深度学习笔记7:激活函数层的实现
如果有什么疑问或者发现什么错误,欢迎在评论区留言,有时间我会一一回复
激活函数是用来引入非线性因素的。网络中仅有线性模型的话,表达能力不够。比如一个多层的线性网络,其表达能力和单层的线性网络是相同的(可以化简一个3层的线性网络试试)。我们前边提到的卷积层、池化层和全连接层都是线性的,所以,我们要在网络中加入非线性的激活函数层。一般一个网络中只设置一个激活层。
激活函数一般具有以下性质:
非线性: 线性模型的不足我们前边已经提到。
处处可导:反向传播时需要计算激活函数的偏导数,所以要求激活函数除个别点外,处处可导。
单调性:当激活函数是单调的时候,单层网络能够保证是凸函数。
输出值的范围: 当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate.
常见激活函数介绍:
实际中可选用的激活函数有很多,如下图:
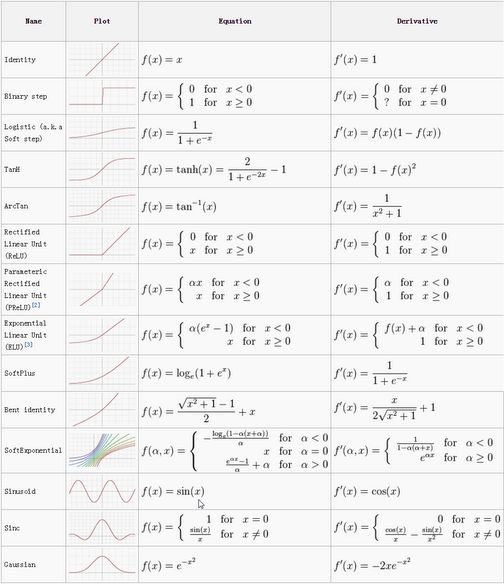
但不同的激活函数效果有好有坏,现在一般比较常见的激活函数有sigmoid、tanh和Relu,其中Relu由于效果最好,现在使用的比较广泛。3种激活函数具体介绍如下:
Sigmoid函数
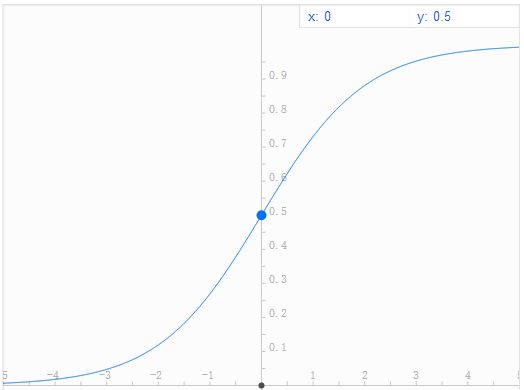
Sigmoid函数表达式为: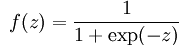 ,它将输入值映射到[0,1]区间内,其函数图像如下图(谷歌和百度搜索框输入表达式就能给出图像,挺好用的)。
,它将输入值映射到[0,1]区间内,其函数图像如下图(谷歌和百度搜索框输入表达式就能给出图像,挺好用的)。
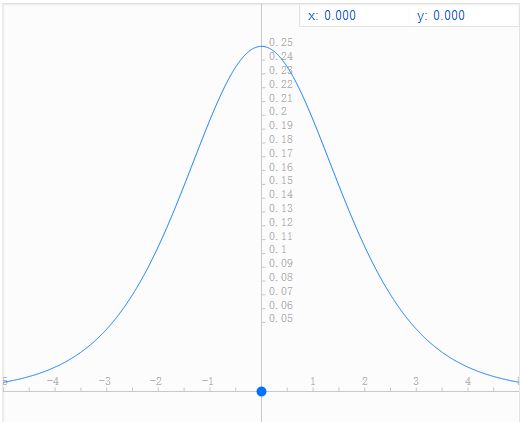
Sigmoid有一个十分致命的缺点就是它的导数值很小(sigmoid函数导数图像如下图),其导数最大值也只有1/4,而且特别是在输入很大或者很小的时候,其导数趋近于0。这直接导致的结果就是在反向传播中,梯度会衰减的十分迅速(后面公式的推导过程会证明这一点),导致传递到前边层的梯度很小甚至消失,训练会变得十分困难。
还有就是sigmoid函数的计算相对来说较为复杂(相对后面的relu函数),耗时较长,所以由于这些缺点,现在已经很少有人使用sigmoid函数。
Tanh函数
Tanh函数表达式为: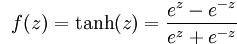 ,其图像为(函数复杂点百度就画不了了
,其图像为(函数复杂点百度就画不了了
 ):
):
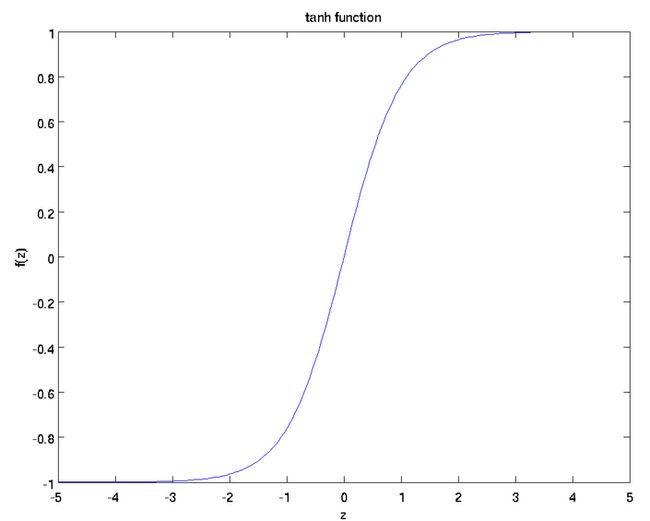
Tanh函数现在也很少使用。
Relu函数
Relu函数为现在使用比较广泛的激活函数,其表达式为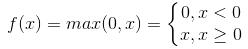 。当输入x<0时,输出为0;当x>0时,输出等于输入值。
。当输入x<0时,输出为0;当x>0时,输出等于输入值。

Relu函数相对于前边2种激活函数,有以下优点:
1、relu函数的计算十分简单,前向计算时只需输入值和一个阈值(这里为0)比较,即可得到输出值。在反向传播时,relu函数的导数为 。计算也比前边2个函数的导数简单很多。
。计算也比前边2个函数的导数简单很多。
2、由于relu函数的导数为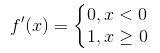 ,即反向传播时梯度要么为0,要么不变,所以梯度的衰减很小,即使网路层数很深,前边层的收敛速度也不会很慢。
