tomcat下jsp乱码原因(下)
系列文章: tomcat下jsp乱码的原因
上一篇文章里面, 主要讲解了文件编码、页面编码、如何解码, 以及分析了tomcat所起到的作用, 猛戳这里详细了解 tomcat下jsp乱码的原因(上)
tomcat下jsp乱码原因(下) ,这里我们分为以下几点讲解下解决乱码的方式, 都是结合tomcat来的。
1、纯手工解码
2、setEncoding
3、get、post方法
4、通过配置tomcat参数
好了, 我们详细看看以上几个方法
1、纯手工解码
String abc1 = new String(abc.getBytes("ISO-8859-1"),"utf8");
String abc1 = new String(abc.getBytes("ISO-8859-1"),"utf8");让我们回顾下上篇文章中,tomcat的源码。
String encoding = getCharacterEncoding();
if (encoding == null)
encoding = "ISO-8859-1";
try{
RequestUtil.parseParameters(queryParameters, queryParamString, encoding);
}catch (Exception e){
;
} 这里我们首先看到tomcat默认把字符串设置成了iso8859, 但是是在getCharacterEncoding() 么有取到值的时候, 所以, 我们就有了一个比较简单的办法处理这个问题
1、在String abc = request.getParameter("abc");之前, 我们就可以写添加一句代码, 用来专门设置request的encoding, 这样tomcat在getCharacterEncoding()的时候
就可以取到我们定义的encoding,代码就是这样:
request.setCharacterEncoding("utf8");
String abc = request.getParameter("abc");action中, 就不用处理这个encoding, 这样更有利于统一处理编码, 当然如果做的更灵活可以把request.setCharacterEncoding("utf8");中的utf8做成参数话, 这样就更
灵活, 可以随时修改而不用重新编译程序了。
是不是更符合懒惰的思想作风, 呵呵, 确实比第一种方法简洁了很多。 但是这也是一把双刃剑, 简洁的同时,也隐藏了很多的内容, 很多项目里面大部分的人都是针对业务的, 如果没有接触的话, 那么很可能搞不清中间还有这些转换的事情的发生, 所以作为一个程序员应该提高自身的素质, 而不是仅仅的完成任务, 好了这个已经超出了我们的范围了。 好了说了些废话以后, 我们继续回到主题上来。
如果用上面的方法可以统一设置的话, 那我们就可以算是大功告成了, 那我们来试试运行效果吧。
上代码test.jsp
<%@ page language="java" isThreadSafe="true" pageEncoding="utf8" %>
<%@ page contentType="text/html; charset=gbk"%>
<%@ page language="java" isThreadSafe="true" pageEncoding="utf8" %>
<%@ page contentType="text/html; charset=utf8"%>
");
out.println("utf8编码:");
String abc1 = new String(abc.getBytes("ISO-8859-1"),"utf8");
System.out.println(abc1);
out.println(abc1);
out.println("
");
out.println("gbk编码:");
String abc2 = new String(abc.getBytes("ISO-8859-1"),"gbk");
out.println(abc2);
}
%>
abc返回
运行结果截图:
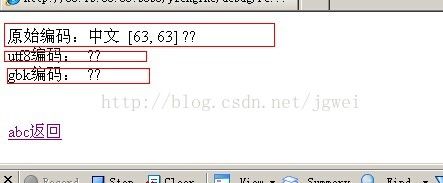
对应result.jsp 的代码, 我们可以看到我们的程序直接 String abc = request.getParameter("abc"); 这个时候获取的就是正常的, 如果再做编码转换的话, 就会乱码。
因为我们上一句代码就是request.setCharacterEncoding("gbk"), 所以后面再从getParameter里面去参数的时候, 无需再编码处理。 这完全符合上一篇文章中得出的。
test.jsp 什么编码,result.jsp 里面就怎么解码。下面我们把test.jsp 的代码稍作修改
<%@ page language="java" isThreadSafe="true" pageEncoding="utf8" %>
<%@ page contentType="text/html; charset=gbk"%>
然后再看结果:

唉, 又乱码了, 我们仅仅改了提交的方式, 页面又出现乱码了。 这是怎么回事?
