Python学习笔记之Flask问题总结
一、解释什么是Flask及其好处?
Flask是一个使用Python编写的轻量级WEB应用框架,其WSGI(Python Web服务器网关接口)工具采用Werkzeug,模版引擎则使用Jinja2。Flask使用BSD授权。Flask属于微框架这一类别,微框架通常是很小的不依赖外部库的框架。这既有优点也有缺点,优点是框架很轻量,更新时以来少,而且专注安全方面的Bug,缺点是,你不得不自己作更多的工作,或通过添加插件增加自己的依赖列表,Flask的依赖如下:
- Werkzeug一个WSGI工具包
- jinja2模板引擎。
Flask优点:
- Flask只提供供了一些核心功能,简洁。
- flask的blueprint使它可以能够很方便的进行水平扩展,实现模块化。
- flask配置灵活。
- flask拥有详尽的文档
二、Django和Flask有什么区别?
Flask:
1、轻量级web框架,只有一个内核,默认依赖两个外部库:jinja2模板引擎和Werkzeug WSGI 工具集,自由灵活,可扩展性强。
2、使用与做小型网站以及web服务API,开发大型网站无压力,架构需要自己设计。
3、与关系型数据库结合不弱于Django,而与非关系型数据库的结合远远优于Django
Django:
1、重量级web框架、功能齐全,提供一站式解决思路,能让开发者不用在选择应用上花费大量的时间
2、自带ORM(对象关系映射)和模板引擎,支持jinja等非官方模板引擎,灵活度不高
3、自带ORM使Django和关系型数据库耦合度过高,如果非要使用非关系型数据库,需要第三方库
4、自带数据库管理app
5、成熟、稳定、开发效率高、相对于Flask、Django的整体封闭性较好、适合做企业级网站的开发
6、python web 框架的先驱、第三方库完善
7、上手容易、开发文档详细、完善、资料丰富
本问题答案转载源
三、Flask-WTF是什么,有什么特点?
Flask-WTF是flask的一个表单数据验证处理插件,其wtforms模块中带有许多的验证类,并且在其中有DataRequired验证器,并且我们也可以通过自定义检查规则去表单数据(自定义的检查规则函数命名规则:validate_字段名)。
特点:
- 数据验证安全方便
- 在内部已经为我们封装好了前端页面的Form
- 已经做好了校验工作
- 和前端代码耦合性比较低
四、Flask脚本的使用方式是什么?
- 在shell中使用命令(python3 xxx.py)运行对应的.py文件
- 在pycharm解释器中打开flask项目并运行。
五、什么是flask会话?如何在Flask中访问会话?
flask会话:
会话/session是为web服务器简历状态的一个成熟模式。会话主要解决两个问题
- 访问者的标示问题:
服务器需要识别来自同一访问者的请求。这主要是通过浏览器的cookies实现的。访问者在第一次访问服务器是,服务器在其cookies中设置一个唯一的ID号——会话ID。这样访问者后续对服务器的访问头中将自动包含该信息,服务器通过这个ID号即可区别不同的访问者
- 访问者的信息记录的问题:
服务器可以记录、提取访问者的历史信息。对每一个会话ID,服务端维护一个数据上下文,这个数据运行在内存中,通常在变化时持久化到文件系统和数据库中。
Flask中访问会话:
在视图函数内Flask提供了全局对象session,它时中等效于当前请求所对应的session类的示例对象。session类定义了get_item()方法set_item()方法,因此我们可以像使用Dict对象一样,通过操作符读取或设置会话变量:
一个会话基本上允许记住从一个请求到另一个请求的信息。在Flask中,它使用签名的cookie,以便用户可以查看会话内容并进行修改。用户可以修改会话,只要它有密钥Flask.secret_key。
# -*- coding:utf-8 -*-
from flask import Flask,session,request
app = Flask(__name__)
app.secret_key = 'XOIU01293jkjsjfdg127'
@app.route('/')
def v_index():
if 'counter' not in session:
session['counter'] = 0
session['counter'] = session['counter'] + 1
return 'this is your %d times visit' % session['counter']
app.run(host='0.0.0.0',port=8080)六、Flask是一个MVC模型吗?若果是,可以示例一下吗?
