Keras中的多分类损失函数用法categorical_crossentropy
Keras中的多分类损失函数用法categorical_crossentropy
更多python视频教程请到菜鸟教程https://www.piaodoo.com/
from keras.utils.np_utils import to_categorical
注意:当使用categorical_crossentropy损失函数时,你的标签应为多类模式,例如如果你有10个类别,每一个样本的标签应该是一个10维的向量,该向量在对应有值的索引位置为1其余为0。
可以使用这个方法进行转换:
from keras.utils.np_utils import to_categorical
categorical_labels = to_categorical(int_labels, num_classes=None)
以mnist数据集为例:
from keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
…
model.compile(loss=‘categorical_crossentropy’, optimizer=‘adam’)
model.fit(X_train, y_train, epochs=100, batch_size=1, verbose=2)
补充知识:Keras中损失函数binary_crossentropy和categorical_crossentropy产生不同结果的分析
问题
在使用keras做对心电信号分类的项目中发现一个问题,这个问题起源于我的一个使用错误:
binary_crossentropy 二进制交叉熵用于二分类问题中,categorical_crossentropy分类交叉熵适用于多分类问题中,我的心电分类是一个多分类问题,但是我起初使用了二进制交叉熵,代码如下所示:
sgd = SGD(lr=0.003, decay=0, momentum=0.7, nesterov=False) model.compile(loss='categorical_crossentropy', optimizer='sgd',metrics=['accuracy']) model.fit(X_train, Y_train, validation_data=(X_test,Y_test),batch_size=16, epochs=20) score = model.evaluate(X_test, Y_test, batch_size=16)
注意:我的CNN网络模型在最后输入层正确使用了应该用于多分类问题的softmax激活函数
后来我在另一个残差网络模型中对同类数据进行相同的分类问题中,正确使用了分类交叉熵,令人奇怪的是残差模型的效果远弱于普通卷积神经网络,这一点是不符合常理的,经过多次修改分析终于发现可能是损失函数的问题,因此我使用二进制交叉熵在残差网络中,终于取得了优于普通卷积神经网络的效果。
因此可以断定问题就出在所使用的损失函数身上
原理
本人也只是个只会使用框架的调参侠,对于一些原理也是一知半解,经过了学习才大致明白,将一些原理记录如下:
要搞明白分类熵和二进制交叉熵先要从二者适用的激活函数说起
激活函数
sigmoid, softmax主要用于神经网络输出层的输出。
softmax函数
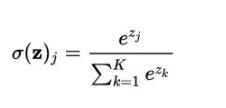
softmax可以看作是Sigmoid的一般情况,用于多分类问题。
Softmax函数将K维的实数向量压缩(映射)成另一个K维的实数向量,其中向量中的每个元素取值都介于 (0,1) 之间。常用于多分类问题。
sigmoid函数
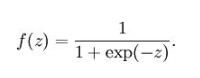
Sigmoid 将一个实数映射到 (0,1) 的区间,可以用来做二分类。Sigmoid 在特征相差比较复杂或是相差不是特别大时效果比较好。Sigmoid不适合用在神经网络的中间层,因为对于深层网络,sigmoid 函数反向传播时,很容易就会出现梯度消失的情况(在 sigmoid 接近饱和区时,变换太缓慢,导数趋于 0,这种情况会造成信息丢失),从而无法完成深层网络的训练。所以Sigmoid主要用于对神经网络输出层的激活。
分析
所以说多分类问题是要softmax激活函数配合分类交叉熵函数使用,而二分类问题要使用sigmoid激活函数配合二进制交叉熵函数适用,但是如果在多分类问题中使用了二进制交叉熵函数最后的模型分类效果会虚高,即比模型本身真实的分类效果好。
所以就会出现我遇到的情况,这里引用了论坛一位大佬的样例:
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # WRONG way
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=2, # only 2 epochs, for demonstration purposes
verbose=1,
validation_data=(x_test, y_test))
Keras reported accuracy:
score = model.evaluate(x_test, y_test, verbose=0)
score[1]
0.9975801164627075
Actual accuracy calculated manually:
import numpy as np
y_pred = model.predict(x_test)
acc = sum([np.argmax(y_test[i])==np.argmax(y_pred[i]) for i in range(10000)])/10000
acc
0.98780000000000001
score[1]==acc
False
样例中模型在评估中得到的准确度高于实际测算得到的准确度,网上给出的原因是Keras没有定义一个准确的度量,但有几个不同的,比如binary_accuracy和categorical_accuracy,当你使用binary_crossentropy时keras默认在评估过程中使用了binary_accuracy,但是针对你的分类要求,应当采用的是categorical_accuracy,所以就造成了这个问题(其中的具体原理我也没去看源码详细了解)
解决
所以问题最后的解决方法就是:
对于多分类问题,要么采用
from keras.metrics import categorical_accuracy model.compile(loss='binary_crossentropy', optimizer='adam', metrics=[categorical_accuracy])
要么采用
model.compile(loss='categorical_crossentropy',
optimizer='adam',metrics=['accuracy'])
以上这篇Keras中的多分类损失函数用法categorical_crossentropy就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多
茂名论坛https://www.hnthzk.com/
化州橘红http://www.sfkyty.com/
茂名论坛http://www.nrso.net/
源码搜藏网http://www.cntkd.net/
茂名市高级技工学校(茂名一技)http://www.szsyby.net/
茂名一技https://www.mmbbu.com/