Attentive Generative Adversarial Network for Raindrop Removal from A Single Image(2018CVPR翻译)
为了节省一点篇幅,我会删去原文中一些东西,不影响大家理解文章,同时我会保证英文和中文是对应的:
Attentive Generative Adversarial Network for Raindrop Removal from A Single Image(2018CVPR)
Abstract(摘要):
Raindrops adhered to a glass window or camera lens can severely hamper the visibility of a background scene and degrade an image considerably. In this paper, we address the problem by visually removing raindrops, and thus transforming a raindrop degraded image into a clean one. The problem is intractable, since first the regions occluded by raindrops are not given. Second, the information about the background scene of the occluded regions is completely lost for most part. To resolve the problem, we apply an attentive generative network using adversarial training. Our main idea is to inject visual attention into both the generative and discriminative networks. During the training, our visual attention learns about raindrop regions and their surroundings. Hence, by injecting this information, the generative network will pay more attention to the raindrop regions and the surrounding structures, and the discriminative network will be able to assess the local consistency of the restored regions. This injection of visual attention to both generative and discriminative networks is the main contribution of this paper. Our experiments show the effectiveness of our approach, which outperforms the state of the art methods quantitatively and qualitatively.
吸附在玻璃窗或者是相机镜头上的雨滴会严重妨碍背景场景的可见性,并且会严重降低图像质量。在这篇文章中,我们通过移除雨滴来解决这个问题,也就是把一张被雨滴污染的图像转化为一张干净的图像。问题是十分棘手的,首先是因为被雨滴遮挡的区域没有给出。其次,被遮挡区域的背景场景的信息在大多数情况下是完全丢失的。为了解决这个问题,我们将一个注意力生成网络用于对抗训练。我们的主要思想是将视觉注意力同时注入生成网络和判别网络中。在训练期间,我们的视觉注意力会学习到雨滴区域以及它周围的信息。因此,通过注入这个信息,生成网络将会将更多的注意力放在雨滴区域以及周围的结构上,并且判别网络能够评价恢复区域的本地一致性。将视觉注意力注入到生成和判别网络是这篇文章的主要贡献。我们的实验显示了我们的方法的有效性,定性上和定量上都超过了最先进的方法。
1. Introduction
Raindrops attached to a glass window, windscreen or lens can hamper the visibility of a background scene and degrade an image. Principally, the degradation occurs because raindrop regions contain different imageries from those without raindrops. Unlike non-raindrop regions, rain-drop regions are formed by rays of reflected light from a wider environment, due to the shape of raindrops, which is similar to that of a fish-eye lens. Moreover, in most cases, the focus of the camera is on the background scene, making the appearance of raindrops blur.
吸附在玻璃窗、挡风玻璃或者镜头上的雨滴会妨碍背景场景的可见性,并且会降低图像质量。从原理上来讲,降解的出现是因此雨滴区域包含了与那些非雨滴区域不同的图像。不像非雨滴区域,由于区域的形状和鱼眼镜头类似,雨滴区域是由来自广阔的环境的反射光线形成的。还有,在多数情况下,相机聚焦在背景场景上,这也使得雨滴看起来很模糊。In this paper, we address this visibility degradation problem. Given an image impaired by raindrops, our goal is to remove the raindrops and produce a clean background as shown in Fig. 1. Our method is fully automatic. We consider that it will benefit image processing and computer vision applications, particularly for those suffering from raindrops, dirt, or similar artifacts.
在这篇文章中,我们解决这些视觉上问题。输入一张被雨滴影响的图像,我们的目标是去除这些雨滴并且生成一张干净的背景图片,如Fig.1.所示。我们的方法是完全自动的,我们认为这将有利于它在图像处理和计算机视觉上的应用,特别是那些受到雨滴、灰尘或者类似的人工产品的影响的应用。

Generally, the raindrop-removal problem is intractable, since first the regions which are occluded by raindrops are not given. Second, the information about the background scene of the occluded regions is completely lost for most part. The problem gets worse when the raindrops are relatively large and distributed densely across the input image. To resolve the problem, we use a generative adversarial network, where our generated outputs will be assessed by our discriminative network to ensure that our outputs look like real images. To deal with the complexity of the problem, our generative network first attempts to produce an attention map. This attention map is the most critical part of our network, since it will guide the next process in the generative network to focus on raindrop regions. This map is produced by a recurrent network consisting of deep residual networks (ResNets) [8] combined with a convolutional LSTM [21] and a few standard convolutional layers. We call this attentive-recurrent network.
