两个非常有意思的适合桌面使用的Linux task调度器: BFS和MuqSS
大家都知道Linux内核task调度器经历了O(n),O(1)调度器,目前是CFS,期间也出现了几个优秀的候选调度器,但最终都没能并入内核,我们只能从一些零散的patch和文章中知道它们的存在。
但Linux内核的世界乃是非常之宽广,在主线内核之外还有很多支线可供观摩。
本文我来介绍Linux主线内核之外的两个非常有意思的适合桌面使用的task调度器BFS和MuqSS。
Linux内核其实有很多支线分支,其中Linux-CK就是著名的一支:
Con Kolivas的信仰是 万事不能一刀切,没有放之四海而皆准的真理! 所以,他主要关注Linux桌面,他不相信存在one-size-fits-all的调度器,所以他设计了专门适用于桌面交互的BFS。
BFS不是一个普适的task调度器,相反,它仅仅适用于桌面交互的环境。所以,为你的水冷游戏机使用BFS,而不是在携带众核CPU嗡嗡作响的2U服务器上使用它。
MuqSS则是BFS的改进版。MuqSS的全称是 Multiple Queue Skiplist Scheduler。
有必要先介绍一下什么是BFS,然后我们看MuqSS进行了什么改进。
简单来讲,BFS是一种向O(n)算法的回归,Con Kolivas认为:
桌面系统的task数量不会太多。
对于主线内核的调度算法太复杂。
基于这种认知,Con Kolivas设计了BFS。他认为 让一个支持4096个CPU的调度器去调度桌面交互应用的task是错误且可笑的做法 ,下面的BFS宣传漫画说明了这一点:
本文主要概括BFS以及其增强版MuqSS的核心思路而不是实现细节。
关于BFS的细节请参考下面的一篇文章:
https://blog.csdn.net/dog250/article/details/7459533
BFS的核心数据结构非常简单,就是普通双向链表,每次选择task时,该链表会被遍历,具有最小 Virtual Deadline 的task将会被选中。
显然,这个过程的时间复杂度是O(n)。其中, Virtual Deadline 的计算方法如下:
BFS虽然简单,但是两个问题却非常明显:
遍历查找的O(n)问题。
多CPU操作全局链表的锁问题。
众所周知, “O(n)时间复杂度和锁” 在计算机领域一直饱受诟病,它们似难兄难弟一般的存在。BFS却毫不忌讳地同时将它们采纳到自己的核心算法中。
对此,Con Kolivas的解释就是 保持实现的简单:
启发式的复杂算法终究还是启发式的,总是伴随误判。在单一的环境中,与其以庞大的代码量维持不必要的启发式算法,不如放弃启发式算法,退回到最简单的数据结构和代码实现。
我们看看BFS的算法简单到何种程度:
task插入:直接将task插入链表末尾。
task选择:冒泡选择Virtual Deadline最小的task。
如果要实现Virtual Deadline的预排序,必然要在下面二者之间作出权衡:
链表操作的O(n)时间复杂度代价。
复杂数据结构实现的代价和副作用。
最终,Con Kolivas认为:
在task数量并不太大的情况下,O(n)算法没有任何问题。
在CPU数量保持在16个以内时,争锁的开销可以忽略。
因此,没有必要为了可以忽略不计的问题而付出复杂性的代价。
所以,结论是BFS很好,它显示出了一种干练。有人如此评价BFS, “快 !人能感觉到的快!”
问题确实存在,Con Kolivas只是觉得为了解决那些在桌面环境下不足以带来严重影响的问题而以引入复杂性为代价,这不值得。除非可以在保持简单的前提下零代价解决问题!
有这样的方案吗?
当然有!这就是MuqSS的算法!
