用selenium爬取58同城租房信息(万级数据)
今天想做一个58同城的爬虫,然后到页面分析一下链接,发现58同城的链接的有些参数是由js动态生成的,然后我就想偷懒了。(当然其实去js文件中找到生成式并不难),但我就是不想去找。然后就想到了selenium,各种工具都常拿出来溜溜,才能用的好!
python + selenium + (head_less)Chrome,然后用BeautifulSoup解析数据,完成了。
我们来一步步的看,首先我们要生成一个驱动器的对象吧
from selenium import webdriver
options = webdriver.ChromeOptions()
options.set_headless()
# 无头
options.add_argument('--diable-gpu')
# 禁用gpu
driver = webdriver.Chrome(options=options)
# 生成了一个无头的Chrome的驱动器对象对了,我们还是把我们的目标截图看一下吧!
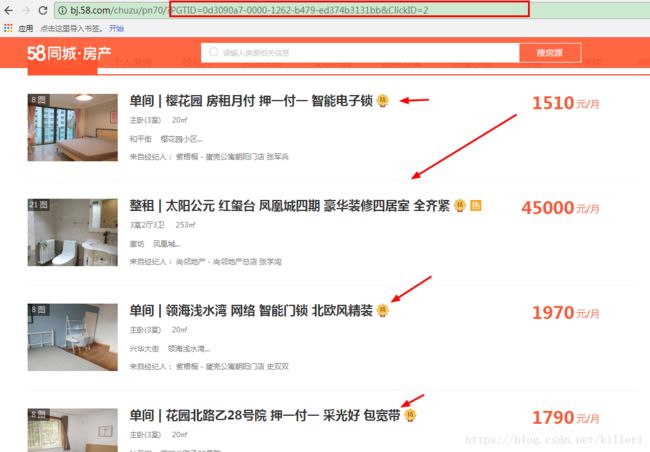
框起来的部分是有js文件动态生成的参数,我们的目标是箭头指向的部分。
好了,目标给你们看了,像这样的页面一共有70页,每页有60个房子的信息(别说我骗你只有4200条数据不是万级数据,那你可以换城市呀!)
首先我们实现这个页面的爬取,看代码:
content = driver.page_source.encode('utf-8')
# 获取页面资源
Soup = BeautifulSoup(content,'lxml')
# 用BeautifulSoup库进行解析,结合BeautifulSoup
li_list = Soup.find(attrs={'class':'content'}).find_next(attrs={'class':'listUl'}).find_all('li')
# 解析
for li in li_list:
try:
if li.has_attr('logr'):
# 因为渲染过的页面上还有一种公寓的信息,是我不要的,这里的这个判断语句相当于一个赛选
img_list = li.div.find_next('img').get('src')
img_num = li.find_next('span').get_text()
des = li.find(attrs={'class': 'des'})
h2 = des.h2.a.get_text()
room = des.find(attrs={'class': 'room'}).get_text()
jjr = des.find(attrs={'class': 'jjr'}).get_text(strip=True)
listliright = li.find(attrs={'class': 'listliright'})
sendtime = listliright.find(attrs={'class': 'sendTime'}).get_text()
money = listliright.find(attrs={'class': 'money'}).get_text()
writer.writerow([img_list, img_num, h2, room, jjr, sendtime, money])
# 这里是写进文件,我们传进来一个写的对象,后面会看到
else:
continue
except AttributeError:
continue
# 有错误什么的都进跳过代码的注释很详细把,就不用说了吧,这是对一个页面的提取信息
这是一个页面,我们要进行多个页面的跳转呀,所以这时selenium的元素定位就出来了。
我们找到这个“下一页”的元素,然后点击,就可以进入下一页了!