一般来讲,雨滴移除问题是棘手的。首先是因为被雨滴遮挡的区域没有给出,其次是被遮挡的区域的背景信息在大多数时候是完全丢失的。当输入图像上雨滴相对较大或者分布密集的时候问题变得更严重。为了解决这个问题,我们使用了一个生成对抗网络,在这个网络中我们生成的输出将会被判别网络进行评价确保我们的输出像一张真实的图像。为了处理问题的复杂性,我们的生成网络首先尝试生成一张Attention map. 这个Attention map是我们的网络中最重要的一部分,因为它将引导后面生成网络的处理过程将注意力放在雨滴区域。这个Attention map由包含深度残差网络(ResNets)、卷积LSTM单元、一些标准的卷积层组成的循环网络生成。我们将它成为Attentive-recurrent network(注意力循环网络)。
The second part of our generative network is an autoencoder, which takes both the input image and the attention map as the input. To obtain wider contextual information, in the decoder side of the autoencoder, we apply multi-scale losses. Each of these losses compares the difference between the output of the convolutional layers and the corresponding ground truth that has been downscaled accordingly. The input of the convolutional layers is the features from a decoder layer. Besides these losses, for the final output of the autoencoder, we apply a perceptual loss to obtain a more global similarity to the ground truth. This final output is also the output of our generative network.
我们的生成网络的第二个部分是一个自动编码器,它的输入是原始输入图像和Attention map。为了得到更广泛的上下文信息,在自动编码器的解码器部分,我们使用了多尺度损失。这些损失中的每一个都将卷积层的输出和相应的被降采样的真实图像的对应区域进行比较。卷积层的输入是解码层提取的特征。除了这些损失之外,对于自动编码器的最终的输出,我们应用了一个感知损失来得到更全局的与真实图像的相似。这个最终的输出同时也是也是生成网络的输出。
总结一下,生成网络做了两个工作:1)使用Attentive-recurrent Network生成了一个Attention map;2)使用Autodecoder结合Attention map恢复了一张没有雨滴的干净背景的图像。
Having obtained the generative image output, our discriminative network will check if it is real enough. Like in a few inpainting methods, our discriminative network validates the image both globally and locally. However, unlike the case of inpainting, in our problem and particularly in the testing stage, the target raindrop regions are not given. Thus, there is no information on the local regions that the discriminative network can focus on. To address this problem, we utilize our attention map to guide the discriminative network toward local target regions.
得到了生成网络的输出之后,我们的判别网络将会判别它是否是真实图像。与一些图像恢复的方法类似,我们的判别网络从全局和局部来验证图像。然而,与那些图像恢复的例子不同的是,在我们的问题中,尤其是在测试阶段,雨滴区域没有给出。因此,没有让判别网络应该注意的局部区域的信息。为了解决这个问题,我们利用生成的Attention map来引导判别网络将注意力放在哪一些局部区域。
3. Raindrop Image Formation
We model a raindrop degraded image as the combination of a background image and effect of the raindrops:
我们把雨滴退化图像建模为背景图像和雨滴效应的结合:(可以用下面的公式表示)
![]()
where I is the colored input image and M is the binary mask. In the mask, M(x) = 1 means the pixel x is part of a raindrop region, and otherwise means it is part of background regions. B is the background image and R is the effect brought by the raindrops, representing the complex mixture of the background information and the light reflected by the environment and passing through the raindrops adhered to a lens or windscreen. Operator means element-wise multiplication.
