解决防爬虫机制方法(二)
最近为了完成学校的大数据的作业,老师要我们爬一个的网站,里面有还算不错的防爬机制,忙活了几天,总结出一些常见的防爬机制的应对方法,方法均来自个人实战总结,非专业爬虫角度分析
承接上一次讲的方法解决防爬虫机制方法(一)-CSDN博客
3. 学会抓包
其实这个不算是防爬虫机制的方法了,主要是网站基于异步处理,就是点击了其他种类但是url并没有跳转,标签页如图下所示:


一般很多网页都是基于页码或者是同页面下通过转url来进行页面跳转,如果遇到这种以上这种情况也算是防爬虫的一个小手段了吧,一般每种病都是有一个编号的,但是通过控制台无法找到一个文件包含了所有疾病对应的编号
通过搜索对应编号只有自己的url包出现,通过点击其他类型疾病后这个包还会继续保留,

然后我的做法是通过筛选出url包获取,然后将每个种类都点击一下,这样就会抓到每个类型里面全部的包,然后通过筛选如图下所示:
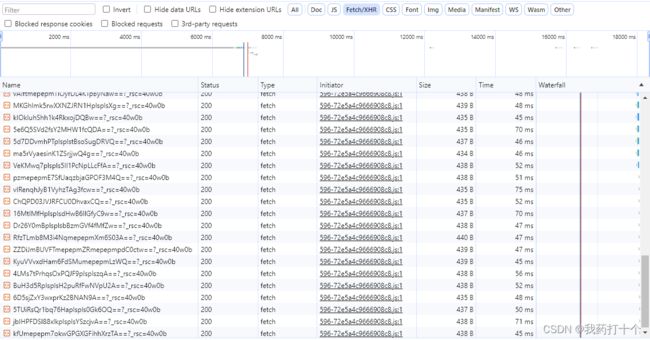
通过对应的导出键就可以将所有的抓包全部导出来了
![]()
后面则可以通过python里的haralyzer来解析包,但是里面的url地址挺多的,自己可以通过筛选出自己想要的url地址
演示代码如下所示
import json
from haralyzer import HarParser
# 用你的HAR文件路径替换下面的路径
har_file_path = 'drugs.dxy.cn.har'
# 读取HAR文件
with open(har_file_path, 'r', encoding='utf-8') as file:
har_content = file.read()
# 将HAR文件内容转换为字典
har_dict = json.loads(har_content)
# 创建HarParser对象
har_parser = HarParser(har_dict)
# 解析HAR文件
har_data = har_parser.har_data
# print(har_data)
# 获取请求列表
# print("Keys in har_data:", har_data.keys())
# Keys in har_data: dict_keys(['version', 'creator', 'pages', 'entries'])
entries = har_data['entries']
# 打印请求的详细信息
urls = []
if entries:
for i in range(len(entries)):
first_entry = entries[i]
print("Request URL:", first_entry['request']['url'])
print("Request Method:", first_entry['request']['method'])
print("Response Status:", first_entry['response']['status'])
print("Response Content Type:", first_entry['response']['content']['mimeType'])
else:
print("No entries found in the HAR file.")
print(urls[-8])
这些方法还是比较适用于一些比较简单的爬取,如果是大佬级别或者是长时间爬取的仅供参考
希望这篇博客对你有帮助!!!!!