flume使用之flume+hive 实现日志离线收集、分析
在如今互联网行业中,数据的收集特别是日志数据的收集已经成为了系统的标配。将用户行为日志或者线上系统生产的数据通过flume收集起来,存放到数据仓库(hive)中,然后离线通过sql进行统计分析,这一套数据流的建设对系统有非常重要的意义。
1、思路:
1)线上系统通过log4j将数据打印到本地磁盘上;
2)在线上系统服务器上安装flume,作为agent使用exec source将线上系统log4j打印的日志收集到flume中;
3)自定义flume的intercept,将收集的event 数据库进行格式化;
4)flume日志收集架构设计成扇入流的方式,将各个线上系统服务器上的flume agent收集的event 数据流扇入到另外一台/多台(ha)flume服务器上;
5)汇总的flume将event 数据库保存到hdfs上;(/t 分隔的文本格式)
6)hive建立外表,读取flume收集到hdfs上的数据。
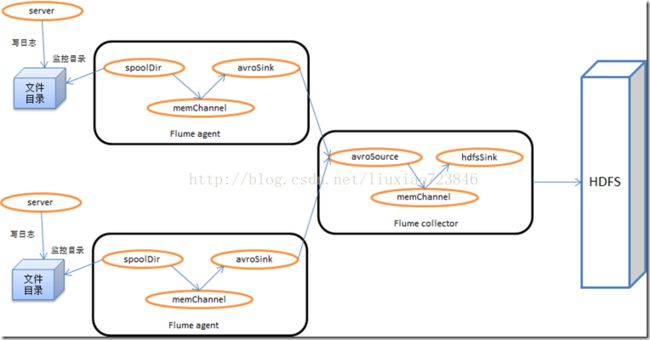
2、实例:
假设线上系统有3台服务器:A、B、C,汇总event 数据流的flume有一台服务器D。
1)线上系统通过log4j打印到本地的日志格式如下:
[09-30 14:53:30] [INFO] [com.abc.ttbrain.recommend.api.controller.PersonalRecommendController:205] personalRecommend(): cost=28ms; puid=; uId=FAB3032BAEE9873EFC0804261B81C58F; fnum=10; chId=default; usg=2; recId=[389935990570, 323814380570, 364350750570, 247529500570, 398584230570, 412302730570, 403611070570, 251533940570, 353868780570, 299541130570]; mutilFeeds={"p_11":[403611070570],"p_14":[412302730570],"p_17":[323814380570,247529500570,398584230570,251533940570,299541130570],"p_16":[389935990570,353868780570],"p_5":[364350750570]}; typeFeeds={"NEWS":[353868780570,299541130570],"VIDEO":[389935990570,323814380570,364350750570,247529500570,398584230570,412302730570,403611070570,251533940570]}; prefMap={353868780570:"傻小子,嫂子",364350750570:"避孕,性生活",323814380570:"超能太监",398584230570:"女间谍,洗澡",389935990570:"日韩,谎言",412302730570:"车房,健康",299541130570:"小说",403611070570:"相亲",247529500570:"女俘虏,监狱,汉奸"}; prior=null; reqUniqId=1506754410862177835258FAB3032BAEE9873EFC0804261B81C58F; version=; flag=per_rec; rg=0; rh=9; pg=0; ph=4; sg=0; sh=2; strategy=r_blp,ctr_blp,ltr_blp,s_blp,c_blp
2)自定义flume的intercept:
package com.abc.ttbrain.log.flume.interceptor;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.commons.lang.StringUtils;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.google.common.base.Charsets;
import com.google.common.collect.Lists;
import com.abc.ttbrain.log.common.entity.LogEntity;
/**
* flume interceptor
* @author kevinliu
*
*/
public class MyInterceptor implements Interceptor {
private static final Logger logger = LoggerFactory.getLogger(MyInterceptor.class);
@Override
public void close() {
// TODO Auto-generated method stub
logger.info("flume myinterceptor is close");
}
@Override
public void initialize() {
// TODO Auto-generated method stub
logger.info("flume myinterceptor is initialize");
}
/**
* [08-04 10:12:26] [INFO] [com.abc.ttbrain.recommend.api.controller.PersonalRecommendController:195] personalRecommend():
