD操作
文章目录
- 快速开始
- 查询操作
- 新增操作
- 删除操作
- 修改操作
- 删除操作
- sql 性能分析插件
- 常用的条件构造器
- 多表操作还需添加的配置
上篇我们说了mybaits-plus的逆向工程的操作,这篇我们来说下CRUD操作吧,本来打算写一篇的,但是篇幅实在有点长;可读性不好,还是拆一下;
快速开始
这里就不重新建项目引入依赖了,我们直接在上篇的项目中开始
开始之前,我们需要开启打印下mybatis-plus在控制台打印的sql,只需要在yaml文件中加上如下配置即可
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
测试查询查看控制台输出:
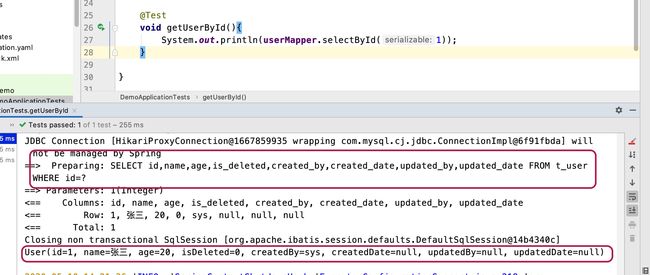
我们先来看下BaseMapper中有哪些方法,如下:

查询操作
添加分页拦截器,新建MpHandler如下:
package com.demo.study.config;
import com.baomidou.mybatisplus.core.handlers.MetaObjectHandler;
import org.apache.ibatis.reflection.MetaObject;
import org.springframework.context.annotation.Configuration;
import java.util.Date;
@Configuration
public class MpHandler {
// 分页插件
@Bean
public PaginationInterceptor paginationInterceptor(){
return new PaginationInterceptor();
}
}
测试查询
// 查询(使用的最多,单个,多个,数量,分页查询!)
@Test
void testSelectById(){
User user = userMapper.selectById(1L);
System.out.println(user);
}
@Test
void testSelectByIds(){
// 批量查询
List<User> users = userMapper.selectBatchIds(Arrays.asList(1, 2, 3));
users.forEach(System.out::println);
}
@Test
void testSelectByCount(){
// 查询数据量 SELECT COUNT(1) FROM user
Integer integer = userMapper.selectCount(null);
System.out.println(integer);
}
@Test
void testSelectByMap(){
// 简单的条件查询 不建议map查询而是querywrapper.setEntity
//HashMap map = new HashMap<>();
//map.put("name","张三");
//map.put("age",21);
//List users = userMapper.selectByMap(map);
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
User queryUser = new User();
user.setName("张三").setAge(21);
queryWrapper.setEntity(user);
List<User> users = userMapper.selectList(queryWrapper);
users.forEach(System.out::println);
}
// 分页实现 limit(sql) PageHelper Mp内置分页插件(导入即可!)
@Test
void testPage(){ // 当前页、总页数
//1、先查询总数
//2、本质还是 LIMIT 0,10 (默认的)
// 参数 (当前页,每个页面的大小!)
// 以后做分页就使用Page对象即可!
Page<User> page = new Page<>(2,5);
userMapper.selectPage(page,null);
System.out.println(page.getTotal());
System.out.println(page.hasNext());
System.out.println(page.hasPrevious());
page.getRecords().forEach(System.out::println);
System.out.println(page.getSize());
}
新增操作
user实体对应字段
// 配置主键自增策略 当然还有其他策略可以自行选择(还有雪花算法,手动设置,uuid等)
@ApiModelProperty(value = "主键")
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
//因为上篇文章中我们配置了这两个时间字段的自动填充策略,
//那么我们在执行插入和更新操作的时候就会自动更新为当前时间
@ApiModelProperty(value = "创建时间")
@TableField(fill = FieldFill.INSERT)
private Date createdDate;
@ApiModelProperty(value = "更新时间")
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updatedDate;
开始之前,我们还需要配置下注解处理器,处理时间的自动填充
MpHandler implements MetaObjectHandler
// 插入的策略
@Override
public void insertFill(MetaObject metaObject) {
// this.setFieldValByName()设置当前字段的值!
// String fieldName, Object fieldVal, MetaObject metaObjec
// 以后只要是插入操作就会自动控制
// createTime updateTime 使用 new Date() 进行填充
this.setFieldValByName("createdDate",new Date(),metaObject);
this.setFieldValByName("updatedDate",new Date(),metaObject);
}
// 更新策略
@Override
public void updateFill(MetaObject metaObject) {
this.setFieldValByName("updatedDate",new Date(),metaObject);
}
测试类中测试新增
// 因为这里我们主键配置的自增 时间配置了自动填充所以无需我们再处理
@Test
void testInsert(){
User user = new User();
user.setAge(18).setName("如花").setCreatedBy("echo");
userMapper.insert(user);
// mp 插入成功后主键会自动回显
System.out.println(userMapper.selectById(user.getId()));
}
注意:mp 没有提供批量插入,我们需要自己写xml sql来实现!
