目标跟踪
本篇是基于单目标跟踪的论述
目标跟踪概述
1.1 定义:
1,单目标,即在给定的视频中只跟踪一个目标
2,在第一帧中会通过矩形的bounding box将目标给出。给定后,使用tracker找出每一帧的目标。
3,短期
1.2 目标跟踪面临的挑战有:
1,运动模糊(Motion Blur)

在获取视频时由于环境因素,相机抖动或物体运动等多种因素的影响,导致获取的视频帧像素退化,这种退化会导致角点,边缘等显著特征受损甚至消失。一般存在两种情况,当点扩散函数处于未知状态时,叫做盲去模糊,当点扩散函数已知时叫做非盲去模糊。
2,遮挡(Occlusion)

遮挡是目标跟踪中比较常见的挑战因素。遮挡又分为部分遮挡(Partial Occlusion)和完全遮挡(Full Occlusion)。解决部分遮挡目前较为常用的大致有两种思路:(1)利用检测机制判断目标是否被遮挡,从而决定是否更新模板,保证模板对遮挡的鲁棒性。(2)把目标分成多个块,利用没有被遮挡的块进行有效的跟踪。而对于完全遮挡目前并没有特别好的办法完全解决这个问题。
3,形变(Deformation)(与第一帧差异过大)

通常而言跟踪的目标并非一层不变的。而跟踪目标的形变,如果过大则会导致跟踪发生漂移(Drift)。而解决这个挑战的主要解决点就在解决漂移问题。常用的方法是更新目标的表观模型,使其适应表观的变化。因此面对这个问题时,至关重要的是模型更新方法。能否及时,准时更新,能否确定好更新的频率变成面对这个挑战时要关注的问题。
4,尺度变化(Changing In Scale)(镜头的拉近或拉远)

尺度变换是指目标在运动过程中距离拍摄的镜头距离的变化而产生的尺度大小的变化现象。由于尺度变换如果不能快速准确的预测出跟踪目标变化的系数就会影响跟踪的准确率。现在通常的做法有:(1)在运动模型产生候选样本的时候,生成大量的尺度大小不等的候选框,选择最优作为目标。(2)在多个不同尺度的目标上进行目标跟踪,产生多个预测结果,选择其中最优作为最后的预测目标。
5,快速移动(Fast Motion)

