Python爬虫:爬取国内所有高校名称、类型、官网
本博客仅用于技术讨论,若有侵权,联系笔者删除。
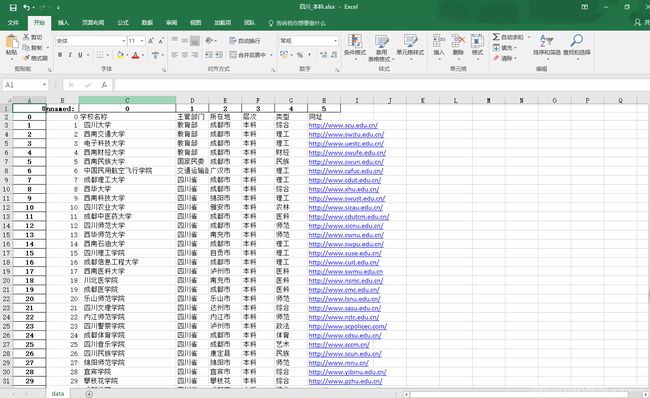
此次的目的是爬取国内高校的基本信息,并按省份存储。爬取的黄页是http://www.gx211.com/gxmd/gx-bj.html。以下是结果图:

一、初始化数据
初始化基本的数据,包括global变量,省份名称等等。
from bs4 import BeautifulSoup
from selenium import webdriver
import pandas as pd
import requests
import csv
from string import digits
#初始化
def init():
global url, headers, province_name, province_url_address, driver
url = 'http://www.gx211.com/gxmd/'
province_name = [
'北京', '天津', '河北', '山西', '辽宁', '吉林', '黑龙江', '上海',
'江苏', '浙江', '安徽', '福建', '江西', '山东', '河南', '湖北',
'湖南', '广东', '内蒙古', '广西', '海南', '重庆', '四川', '贵州',
'云南', '新疆', '陕西', '甘肃', '青海', '宁夏', '新疆'
]
headers = {
'Cookie':'acw_tc=7b39758215646241450881184e8baf04d936a25ea3fe3414443e15b0efc3ba; UM_distinctid=16c4addcb52784-087525bdc71e12-c343162-13c680-16c4addcb53826; Hm_lvt_afa8c15093ebdca7a48e7d4be02e164b=1564625709; CNZZDATA2098941=cnzz_eid%3D1427590086-1564621705-null%26ntime%3D1564731169; acw_sc__v2=5d43f50ababce2fa803faca1fcf442c3ce835610; acw_sc__v3=5d43f50bdb92af42b7fe3555b33740a6e4202b94',
'Host':'www.gx211.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
province_url_address = []
driver = webdriver.Chrome()
driver.implicitly_wait(30)二、获取各省的URL
由网页得知,其各省的数据在不同的html。所以先获取各省的URL,再分别对每个省进行操作。
#获取各省链接
def province_url():
r = requests.get('http://www.gx211.com/gxmd/gx-bj.html',headers=headers,timeout=10)
print(r.text)
soup = BeautifulSoup(r.text, "lxml")
# 非法URL 1
invalidLink1='#'
# 非法URL 2
invalidLink2='javascript:void(0)'
for k in soup.find_all('a', target = '_self'):
link=k.get('href',)
if(link is not None):
#过滤非法链接
if link==invalidLink1:
pass
elif link==invalidLink2:
pass
elif link.find("javascript:")!=-1:
pass
else:
province_url_address.append(link)三、保存省的高校数据
由于每个省的高校数据是以table的形式存放在网上,所以笔者直接用pandas将table转化为excel的形式存储。
#保存当前省份的数据
def sav_province_school_data(now_province_url, now_province_name):
#school_attributes = ['本科', '专科', '独立', '民办']
#i = 0
#for tb in pd.read_html(url+now_province_url):
# tb.to_csv('./高等院校官网爬虫数据/'+now_province_name+'_'+school_attributes[i]+'.csv', mode='a', encoding='GBK', header=0, index=0)
# i = i + 1
new_url = url+now_province_url
driver.get(new_url)
tab = driver.find_element_by_class_name("WrapContent")
tab_html = tab.get_attribute('outerHTML')
tab_dfs = pd.read_html(tab_html)
# tb = tab_dfs[0]
# tb.to_csv('./高等院校官网爬虫数据/'+now_province_name+'_本科.csv', mode='a', encoding='GB18030', header=0, index=0)
tb = tab_dfs[0]
tb.to_excel('./高等院校官网爬虫数据/'+now_province_name+'_本科.xlsx', sheet_name='data')
data_clean('./高等院校官网爬虫数据/'+now_province_name+'_本科.xlsx')
tb = tab_dfs[1]
tb.to_excel('./高等院校官网爬虫数据/'+now_province_name+'_专科.xlsx', sheet_name='data')
data_clean('./高等院校官网爬虫数据/'+now_province_name+'_专科.xlsx')
tb = tab_dfs[2]
tb.to_excel('./高等院校官网爬虫数据/'+now_province_name+'_独立.xlsx', sheet_name='data')
data_clean('./高等院校官网爬虫数据/'+now_province_name+'_独立.xlsx')
tb = tab_dfs[3]
tb.to_excel('./高等院校官网爬虫数据/'+now_province_name+'_民办.xlsx', sheet_name='data')
data_clean('./高等院校官网爬虫数据/'+now_province_name+'_民办.xlsx')四、清洗数据
由于直接用pandas转化,所以在高校名称的列,名称还包括了编号和985.211等信息。这些都不是笔者想要的所以再写一个清洗函数。
#清洗函数
def data_clean(province):
data = pd.read_excel(province, sheet_name='data')
#data[0] = re.search(r'^[0-9]* (.*?)(211(.985)?)?$', data[0])
new_data = []
for i in range(1, len(data[0])):
remove_digits = str.maketrans('', '', digits)
data[0][i] = data[0][i].translate(remove_digits)
data[0][i] = data[0][i].replace('.','')
data.to_excel(province,sheet_name='data')五、主函数
主函数则负责整个逻辑,包括对各省的循环操作。
#主函数
if __name__ == '__main__':
init()
province_url()
i = 0
print(province_url_address)
for pro_url in province_url_address:
sav_province_school_data(pro_url, province_name[i])
i = i + 1