这里I是彩色输入图像,M是一个二进制掩码。在掩码中,如果M(x)=1意味着像素x是雨滴区域的一部分,否则是背景区域的一部分。B是背景图像,R是雨滴带来的效应,它代表背景信息以及穿过被雨滴吸附的镜头或者挡风玻璃的反射光线的混合。中间的类似于乘法运算,当然是矩阵乘法而不是普通的数乘了。
上面的公式中的变量都做了解释,但是我觉得还是要把整个公式理解一下,因为这是整篇文章的基础。M是一个掩码,用来表示哪些像素是雨滴的一部分,是雨滴用1表示,不是用0表示。(1-M)与M相反,是雨滴用0表示,不是用1表示,然后(1-M)*B就相当于是从背景图像上把是雨滴的像素都扣掉了(像素值变为0了),剩下的都是没有雨滴的像素。所以(1-M)的作用就类似于一个滤波器。然后加上R(雨滴效应)就得到了一张被雨滴污染的图像了。
最后,再说一下掩码M是怎么得到的呢?其实这个网络的测试集需要的是成对的图像,每一对图像包含了干净图像和被雨滴污染的图像,我们用被雨滴污染的图像减去干净图像,然后做一个阈值限制,就得到了掩码了。
Raindrops are in fact transparent. However, due to their shapes and refractive index, a pixel in a raindrop region is not only influenced by one point in the real world but by the whole environment [25], making most part of raindrops seem to have their own imagery different from the background scene. Moreover, since our camera is assumed to focus on the background scene, this imagery inside a raindrop region is mostly blur. Some parts of the raindrops, particularly at the periphery and transparent regions, convey some information about the background. We notice that the information can be revealed and used by our network.
雨滴实际上是透明的,然后由于它们的形状和折射率(refractive是折射的意思,index有索引,系数的意思),雨滴区域的一个像素不仅被真实世界的一个点影响,而是受整个环境的影响,这导致大多数雨滴看起来有和背景场景不同的图像。还有,因为我们的相机被认为应该聚焦在背景上,所以雨滴区域的图像更加模糊。一些雨滴区域,特别是雨滴的周边(periphery的意思是周围、边缘)和透明区域,传达了有关背景的一些信息。我们注意到这些信息可以被我们的网络揭示并使用。
Based on the model (Eq. (1)), our goal is to obtain the background image B from a given input I. To accomplish this, we create an attention map guided by the binary mask M. Note that, for our training data, as shown in Fig. 5, to obtain the mask we simply subtract the image degraded by raindrops I with its corresponding clean image B. We use a threshold to determine whether a pixel is part of a raindrop region. In practice, we set the threshold to 30 for all images in our training dataset. This simple thresholding is sufficient for our purpose of generating the attention map.
基于上面的雨滴模型,我们的目标是从一个输入I中得到背景图像B。为了实现这一点,我们用二进制掩码M创建了一个Attention map。注意,我们的训练数据如Fig. 5所示,为了得到掩码,我们简单的用于被雨滴污染的图像减去它对应的干净图像B。我们使用一个阈值来确定一个像素是否是雨滴区域的一部分。在实际情况下,我们将阈值设置为30,用于我们训练集中的所有图像。这个简单的阈值对于生成Attention map的目的来说足够了。

4. Raindrop Removal using Attentive GAN
The figure below shows the overall architecture of our proposed network. Following the idea of generative adversarial networks, there are two main parts in our network: the generative and discriminative networks. Given an input image degraded by raindrops, our generative network attempts to produce an image as real as possible and free from raindrops. The discriminative network will validate whether the image produced by the generative network looks real.
下图展示了我们提出的网络的整体架构。遵循生成对抗网络的思想,我们的网络有两个主要部分:生成网络和判别网络。给定一张被雨滴污染的输入图像,我们的生成网络尝试生成一张尽可能真实的没有雨滴的图像。判别网络将会验证生成网络生成的图像看起来是否真实。

Our generative adversarial loss can be expressed as:
where G represents the generative network, and D represents the discriminative network. I is a sample drawn from our pool of images degraded by raindrops, which is the input of our generative network. R is a sample from a pool of clean natural images.
