源码解析MyBatis Sharding-Jdbc SQL语句执行流程详解
源码分析Mybatis系列目录:
1、源码分析Mybatis MapperProxy初始化之Mapper对象的扫描与构建
2、源码分析Mybatis MappedStatement的创建流程
3、Mybatis执行SQL的4大基础组件详解
源码解析MyBatis Sharding-Jdbc SQL语句执行流程详解
- 1、SQL执行序列图
- 2、源码解析SQL执行流程
- 2.1 MapperProxy#invoker
- 2.2 MapperMethod#execute
- 2.3 MapperMethod#executeForMany
- 2.4 DefaultSqlSession#selectList
- 2.5 BaseExecutor#query
- 2.6 SimpleExecutor#doQuery
- 3、Statement对象创建流程
- 3.1 java.sql.Connection对象创建
- 3.1.1 SimpleExecutor#prepareStatement
- 3.1.2 SimpleExecutor#getConnection
- 3.2 java.sql.Statement对象创建
- 3.2.1 BaseStatementHandler#prepare
- 3.2.2 PreparedStatementHandler#instantiateStatement
- 3.2.2 ShardingConnection#prepareStatement
- 4、SQL执行流程
- 4.1 PreparedStatementHandler#query
- 4.2 ShardingPreparedStatement#execute
- 4.3 ShardingPreparedStatement#routeSQL
- 4.4 PreparedStatementExecutor#execute
- 4.4 DefaultResultSetHandler#handleResultSets
本文将详细介绍Mybatis SQL语句执行的全流程,本文与上篇具有一定的关联性,建议先阅读该系列中的前面3篇文章,重点掌握Mybatis Mapper类的初始化过程,因为在Mybatis中,Mapper是执行SQL语句的入口,类似下面这段代码:
@Service
public UserService implements IUserService {
@Autowired
private UserMapper userMapper;
public User findUser(Integer id) {
return userMapper.find(id);
}
}
开始进入本文的主题,以源码为手段,分析Mybatis执行SQL语句的流行,并且使用了数据库分库分表中间件sharding-jdbc,其版本为sharding-jdbc1.4.1。
为了方便大家对本文的源码分析,先给出Mybatis层面核心类的方法调用序列图。
1、SQL执行序列图
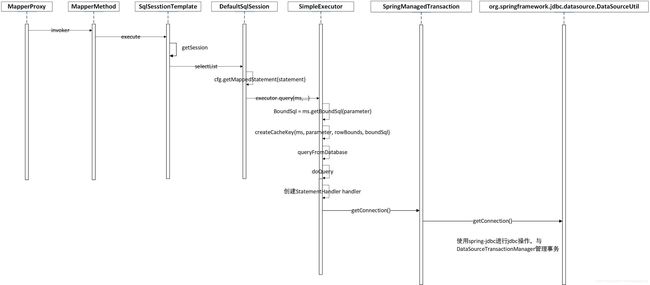
2、源码解析SQL执行流程
接下来从从源码的角度对其进行剖析。
温馨提示:在本文的末尾,还会给出一张详细的Mybatis Shardingjdbc语句执行流程图。(请勿错过哦)。
2.1 MapperProxy#invoker
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (Object.class.equals(method.getDeclaringClass())) {
try {
return method.invoke(this, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
final MapperMethod mapperMethod = cachedMapperMethod(method); // @1
return mapperMethod.execute(sqlSession, args); // @2
}
代码@1:创建并缓存MapperMethod对象。
代码@2:调用MapperMethod对象的execute方法,即mapperInterface中定义的每一个方法最终会对应一个MapperMethod。
2.2 MapperMethod#execute
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
if (SqlCommandType.INSERT == command.getType()) {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
} else if (SqlCommandType.UPDATE == command.getType()) {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
} else if (SqlCommandType.DELETE == command.getType()) {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
} else if (SqlCommandType.SELECT == command.getType()) {
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
result = sqlSession.selectOne(command.getName(), param);
}
} else {
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
该方法主要是根据SQL类型,insert、update、select等操作,执行对应的逻辑,本文我们以查询语句,进行跟踪,进入executeForMany(sqlSession, args)方法。
2.3 MapperMethod#executeForMany
private <E> Object executeForMany(SqlSession sqlSession, Object[] args) {
List<E> result;
Object param = method.convertArgsToSqlCommandParam(args);
if (method.hasRowBounds()) {
RowBounds rowBounds = method.extractRowBounds(args);
result = sqlSession.<E>selectList(command.getName(), param, rowBounds);
} else {
result = sqlSession.<E>selectList(command.getName(), param);
}
// issue #510 Collections & arrays support
if (!method.getReturnType().isAssignableFrom(result.getClass())) {
if (method.getReturnType().isArray()) {
return convertToArray(result);
