爬虫学习之猫眼TOP100爬取
一.进入猫眼TOP100网站,分析respond结果
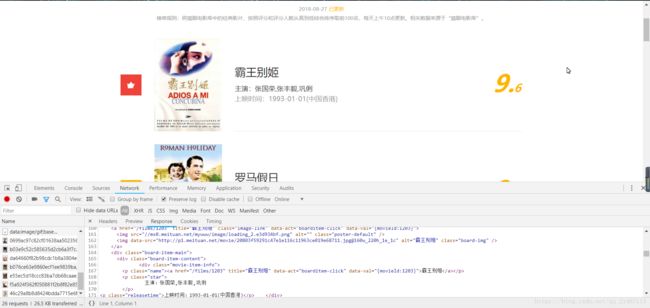
可以直接接收到HTML代码,使用request库来获取网页代码。
二.获取网页代码
先用一小段代码测试下能否正常接收
import requests
respond = requests.get('http://maoyan.com/board/4')
print(respond.text)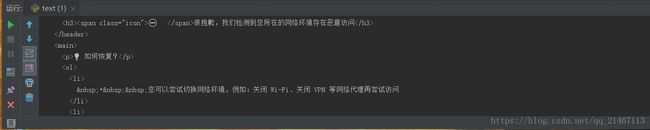 可以看到访问获得的并不是我们想要的代码,因为这是猫眼官方设置的反爬取手段,request的方式不能获取到,就只能使用selenium库来模拟访问获取。
可以看到访问获得的并不是我们想要的代码,因为这是猫眼官方设置的反爬取手段,request的方式不能获取到,就只能使用selenium库来模拟访问获取。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://maoyan.com/board/4')
print(browser.page_source) 可以看到成功获取到了自己想要的代码
可以看到成功获取到了自己想要的代码
三.提取关键信息
现在获取到了top榜的数据,但并不方便我们观看,因为这个网页信息比较简单,所以直接使用正则表达式来进行提取。
from selenium import webdriver
import re
browser = webdriver.Chrome()
def get_pagesource():
try:
url = 'https://maoyan.com/board/4?'
browser.get(url)
return browser.page_source
except TimeoutError:
get_pagesource()
def handelsource(html):
print(html)
pattern = re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">(.*?).*?star">(.*?).*?releasetime">(.*?)'
+'.*?integer">(.*?).*?fraction">(.*?).*? ',re.S)
results = re.findall(pattern,html)
for item in results:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5]+item[6]
}
def main():
html = get_pagesource()
for item in handelsource(html):
print(item)
if __name__ == '__main__':
main()并将需要的信息存储成一个字典,方便查看

四.存储爬取信息
通过一个I/O操作将爬取信息写入文件中
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False) + '\n')
f.close()注:对于传入的字典信息需对其用json.dumps()转化为字符串。
五.批处理爬取
因为改爬取页数只有10页,可以通过创建一个进程池Pool来进行批处理爬取所以页面信息
以下为完整代码:
from selenium import webdriver
import re
import json
from multiprocessing import Pool
browser = webdriver.Chrome()
def get_pagesource(data):
try:
url = 'https://maoyan.com/board/4?offset=' + str(data)
browser.get(url)
return browser.page_source
except TimeoutError:
get_pagesource()
def handelsource(html):
print(html)
pattern = re.compile('.*?board-index.*?>(\d+).*?data-src="(.*?)".*?name">(.*?).*?star">(.*?).*?releasetime">(.*?)'
+'.*?integer">(.*?).*?fraction">(.*?).*? ',re.S)
results = re.findall(pattern,html)
for item in results:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5]+item[6]
}
def write_to_file(content):
with open('result.txt','a',encoding='utf-8') as f:
f.write(json.dumps(content,ensure_ascii=False) + '\n')
f.close()
def main(data):
html = get_pagesource(data)
for item in handelsource(html):
write_to_file(item)
if __name__ == '__main__':
pool = Pool()
pool.map(main, [i*10 for i in range(10)])