我们的生成对抗网络的损失函数可以用下面的公式表示:
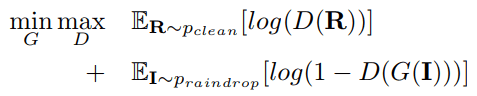
在下面的公式中G代表生成网络,D代表判别网络。I是我们的被雨滴污染的图像库中的一张样本图像,它作为生成网络的输入。R是对应的干净的自然图像库中的一个样本。
4.1. Generative Network
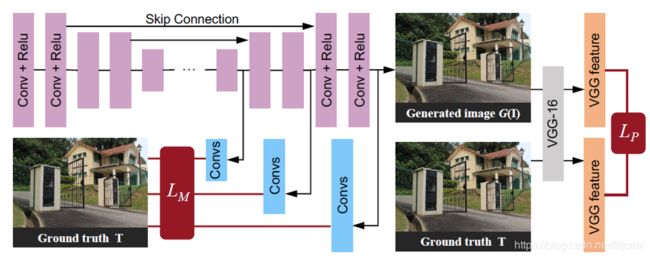
As shown in Fig. 2, our generative network consists of two sub-networks: an attentive-recurrent network and a contextual autoencoder. The purpose of the attentiverecurrent network is to find regions in the input image that need to get attention. These regions are mainly the raindrop regions and their surrounding structures that are necessary for the contextual autoencoder to focus on, so that it can generate better local image restoration, and for the discriminative network to focus the assessment on.
正如上面的网络结构所展示的,我们的生成网络包含了两个子网络:一个注意力递归网络和一个上下文自动编码器。注意力递归网络的目的就是找到输入图像上应该被注意的区域。这些区域是上下文自动编码器应该注意的雨滴区域和它们的周围区域,为了它能够生成更好局部图像恢复图,并且判别网络能够把注意力放在应该被评估的局部区域上。
Attentive-Recurrent Network. Visual attention models have been applied to localizing targeted regions in an image to capture features of the regions. The idea has been utilized for visual recognition and classification (e.g. [26, 15, 5]). In a similar way, we consider visual attention to be important for generating raindrop-free background images, since it allows the network to know where the removal/restoration should be focused on. As shown in our architecture in Fig. 2, we employ a recurrent network to generate our visual attention. Each block (of each time step) in our recurrent network comprises of five layers of ResNet [8] that help extract features from the input image and the mask of the previous block, a convolutional LSTM unit [21] and convolutional layers for generating the 2D attention maps.
注意力递归网络. 视觉注意力模型被用于在一张图像上定位目标区域来捕捉区域的特征。这个想法已经被用于视觉识别和分类上了。以相似的方式,我们认为视觉注意力对于生成没有雨滴的背景图像来说是非常重要,因为它允许网络知道哪些区域是应该去除/恢复的。正如在上面的网络架构图上展示的一样,我们使用一个递归网络来生成我们的视觉注意力。我们的递归网络的每一个块(每一个时间步)由帮助提取从输入图像中提取特征以及上一个块的掩码的5层ResNets、一个卷积LSTM单元、用于生成2D Attention maps的卷积层组成。
Our attention map, which is learned at each time step, is a matrix ranging from 0 to 1, where the greater the value, the greater attention it suggests, as shown in the visualization in Fig. 3. Unlike the binary mask, M, the attention map is a non-binary map, and represents the increasing attention from non-raindrop regions to raindrop regions, and the values vary even inside raindrop regions. This increasing attention makes sense to have, since the surrounding regions of raindrops also needs the attention, and the transparency of a raindrop area in fact varies (some parts do not totally occlude the background, and thus convey some background information).
我们的attention map,从每一个时间步中学习得到,它是一个值在0~1的矩阵,值越大,对应更大的注意力,如下图所示。与二进制掩码M不同,Attention map是一个非二进制的map,它表示从非雨滴区域到雨滴区域递增的注意力,甚至在雨滴区域的内部也是不同的。递增的注意力是非常有意义的,因为雨滴区域的周围也是应该被注意的,并且事实上雨滴区域的透明度也是不同的。(一些部分没有完全被遮挡,因此传递了一些背景信息)。

In training the generative network, we use pairs of images with and without raindrops that contain exactly the same background scene. The loss function in each recurrent block is defined as the mean squared error (MSE) between the output attention map at time step t, or At, and the binary mask, M. We apply this process N time steps. The earlier attention maps have smaller values and get larger when approaching the Nth time step indicating the increase in con- fidence. The loss function is expressed as:
在训练生成网络的时候,我们使用具有相同背景的有雨滴和没有雨滴的图像对。每一个递归块的损失函数都被定义为时间步骤t和二进制掩码M之间的均方误差,我们应用了N个时间步。越早的Attention map对应的权值越小,当接近第N个时间步权值变大,这也暗示自信度的增加。损失函数的定义如下所示:

where At is the attention map produced by the attentive-recurrent network at time step t. We set N to 4 and θ to 0.8. We expect a higher N will produce a better attention map, but it also requires larger memory.