} else {
return convertToDeclaredCollection(sqlSession.getConfiguration(), result);
}
}
return result;
}
该方法也比较简单,最终通过SqlSession调用selectList方法。
2.4 DefaultSqlSession#selectList
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement); // @1
List<E> result = executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER); // @2
return result;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
代码@1:根据资源名称获取对应的MappedStatement对象,此时的statement为资源名称,例如com.demo.UserMapper.findUser。至于MappedStatement对象的生成在上一节初始化时已详细介绍过,此处不再重复介绍。
代码@2:调用Executor的query方法。这里说明一下,其实一开始会进入到CachingExecutor#query方法,由于CachingExecutor的Executor delegate属性默认是SimpleExecutor,故最终还是会进入到SimpleExecutor#query中。
接下来我们进入到SimpleExecutor的父类BaseExecutor的query方法中。
2.5 BaseExecutor#query
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // @1
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) throw new ExecutorException("Executor was closed.");
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; // @2
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); // @3
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear(); // issue #601
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { // @4
clearLocalCache(); // issue #482
}
}
return list;
}
代码@1:首先介绍一下该方法的入参,这些类都是Mybatis的重要类:
- MappedStatement ms
映射语句,一个MappedStatemnet对象代表一个Mapper中的一个方法,是映射的最基本对象。 - Object parameter
SQL语句的参数列表。 - RowBounds rowBounds
行边界对象,其实就是分页参数limit与size。 - ResultHandler resultHandler
结果处理Handler。 - CacheKey key
Mybatis缓存Key - BoundSql boundSql
SQL与参数绑定信息,从该对象可以获取在映射文件中的SQL语句。
代码@2:首先从缓存中获取,Mybatis支持一级缓存(SqlSession)与二级缓存(多个SqlSession共享)。
代码@3:从数据库查询结果,然后进入到doQuery方法,执行真正的查询动作。
代码@4:如果一级缓存是语句级别的,则语句执行完毕后,删除缓存。
2.6 SimpleExecutor#doQuery
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); // @1
stmt = prepareStatement(handler, ms.getStatementLog()); // @2
return handler.<E>query(stmt, resultHandler); // @3
} finally {
closeStatement(stmt);
}
}
代码@1:创建StatementHandler,这里会加入Mybatis的插件扩展机制(将在下篇详细介绍),如图所示:

代码@2:创建Statement对象,注意,这里就是JDBC协议的java.sql.Statement对象了。
代码@3:使用Statment对象执行SQL语句。
接下来详细介绍Statement对象的创建过程与执行过程,即分布详细跟踪代码@2与代码@3。
3、Statement对象创建流程
3.1 java.sql.Connection对象创建
3.1.1 SimpleExecutor#prepareStatement
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog); // @1
stmt = handler.prepare(connection); // @2
handler.parameterize(stmt); // @3
return stmt;
}
创建Statement对象,分成三步:
代码@1:创建java.sql.Connection对象。
代码@2:使用Connection对象创建Statment对象。
代码@3:对Statement进行额外处理,特别是PrepareStatement的参数设置(ParameterHandler)。
3.1.2 SimpleExecutor#getConnection
getConnection方法,根据上面流程图所示,先是进入到org.mybatis.spring.transaction.SpringManagedTransaction,再通过spring-jdbc框架,利用DataSourceUtils获取连接,其代码如下:
public static Connection doGetConnection(DataSource dataSource) throws SQLException {
Assert.notNull(dataSource, "No DataSource specified");
ConnectionHolder conHolder = (ConnectionHolder) TransactionSynchronizationManager.getResource(dataSource);
if (conHolder != null && (conHolder.hasConnection() || conHolder.isSynchronizedWithTransaction())) {
conHolder.requested();
if (!conHolder.hasConnection()) {
conHolder.setConnection(dataSource.getConnection());
}
return conHolder.getConnection();
}
// Else we either got no holder or an empty thread-bound holder here.
logger.debug("Fetching JDBC Connection from DataSource");
Connection con = dataSource.getConnection(); // @1
// 这里省略与事务处理相关的代码
return con;
}
代码@1:通过DataSource获取connection,那此处的DataSource是“谁”呢?看一下我们工程的配置:


故最终dataSouce.getConnection获取的连接,是从SpringShardingDataSource中获取连接。
com.dangdang.ddframe.rdb.sharding.jdbc.ShardingDataSource#getConnection
public ShardingConnection getConnection() throws SQLException {
MetricsContext.init(shardingProperties);
return new ShardingConnection(shardingContext);
}
返回的结果如下:
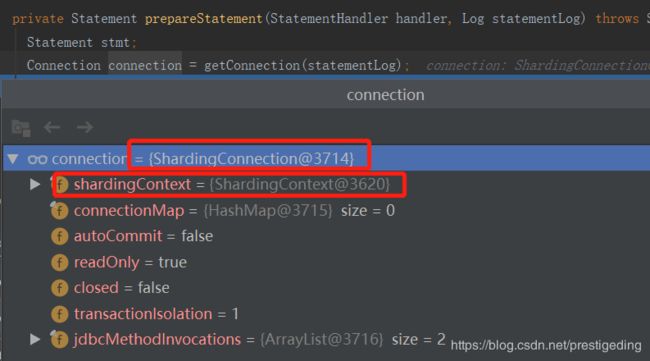
备注:这里只是返回了一个ShardingConnection对象,该对象包含了分库分表上下文,但此时并没有执行具体的分库操作(切换数据源)。
Connection的获取流程清楚后,我们继续来看一下Statemnet对象的创建。
3.2 java.sql.Statement对象创建
stmt = prepareStatement(handler, ms.getStatementLog());
上面语句的调用链:RoutingStatementHandler -》BaseStatementHandler
3.2.1 BaseStatementHandler#prepare
public Statement prepare(Connection connection) throws SQLException {
ErrorContext.instance().sql(boundSql.getSql());
Statement statement = null;
try {
statement = instantiateStatement(connection); // @1
setStatementTimeout(statement); // @2
setFetchSize(statement); // @3
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
代码@1:根据Connection对象(本文中是ShardingConnection)来创建Statement对象,其默认实现类:PreparedStatementHandler#instantiateStatement方法。
代码@2:为Statement设置超时时间。
代码@3:设置fetchSize。
3.2.2 PreparedStatementHandler#instantiateStatement
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() != null) {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
} else {
return connection.prepareStatement(sql);
}
}
其实Statement对象的创建,就比较简单了,既然Connection是ShardingConnection,那就看一下其对应的prepareStatement方法即可。
3.2.2 ShardingConnection#prepareStatement
public PreparedStatement prepareStatement(final String sql) throws SQLException { // sql,为配置在mybatis xml文件中的sql语句
return new ShardingPreparedStatement(this, sql);
}
ShardingPreparedStatement(final ShardingConnection shardingConnection,
final String sql, final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability) {
super(shardingConnection, resultSetType, resultSetConcurrency, resultSetHoldability);
preparedSQLRouter = shardingConnection.getShardingContext().getSqlRouteEngine().prepareSQL(sql);
}
在构建ShardingPreparedStatement对象的时候,会根据SQL语句创建解析SQL路由的解析器对象,但此时并不会执行相关的路由计算,PreparedStatement对象创建完成后,就开始进入SQL执行流程中。
4、SQL执行流程
接下来我们继续看SimpleExecutor#doQuery方法的第3步,执行SQL语句:
handler.<E>query(stmt, resultHandler)。
首先会进入RoutingStatementHandler这个类中,进行Mybatis层面的路由(主要是根据Statement类型)

然后进入到PreparedStatementHandler#query中。
4.1 PreparedStatementHandler#query
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute(); // @1
return resultSetHandler.<E> handleResultSets(ps); // @2
}
代码@1:调用PreparedStatement的execute方法,由于本例是使用了Sharding-jdbc分库分表,此时调用的具体实现为:ShardingPreparedStatement。
代码@2:处理结果。
我们接下来分别来跟进execute与结果处理方法。
4.2 ShardingPreparedStatement#execute
public boolean execute() throws SQLException {
try {
return new PreparedStatementExecutor(getShardingConnection().getShardingContext().getExecutorEngine(), routeSQL()).execute(); // @1
} finally {
clearRouteContext();
}
}
这里奥妙无穷,其关键点如下:
1)创造PreparedStatementExecutor对象,其两个核心参数:
- ExecutorEngine executorEngine:shardingjdbc执行引擎。
- Collection< PreparedStatementExecutorWrapper> preparedStatemenWrappers
一个集合,每一个集合是PreparedStatement的包装类,这个集合如何而来?