MVC模型是一种使用MVC(模型-视图-控制)设计创建web应用的模式。MVC分层的同时也简化了分组开发,不同的开发人员可同时开发视图、控制器逻辑、和业务逻辑,并且实现了代码的解耦合。
flask是一种MVC模型,我们可以通过下面一段代码分析:
后台代码:
from flask import Flask,render_template
app = Flask(__name__)
@app.route('//')
def mvc_test(name):
return render_template('mvc_test.html',name=name)
if __name__ == '__main__':
app.run(host='172.25.254.2',port=9099) 前端代码:
Flask-MVC模式证明
Flask-MVC模式证明:{{ name }}
我想前端和后台代码都非常简单,看懂不是问题,现在就来详细分析这两段代码中的mvc模型:
- 首先我们在浏览器中输入一个172.25.254.2:9099/name_python/路由时,浏览器进行GET请求,此时会将name_python的值传入装饰器@app.route('/
- 该路由会启动函数mvc_test(name)函数运行,并将name_python作为实参传入,render_template()函数会将形参name的值传递给前端(前端中调用变量名name)
- 在前端页面中代码
Flask-MVC模式证明:{{ name }}
会去调用name变量,并将其的值显示,与用户进行交互。
在上面三个步骤中:html页面源代码就像一个模版,将我们的数据进行调用与用户交互,最终用户看到的不是一个html页面。而在完成变量的调用与路由的生成,页面的返回等步骤都属于我们的控制器逻辑(可参见下图深入理解)。
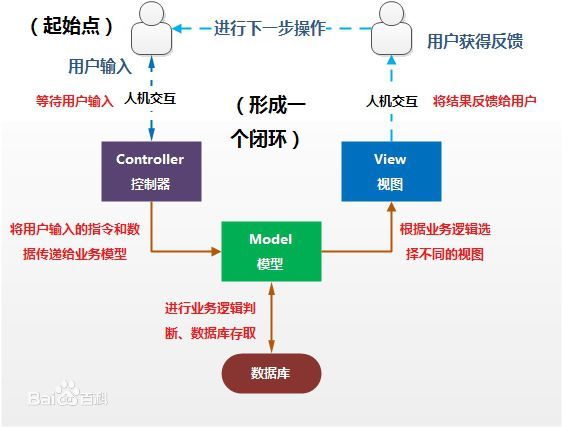
上图为mvc模型
七、解释Python Flask中的数据库链接?
- 安装pymysql、flask_sqlalchemy模块、并导入SQLAlchemy
- 创建应用程序app,并将其传给QLAlchemy构造函数
from flask import Flask
from flask.ext.sqlalchemy import SQLAlchemy
app = Flask(__name__)
db = SQLAlchemy(app)
- Flask-SQLAlchemy配置链接数据库(参见flask_sqlalchemy配置)
app.config['SQLALCHEMY_DATABASE_URI'] ='mysql+pymysql://root:123456@localhost/RelationOrmFlask_2'
#mysql+pymysql:数据库类型、root:用户名、123456:数据库密码、@localhost:链接主机
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True- 继承db.Model类创建表格,
db.create_all(self, bind='__all__', app=None)函数可以创建指定app的指定的表格同样db.drop_all(self, bind='__all__', app=None)函数可以删除指定app的指定表格,如果两个函数不传递参数,则会创建所有继承了db.Model的类的表格,或者删除该链接的数据库中的所有的表格。创建表格类时使用db.Column()函数可以创建表格表头,并使用db.session.commit()提交操作class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True)
email = db.Column(db.String(120), unique=True)
def __init__(self, username, email):
self.username = username
self.email = email
def __repr__(self):
return '' % self.username -
通过表对象查找表中的行信息对象,并进行增删改查
Flask-SQLAlchemy 在的 Model 类上提供了 query 属性。当访问它时,会得到一个新的所有记录的查询对象。在使用 all() 或者 first() 发起查询之前可以使用方法 filter() 来过滤记录。如果想要用主键查询的话,也可以使用 get()。