代码如下:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
wait_time = WebDriverWait(driver,10,0.5)
# 设置显式等待的时间
next_element = wait_time.until(EC.element_to_be_clickable((By.CLASS_NAME,'next')))
# 定位到页面的“下一页”的按钮,并进行点击
next_element.click()
# 这样就进入下一页了好了,通过以上两步,我们就可以实现页面数据的提取和页面的跳转了,关键的两步都已经完成了,现在只剩下,数据的写入和逻辑的实现了
接下来我们对函数进行一个递归的调用,实现的代码的复用,具体的话你可能要看完整的代码了
贴出来:
# _*_ coding : utf-8 _*_
import csv
import random
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
options = webdriver.ChromeOptions()
options.set_headless()
options.add_argument('--diable-gpu')
driver = webdriver.Chrome(options=options)
wait_time = WebDriverWait(driver,10,0.5)
# 这里设置隐式等待的时间
# 设置无头Chrome进行作业
# 直接定位到要爬取的网页,不用有一个过程的
#driver.get_screenshot_as_file('58.png')
# 截屏
#get_html = driver.find_element(By.TAG_NAME, 'html')
# 定位到这个get_html元素
def parse_dom(driver,writer):
content = driver.page_source.encode('utf-8')
# 获取页面资源
Soup = BeautifulSoup(content,'lxml')
# 用BeautifulSoup库进行解析,结合BeautifulSoup
li_list = Soup.find(attrs={'class':'content'}).find_next(attrs={'class':'listUl'}).find_all('li')
# 解析
for li in li_list:
try:
if li.has_attr('logr'):
# 因为渲染过的页面上还有一种公寓的信息,是我不要的,这里的这个判断语句相当于一个赛选
img_list = li.div.find_next('img').get('src')
img_num = li.find_next('span').get_text()
des = li.find(attrs={'class': 'des'})
h2 = des.h2.a.get_text()
room = des.find(attrs={'class': 'room'}).get_text()
jjr = des.find(attrs={'class': 'jjr'}).get_text(strip=True)
listliright = li.find(attrs={'class': 'listliright'})
sendtime = listliright.find(attrs={'class': 'sendTime'}).get_text()
money = listliright.find(attrs={'class': 'money'}).get_text()
writer.writerow([img_list, img_num, h2, room, jjr, sendtime, money])
else:
continue
except AttributeError:
continue
# 有错误什么的都进跳过
try:
next_element = wait_time.until(EC.element_to_be_clickable((By.CLASS_NAME,'next')))
# 定位到页面的“下一页”的按钮,并进行点击
next_element.click()
# 点击过后,driver对象就是下一页的内容了,这里不要纠结
# 注意:在某些时候,点击一个按钮会出现一个新的窗口,这是就要注意切换窗口了。
driver.get_screenshot_as_file('D:/selenium/{name}.png'.format(name=random.uniform(0,39)))
# 别问我这个39什么意思,什么意思也没有,我就是随便选的
# uniform是选取浮点数,如果你想用整数可以用randint
# 截频每次爬取的网页,并随机生成一个图片的名字
print(1)
# 这是我给自己视觉上的一个信号,不然我不知道它在爬取呀!!!!!
parse_dom(driver,writer)
# 进行一个递归的循环
except NoSuchElementException:
print('已经到了末尾了!')
return
# 到了末尾自然就找不到“下一页”那个元素了,这是就可以报错了
# 就可以return,停止运行了
def main():
driver.get(url='http://bj.58.com/chuzu/?PGTID=0d200001-0000-1fd1-f53b-dedf284b5de1&ClickID=1')
with open('58city.csv','a',encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['img_list', 'img_num', 'h2', 'room', 'jjr', 'sendtime', 'money'])
# 建立一个writer对象并写入title
parse_dom(driver,writer)
# 这个函数我实现的是一个递归的调用
if __name__ == '__main__':
main()
# 执行主函数完成了爬取,成果的话,贴出来,不过我并没有爬完(限速的我伤不起,还要试一下怎么用scrapy结合selenium进行爬取)
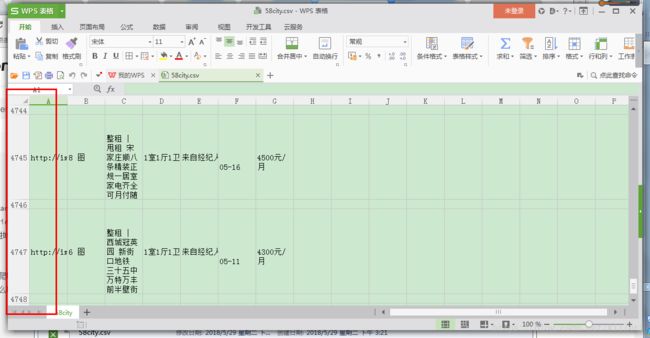
如图,我大概只爬取了两千条的数据。