上式中的At是注意力递归网络在时间步t的时候生成的Attention map。我们把N设置为4,theta设置为0.8。N越大,将会产生一个更好的attention map,但是它也会要求更大的内存。Contextual Autoencoder.
The purpose of our contextual autoencoder is to generate an image that is free from raindrops. The input of the autoencoder is the concatenation of the input image and the final attention map from the attentive-recurrent network. Our deep autoencoder has 16 conv-relu blocks, and skip connections are added to prevent blurred outputs. Fig. 4 illustrates the architecture of our contextual autoencoder.
上下文自动编码器.
我们的上下文自动编码器的目的是生成一张没有雨滴的图像,自动编码器的输入是输入图像和注意力递归网络自动生成的Attention map的联合(Concatenation是个名词,意思是联结). 我们的深度自动编码器有16个conv-relu块(conv-relu的意思是先卷积,再使用relu函数激活),并且为了防止模糊输出增加了跳跃联结。图Fig.4. 展示了我们的上下文自动编码器的架构。
As shown in the figure, there are two loss functions in our autoencoder: multi-scale losses and perceptual loss. For the multi-scale losses, we extract features from different decoder layers to form outputs in different sizes. By adopting this, we intend to capture more contextual information from different scales. This is also the reason why we call it contextual autoencoder.
正如上图所展示的,在自动编码器中有两个损失函数:多尺度损失和感知损失。对于多尺度损失,我们从不同的解码层中提取特征来形成不同尺寸的输出。通过采用这个方法,我们尝试从不同的尺度中捕捉更多的上下文信息。这也是我们称它为上下文自动编码器的原因。
We define the loss function as:
where Si indicates the ith output extracted from the decoder layers, and Ti indicates the ground truth that has the same scale as that of Si . {λi}are the weights for different scales. We put more weight at the larger scale. To be more specific, the outputs of the last 1st, 3rd and 5th layers are used, whose sizes are 1/4 , 1/2 and 1 of the original size, respectively. Smaller layers are not used since the information is insignificant. We set λ’s to 0.6, 0.8, 1.0.
我们将(多尺度损失)定义为下式,Si表示从解码层中提取的第i个输出,Ti表示与Si具有相同尺度的真值. {λi}是不同的尺度的权重。我们赋予了更大的尺度更大的权重。具体来说,我们使用了最后一层、第三层和第五层的输出,它们的尺寸分别是原始尺寸的1/4、1/2和1。更小的层我们没有使用,因为它们的信息不是很重要。我们将λ设置为0.6、0.8、10.
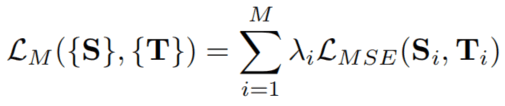
Aside from the multi-scale losses, which are based on a pixel-by-pixel operation, we also add a perceptual loss that measures the global discrepancy between the features of the autoencoder’s output and those of the corresponding ground-truth clean image. These features can be extracted from a well-trained CNN, e.g. VGG16 pretrained on ImageNet dataset. Our perceptual loss function is expressed as:
除了多尺度损失之外,多尺度损失是基于像素对像素的操作,我们也增加了一个感知损失用来衡量自动编码器的输出和对应的真实的干净图像之间的全局差异discrepancy是个名词,意思是不符、矛盾、相差. 这些特征是用一个训练好的CNN模型(比如说用ImageNet数据集预训练的VGG16)提取的。感知损失函数可定义为下式:

where VGG is a pretrained CNN, and produces features from a given input image. O is the output image of the autoencoder or, in fact, of the whole generative network: O = G(I). T is the ground-truth image that is free from raindrops.