,即反向传播时梯度要么为0,要么不变,所以梯度的衰减很小,即使网路层数很深,前边层的收敛速度也不会很慢。
Relu函数也有很明显的缺点,就是在训练的时候,网络很脆弱,很容易出现很多神经元值为0,从而再也训练不动。一般我们将学习率设置为较小值来避免这种情况的发生。
为了解决上面的问题,后来又提出很多修正过的模型,比如Leaky-ReLU、Parametric ReLU和Randomized ReLU等,其思想一般都是将x<0的区间不置0值,而是设置为1个参数与输入值相乘的形式,如αx,并在训练过程对α进行修正。
激活函数层的推导
激活函数层的前向计算
这里我以relu层为例介绍一下激活函数层的推导,由于relu层没有参数,所以不需要进行权值的更新,只需进行梯度的传递。下图还是我们熟悉的那个网络,其中倒数第三层为激活函数relu层。
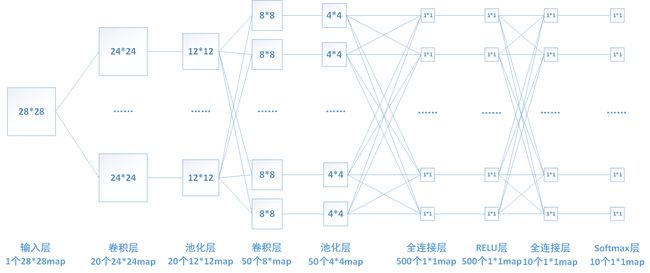
relu函数的表达式为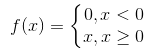 , 所以前向传播时,大于0的输入不变,小于0的置零即可。
, 所以前向传播时,大于0的输入不变,小于0的置零即可。
激活函数层的反向传播
Relu函数的导数为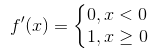 。假设该层前向计算过程为
。假设该层前向计算过程为
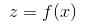 ,其中f(x)为relu函数。反向传播时已知
,其中f(x)为relu函数。反向传播时已知
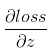 ,根据链式求导法则
,根据链式求导法则
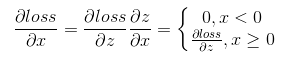 。
。
所以反向传播时,只需将前向计算时输入大于0的结点对应的梯度向前传,小于0的结点的梯度置零即可。
Caffe中激活函数层的实现
在caffe中,我们的网络关于激活函数层的配置信息如下:
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
该层配置信息中各参数含义如下。
name为该层名称。
Type为该层类型,可取值分别为:
(1)ReLU:表示我们使用relu激活函数,relu层支持in-place计算,这意味着该层的输入和输出共享一块内存,以避免内存的消耗。
(2)Sigmoid:代表使用sigmoid函数;
(3) TanH:代表使用tanh函数;
(4) AbsVal:计算每个输入的绝对值f(x)=Abs(x)
(5)power对每个输入数据进行幂运算
f(x)= (shift + scale * x) ^ power
层类型:Power
可选参数:
power: 默认为1
scale: 默认为1
shift: 默认为0
layer {
name: "layer"
bottom: "in"
top: "out"
type: "Power"
power_param {
power: 2
scale: 1
shift: 0
}
}
Caffe中relu层相关的GPU文件有2个,其中\src\caffe\layers\cudnn_relu_layer.cu,是使用的cudnn的api,不再多说。\src\caffe\layers\relu_layer.cu为作者自己写的函数。
前向计算
前向过程代码如下,具体解释见注释部分:
template
