我们都知道CNN常用于图像处理,也可以用一般神经网络去训练,为什么使用卷积神经网络训练呢?我们训练一个一般神经网络往往希望每层训练出一个基本的分类模型,比如第一层识别颜色,或者特殊斜条纹,第二层就有了不同颜色的条纹等等组合,到最后我们就可以识别出像蜂巢,轮胎,人的上半身等等。但是一张图100*100,加上RGB三层就30000个数据,如果1000个神经元参数就就很多了,我们计算起来就很吃力,我们因此引入了卷积神经网络。
卷积神经网络你可能听着感觉比一般神经网络复杂,但其实他的模型是比一般神经网络简单的。

我们怎么判断一张图有没有鸟呢,我们事实上只需要判断是否有鸟嘴就行,判断鸟嘴只需要判断图中很小的一部分就可以,所以一个神经元可以不用看整张图来发现这个pattern

我们比较下2张鸟图,鸟嘴分别在不同的位置,一个左上,一个靠中间,我们并不需要做2个神经元分别匹配左上的鸟嘴和中间的鸟嘴,而是使用相同的权值,一个神经元来识别鸟嘴,可以节省参数

我们也可以用图片的2次采样,比如取出图片奇数列偶数行的值形成缩放图片,虽然图片变小但是并没有影响我们识别,减小图片有助于我们使用更少的参数建立网络

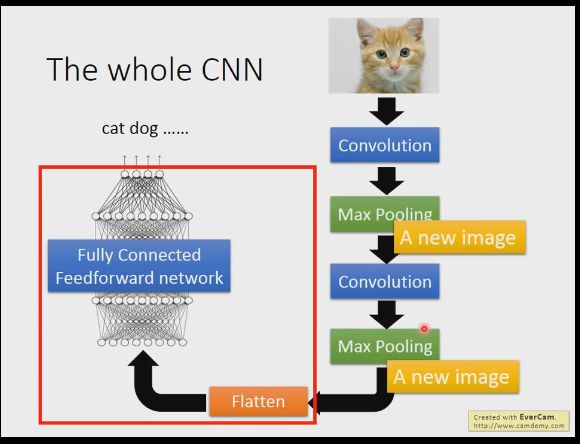
我们做卷积神经网络的一般步骤就是将图片信息经过卷积池化(可以多次)最后拉平,送到一个全连接神经网络里,最后输出我们的分类结果,卷积是使我们可以发现图片的样式pattern,池化可以使我们的图片实现缩放。

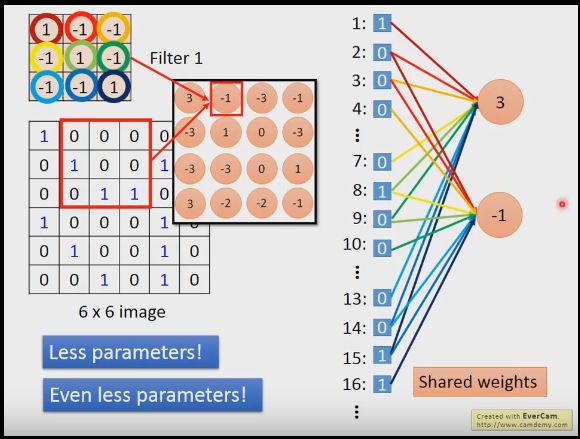
我们先提卷积层,其实卷积层就算是多个过滤器filter,每个过滤器有不同的参数,其实他们就是实现神经网络里的w,b功能,以3*3为例,不同的值就是在图中识别不同3*3区域的特征,

我们如何进行卷积呢,比如我们使用一个对角线都是1其余元素-1的3*3过滤器,将过滤器放置到图片左上角,进行内积,再向右移动,又得到一个内积结果,至于移动多少,需要我们指定stride,通常是1,向右到边缘后,我们移动到向下stride行的最左侧,然后再向右重复,如此直到过滤器计算完右下角,以图中6*6图片为例,经过卷积处理得到4*4矩阵,4,4矩阵左上左下最大,因为他们都满足符合对角线元素为1其他位0的特性,这也反映了进行pattern分类的效果
当然我们可以由很多个过滤器,不同过滤器对同一张图片可以得到不同的结果,一个RGB图像有3个通道,我们并不是把每个通道都用不同的过滤器,而是一个过滤器同时作用在3个通道上

