Tensorflow基于mnist数据集实现AlexNet
AlexNet
AlexNet 可以说是具有历史意义的一个网络结构,可以说在AlexNet之前,深度学习已经沉寂了很久。历史的转折在2012年到来,AlexNet 在当年的ImageNet图像分类竞赛中,top-5错误率比上一年的冠军下降了十个百分点,而且远远超过当年的第二名。
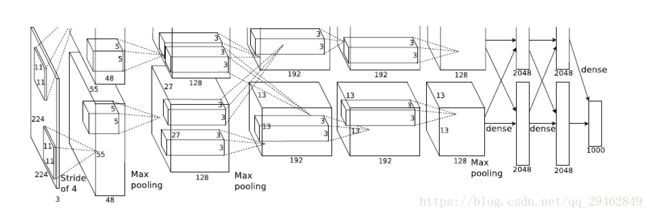
下图所示即为Alexnet的网络结构,主要由九个部分组成:
- 图像输入层
- Layer1(卷积层+池化层)
- Layer2(卷积层+池化层)
- Layer3(卷积层)
- Layer4(卷积层)
- Layer5(卷积层+池化层)
- Layer6(全连接层+Dropout)
- Layer7(全连接层+Dropout)
- Softmax层
不同之处
AlexNet的原始输入数据为224*224*3,但是因为自己电脑的性能不够好,只能通过mnist小型数据集进行替代。除此之外,AlexNet中包含LRN层(局部响应归一化层),由于现在很少使用LRN层,更多的是被L1、L2或者Dropout等代替,所以程序中只使用了Dropout,tensorflow中包含LRN操作,有兴趣可以看下。以下代码可以直接运行使用!
代码
# -*- coding: utf-8 -*-
"""
Created on Thu May 10 12:53:59 2018
@author: new
"""
#Tensorflow在mnist数据集上实现Alexnet
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import scipy.misc
import matplotlib.image as mpimg
from skimage import io
#这里可以通过tensorflow内嵌的函数现在mnist数据集
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
sess = tf.InteractiveSession()
#Layer1
W_conv1 =tf.Variable(tf.truncated_normal([3, 3, 1, 32],stddev=0.1))
b_conv1 = tf.Variable(tf.constant(0.1,shape=[32]))
#调整x的大小
x_image = tf.reshape(x, [-1,28,28,1])
h_conv1 = tf.nn.relu(tf.nn.conv2d(x_image, W_conv1,strides=[1, 1, 1, 1], padding='SAME') + b_conv1)
h_pool1 = tf.nn.max_pool(h_conv1, ksize=[1, 2, 2, 1],
strides=[1, 1, 1, 1], padding='SAME')
#Layer2
W_conv2 = tf.Variable(tf.truncated_normal([5, 5, 32, 64],stddev=0.1))
b_conv2 = tf.Variable(tf.constant(0.1,shape=[64]))
h_conv2 = tf.nn.relu(tf.nn.conv2d(h_pool1, W_conv2,strides=[1, 1, 1, 1], padding='SAME') + b_conv2)
h_pool2 = tf.nn.max_pool(h_conv2, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
#Layer3
W_conv3 = tf.Variable(tf.truncated_normal([5, 5, 64, 64],stddev=0.1))
b_conv3 = tf.Variable(tf.constant(0.1,shape=[64]))
h_conv3 = tf.nn.relu(tf.nn.conv2d(h_pool2, W_conv3,strides=[1, 1, 1, 1], padding='SAME') + b_conv3)
#Layer4
W_conv4 = tf.Variable(tf.truncated_normal([5, 5, 64, 32],stddev=0.1))
b_conv4 = tf.Variable(tf.constant(0.1,shape=[32]))
h_conv4 = tf.nn.relu(tf.nn.conv2d(h_conv3, W_conv4,strides=[1, 1, 1, 1], padding='SAME') + b_conv4)
#Layer5
W_conv5 = tf.Variable(tf.truncated_normal([5, 5, 32, 64],stddev=0.1))
b_conv5 = tf.Variable(tf.constant(0.1,shape=[64]))
h_conv5 = tf.nn.relu(tf.nn.conv2d(h_conv4, W_conv5,strides=[1, 1, 1, 1], padding='SAME') + b_conv5)
h_pool3 = tf.nn.max_pool(h_conv5, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
#Layer6-全连接层
W_fc1 = tf.Variable(tf.truncated_normal([7*7*64,1024],stddev=0.1))
b_fc1 = tf.Variable(tf.constant(0.1,shape=[1024]))
#对h_pool2数据进行铺平
h_pool2_flat = tf.reshape(h_pool3, [-1, 7*7*64])
#进行relu计算,matmul表示(wx+b)计算
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#Layer7-全连接层,这里也可以是[1024,其它],大家可以尝试下
W_fc2 = tf.Variable(tf.truncated_normal([1024,1024],stddev=0.1))
b_fc2 = tf.Variable(tf.constant(0.1,shape=[1024]))
h_fc2 = tf.nn.relu(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
h_fc2_drop = tf.nn.dropout(h_fc2, keep_prob)
#Softmax层
W_fc3 = tf.Variable(tf.truncated_normal([1024,10],stddev=0.1))
b_fc3 = tf.Variable(tf.constant(0.1,shape=[10]))
y_conv = tf.matmul(h_fc2_drop, W_fc3) + b_fc3
#在这里通过tf.nn.softmax_cross_entropy_with_logits函数可以对y_conv完成softmax计算,同时计算交叉熵损失函数
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
#定义训练目标以及加速优化器
train_step = tf.train.AdamOptimizer(1e-3).minimize(cross_entropy)
#计算准确率
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#初始化变量
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = mnist.train.next_batch(10)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
#保存模型
save_path = saver.save(sess, "./model/save_net.ckpt")
print("test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images[:3000], y_: mnist.test.labels[:3000], keep_prob: 1.0}))训练结果
可以发现在mnist数据集上进行训练,15轮之后即可收敛。
step 0, training accuracy 0
step 100, training accuracy 0.2
step 200, training accuracy 0.2
step 300, training accuracy 0.1
step 400, training accuracy 0.2
step 500, training accuracy 0.4
step 600, training accuracy 0.6
step 700, training accuracy 0.5
step 800, training accuracy 0.9
step 900, training accuracy 0.8
step 1000, training accuracy 0.7
step 1100, training accuracy 0.9
step 1200, training accuracy 0.9
step 1300, training accuracy 0.9
step 1400, training accuracy 0.9
step 1500, training accuracy 0.9
step 1600, training accuracy 1
step 1700, training accuracy 1
step 1800, training accuracy 1
step 1900, training accuracy 1