上面的VGG是一个预训练的CNN模型,它能够生成给定的输入图像的特征。O是自动编码器的输出图像,实际上,也是整个生成网络的输出图像:O=G(I). T是没有雨滴的真实的干净的图像。
Overall, the loss of our generative can be written as:
综合来看,整个生成网络的损失函数为:
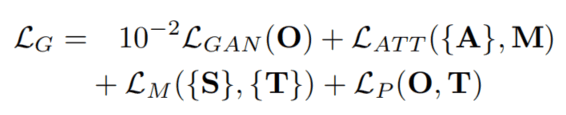
L G A N ( O ) = l o g ( 1 − D ( O ) ) L_{GAN}(O)=log(1-D(O)) LGAN(O)=log(1−D(O)),它是生成对抗网络中生成器自身的损失。
4.2. Discriminative Network
To differentiate fake images from real ones, a few GAN-based methods adopt global and local image-content consistency in the discriminative part (e.g. [9, 13]) . The global discriminator looks at the whole image to check if there is any inconsistency, while the local discriminator looks at small specific regions. The strategy of a local discriminator is particularly useful if we know the regions that are likely to be fake (like in the case of image inpainting, where the regions to be restored are given). Unfortunately, in our problem, particularly in our testing stage, we do not know where the regions degraded by raindrops and the information is not given. Hence, the local discriminator must try to find those regions by itself.
为了区分从真图像中区分出假图像,一些基于GAN的方法在判别部分采用全局和局部图像内容一致性判别。全局判别器查看整个图像来检查是否有任何不一致性,然而局部判别器查看小的特定区域。一个局部图像判别器的策略非常的有用,如果我们知道那些可能是假的区域(比如说图像恢复的例子,被恢复的区域给出来了)。不幸的是,在我们的问题中,特别是在我们的测试阶段,我们并不知道哪些图像被雨滴污染了,并且它的信息没有给出。因此,局部判别器必须自己尝试找出来这些区域。
To resolve this problem, our idea is to use an attentive discriminator. For this, we employ the attention map generated by our attentive-recurrent network. Specifically, we extract the features from the interior layers of the discriminator, and feed them to a CNN. We define a loss function based on the CNN’s output and the attention map. Moreover, we use the CNN’s output and multiply it with the original features from the discriminative network, before feeding them into the next layers. Our underlying idea of doing this is to guide our discriminator to focus on regions indicated by the attention map. Finally, at the end layer we use a fully connected layer to decide whether the input image is fake or real. The right part of Fig. 2 illustrates our discriminative architecture.
为了解决这个问题,我们的想法是使用一个注意力判别器。为此,我们应用了再注意递归网络中生成的Attention map。具体来说,我们从判别的内部层中提取特征,并且将他们喂进CNN模型中。我们基于CNN的输出和Attention map定义了一个损失函数。还有,我们使用CNN的输出并且将它与判别网络的原始特征相乘,在喂去下一层之前。我们这样做的潜在的想法是引导我们的判别去注意Attention map所暗示的区域。最后,我们使用了一个全连接层来确定输入是假的还是真的。Fig.2展示了我们的判别网络的架构。
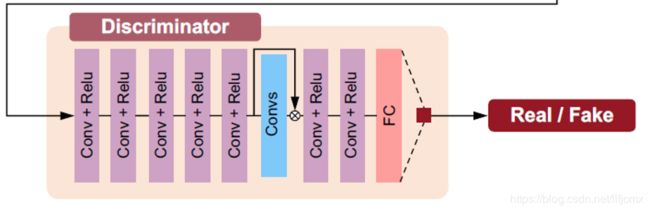
对判别网络做一个更通俗的解释:输入是生成网络生成的干净图像,然后经过五个Conv+Relu层得到图像的特征(文章中说的原始特征),经过Convs,这里其实用到了Attention map(从损失函数可以看出来),然后与原始的特征,相当于剩下的都是有雨滴区域的特征(即得到了雨滴区域),然后送入下一层进行判别。
The whole loss function of the discriminator can be expressed as:
生成器的整个损失函数可以定义为下式:
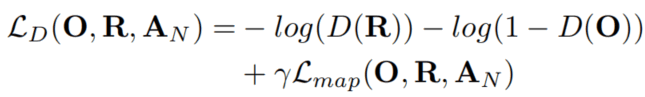
where Lmap is the loss between the features extracted from interior layers of the discriminator and the final attention map:
上式中的Lmap是从判别的内部层中提取的特征与最终的Attention map的损失。
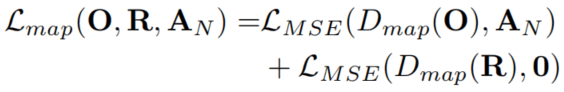
where Dmap represents the process of producing a 2D map by the discriminative network. γ is set to 0.05. R is a sample image drawn from a pool of real and clean images. 0 represents a map containing only 0 values. Thus, the second term of Eq. (9) implies that for R, there is no specific region necessary to focus on.