__global__ void ReLUForward(const int n, const Dtype* in, Dtype* out,
Dtype negative_slope) {
CUDA_KERNEL_LOOP(index, n) {
//实际执行时negative_slope = 0
out[index] = in[index] > 0 ? in[index] : in[index] * negative_slope;
}
}
template
void ReLULayer::Forward_gpu(const vector*>& bottom,
const vector*>& top) {
const Dtype* bottom_data = bottom[0]->gpu_data();
Dtype* top_data = top[0]->mutable_gpu_data();
const int count = bottom[0]->count();
Dtype negative_slope = this->layer_param_.relu_param().negative_slope();
// NOLINT_NEXT_LINE(whitespace/operators)
//调用ReLUBackward进行前向计算
ReLUForward<<>>(
count, bottom_data, top_data, negative_slope);
CUDA_POST_KERNEL_CHECK;
} 反向传播
代码及注释如下
template
__global__ void ReLUBackward(const int n, const Dtype* in_diff,
const Dtype* in_data, Dtype* out_diff, Dtype negative_slope) {
CUDA_KERNEL_LOOP(index, n) {
//实际执行时negative_slope = 0
out_diff[index] = in_diff[index] * ((in_data[index] > 0)
+ (in_data[index] <= 0) * negative_slope);
}
}
template
void ReLULayer::Backward_gpu(const vector*>& top,
const vector& propagate_down,
const vector*>& bottom) {
if (propagate_down[0]) {
const Dtype* bottom_data = bottom[0]->gpu_data();
const Dtype* top_diff = top[0]->gpu_diff();
Dtype* bottom_diff = bottom[0]->mutable_gpu_diff();
const int count = bottom[0]->count();
Dtype negative_slope = this->layer_param_.relu_param().negative_slope();
// NOLINT_NEXT_LINE(whitespace/operators)
//调用ReLUBackward进行反向计算
ReLUBackward<<>>(
count, top_diff, bottom_data, bottom_diff, negative_slope);
CUDA_POST_KERNEL_CHECK;
}
}