* cost=13ms; puid=; uId=579AEB028EA6402A5F5507FDB5A27B64; fnum=8; chId=1; usg=1;
* recId=[325747850570, 325825180570, 325801330570, 325401880570, 325714680570, 325750900570, 325805720570, 325823150570];
* mutilFeeds={"p_7":[325747850570,325825180570,325801330570,325401880570,325714680570,325750900570,325805720570,325823150570]};
* typeFeeds={"VIDEO":[325747850570,325825180570,325801330570,325401880570,325714680570,325750900570,325805720570,325823150570]};
* prefMap={325805720570:"奔跑吧兄弟,陈赫,过山车",325750900570:"明星宝贝,贾静雯,妈妈是超人",325714680570:"张杰,朱亚文,佟大为",325747850570:"叶倩文,郑秀文",325801330570:"郑秀晶,郑秀妍",325401880570:"黄子韬",325825180570:"丁俊晖,吴尊,台球",325823150570:"极限挑战,罗志祥,黄宗泽"};
* prior=null; reqUniqId=1501812746481177835258579AEB028EA6402A5F5507FDB5A27B64;
* version=; flag=per_rec; rg=0; rh=0; pg=0; ph=7; sg=0; sh=1
*/
@Override
public Event intercept(Event event) {
try {
Map headers = event.getHeaders();
String body = new String(event.getBody(), Charsets.UTF_8);
String[] split = body.split("personalRecommend\\(\\):");
if (split == null || split.length <2) {
return null;
} else {
String logStr = split[1];
Map fieldMap = getLongStr4Map(logStr);
LogEntity logEntity = getLogEntityFromMap(fieldMap);
String hostName = headers.get("hostname");
String timeStamp = headers.get("timestamp");
logEntity.setHost(hostName);
logEntity.setTimeStamp(timeStamp);
event.setBody(logEntity.toString().getBytes());
logger.info("device:{}",logEntity.getUid());
return event;
}
} catch (Exception e ) {
logger.error("intercept:",e);
}
return null;
}
public Map getLongStr4Map(String str) {
Map map = new HashMap<>();
String[] split = str.split(";");
for (String fileds:split) {
if (StringUtils.isBlank(fileds)) {
continue;
}
String[] split2 = fileds.split("=");
if (split2 == null || split2.length<2) {
continue;
}
String key = split2[0];
String value = split2[1];
map.put(key.trim(), value.trim());
}
return map;
}
/**
* uid|ppuid|channel|feedNum|cost|usg|prior|reqUniqId|version|rg|rh|pg|ph|sg|sh|timeStamp|host
* |recFeedId|txt|gallery|vedio|p_1|p_2|p_3|p_4|p_5|p_6|p_7|p_8|p_9|p_10|p_11|p_12|p_13|p_14|p_15
*/
public LogEntity getLogEntityFromMap(Map fieldMap) {
LogEntity logEntity = new LogEntity();
String uId = fieldMap.get("uId");
String puid = fieldMap.get("puid") == null ? "":fieldMap.get("puid");
String chId = fieldMap.get("chId") == null ? "default" :fieldMap.get("chId");
String fnum = fieldMap.get("fnum");
String sh = fieldMap.get("sh");
logEntity.setUid(uId);
logEntity.setPpuid(puid);
logEntity.setChannel(chId);
logEntity.setFeedNum(Integer.parseInt(fnum));
//...