这里的Dmap代表判别网络生成的2D map图。γ被设置为0.05. R是真实的干净的图像库中的样本图像,0代表这个具有0值的map。因此,上式的第二项代表真实图像R没有需要注意的区域。
5. Raindrop Dataset
Similar to current deep learning methods, our method requires relatively a large amount of data with groundtruths for training. However, since there is no such dataset for raindrops attached to a glass window or lens, we create our own. For our case, we need a set of image pairs, where each pair contains exactly the same background scene, yet one is degraded by raindrops and the other one is free from raindrops. To obtain this, we use two pieces of exactly the same glass: one sprayed with water, and the other is left clean. Using two pieces of glass allows us to avoid misalignment, as glass has a refractive index that is different from air, and thus refracts light rays. In general, we also need to manage any other causes of misalignment, such as camera motion, when taking the two images; and, ensure that the atmospheric conditions (e.g., sunlight, clouds, etc.) as well as the background objects to be static during the acquisition process.
与目前的深度学习方法类似,为了训练我们的方法需要相对大量的真实数据。然而,因为没有这样的吸附在玻璃窗或者镜头上的雨滴的数据集,所以我们创建了自己的数据集。在我们的方法中,我们需要一系列的图像对,每一对图像都包含相同的背景,但是一张被雨滴污染了,另一张是没有雨滴的图像。为了达到这个目的,我们使用了两片相同的玻璃:一张撒上水,一张是干净的。使用两片玻璃可以帮助我们避免不对齐的问题,因为玻璃的折射率和空气不同,因此会折射光线。总体来说,我们也需要解决其他任何的不对齐的原因,比如当拍摄两张图像的时候相机的运动,并且在采集过程中,确保大气条件(比如阳光、云层等)以及背景中的物理是静态的。
In total, we captured 1119 pairs of images, with various background scenes and raindrops. We used Sony A6000 and Canon EOS 60 for the image acquisition. Our glass slabs have the thickness of 3 mm and attached to the camera lens. We set the distance between the glass and the camera varying from 2 to 5 cm to generate diverse raindrop images, and to minimize the reflection effect of the glass. Fig. 5 shows some samples of our data.
我们一共采集了1119对图像,在不同的背景和雨滴情况下。我们使用索尼A6000和Canon EOS 60来进行图像采集。我们的玻璃板的厚度是3mm,并且贴附在相机镜头上。我们将玻璃和镜头之间的距离设置为2-5cm,以产生不同雨滴图像,并最大限度的减少玻璃的反射效果。下图Fig.5. 展示了我们的数据样本。

6. Experimental Results
整篇文章的最核心的部分已经翻译完了,并且加上了一些自己的理解。实验结果部分只是展示了作者的方法的有效性,我个人认为不是最重要的。所以这部分我就不按照原文进行翻译了,直接给出结果吧。
可以看出,作者的方法的效果是已有的几种方法中最好的。
这篇论文就翻译到这儿把,文中有问题的地方希望各位慷慨指出。下面是我的个人公众号,有兴趣的可以关注一下,一周大概会推3篇关于深度学习和SLAM的文章,如果休闲时间较多愿意和我一起运营的话,也可以通过邮箱([email protected])与我联系。