Python pandas处理csv文件
Python pandas处理csv文件
工具:Pycharm,Win10,Python3.6.4
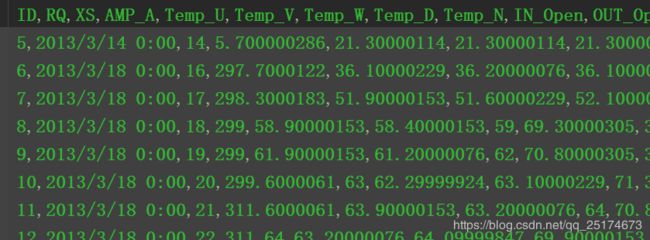
现有上面这样一份CSV文件,我们要对其做如下处理
1.第一列重新编序号从1开始
2.第三列数字0改成24
3.第三列之后的数据带小数的精度都设为小数点后一位
因为我们要对多个csv文件处理,所以事先把多个csv文件放在一个文件夹中,循环读取每个文件并对每个文件做以上处理。
1.重新编序号
data = pd.read_csv('files/'+csvfile,)
# print(len(data))
for i in range (len(data)):
data['ID'][i] = i + 1但是这段代码有个问题,会提示警告导致程序卡死,经过百度添加
pd.set_option('mode.chained_assignment', None)解决这个问题。
2.第三列数字0改为24
data = pd.read_csv('files/'+csvfile,)
# print(len(data))
for i in range (len(data)):
data['ID'][i] = i + 1
if data.iloc[:,2][i] == 0:
data.iloc[:, 2][i] = 243.第三列之后的数据带小数的精度都设为小数点后一位
num = data.columns.size
# data = data.dropna()
for n in range(3,num):
for k in range(len(data.iloc[:, n])):
# if data.iloc[:, n][k].isna() == False:
data.iloc[:, n][k] =((data.iloc[:, n][k]+0.05) * 10).astype('int') / 10完整代码如下
import pandas as pd
import os
# pd.set_option('mode.chained_assignment', None)
for csvfile in os.listdir('files/'):
data = pd.read_csv('files/'+csvfile,)
# print(len(data))
for i in range (len(data)):
data['ID'][i] = i + 1
if data.iloc[:,2][i] == 0:
data.iloc[:, 2][i] = 24
# data.iloc[:,lambda data:[3,]] =int( (data.iloc[:,lambda data:[3,]]+0.05) * 10) / 10
num = data.columns.size
# data = data.dropna()
for n in range(3,num):
for k in range(len(data.iloc[:, n])):
# if data.iloc[:, n][k].isna() == False:
data.iloc[:, n][k] =((data.iloc[:, n][k]+0.05) * 10).astype('int') / 10
data.to_csv(csvfile+'_process.csv',index = False)主要是简单熟悉一下os模块,pandas模块。如果文件中有空数据会自动处理成
-214748364.8