MuqSS零代价解决了BFS存在的两个问题:
遍历查找的O(n)问题。O(logn)的插入代价下将查找的时间复杂度降为O(1)。
https://blog.csdn.net/dog250/article/details/46997155】
多CPU操作全局链表的锁问题。
Con Kolivas在 保持简单 这个约束下设计了MuqSS,其要点是:
Skiplist的作用类似主线Linux内核CFS中的红黑树,但比红黑树简单得多。
选择task的算法遍历所有CPU的Skiplist表头,选择当前全局最优task。
锁粒度细化到每个CPU的Skiplist。
遍历过程针对每CPU锁采用trylock,失败则继续下一个CPU,实现无锁化。
我们看一下MuqSS调度算法中选择task的具体操作流程: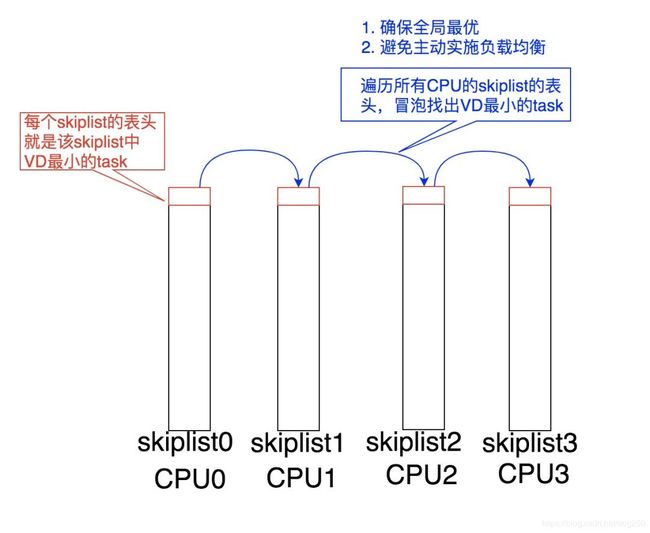
和BFS不同,BFS是在全局的链表中遍历找VD最小的task,而MuqSS则遍历每CPU链表的表头查找VD最小的task。
之所以要遍历所有CPU的Skiplist上的表头,是因为每次查找操作均要找到一个全局最优解,这样也就消除了主动负载均衡的必要,极大降低了算法的复杂性。
时间复杂度同样都是O(n),但MuqSS的n指的是CPU数量而非task数量。我们看一下MuqSS选择task算法相比BFS的改进: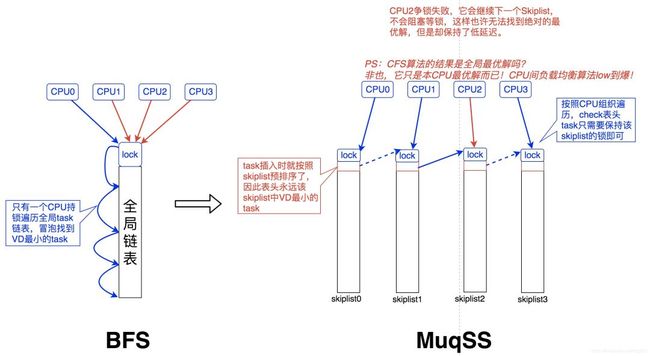
下面,我摘录并精简Con Kolivas补丁集中的相关函数,给出一个观感上的体会。
首先我们看一下0.104版本的MuqSS的选择task算法,请侧重代码的注释而不是代码本身:
/*
* Task selection with skiplists is a simple matter of picking off the first
* task in the sorted list, an O(1) operation. The only time it takes longer
* is if tasks do not have suitable affinity and then we iterate over entries
* till we find the first that does. Worst case here is no tasks with suitable
* affinity and taking O(k) where k is number of processors.
*
* As many runqueues as can be locked without contention are grabbed via
* lock_rqs and only those runqueues are examined. All balancing between CPUs
* is thus done here in an extremely simple first come best fit manner.
*
* This iterates over runqueues in cache locality order. In interactive mode
* it iterates over all CPUs and finds the task with the earliest deadline.
* In non-interactive mode it will only take a task if it's from the current
* runqueue or a runqueue with more tasks than the current one.
*/
static inline struct
task_struct *earliest_deadline_task(struct rq *rq, int cpu, struct task_struct *idle)
{
// 冒泡基准
u64 earliest_deadline = ~0ULL;
...
lock_rqs(rq, &locked); // 这里还是统一上锁的版本
// 一个for循环,冒泡找出VD最小的task
for (i = 0; i < num_possible_cpus(); i++) {
struct rq *other_rq = rq->rq_order[i];
struct task_struct *p;
...
p = other_rq->node.next[0]->value;
...
if (!deadline_before(p->deadline, earliest_deadline))
continue;
earliest_deadline = p->deadline;
edt = p;
}
...
unlock_rqs(rq, &locked);
return edt;
}我删掉了不影响理解算法核心的代码,以突出重点,完整的代码请参看下面的链接:
http://ck.kolivas.org/patches/4.0/4.8/4.8-ck2/patches/0008-MuQSS-version-0.104.patch
我们再看下最新的版本中选择task的实现,它实现了查找过程的无锁化,代价只是稍微损失了全局最优的准确度:
/*
* Task selection with skiplists is a simple matter of picking off the first
* task in the sorted list, an O(1) operation. The lookup is amortised O(1)
* being bound to the number of processors.
*
* Runqueues are selectively locked based on their unlocked data and then
* unlocked if not needed. At most 3 locks will be held at any time and are
* released as soon as they're no longer needed. All balancing between CPUs
* is thus done here in an extremely simple first come best fit manner.
*
* This iterates over runqueues in cache locality order. In interactive mode
* it iterates over all CPUs and finds the task with the best key/deadline.
* In non-interactive mode it will only take a task if it's from the current
* runqueue or a runqueue with more tasks than the current one with a better
* key/deadline.
*/
#ifdef CONFIG_SMP
static inline struct task_struct
*earliest_deadline_task(struct rq *rq, int cpu, struct task_struct *idle)
{
struct rq *locked = NULL, *chosen = NULL;
for (i = 0; i < total_runqueues; i++) {
struct rq *other_rq = rq_order(rq, i);
skiplist_node *next;
...
if (other_rq->best_key >= best_key)
continue;
// 采用trylock的方式,如果锁定失败便继续尝试下一个CPU,不再阻塞等锁。
if (unlikely(!trylock_rq(rq, other_rq)))
continue;
...
next = other_rq->node;
while ((next = next->next[0]) != other_rq->node) {
struct task_struct *p;
// 这里增加了新的约束:并不是所有的skiplist表头的task都是无可厚非的候选者,某些条件下,它们也会落选的。
edt = p;
break;
}
...
}
...
return edt;
}完整的代码请参见下面的链接:
http://ck.kolivas.org/patches/muqss/5.0/5.2/0001-MultiQueue-Skiplist-Scheduler-version-0.193.patch
关于BFS以及MuqSS的核心原理就介绍到这里。关于MuqSS更详细的信息,出了上述给出的源码链接之外,其本身的Doc以及Lwn文章也是值得一读:
接下来我们看看作为Linux Kernel patch的BFS,MuqSS是怎样一种存在。
Linux内核的调度器并不是可插拔的,内核中不存在sched_class的任何注册接口和替换接口,这意味着如果你想实现自己的调度器,会非常麻烦。
当然,最直接的方式就是直接修改内核源码了,Con Kolivas便采用了这个方法从而分裂出了自己的分支,你可以在下面的链接找到他的patch:
MuqSS调度器是通过直接修改schedule函数实现的:
+static void __sched notrace __schedule(bool preempt)
+{
+ ...
+ next = earliest_deadline_task(rq, cpu, idle);
+ if (likely(next->prio != PRIO_LIMIT))
+ clear_cpuidle_map(cpu);
+ else {
+ set_cpuidle_map(cpu);
+ update_load_avg(rq, 0);
+ }
+
+ set_rq_task(rq, next);
+ next->last_ran = niffies;
由于MuqSS是专门针对桌面交互应用设计的调度器,而Linus本人则不认同主线内核中的任何专门化的定制设计,因此可以预见Con Kolivas的patch很难合入主线。
这背后是Linus Torvalds和Con Kolivas的理念之争:
Linus Torvalds讨厌一切定制。
Con Kolivas不相信one-size-fits-all。
Con Kolivas将长期维护他自己的CK分支或者如Linus本人那般,Con Kolivas也可能基于Linux-CK生成另一个自己的CK主线,彻底和Linux决裂!事实上,Con Kolivas早该这么做了,虽然名字里保留Linux字眼看上去有些不妥…
最后一个问题是,我要如何做才能享用MuqSS的收益呢?
确保你的环境是桌面环境,做下面的事:
下载4.9版本内核以上的社区主线代码。
在http://ck.kolivas.org/patches/4.0/找到对应版本的patchset,然后打上这些patch。
重新编译打上patch的内核,安装内核并启动新内核。
享用。
…
好了,这就是我要跟你讲的BFS和MuqSS的故事。
(完)
Linux阅码场精选在线视频课程汇总
更多精彩,尽在"Linux阅码场",扫描下方二维码关注

你的随手转发或点个在看是对我们最大的支持!