这里来回顾下,批量插入的写法
<insert id="batchInsert" useGeneratedKeys="true" keyProperty="id" parameterType="java.util.List">
insert into user
(name, age) values
<foreach collection="list" item="item" index="index" separator=",">
<trim prefix="(" suffix=")" suffixOverrides=",">
#{item.name,jdbcType=VARCHAR},
#{item.age,jdbcType=INTEGER}
trim>
foreach>
insert>
删除操作
// 删除(单个,多个)
@Test
void testDeleteById(){
userMapper.deleteById(1);
}
@Test
void testDeleteByIds(){
userMapper.deleteBatchIds(Arrays.asList(2,3,4,5));
}
一般,我们删除都采用逻辑删除,即将is_deleted改为1即可!
修改操作
开始之前我们先来了解下乐观锁、悲观锁!
乐观锁 : 非常乐观,无论什么操作都不加锁!(分布式环境怎么处理冲突问题呢?版本号)
悲观锁 : 非常悲观,无论什么操作都加锁!(性能问题)
当要更新一条记录的时候,希望这条记录没有被别人更新过,通常的方式就增加一个乐观锁字段即可 (version)
MP 对乐观锁也进行了支持!
- 1、添加version注解到字段上面
- 2、添加 乐观锁插件即可!
- 3、测试就自动带上了版本号!
数据库新增version字段我们设置初始值为1,那么它每次都会去上一次值做比较,如果是原值就证明没被改动过就更新,如果非原值就更新失败!
对应的user实体及数据库中我们也新增此version字段加上@version注解
@Version
private Integer version;
这里我们在MpHandler中加入 乐观锁拦截器
@Bean
public OptimisticLockerInterceptor optimisticLockerInterceptor(){
return new OptimisticLockerInterceptor();
}
接下来我们测试更新操作:
@Test
void testLock(){
User user = userMapper.selectById(2);
user.setName("老铁");
userMapper.updateById(user);
}
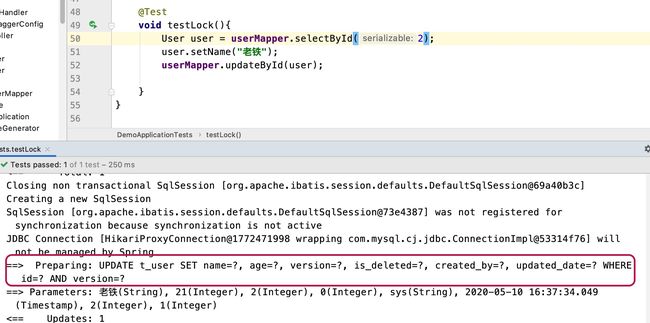
可以看到更新的时候它帮我们自动加上了这个version 字段
接下来我们来模仿下并发的情况下,因为version加锁更新失败的情况:
@Test
void testLockFail(){
// 老铁-> 狂铁
User initUser = userMapper.selectById(2);
initUser.setName("狂铁");
// x 先修改为 打铁
User xUser = userMapper.selectById(2);
xUser.setName("打铁");
userMapper.updateById(xUser);
// 改成 狂铁
userMapper.updateById(initUser);
}
执行查看控制台输出
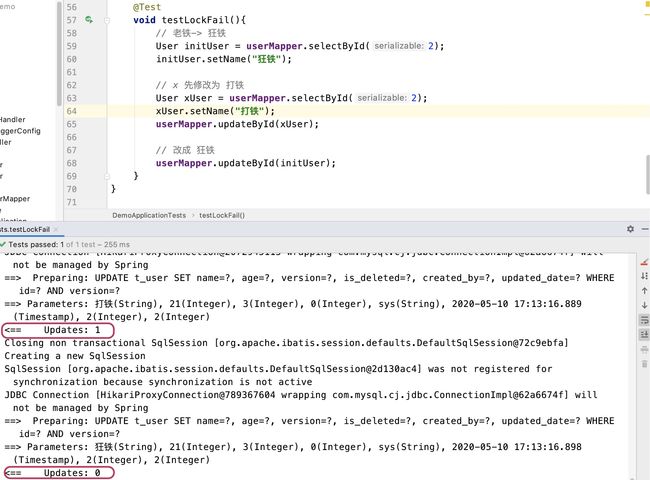
可以看到并发的情况下若是版本号被修改了,initUser则会更新失败!
删除操作
// 删除(单个,多个)
@Test
void testDeleteById(){
userMapper.deleteById(3);
}
@Test
void testDeleteByIds(){
userMapper.deleteBatchIds(Arrays.asList(4,5,6);
}
// 简单的条件删除
@Test
void testDeleteByMap(){
HashMap<String, Object> map = new HashMap<>();
map.put("name","张三");
map.put("age",20);
userMapper.deleteByMap(map);
}
但是我们实际开发中基本不这么干,只是更新is_deleted字段,改成逻辑删除!
然后我们查询的时候只会把没有删除的查询出来,添加@TableLogic
这里因为我们在代码生成器中指定了删除标识字段,所以这个注解自动加上了
@TableLogic 所标注的字段是一个逻辑删除字段
另外我们还需在yaml中增加逻辑删除值的配置
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
logic-delete-value: 1 #删除
logic-not-delete-value: 0 #未删除
MpHandler 中新增逻辑删除插件
@Bean
public ISqlInjector sqlInjector(){
return new LogicSqlInjector();
}
这两步完了之后,我们再测一下
@Test
void testDeleteById(){
userMapper.deleteById(4);
}
@Test
void testSelectById(){
userMapper.selectById(4);
}
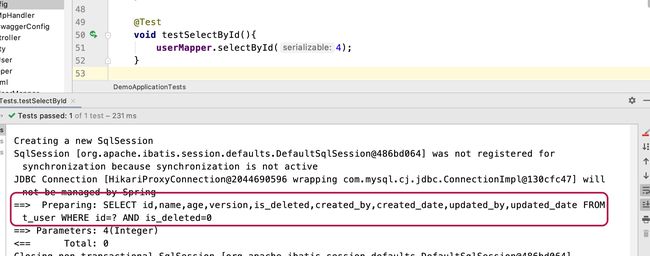
可以看到删除的数据我们这里已经查不到了,查询的时候自动给我们带上了is_deleted=0的条件
sql 性能分析插件
MpHandler 中加入以下拦截器,就可以拦截慢sql
// SQL执行效率插件
@Bean
@Profile({"dev","test"})// 设置 dev test 环境开启
public PerformanceInterceptor performanceInterceptor() {
PerformanceInterceptor performanceInterceptor = new PerformanceInterceptor();
// 允许执行的sql的最长时间 ,默认的单位是ms
performanceInterceptor.setMaxTime(2000);
return performanceInterceptor;
}
这里就不演示了,感兴趣的可以自行试下,maxTime改成1 试下,哈哈
根据控制台的报错信息或者说你配置了统一日志打印的话,可以根据里面的报错信息找到对应的慢sql
然后,我们就可以分析对应的问题(分库分表,索引,缓存等)
常用的条件构造器
就是大于,等于,小于,包含,不包含,子查询等
// 条件查询器
@Test
void testLogicDelete(){
QueryWrapper<User> wrapper = new QueryWrapper();
wrapper //
.isNotNull("name") .ge("age",21); // 大于等于
.eq("age",0);
userMapper.delete(wrapper);
}
// 边界查询
@Test
void testSelectCount(){
QueryWrapper<User> wrapper = new QueryWrapper();
wrapper.between("age",20,25);
Integer integer = userMapper.selectCount(wrapper);
}
// 精准匹配
@Test
void testSelectList(){
QueryWrapper<User> wrapper = new QueryWrapper();
HashMap<String, Object> map = new HashMap<>(16);
map.put("name","李四");
wrapper.allEq(map);
List<User> users = userMapper.selectList(wrapper);
}
// 模糊查询
@Test
void testSelectMaps(){
QueryWrapper<User> wrapper = new QueryWrapper();
wrapper.notLike("name","e")
.likeRight("email","t");
List<Map<String,Object>> = userMapper.selectMaps(wrapper);
maps.forEach(System.out::println);
}
// 子查询
@Test
void testSelectObjs(){
QueryWrapper<User> wrapper = new QueryWrapper();
// 条件in查询
wrapper.in("id",1,2,3,4);
// 子查询!
wrapper.inSql("id","select id from user where id < 3");
List<Object> objects = userMapper.selectObjs(wrapper);
objects.forEach(System.out::println);
}
// and or
@Test
void testUpdate(){
// 修改值
User user = new User();
user.setAge(99).setName("老佛爷");
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
// 在一些新的框架中,链式编程,lambda表达式,函数式接口十分常用!
updateWrapper.like("name","张三")
.or(i->i.eq("name","李四")
.eq("age",0));
int update = userMapper.update(user, updateWrapper);
}
// 排序
@Test
void selectList(){
QueryWrapper<User> wrapper = new QueryWrapper();
wrapper.orderByAsc("id");
wrapper.orderByDesc("id");
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
@Test
void tSelectList(){
// 多表查询解决方案 last (不建议使用,相当于直接拼接到sql 后面)
// 尽量使用单表查询
// 如果要多表查询,没有简便方法,就只有xml 中自己写了!
QueryWrapper<User> wrapper = new QueryWrapper();
wrapper.last("limit 1");
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
多表操作还需添加的配置
如果,单表查询不满足我们的要求的话,就需要自己写sql 查询了;
自己写sql的话,我们需要绑定mapper.xml 和实体的关系
mybatis-plus 需要增加以下配置
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
logic-delete-value: 1 # 已删除
logic-not-delete-value: 0 # 未删除
mapper-locations: classpath*:com/demo/**/*.xml
type-aliases-package: com.demo.**.entity
pom 文件中增加如下配置:
<build>
<resources>
<resource>
<directory>src/main/javadirectory>
<includes>
<include>**/*.xmlinclude>
includes>
resource>
resources>
build>
好了,至此我们已经完成了mybatis-plus crud语法的学习和常用插件的配置,那么就尽快使用起来吧;