user = User(username = 'xiaoming') #实例化db.Model的子类对象
db.session.add(user) #增加
peter = User.query.filter_by(username='peter').first() #查找
peter.username = 'liqiang' #更改表中某个组的属性信息
db.session.delete(peter) #删除
db.session.commit()#提交操作
八、谈谈restful?(参考博文)
理解RESTFUL架构我们先要理解Representational State Transfer即‘表现层转化’。
(1)资源(Resources)所谓的资源就是网络上的一个实体,可以是一种服务,一首歌曲,一张图片...可以使用一个URL指向它,梅花宗资源对应一个特定的URL。要获取资源,访问这个url即可。
(2)表现层(Representation):即我们把‘资源’具体呈现出来的形式。文本可以用txt格式表现,也可以用HTML格式、XML格式、JSON格式表现,甚至可以采用二进制格式;图片可以用JPG格式表现,也可以用PNG格式表现。
(3)状态转化(State Transfer):http协议是一个无状态协议,这意味着,所有的状态都保存在服务器端,因此客户端想要操作服务器,必须用过某种手段,日那个服务器发生‘状态变化(State Transfer)‘。而这种转化是建立在表现层值上的,所以就是‘表现层状态转化‘。客户端用到的手段,只能时HTTP协议,简单来讲,就是HTTP协议中的四个操作:GET、POST、PUT、DELETE。他们分别对应的操作为GET:用来获取资源、POST用来新建资源、PUT用来更新资源、DELETE用来删除资源。
综述:RESTful架构:
(1) 每一个url代表一种资源
(2)客户端和服务器之间,传递这种资源的某种表现层
(3)客户端通过四个HTTP动词,队服务器端资源进行操作,实现‘表现层状态转化’。
九、列举HTTP常见的请求方式?
http常见的请求方法有下面几种:
- GET:浏览器告知服务器:只获取页面上的信息并发给我
- POST:浏览器告知服务器:想要在URL上发布新信息。并且服务器必须保证数据已经存储且仅一次。是Html表单通常发送数据到服务器的方法之一。
- HEAD:浏览器告知服务器:欲获取信息,但只关心消息头。应用应像处理GET请求一样来处理它,但是不发送实际内容。在Flask中完全无序人工干预,底层werkzeug已经完成。
- PUT:类似POST,但是服务器可能触发存储过程多次,多次覆盖调久值。因为,传输中链接可能丢失,在这种情况下浏览器和服务器只见的系统可能安全的第二次接收请求,而不破坏其他东西,因为POST它只触发一次,所以用POST是不可能的。
十、列举http请求中的状态码?
http 状态码返回 1xx(临时响应)
100(继续)请求者应当继续提出请求,服务器返回才代码表示已经收到请求的第一部分,正在等待其余部分。
101(切换协议)请求者已要求服务器切换协议,服务器已经确认并准备切换。
http状态码返回2xx (成功)表示已经成功处理了请求的状态码
200(成功)服务器已经成功处理了请求,通常这表示服务器提供了请求的页面。
201(已经创建)请求成功并且服务器创建了新的资源。
202(已经接受)服务器已经接受请求但是未处理。
204(无内容)服务器成功处理了请求但是没有返回任何内容
http状态码3xx(重定向)表示完成了请求,需要进一步操作。
300(多种选择)针对请求,服务器可以执行多种操作,服务器可根据请求者选择一项操作,或提供操作列表给请求者选择
301(永久移动)请求的网页已经永久移动到新位置,服务器返回响应的请求时会自动转到新位置。
302(临时移动)请求者当对应不同位置使用单独的GET请求来检索响应时,服务器返回此代码
307
http状态码4xx(请求错误),这些状态码表示客户端的请求可能出错,服务器无法处理。
400(请求错误)服务器不理解请求的语法
401(未授权)请求要求身份验证。对于需要登录的网页,服务器可能会返回该响应
403(禁止)服务器拒绝请求(有可能是客户端没有权限)
404(未找到)服务器找不到请求的网页。
408(请求超时)服务器等候请求时发生超时
414(请求的url过长)请求的 URI(通常为网址)过长,服务器无法处理
http状态码返回5xx(服务器错误)
500 (服务器内部错误)服务器遇到错误,无法完成请求。
503(服务不可用)服务器作为网关或代理,但是没有及时从上游服务器收到请求。
十一、列举http请求中常见的请求头与响应头?