虽然我们一肚子疑问, 但是至少可以得出这样的结论:
setCharacterEncoding 虽然简便, tomcat里面这个方法只能对post的方式的编码有效。 get方式无效。
下面我们先做些准备知识。
3、get、post方法
html的get和post的方法, 为啥要在这里列出这个问题呢? 我们先看看2个截图, 还是用上一篇文章中的test.jsp 和 result.jsp 作为例子:
首先我们test.jsp中设定成get的方法, 我们使用httpwatch 来观察下ie浏览器做了些什么?

首先我们test.jsp中设定成post的方法, 我们使用httpwatch 来观察下ie浏览器做了些什么?
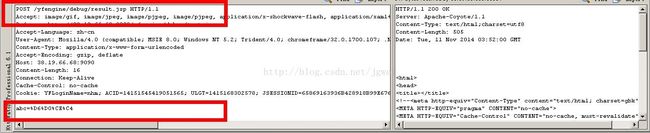
通过以上2附图,可以很清楚的看到我们的test.jsp的提交时候的变化。 一个参数在head, 一个参数在body。 (注:这个也是post可以数据更长的原因, 而get是有限制的, 当然还需要在tomcat里面设置参数, 这个另外说)有了这个基本的认识, 我们回到主题, 看看tomcat究竟怎么帮助我们处理这个编码问题。
我们深入tomcat源码一探究竟:
Daemon Thread [http-bio-9090-exec-2] (Suspended (breakpoint at line 251 in Parameters))
owns: SocketWrapper (id=172)
Parameters.processParameters(byte[], int, int, Charset) line: 251
Parameters.processParameters(MessageBytes, String) line: 501
Parameters.handleQueryParameters() line: 194
Request.parseParameters() line: 3072
Request.getParameter(String) line: 1145
RequestFacade.getParameter(String) line: 382
result.jsp line: 15
result_jsp(HttpJspBase).service(HttpServletRequest, HttpServletResponse) line: 70
result_jsp(HttpServlet).service(ServletRequest, ServletResponse) line: 727
JspServletWrapper.service(HttpServletRequest, HttpServletResponse, boolean) line: 432
JspServlet.serviceJspFile(HttpServletRequest, HttpServletResponse, String, boolean) line: 395
JspServlet.service(HttpServletRequest, HttpServletResponse) line: 339
JspServlet(HttpServlet).service(ServletRequest, ServletResponse) line: 727
ApplicationFilterChain.internalDoFilter(ServletRequest, ServletResponse) line: 303
ApplicationFilterChain.doFilter(ServletRequest, ServletResponse) line: 208
LoginFilter.MydoFilter(ServletRequest, ServletResponse, FilterChain) line: 170
LoginFilter.doFilter(ServletRequest, ServletResponse, FilterChain) line: 123
ApplicationFilterChain.internalDoFilter(ServletRequest, ServletResponse) line: 241
ApplicationFilterChain.doFilter(ServletRequest, ServletResponse) line: 208
StandardWrapperValve.invoke(Request, Response) line: 220
StandardContextValve.invoke(Request, Response) line: 122
NonLoginAuthenticator(AuthenticatorBase).invoke(Request, Response) line: 503
StandardHostValve.invoke(Request, Response) line: 170
ErrorReportValve.invoke(Request, Response) line: 103
AccessLogValve.invoke(Request, Response) line: 950
StandardEngineValve.invoke(Request, Response) line: 116
CoyoteAdapter.service(Request, Response) line: 421
Http11Processor(AbstractHttp11Processor).process(SocketWrapper) line: 1070
Http11Protocol$Http11ConnectionHandler(AbstractProtocol$AbstractConnectionHandler).process(SocketWrapper, SocketStatus) line: 611
JIoEndpoint$SocketProcessor.run() line: 316
ThreadPoolExecutor$Worker.runTask(Runnable) line: 895
ThreadPoolExecutor$Worker.run() line: 918
TaskThread$WrappingRunnable.run() line: 61
TaskThread(Thread).run() line: 695
然后我们看看源码里面tomcat究竟做了什么。贴上源码, 有点长:
/**
* Parse request parameters.
