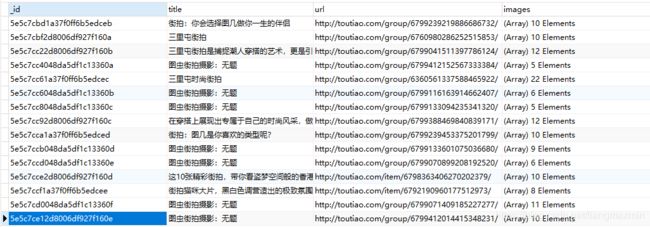
python爬取今日头条图片
有关问题:
在爬取json数据的时候经常会遇到返回的数据不全或者为空
解决办法:
注意headers里的cookie字段,每隔一段时间就会改变。
最好选用火狐浏览器里的headers全部复制,我之前就是用的谷歌爬取但是会有一个timestamp时间戳导致爬取的json为空
收获:
下载图片时要以二进制获取并保存。
确定字段存在
if data and ‘sub_images’ in data.keys():
import re
import requests
# 请求异常时抛出
from requests.exceptions import RequestException
# 解析post请求的字段
from urllib.parse import urlencode
# 解析json数据
import json
# 抓取相关字段
from bs4 import BeautifulSoup
# 连接数据库
import pymongo
# 引入pymongo配置文件
from config import *
# 识别图片是否重复
from hashlib import md5
# 文件列表
import os
# 多线程池
from multiprocessing import Pool
# 连接mongo数据库 False是因为多进程下频繁的连接会报错
client = pymongo.MongoClient(MONGO_URL,connect=False)
db = client[MONGO_DB]
# 请求我们要爬取的json数据
def get_page_index(offset, keyword):
# post请求提交的字段
data = {
'aid': 24,
'app_name': 'web_search',
'offset': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'en_qc': 1,
'cur_tab': 1,
'from': 'search_tab',
'pd': 'synthesis'
}
# 伪装浏览器
headers = {
'Host': 'www.toutiao.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0',
'Accept': 'application/json, text/javascript',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'X-Requested-With': 'XMLHttpRequest',
'Content-Type': 'application/x-www-form-urlencoded',
'Connection': 'keep-alive',
'Referer': 'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D',
# cookie这一步非常重要 我们在请求的时候每隔一段时间他就会变 导致请求的json为空
'Cookie': 'tt_webid=6798858588834121230; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6798858588834121230; csrftoken=e1c1bbef2bdddf1a0956eff79ee755b6; ttcid=3f03989a23704b6ba6aa4853b9441b8034; SLARDAR_WEB_ID=vn; s_v_web_id=verify_k79wbgce_rf3idn7y_ywfm_4IcX_ALlv_F0XgbpFgC3SQ; __tasessionId=l90c2qu3i1583119236978; tt_scid=eW9knXOj5CoW5cii.BsCILwbJyp-9cDwe1KtMbu8ZesZwkJN-mLAjeVaenKnnZnG73af',
'TE': 'Trailers'
}
# urlcode解析data
url = 'https://www.toutiao.com/api/search/content/?' + urlencode(data)
try:
response = requests.get(url, headers=headers, timeout=5)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求索引页')
return None
def parse_page_index(html):
data = json.loads(html)
# 确定data字段存在
if data and 'data' in data.keys():
# 迭代data
for item in data.get('data'):
# 以字典的形式获取图片链接
yield item.get('article_url')
# 判断图片链接是否有效
def get_page_detail(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求详情页出错', url)
return None
# 解析图片连接
def parse_page_detail(html, url):
soup = BeautifulSoup(html, 'lxml')
# 获取title文本内容
title = soup.select('title')[0].get_text()
print(title)
# 正则表达式匹配我们要的数据
image_pagttern = re.compile('gallery: JSON.parse\\((.*?)\\),', re.S)
result = re.search(image_pagttern, html)
# 加一个判断是否匹配到内容
if result:
# 需要解析两次
data = json.loads(json.loads(result.group(1)))
# 确定sub_images字段存在
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
# 遍历sub_images获取单个图片地址
images = [item.get('url') for item in sub_images]
for image in images: download_image(image)
# 以字典的形式保存
return {
'title': title,
'url': url,
'images': images
}
# 保存到数据库
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储成功', result)
return True
return False
def download_image(url):
print('正在下载',url)
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
# 图片要以二进制的形式保存
save_image(response.content)
return None
except RequestException:
print('请求图片出错', url)
return None
# 保存下载的图片
def save_image(content):
file_path = '{0}/{1}.{2}'.format("D://image", md5(content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(content)
f.close()
def main(offset):
# 获取json数据
html = get_page_index(offset, '街拍')
print(html)
# 遍历解析后的图片网页地址
for url in parse_page_index(html):
# 因为有的链接里面不存在article_url,因此返回的url为空
if url != None:
html = get_page_detail(url)
if html:
result = parse_page_detail(html, url)
if result:save_to_mongo(result)
if __name__ == '__main__':
# 多进程爬取网页
groups=[x*20 for x in range(GROUP_START,GROUP_END+1)]
pool = Pool()
pool.map(main,groups)
config
#存入MongoDB
MONGO_URL='localhost'
MONGO_DB='toutiao'
MONGO_TABLE='toutiao'
#定义一个offset偏移量,用于循环
GROUP_START=1
GROUP_END=20