http请求中常用的请求头:
Accpet : 告诉服务器,客户端支持的数据类型
Accpet-Charset : 告诉服务器客户端采用的编码格式
Accpet-Encoding:告诉服务器,客户机支持的数据压缩格式
Accept-Language:告诉服务器,客户机的语言环境。
Host:客户机通过这个头告诉服务器想要访问的主机名
if-Modified-Since:客户机告诉服务器资源缓冲的时间
Refere:客户机告诉服务器,它是从哪个资源来访问服务器的(一般用于防盗链)
User-Agent:客户机通过这个头告诉服务器,客户机的软件环境
Cookie:客户机通过这个告诉服务器,可以项服务器带数据
Connection:客户机告诉服务器,请求完成后是保持关闭还是保持链接。
Date:客户机通过着告诉服务器,客户机当前请求时间。
http请求中常见的响应头:
Server:服务器通过这个头告诉浏览器的类型。
Content-Encoding:服务器通过这个头告诉浏览器采用的数据压缩格式。
Content-Length:服务器通过这个头告诉浏览器返回的数据长度。
Content-Language:服务器通过这个头告诉服务器的语言环境
Content-Type:服务器通过这个头回送数据类型
Last-Modified:服务器通过这个头告诉浏览器当前资源的缓存时间。
Refresh:服务器通过这个头,告诉浏览器每隔多久刷新一次。
Content-Dispostion:服务器告诉浏览器以下载方式打开数据
Transfer-Encoding:告诉浏览器的数据传送格式
Etag:与缓存相关的头
Expires:告诉浏览器把回送的数据缓存多久,-1或0不缓存。
Cache-Control和Pragma:服务器通过这个头,可以控制浏览器不缓存数据。
Connection:服务器通过这个头,响应完是保持链接还是关闭链接。
Date:告诉客户机,返回响应的时间。
十二、什么是wsgi?
对于一个web应用和程序来讲,最基本的概念就是客户端发送请求(request),受到服务器端的响应(response)。在实际中,python程序是放在服务器的http server(比如apache,nginx等)上的。现在的问题是:服务器程序怎样把接收到的请求传递给python呢,怎么在网络的数据流和python的结构体只见转换呢?而这就是wsgi做的事情:一套关于程序端与服务端的规范,或者说统一的接口。
WSGI应用程序端:
WSGI规定每个python程序(Application)必须是一个可调用的对象(实现了__call__函数的方法或者类),并接受两个参数environ(WSGI环境信息)和start_response(开始响应请求的函数),并返回一个iterable(可迭代对象)
注意:1.environ和start_response由http server提供并实现
2.environ变量包含了环境信息的字典
3.Application内部在返回前调用start_response
4.start_response也是一个callable,接收两个必须的参数,status(http状态)和response_headers(响应消息的头)
5.Applcation返回对象是一个可迭代的值
WSGI服务器程序端:
前面说过标准要确切的执行,必须要求程序端和服务端必须共同遵守。nevrion和start_response都是服务器端提供的。那么服务器需要履行的义务如下。
1.准备environn参数
2.定义start_response函数
3.调用程序端的可调用对象(如Application)
中间层middleware
有些程序可能会处于服务器端和程序端两者之间:对于服务器程序,他就是应用程序;而对于应用程序,他就是服务程序。这就是中间层:middleware。middleware对服务器程序和应用是透明的,他就像一个代理/管道一样,把接收到的请求进行一些处理,然后往后传递,一直传递到客户端程序,最后把程序的客户端处理结果在进行返回。
参考博文
十三、Flask框架依赖结构
flask主要依赖两个外部库:
-
jianja2模板引擎
-
Werkzeng WSGI工具集.