我们是用卷积层时,一个神经元不用像全连接层连接所有输入,只需要连接9个,而且每个神经元共享权重,大大减小了参数的数量
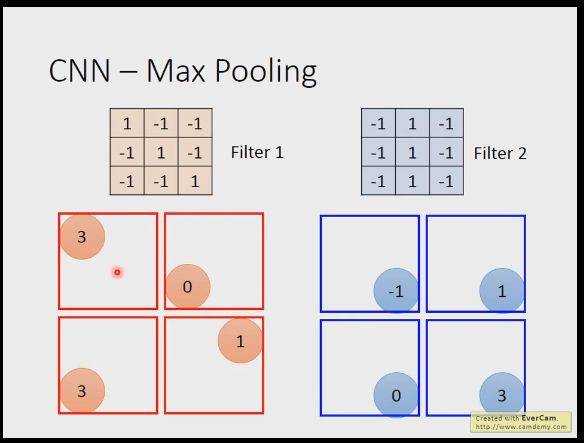
我们接下来将卷积层输出到池化层,池化层的方法有很多,可以选择最大值,也可以选择均值,,池化后图像尺寸进一步减小
我们卷积后,比如第一层有25个filter,第二次又有25个,那我们是25*25个吗,不是的,每层卷积过滤器是多少,我们就是多少个图,只不过每个图的维度了1维,值为25
Flatten就是把矩阵变成一维向量,输入到全连接神经网络进行使用,到全连接相信我们很熟悉了
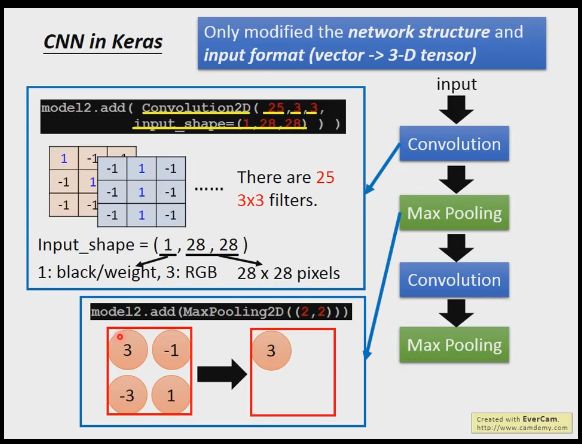
我们怎么在keras里做呢,我们的输入给卷积层的不再是普通矩阵,而是3维的张量,卷积层我们前三个参数是,25,3,3分别表示25层深度(或者叫25个过滤器),每个过滤器窗口尺寸3*3,input_shape的三个参数分别是,1表示图片是灰度图,如果是RGB,这个位置传3, 28,28表示我们识别手写数字的尺寸是28*28的。池化层,我们传入的参数是2,2,表示我们是将4个像素合并成1个
我们将1张28*28的图片送入25*3*3的过滤器,就得到了25*26*26的图像组,经过2*2池化,就得到了25*13*13的图像组,经过50*3*3的过滤器,就得到了50*11*11的图像组,再经过池化,最终得到50*5*5的图片组,我们2次卷积过滤虽然都是3*3的矩阵,但是2次矩阵的参数量是不一样的,第一次是9个,第二次由于第一次的25层深,所以参数量其实是25*9

老师课上没有讲解代码试验,我根据网上的修改了下,需要注意的是图片数据首先就需要reshape下,然后注意传递给Converlutional2D,Maxpooling2D的参数,改进后准确率97.7%
代码位置https://fishc.com.cn/forum.php?mod=viewthread&tid=132243&page=1&extra=#pid3800839
我们进行卷积神经网络,他到底学了什么,看下图,比如到了50*11*11的图像,第K个卷积层的i行,j列的元素是我们把整张图求和,反映出一个图片让这个卷积层激活的程度,我们模型确定的时候,就可以找到一张图像x,使这个激活程度最大,使用的是梯度上升的方法。

我们于是就有了如下的一组图,分别使过滤器最大,每个图分别捕获的是不同的纹理,方向分别不一样

我们接下来对全连接网络神经元做相类似的事情,求出使输入神经元激活函数前值最大的图,如下

我们又类似的从输出去找最激活的图,会发现如下图左,0-8看上去都不太像,但是这就是网络学到的最像0-8的数字,你将其输入就得到0-8

我们把图片激活最大引入正则项,图中L1正则左边应该是减号,就得到了下图右部分,有点数字隐约的意思,但也不是很像。

我们有一张图片,我们CNN学习后,把卷积层参数调大,正的更正,负的更负,将图片输出就会得到他识别到的强化图片。

强化后的图片中出现了很多‘念兽’- -

我们类似的就可以实现DeepStyle,算法可以参照图片网址,我们训练2张图片送给CNN,分别学到content和style,然后训练新的CNN同时使2这最小(梯度下降),就得到了新的融合风格图片

我们也可以用卷积神经网络来实现下围棋,我们可以用19*19的输入向量给全连接的前馈神经网络,但我们可以把19*19理解成一个图片,使用卷积神经网络训练得效果更好点。
我们什么时候使用CNN,是对象要有Image该有的特性

我们在alphago里虽然使用了cnn,但是却没有使用池化层,因为池化会影响下棋的判定,输入卷积层采用19,19,48即48深度的,第一层隐层将其先补0,做成23,23图像,然后采用5*5的卷积核,得到21,21的图像,然后再经过3,3的卷积核k个,k这里alphago取了192个

CNN还可以是做语音识别,例如我们把‘你好’作为输入,按时间和频率的关系可以形成下图,我们可以试图开一个窗口,把其作为Image交给CNN处理,只不过卷积层只有按照频率的步进,没有按照时间的步进,因为时间上的关系,我们可以交给后续网络去处理,而比如男的和女的说你好,一般就是略微的频率的差别,但是pattern基本是一致的

CNN还可以用于文本处理,我们建立文本语句维度(时间维度)和embedding dimension维度(老师也没说清楚什么鬼),这时还是将其看成一个Image,这次我们移动的维度是时间上移动

我们想了解更多CNN有关知识,可以去下图中的网址

如果想知道如何让机器学会画一张图,我们可以参考如下网址
