解决Python中读Oracle数据库的中文编码问题
一、编码
字符是各种文字和符号的总称,包括各个国家文字、标点符号、图形符号、数字等。字符集是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集有:ASCII字符集、ISO 8859字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等。计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
1、ASCII
ASCII(American Standard Code for Information Interchange),是一种单字节的编码。计算机世界里一开始只有英文,而单字节可以表示256个不同的字符,可以表示所有的英文字符和许多的控制符号。
2、GB2312,GBK和GB18030
(1)GB2312
当中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存,于是GB2312 是对 ASCII 的中文扩展。兼容ASCII。(2)GBK
但是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,不得不继续把 GB2312 没有用到的码位找出来用上。后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 “GBK” 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。(3)GB18030
后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK 扩成了 GB18030。从此之后,中华民族的文化就可以在计算机时代中传承了。3、Unicode
后来,有人开始觉得太多编码导致世界变得过于复杂了,让人脑袋疼,于是大家坐在一起拍脑袋想出来一个方法,国际组织制定了 UNICODE 字符集,为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。
目前计算机一般使用 2 个字节(16 位)来存放一个序号(DBCS,Double Byte Character System),因此,这种方式存放的字符也被称作宽字节字符。比如,字符串 “中文123” 在 Windows 2000 下,内存中实际存放的是 5 个序号,一共10个字节。
4、UTF-8
Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)。UTF-8作为一种常用的字符编码,是变长的,最多是使用3个字节来表示一个字符。
二、Oracle编码
查询Oracle Server端的字符集:
有很多种方法可以查出oracle server端的字符集,比较直观的查询方法是以下这种:
SQL>select userenv(‘language’) from dual; 三、Python读取数据库
# -*- coding: utf-8 -*-
import pandas as pd
import cx_Oracle
conn = cx_Oracle.connect("c##Badrain/person@localhost:1521/orclavip")
cursor = conn.cursor ()
sql = "select * from table_test"
cursor.execute(sql)
rows = cursor.fetchall()
#rows[0][1] = rows[0][1].encode('utf8')
data = pd.DataFrame(rows,columns=['id','text'])
print data id text
0 1 �Ϻ�
1 2 ����如果要正确输出,我们需要首先对读入的字符串以GBK编码形式进行解码然后再以UTF-8形式进行编码:
text = data.loc[:,'text']
text = pd.Series([text[item].decode('GBK').encode('UTF-8') for item in text])
data.loc[:,'text'] = text
print data id text
0 1 上海
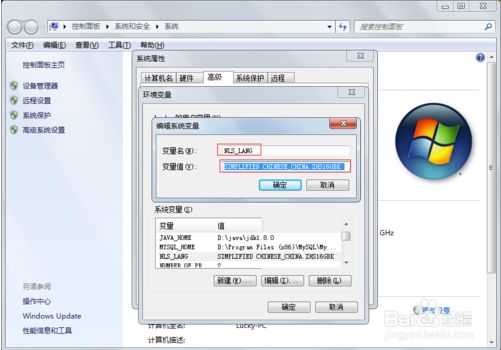
1 2 杭州四、配置环境变量
如果仅仅是安装了Oracle,却没有在环境变量中进行相应的配置,那么可能发生各种各样的错误。
比如这样的:
shopid dishid dishname price score
dishid
4383 1591234189 4383 ???? 22.0 6.0
4391 1591234189 4391 ???? 18.0 9.0
变量名叫 NLS_LANG。 变量值 SIMPLIFIED CHINESE_CHINA.ZHS16GBK 说明:这里,请大家直接复制上面的变量值。 具体配置界面见下图: