springboot 集成Elasticsearch使用ElasticSearchRepository进行增删改查操作
1.引入elasticsearch相关的依赖
org.springframework.boot
spring-boot-starter-data-elasticsearch
2.1.5.RELEASE
pom.xml文件中最重要的其实就是引入ES(Elasticsearch的简称后面我都这么叫),也就是spring-boot-starter-data-elasticsearch 依赖。
2.接下来就是对应的配置文件了,具体配置文件如下所示:
# elasticsearch集群名称,默认的是elasticsearch
spring.data.elasticsearch.cluster-name=my-application
#节点的地址 注意api模式下端口号是9300,千万不要写成9200
spring.data.elasticsearch.cluster-nodes=192.168.11.24:9300
#是否开启本地存储
spring.data.elasticsearch.repositories.enable=true
3.索引对应的实体类如下所示:
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
@Document(indexName = "company",type = "employee", shards = 1,replicas = 0, refreshInterval = "-1")
public class Employee {
@Id
private String id;
@Field
private String firstName;
@Field
private String lastName;
@Field
private Integer age = 0;
@Field
private String about;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getAbout() {
return about;
}
public void setAbout(String about) {
this.about = about;
}
@Override
public String toString() {
return "Employee{" +
"id='" + id + '\'' +
", firstName='" + firstName + '\'' +
", lastName='" + lastName + '\'' +
", age=" + age +
", about='" + about + '\'' +
'}';
}
}
4.实体类对应的dao接口如下所示:
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Component;
import springbootelasticsearchrepository.springbootelasticsearchrepository.pojo.Employee;
@Component
public interface EmployeeRepository extends ElasticsearchRepository {
Employee queryEmployeeById(String id);
}
5. ElasticSearchRepository的基本使用
@NoRepositoryBean
public interface ElasticsearchRepository extends ElasticsearchCrudRepository {
S index(S var1);
Iterable search(QueryBuilder var1);
Page search(QueryBuilder var1, Pageable var2);
Page search(SearchQuery var1);
Page searchSimilar(T var1, String[] var2, Pageable var3);
void refresh();
Class getEntityClass();
}
我们是通过继承ElasticsearchRepository来完成基本的CRUD及分页操作的,和普通的JPA没有什么区别。
ElasticsearchRepository继承了ElasticsearchCrudRepository extends PagingAndSortingRepository.
这个没什么特点,就是普通的JPA查询,这个很熟悉,通过上面的JPA查询就能完成很多的基本操作了。
插入数据也很简单:
/**
* 添加
*
* @return
*/
@RequestMapping("add")
public String add() {
Employee employee = new Employee();
employee.setId("3");
employee.setFirstName("xuxu");
employee.setLastName("zh");
employee.setAge(26);
employee.setAbout("i am in peking");
Employee employee1 = employeeRepository.save(employee);
System.err.println("add a obj");
System.out.println(employee1.toString());
return "success";
}
/**
* 批量添加
*
* @return
*/
@RequestMapping("addBatch")
public String addBatch() {
Employee employee = new Employee();
employee.setId("3");
employee.setFirstName("xuxu");
employee.setLastName("zh");
employee.setAge(26);
employee.setAbout("i am in peking");
Employee employee2 = new Employee();
employee2.setId("3");
employee2.setFirstName("xuxu");
employee2.setLastName("zh");
employee2.setAge(26);
employee2.setAbout("i am in peking");
List sampleEntities = Arrays.asList(employee, employee2);
employeeRepository.saveAll(sampleEntities);
System.err.println("add a obj");
//System.out.println(employee1.toString());
return "success";
}
特殊情况下,ElasticsearchRepository里面有几个特殊的search方法,这些是ES特有的,和普通的JPA区别的地方,用来构建一些ES查询的。
主要是看QueryBuilder和SearchQuery两个参数,要完成一些特殊查询就主要看构建这两个参数。
我们先来看看它们之间的类关系

从这个关系中可以看到ES的search方法需要的参数SearchQuery是一个接口,有一个实现类叫NativeSearchQuery,实际使用中,我们的主要任务就是构建NativeSearchQuery来完成一些复杂的查询的。

我们可以看到要构建NativeSearchQuery,主要是需要几个构造参数
public NativeSearchQuery(QueryBuilder query, QueryBuilder filter, List sorts, Field[] highlightFields) {
this.query = query;
this.filter = filter;
this.sorts = sorts;
this.highlightFields = highlightFields;
}
当然了,我们没必要实现所有的参数。
可以看出来,大概是需要QueryBuilder,filter,和排序的SortBuilder,和高亮的字段。
一般情况下,我们不是直接是new NativeSearchQuery,而是使用NativeSearchQueryBuilder。
通过NativeSearchQueryBuilder.withQuery(QueryBuilder1).withFilter(QueryBuilder2).withSort(SortBuilder1).withXXXX().build();这样的方式来完成NativeSearchQuery的构建。
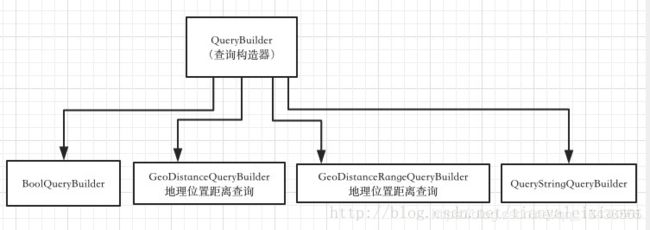

从名字就能看出来,QueryBuilder主要用来构建查询条件、过滤条件,SortBuilder主要是构建排序。
譬如,我们要查询距离某个位置100米范围内的所有人、并且按照距离远近进行排序:
double lat = 39.929986;
double lon = 116.395645;
Long nowTime = System.currentTimeMillis();
//查询某经纬度100米范围内
GeoDistanceQueryBuilder builder = QueryBuilders.geoDistanceQuery("address").point(lat, lon)
.distance(100, DistanceUnit.METERS);
GeoDistanceSortBuilder sortBuilder = SortBuilders.geoDistanceSort("address")
.point(lat, lon)
.unit(DistanceUnit.METERS)
.order(SortOrder.ASC);
Pageable pageable = new PageRequest(0, 50);
NativeSearchQueryBuilder builder1 = new NativeSearchQueryBuilder().withFilter(builder).withSort(sortBuilder).withPageable(pageable);
SearchQuery searchQuery = builder1.build();
要完成字符串的查询:
SearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.queryStringQuery("spring boot OR 书籍")).build();
或者
QueryStringQueryBuilder builder = new QueryStringQueryBuilder(q);
Iterable searchResult = employeeRepository.search(builder);
或者
// 分数,并自动按分排序(对单个属性进行查询)
FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.
functionScoreQuery(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("about", q)),
ScoreFunctionBuilders.weightFactorFunction(1000));
SearchQuery searchQuery = new NativeSearchQueryBuilder().withPageable(pageable)
.withQuery(functionScoreQueryBuilder).build();
要构建QueryBuilder,我们可以使用工具类QueryBuilders,里面有大量的方法用来完成各种各样的QueryBuilder的构建,字符串的、Boolean型的、match的、地理范围的等等。
要构建SortBuilder,可以使用SortBuilders来完成各种排序。
然后就可以通过NativeSearchQueryBuilder来组合这些QueryBuilder和SortBuilder,再组合分页的参数等等,最终就能得到一个SearchQuery了。
至此,我们明白了ElasticSearchRepository里那几个search查询方法需要的参数的含义和构建方式了
详细代码地址:https://gitee.com/oubobey/springboot-elasticsearch