return logEntity;
}
@Override
public List intercept(List events) {
List intercepted = Lists.newArrayListWithCapacity(events.size());
for (Event event : events) {
Event interceptedEvent = intercept(event);
if (interceptedEvent != null) {
intercepted.add(interceptedEvent);
}
}
return intercepted;
}
public static class Builder implements Interceptor.Builder {
//使用Builder初始化Interceptor
@Override
public Interceptor build() {
return new MyInterceptor();
}
@Override
public void configure(Context arg0) {
// TODO Auto-generated method stub
}
}
}
实体类:
package com.abc.ttbrain.log.common.entity;
/**
*
* @author kevinliu
*
*/
public class LogEntity {
private static final String flag = "\t";
private String uid="";
private String ppuid="";
private String channel="";
private int feedNum=10;
private int cost=0;
private String usg = "";
private String prior="";
private String reqUniqId="";
private String version="";
private String rg="";
private String rh="";
private String pg="";
private String ph="";
private String sg="";
private String sh="";
private String timeStamp="";
private String host="";
private String recFeedId="";
private String txt="";
private String gallery="";
private String vedio="";
private String p_1="";
private String p_2="";
private String p_3="";
private String p_4="";
private String p_5="";
private String p_6="";
private String p_7="";
private String p_8="";
private String p_9="";
private String p_10="";
private String p_11="";
private String p_12="";
private String p_13="";
private String p_14="";
private String p_15="";
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(uid).append(flag).append(ppuid).append(flag).append(channel).append(flag).append(feedNum).append(flag).append(cost).append(flag)
.append(usg).append(flag).append(prior).append(flag).append(reqUniqId).append(flag).append(version).append(flag)
.append(rg).append(flag).append(rh).append(flag).append(pg).append(flag).append(ph).append(flag)
.append(sg).append(flag).append(sh).append(flag)
.append(timeStamp).append(flag).append(host).append(flag)
.append(recFeedId).append(flag)
.append(txt).append(flag).append(gallery).append(flag).append(vedio).append(flag)
.append(p_1).append(flag).append(p_2).append(flag).append(p_3).append(flag).append(p_4).append(flag)
.append(p_5).append(flag).append(p_6).append(flag).append(p_7).append(flag).append(p_8).append(flag)
.append(p_9).append(flag).append(p_10).append(flag).append(p_11).append(flag).append(p_12).append(flag)
.append(p_13).append(flag).append(p_14).append(flag).append(p_15).append(flag)
.append("end");
return sb.toString();
}
//get 和 set
}
建立maven项目,编写自定义intercept,打包,将jar放到flume_home的lib下;
3)在线上系统的服务器(A、B、C)上安装flume,配置flume,同时将上一步生成的jar放到flume_home的lib中;
agent1.sources = ngrinder
agent1.channels = mc1 mc2
agent1.sinks = avro-sink
#source
agent1.sources.ngrinder.type = exec
agent1.sources.ngrinder.command = tail -F /data/logs/ttbrain/ttbrain-recommend-api.log
agent1.sources.ngrinder.channels = mc1
#filter
agent1.sources.ngrinder.interceptors=filt1 filt2 filt3 filt4
agent1.sources.ngrinder.interceptors.filt1.type=regex_filter
agent1.sources.ngrinder.interceptors.filt1.regex=.*recId.*
agent1.sources.ngrinder.interceptors.filt2.type=host
agent1.sources.ngrinder.interceptors.filt2.hostHeader=hostname
agent1.sources.ngrinder.interceptors.filt2.useIP=true
agent1.sources.ngrinder.interceptors.filt3.type=timestamp
agent1.sources.ngrinder.interceptors.filt4.type=com.abc.ttbrain.log.flume.interceptor.MyInterceptor$Builder
agent1.channels.mc1.type = file
agent1.channels.mc1.checkpointDir = /data/flume/ckdir/mc1_ck
agent1.channels.mc1.dataDirs = /data/flume/datadir/mc1_data
#sink1
agent1.sinks.avro-sink.type = avro
agent1.sinks.avro-sink.channel = mc1
agent1.sinks.avro-sink.hostname = 10.153.135.113
agent1.sinks.avro-sink.port = 41414A、这里一共设置了4个intercept:
- fillt1是正则表达式,用来过滤线上系统的日志数据;
- filt2是host拦截器,用来往flume的event 数据header中放置host信息;
- filt3是timestamp拦截器,用来往flume的event数据header中放置时间信息;
- filt4是自定义拦截器,用来格式化日志数据;
B、然后启动flume:
nohup flume-ng agent -c /usr/local/apache-flume-1.7.0-bin/conf -f /usr/local/apache-flume-1.7.0-bin/conf/engine-api-log.conf -n agent1 >/dev/null 2>&1 &
4)在服务器D上安装flume,用来汇总A、B、C上flume传递过来的event 数据:
A、flume配置:
ttengine_api_agent.channels = ch1
ttengine_api_agent.sources = s1
ttengine_api_agent.sinks = log-sink1
ttengine_api_agent.sources.s1.type = avro
ttengine_api_agent.sources.s1.bind = 10.153.135.113
ttengine_api_agent.sources.s1.port = 41414
ttengine_api_agent.sources.s1.threads = 5
ttengine_api_agent.sources.s1.channels = ch1
ttengine_api_agent.sources.s1.interceptors = f1
ttengine_api_agent.sources.s1.interceptors.f1.type = timestamp
ttengine_api_agent.sources.s1.interceptors.f1.preserveExisting=false
ttengine_api_agent.channels.ch1.type = memory
ttengine_api_agent.channels.ch1.capacity = 100000
ttengine_api_agent.channels.ch1.transactionCapacity = 100000
ttengine_api_agent.channels.ch1.keep-alive = 30
ttengine_api_agent.sinks.log-sink1.type = hdfs
ttengine_api_agent.sinks.log-sink1.hdfs.path = hdfs://hadoop-jy-namenode/data/qytt/flume/ttengine_api/dt=%Y-%m-%d/hour=%H
ttengine_api_agent.sinks.log-sink1.hdfs.writeFormat = Text
ttengine_api_agent.sinks.log-sink1.hdfs.fileType = DataStream
ttengine_api_agent.sinks.log-sink1.hdfs.fileSuffix = .log
ttengine_api_agent.sinks.log-sink1.hdfs.filePrefix = %Y-%m-%d_%H
ttengine_api_agent.sinks.log-sink1.hdfs.rollInterval = 3600
ttengine_api_agent.sinks.log-sink1.hdfs.rollSize = 0
ttengine_api_agent.sinks.log-sink1.hdfs.rollCount = 0
ttengine_api_agent.sinks.log-sink1.hdfs.batchSize = 1000
ttengine_api_agent.sinks.log-sink1.hdfs.callTimeout = 60000
ttengine_api_agent.sinks.log-sink1.hdfs.appendTimeout = 60000
ttengine_api_agent.sinks.log-sink1.channel = ch1
B、hdfs sink说明:
- writeFormat =Text:存储到hdfs上是文本格式的日志;
- path:为了hive的方便查询,后面需要给hive建立天和小时分区,所以这里的数据存储目录要根据hive分区的定义方式来定义成dt=%Y-%m-%d/hour=%H(flume会自动建立目录)
- 其他:指定flume写入hdfs 的频率和超时;
C、启动flume:
nohup flume-ng agent -c /usr/local/apache-flume-1.7.0-bin/conf -f /usr/local/apache-flume-1.7.0-bin/conf/ttengine_api_hdfs.conf -n ttengine_api_agent >/dev/null 2>&1 &
这时,就会发现线上系统产生的日志,通过扇入流的flume保存到hdfs了。
5)建立hive外表:
CREATE EXTERNAL TABLE `ttengine_api_data`(
`uid` string,
`ppuid` string,
`ch_id` string,
`f_num` int,
`cost` int,
`usg` int,
`prior` string,
`req_id` string,
`vers` string,
`rg` string,
`rh` int,
`pg` string,
`ph` int,
`sg` string,
`sh` int,
`tistmp` bigint,
`host` string,
`rec_feedids` string,
`txt` string,
`vedio` string,
`gallery` string,
`p_1` string,
`p_2` string,
`p_3` string,
`p_4` string,
`p_5` string,
`p_6` string,
`p_7` string,
`p_8` string,
`p_9` string,
`p_10` string,
`p_11` string,
`p_12` string,
`p_13` string,
`p_14` string,
`p_15` string)
PARTITIONED BY (
`dt` string,
`hour` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoop-jy-namenode/data/qytt/flume/ttengine_api'注意:
A、外表的路径要和flume收集到hdfs上的主目录保持一致(不包含分区目录,分区目录hive会自动建立);
B、表的列要和flume自动一 intercept解析数据的格式相互对应;
C、该表有两个分区,dt和hour;
6)定时分区脚本:
#!/bin/bash
if [ $# -eq 0 ];
then
#DT=`date -d"1 days ago" +'%F'`
DT=`date "+%Y-%m-%d"`
HOUR=`date "+%H"`
else
DT=$1
HOUR=$2
fi
QUEUE="test"
TABLE="ttengine_api_data"
hive -e"
set mapred.job.queue.name = $QUEUE;
set hive.exec.compress.output=false;
use qytt;
alter table $TABLE add partition (dt ='$DT',hour='$HOUR');
"
30 0 * * * cd /data/qytt/ttbrain/flume; sh -x ttengine_predict_log.sh >>ttengine_predict_log.log 2>&1 &
查看hive分区情况:
show partitions ttengine_predict_data;
到这里,使用flume+hive搭建日志收集离线统计分析的系统就已经基本完成,后面还有很多优化的余地,比如:扇入流的ha和负载均衡等。
参考:http://www.huyanping.cn/flumehive%E5%A4%84%E7%90%86%E6%97%A5%E5%BF%97/
http://www.debugrun.com/a/JBEXcnu.html