2)preparedStatemenWrappers是通过routeSQL方法产生的。
3)最终调用PreparedStatementExecutor方法的execute来执行。
接下来分别看一下routeSQL与execute方法。
4.3 ShardingPreparedStatement#routeSQL
private List<PreparedStatementExecutorWrapper> routeSQL() throws SQLException {
List<PreparedStatementExecutorWrapper> result = new ArrayList<>();
SQLRouteResult sqlRouteResult = preparedSQLRouter.route(getParameters()); // @1
MergeContext mergeContext = sqlRouteResult.getMergeContext();
setMergeContext(mergeContext);
setGeneratedKeyContext(sqlRouteResult.getGeneratedKeyContext());
for (SQLExecutionUnit each : sqlRouteResult.getExecutionUnits()) { // @2
PreparedStatement preparedStatement = (PreparedStatement) getStatement(getShardingConnection().getConnection(each.getDataSource(), sqlRouteResult.getSqlStatementType()), each.getSql()); // @3
replayMethodsInvocation(preparedStatement);
getParameters().replayMethodsInvocation(preparedStatement);
result.add(wrap(preparedStatement, each));
}
return result;
}
代码@1:根据SQL参数进行路由计算,本文暂不关注其具体实现细节,这些将在具体分析Sharding-jdbc时具体详解,在这里就直观看一下其结果:
代码@2、@3:对分库分表的结果进行遍历,然后使用底层Datasource来创建Connection,创建PreparedStatement 对象。
routeSQL就暂时讲到这,从这里我们得知,会在这里根据路由结果,使用底层的具体数据源创建对应的Connection与PreparedStatement 对象。
4.4 PreparedStatementExecutor#execute
public boolean execute() {
Context context = MetricsContext.start("ShardingPreparedStatement-execute");
eventPostman.postExecutionEvents();
final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();
final Map<String, Object> dataMap = ExecutorDataMap.getDataMap();
try {
if (1 == preparedStatementExecutorWrappers.size()) { // @1
PreparedStatementExecutorWrapper preparedStatementExecutorWrapper = preparedStatementExecutorWrappers.iterator().next();
return executeInternal(preparedStatementExecutorWrapper, isExceptionThrown, dataMap);
}
List<Boolean> result = executorEngine.execute(preparedStatementExecutorWrappers, new ExecuteUnit<PreparedStatementExecutorWrapper, Boolean>() { // @2
@Override
public Boolean execute(final PreparedStatementExecutorWrapper input) throws Exception {
synchronized (input.getPreparedStatement().getConnection()) {
return executeInternal(input, isExceptionThrown, dataMap);
}
}
});
return (null == result || result.isEmpty()) ? false : result.get(0);
} finally {
MetricsContext.stop(context);
}
}
代码@1:如果计算出来的路由信息为1个,则同步执行。
代码@2:如果计算出来的路由信息有多个,则使用线程池异步执行。
那还有一个问题,通过PreparedStatement#execute方法执行后,如何返回结果呢?特别是异步执行的。
在上文其实已经谈到:
4.4 DefaultResultSetHandler#handleResultSets
public List<Object> handleResultSets(Statement stmt) throws SQLException {
ErrorContext.instance().activity("handling results").object(mappedStatement.getId());
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
ResultSetWrapper rsw = getFirstResultSet(stmt); // @1
//省略部分代码,完整代码可以查看DefaultResultSetHandler方法。
return collapseSingleResultList(multipleResults);
}
private ResultSetWrapper getFirstResultSet(Statement stmt) throws SQLException {
ResultSet rs = stmt.getResultSet(); // @2
while (rs == null) {
// move forward to get the first resultset in case the driver
// doesn't return the resultset as the first result (HSQLDB 2.1)
if (stmt.getMoreResults()) {
rs = stmt.getResultSet();
} else {
if (stmt.getUpdateCount() == -1) {
// no more results. Must be no resultset
break;
}
}
}
return rs != null ? new ResultSetWrapper(rs, configuration) : null;
}
我们看一下其关键代码如下:
代码@1:调用Statement#getResultSet()方法,如果使用shardingJdbc,则会调用ShardingStatement#getResultSet(),并会处理分库分表结果集的合并,在这里就不详细进行介绍,该部分会在shardingjdbc专栏详细分析。
代码@2:jdbc statement中获取结果集的通用写法,这里也不过多的介绍。
mybatis shardingjdbc SQL执行流程就介绍到这里了,为了方便大家对上述流程的理解,最后给出SQL执行的流程图:
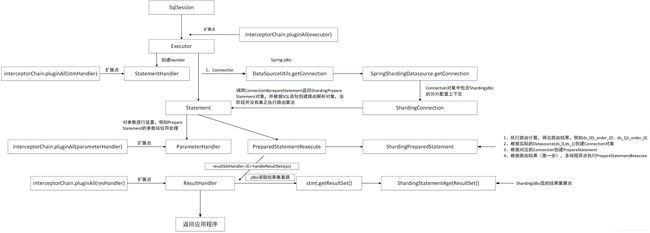
Mybatis Sharding-Jdbc的SQL执行流程就介绍到这里了,从图中也能清晰看到Mybatis的拆件机制,将在下文详细介绍。
欢迎加笔者微信号(dingwpmz),加群探讨,笔者优质专栏目录:
1、源码分析RocketMQ专栏(40篇+)
2、源码分析Sentinel专栏(12篇+)
3、源码分析Dubbo专栏(28篇+)
4、源码分析Mybatis专栏
5、源码分析Netty专栏(18篇+)
6、源码分析JUC专栏
7、源码分析Elasticjob专栏
8、Elasticsearch专栏(20篇+)
9、源码分析MyCat专栏