*/
protected void parseParameters() {
parametersParsed = true;
Parameters parameters = coyoteRequest.getParameters();
boolean success = false;
try {
// Set this every time in case limit has been changed via JMX
parameters.setLimit(getConnector().getMaxParameterCount());
// getCharacterEncoding() may have been overridden to search for
// hidden form field containing request encoding
String enc = getCharacterEncoding();
boolean useBodyEncodingForURI = connector.getUseBodyEncodingForURI();
if (enc != null) {
parameters.setEncoding(enc);
if (useBodyEncodingForURI) {
parameters.setQueryStringEncoding(enc);
}
} else {
parameters.setEncoding
(org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING);
if (useBodyEncodingForURI) {
parameters.setQueryStringEncoding
(org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING);
}
}
parameters.handleQueryParameters();
if (usingInputStream || usingReader) {
success = true;
return;
}
if( !getConnector().isParseBodyMethod(getMethod()) ) {
success = true;
return;
}
String contentType = getContentType();
if (contentType == null) {
contentType = "";
}
int semicolon = contentType.indexOf(';');
if (semicolon >= 0) {
contentType = contentType.substring(0, semicolon).trim();
} else {
contentType = contentType.trim();
}
if ("multipart/form-data".equals(contentType)) {
parseParts();
success = true;
return;
}
if (!("application/x-www-form-urlencoded".equals(contentType))) {
success = true;
return;
}
int len = getContentLength();
if (len > 0) {
int maxPostSize = connector.getMaxPostSize();
if ((maxPostSize > 0) && (len > maxPostSize)) {
if (context.getLogger().isDebugEnabled()) {
context.getLogger().debug(
sm.getString("coyoteRequest.postTooLarge"));
}
checkSwallowInput();
return;
}
byte[] formData = null;
if (len < CACHED_POST_LEN) {
if (postData == null) {
postData = new byte[CACHED_POST_LEN];
}
formData = postData;
} else {
formData = new byte[len];
}
try {
if (readPostBody(formData, len) != len) {
return;
}
} catch (IOException e) {
// Client disconnect
if (context.getLogger().isDebugEnabled()) {
context.getLogger().debug(
sm.getString("coyoteRequest.parseParameters"), e);
}
return;
}
parameters.processParameters(formData, 0, len);
} else if ("chunked".equalsIgnoreCase(
coyoteRequest.getHeader("transfer-encoding"))) {
byte[] formData = null;
try {
formData = readChunkedPostBody();
} catch (IOException e) {
// Client disconnect or chunkedPostTooLarge error
if (context.getLogger().isDebugEnabled()) {
context.getLogger().debug(
sm.getString("coyoteRequest.parseParameters"), e);
}
return;
}
if (formData != null) {
parameters.processParameters(formData, 0, formData.length);
}
}
success = true;
} finally {
if (!success) {
parameters.setParseFailed(true);
}
}
}
蓝色代码部分处理了get的参数
绿色代码处理了post的参数
红色部分是编码值的设置
我们先看看蓝色代码怎么处理get部分的参数
public void handleQueryParameters() {
if( didQueryParameters ) {
return;
}
didQueryParameters=true;
if( queryMB==null || queryMB.isNull() ) {
return;
}
if(log.isDebugEnabled()) {
log.debug("Decoding query " + decodedQuery + " " +
queryStringEncoding);
}
try {
decodedQuery.duplicate( queryMB );
} catch (IOException e) {
// Can't happen, as decodedQuery can't overflow
e.printStackTrace();
}
processParameters( decodedQuery, queryStringEncoding );
}其中: decodedQuery 是参数, queryStringEncoding 是编码, 可以看出处理get参数的编码, 只和queryStringEncoding 变量有关。
我们再回到上面一段代码看看 红色的部分
String enc = getCharacterEncoding();
boolean useBodyEncodingForURI = connector.getUseBodyEncodingForURI();
if (enc != null) {
parameters.setEncoding(enc);
if (useBodyEncodingForURI) {
parameters.setQueryStringEncoding(enc);
}
} else {
parameters.setEncoding
(org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING);
if (useBodyEncodingForURI) {
parameters.setQueryStringEncoding
(org.apache.coyote.Constants.DEFAULT_CHARACTER_ENCODING);
}
}而这个解析的地方, String enc = getCharacterEncoding();
是我们在result.jsp中设置的编码: request.setCharacterEncoding("gbk");
让我们看看处理post的代码
public void processParameters( byte bytes[], int start, int len ) {
processParameters(bytes, start, len, getCharset(encoding));
}
private Charset getCharset(String encoding) {
if (encoding == null) {
return DEFAULT_CHARSET;
}
try {
return B2CConverter.getCharset(encoding);
} catch (UnsupportedEncodingException e) {
return DEFAULT_CHARSET;
}
}如果没有设置的话, 就使用默认的 iso88589。
现在tomcat的处理逻辑比较清楚了:
post参数编码使用request.charEncoding
get参数编码使用Parameters.queryStringEncoding
4、通过配置tomcat参数
tomcat在这个问题上, 把get和post方法分开处理。我们只需要修改相应的参数就可以。
参数的位置和名称分别是config/server.xml
里面添加参数:
URIEncoding=“gbk”
是设置get时候的url编码的。
下面我们分别演示如何使用:
这里我们把server.xml的urlencoding设置成gbk, test.jsp编码目前也是gbk, 这时候是告诉tomcat说, 我的get方式的url参数是用gbk方式编码的。看一下结果:
当result.jsp是这样定义的:
String abc = request.getParameter("abc");
if(abc == null) {
out.println("空值");
}
else
{
out.println("原始编码:");
out.println(abc);
out.println(java.util.Arrays.toString(abc.getBytes("ISO-8859-1")));
out.println(new String(abc.getBytes("ISO-8859-1")));
out.println("
");
out.println("utf8编码:");
String abc1 = new String(abc.getBytes("ISO-8859-1"),"utf8");
System.out.println(abc1);
out.println(abc1);
out.println("
");
out.println("gbk编码:");
String abc2 = new String(abc.getBytes("ISO-8859-1"),"gbk");
out.println(abc2);
} 
对应代码和结果, 我们可以清楚的看到, 我们再使用iso8859方式进行解码的时候, 都出错了。 但是直接获取参数时候, 确实没有乱码。
好下面我们把test.jsp的方式改成post, result.jsp的方式不该, 我们看看结果:

可以看出这个地方的参数设置是针对get方式起效。这个我们可以再看看tomcat的源码来分析下原因
CoyoteAdapter.java
public void service(org.apache.coyote.Request req,
org.apache.coyote.Response res)
throws Exception {
Request request = (Request) req.getNote(ADAPTER_NOTES);
Response response = (Response) res.getNote(ADAPTER_NOTES);
if (request == null) {
// Create objects
request = connector.createRequest();
request.setCoyoteRequest(req);
response = connector.createResponse();
response.setCoyoteResponse(res);
// Link objects
request.setResponse(response);
response.setRequest(request);
// Set as notes
req.setNote(ADAPTER_NOTES, request);
res.setNote(ADAPTER_NOTES, response);
// Set query string encoding
req.getParameters().setQueryStringEncoding
(connector.getURIEncoding());
}从上一节的分析,我们可以知道这个uriencoding因为只和和 queryStringEncoding 有关系, 所以只有get方式生效, 而post方式没有关系。
最后我们再看看参数: useBodyEncodingForURI , 从源码可以看到
boolean useBodyEncodingForURI = connector.getUseBodyEncodingForURI();
if (enc != null) {
parameters.setEncoding(enc);
if (useBodyEncodingForURI) {
parameters.setQueryStringEncoding(enc);
}
}可以理解为 如果设置了 useBodyEncodingForURI = true , 则 queryStringEncoding 会和charEncoding 同步
也就是post和get的编码相同。同时这个URIEncoding失效。
絮絮叨叨又写了这么多, 写了这么多年, 其实这一总结才发现其实有些概念也是第一次了解, 以前都是只知道结果, 并不知道结果, 其实还有很多细节看样子也没有办法一下子就涉及到并且讲清楚。 以后有机会再说。 欢迎交流