快速移动指的是要跟踪的目标在接下来的帧中,快速的变换位置。这样很可能会导致目标丢失,因此也是目标跟踪的一个比较重要的点。
还有背景杂斑(Background Clutter),光照变化(illumination variation)等其他挑战。总而言之对于视觉跟踪而言,由于运动目标的运动场景大多较为复杂,并且经常发生变化,或者要跟踪的目标本身也会发生变化。这样就导致要考虑的问题变成了,如何在复杂变换的场景中识别并跟踪不断变化的目标。
经过上述的方法总结就个人而言感觉视觉跟踪大致有两个比较困难的点:
1.上述的各个挑战,由于要考虑的视频中跟踪的目标的具体情况不同,所以对应的挑战也不相同,想要一劳永逸的解决是不现实的。可能一个算法在面对一个挑战时表现的很好,但面对另一个挑战时表现的又很差。
2.缺乏训练样本,假如我们使用深度学习的方法来进行目标跟踪。那么我们需要对应的数据集来训练网络,但因为目标跟踪任务的特殊性,只有初始帧的图片数据可以利用,因此缺乏数据供神经网络学习。
1.3 目标跟踪方法:
就目前为止,追踪器大致分为两大类生成性追踪器和鉴别性追踪器。
(1)生成性追踪器(Generative Method):通过在线学习的方式建立目标模型,然后使用模型搜索重建误差最小的图像区域,完成目标定位。这一类方法没有考虑目标的背景信息,图像信息没有得到较好的应用。通俗点讲就是在当前帧对目标区域建模,下一帧寻找与模型最相似的区域就是预测位置,比较著名的有卡尔曼滤波,粒子滤波,mean-shift等。
(2)鉴别性追踪器(Discriminative Method):将目标跟踪看作是一个二元分类问题,同时提取目标和背景信息用来训练分类器,将目标从图像序列背景中分离出来,从而得到当前帧的目标位置。CV中的经典套路图像特征+机器学习, 当前帧以目标区域为正样本,背景区域为负样本,机器学习方法训练分类器,下一帧用训练好的分类器找最优区域:与生成类方法最大的区别是,分类器采用机器学习,训练中用到了背景信息,这样分类器就能专注区分前景和背景,所以判别类方法普遍都比生成类好。
1.4 跟踪方法:
稀疏表示(Sparse Representation):对于生成性追踪器来说,较为典型的就是稀疏矩阵了。给定一组过完备字典,将输入信号用这组过完备字典线性表示,对线性表示的系数做一个稀疏性的约束(即使得系数向量的分量尽可能多的为0),那么这一过程就称为稀疏表示。基于稀疏表示的目标跟踪方法则将跟踪问题转化为稀疏逼近问题来求解。但实际上近些年来生成性追踪器使用的较少。因此系数表示也用的也比较少。基本上相关滤波和深度学习占据了目标跟踪的大半。
相关滤波(Correlation Filter):相关滤波本身源于信号领域。其基本思想为衡量两个信号是否相关,两个信号越相似,那么相关的操作越强。对于目标跟踪而言,对应的上一帧得到的目标与下一帧中的区域越相似,响应越高。通常使用卷积表示相关的操作。当其应用到目标跟踪上时,其基本思想就是,寻找一个滤波模板,让下一帧的图像与得到的滤波模板做卷积操作,响应最大的区域就是预测的目标。
深度学习(CNN-Based):对于神经网络来说由于CNN引入了卷积层和池化层的概念。而卷积层在输入的时候不仅考虑到了输入的值,还可以保持输入的形状不变。当输入数据是图像时,卷积层会以三维数据的形式接收输入数据,并且同样以三维数据的形式输出至下一层,因此,CNN可以正确理解图像等具有形状的数据。所以对于计算机视觉领域有着独特的优势。对于检测,人脸识别等早CNN早以发出自己的声音。但对于目标跟踪领域而言,开始并不顺畅。正如上文所述由于目标跟踪的特殊,只有初始帧的图片数据可以用,所以缺乏大量的数据供神经网络学习。直到后来将在分类图象数据集上训练的卷积神经网络应用到目标跟踪上后,基于深度学习的目标跟踪方法才得到充分的发展。
1.5 数据集:
OTB:OTB分为OTB50和OTB100,其中OTB100包含OTB50,该数据集的特点是人工标注的groundtruth,同时包含有25%的灰度数据集。
VOT:本身是竞赛数据集更具有代表性。同时VOT每年更新。
VOT与OTB的区别:这两个数据集都是目标跟踪常用的数据集,但还有一定的差别。
(1)OTB包括有25%的灰度序列,但VOT都是彩色序列,这也导致了很多颜色特征算法性能的差异。
(2)两个库的评价标准也不一样。
(3)OTB有随机帧开始,或者矩形框加随机干扰初始化去跑,但VOT是第一帧初始化跑,每次跟踪失败时,5帧之后重新初始化,VOT以短时跟踪为主,并且认为跟踪监测应该在一起不分离,detecter会多次初始化tracker。
目标跟踪基本流程
2.1 基本流程
单目标视觉跟踪的任务就是在给定某一个视频序列初始帧的目标大小与位置的情况下,预测后续帧中该目标的大小与位置,其基本流程如下图所示:
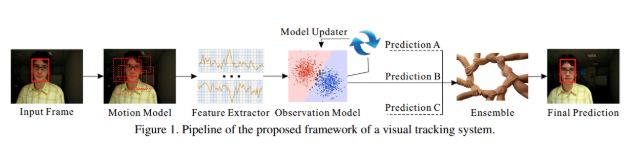
输入初始化目标框,在下一帧中产生众多候选框(Motion Model),提取候选框的特征(Feature Extractor),然后对这些候选框评分(OBservation Model),最后在这些评分中找到一个最高得分的候选框作为预测的目标(Prediction A),或者对多个预测值进行融合(Ensemble)提高准确率。
基于上述过程将该流程大致分为以下五个模块进行研究:
1.运动模型(Motion Model):基于对前一帧的估计,运动模型生成一组可能包含当前帧中目标的候选区域或包围盒。
运动模型旨在描述帧与帧目标运动状态之间的关系,显式或隐式地在视频帧中预测目标图像区域,并给出一组可能的候选区域。常用的有两种方法:粒子滤波和滑动窗口。其中粒子滤波是一种序贯贝叶斯推断方法,通过递归的方式推断目标的隐含状态。滑动窗口是一种穷举搜索方法,它列出目标附近的所有可能的样本作为候选样本。
2.特征提取(Feature Extractor):征提取器使用一些特征表示候选集中的每个候选者。
适用于目标跟踪的特征一般要求,既能较好地描述跟踪目标又能快速计算。常用的特征也被分成两类:手工设计的特征和深度特征。常用的手工设计的特征有:灰度特征,颜色特征,纹理特征等。而深度特征则是通过大量的训练样本学习出来的特征,更具有鉴别性。
3.观测模型(Observation Model):观察模型根据从候选人中提取的特征判断候选人是否是目标。
观测模型返回给定目标候选人的置信度,因此通常被认为是跟踪器的关键部件。与特征提取器和观察模型组件相比,运动模型对性能的影响一般很小。然而,在尺度变化和快速运动的情况下,合理地设置参数仍然是获得良好性能的关键。如上文中提到的,追踪器大致分为两大类生成性追踪器和鉴别性追踪器一致。观测模型可分为两类即生成式模型和鉴别式模型,生成式模型通常寻找与目标模板最为相似的候选作为跟踪结果,可简单视为模板匹配。较为常用为上文中提到的稀疏表示。而鉴别式模型则通过训练一个分类器去区分目标与背景,选择置信度最高的候选样本作为预测结果。判别式方法已经成为目标跟踪中的主流方法,如上文中提到的相关滤波,深度学习。
4.模型更新(Model Update):模型更新器控制更新观测模型的策略和频率。它必须在模型适应和漂移之间取得平衡。
为了捕捉目标( 和背景) 在跟踪过程中的变化,目标跟踪需要包含一个在线更新机制,在跟踪过程中不断更新外观模型。在本文中考虑两种方法。1.每当目标可信度低于阈值时更新模型。这样做可以确保目标始终具有很高的信心。 2.当目标的置信度与背景样本的置信度之差低于阈值时,对模型进行更新。这种策略只是在正面和负面的例子之间保持足够大的差距,而不是强迫目标有很高的信心。
5.集成结果处理(Ensemble Method):当一个跟踪系统由多个跟踪器组成时,集成后处理器获取组成跟踪器的输出,并使用集成学习方法将它们组合成最终结果。
单个跟踪器的结果有时可能非常不稳定,因为即使在很小的扰动下,性能也会发生很大的变化。参数采用集成方法的目的就是为了克服这一限制。
2.2 总结
由上述的过程可得知模块之间的关系为:运动模型负责描述帧与帧目标运动状态之间的关系,给出一组目标可能会出现的候选区域。特征提取则能够很好的跟随目标同时又保证计算较为简洁。而观测模型作用于当前帧,用来判断区域内是否是要跟踪的目标。因为在较长的跟踪过程中目标的特征可能会出现变化,因此需要一个目标更新模块来不时的对观测模型进行实时更新以此来确保跟踪目标的正确性。而单个跟踪器其结果不确定。并不能一定确保跟踪的稳定性。所以需要集成结果处理来确保结果的稳定性。
相关算法
就目前来说相关滤波与深度学习在视觉目标跟踪领域占据主要的地位。如下图所示。

3.1基于相关滤波的典型算法
3.1.1相关滤波在视频跟踪的应用方法:设计一个对目标高响应,同时对背景低响应的滤波器,由此实现对目标模式的快速检测。简单来说就是设计一个滤波模板,利用该模板与目标候选区域做相关运算,最大输出响应的位置即为当前帧的目标位置。
![]()
其中y表示响应输出,x表示输入图像,w表示滤波模板。利用相关定理,将相关转换为计算量更小的点击。
![]()
如上图所示的分别是y,x,w的傅里叶变换。而相关滤波的任务就是寻找最优的滤波模板w。
3.1.2具体的算法:
(1)MOSSE
如同在3.1.1中所提出的相关滤波的应用方法一样,MOSSE的具体做法就是利用了信号处理中的相关性,通过提取目标特征来训练相关滤波器,对下一帧的输入图像进行滤波,当两个信号越相似(后一帧中图像的某个位置与前一帧用于训练的特征越相似),那么在该位置滤波器所计算得到的相关值越高。如下图所示为相关值得计算。
![]()
其中g表示的是计算的相关值,f为输入的图像,h为滤波器模板。运算的过程大致如下,卷积中的卷积层和池化层。
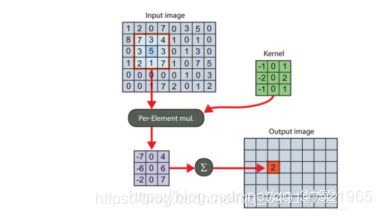
为了减少计算量,加快响应,通过快速傅里叶变换(FFT)将卷积操作变成了点乘操作。同时为了在每一帧后更新相关滤波器,采用将前面的图像都相加的办法,求得相加最小。
所以MOSSE的工作流程大致为:
1.先手动或者条件给定第一帧目标区域,提取特征。
2.对下一帧输入图像裁剪下预测区域,进行特征提取,做FFT运算,与相关滤波相乘后将结果做IFFT运算,得到输出的相应点,其中最大响应点为该帧目标的位置。
3.将该帧的目标区域加入到训练样本中,对相关滤波进行更新。
4.重复步骤2,3.
(2)CSK
CSK针对MOSSE采用稀疏采样造成样本冗余的问题,扩展了岭回归,基于循环移位的近似密集采样方法,以及核方法。
岭回归:
CSK为求解滤波模板的使用了岭回归。如下图:

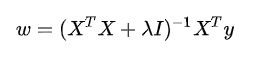
其中x是训练样本,而X是x构成的样本矩阵,y是样本的响应值,w是待求得滤波模板,而λ是正则化系数。使用岭回归为了防止过拟合。使得求到的滤波器在下一帧的图像中的泛化能力更强。
循环移位:
CSK的训练样本是通过循环移位产生的。密集采样与循环移位产生的样本很像,可以用循环移位来近似。循环矩阵原理如图,第一行是实际采集的目标特征,其他行周期性地把最后的矢量依次往前移产生的虚拟目标特征。

对图像进行循环移位的效果实例如图

循环移位的样本集是隐性的,并没有真正产生过,只是在推导过程中用到,所以也不需要真正的内存空间去存储这些样本。同时生成的近似样本集结合FFT极大地减少了计算量,但这种近似引入边界效应。
(3)CN
MOSSE与CSK处理的都是单通道灰度图像。引入多通道特征扩展只需要对频域通道响应求和即可。HOG+CN在近年来的跟踪算法中是常用的特征搭配,HOG是梯度特征,而CN是颜色特征,二者可以互补。
CN其实是一种颜色的命名方式,与RGB,HSV同属于一类。CN在CSK的基础上扩展了多通道颜色。将RGB的3通道图像投影到11个颜色通道,,分别对应英语中常用的语言颜色分类,分别是black, blue, brown, grey, green, orange, pink, purple, red, white, yellow,并归一化得到10通道颜色特征。也可以利用PCA方法,将CN降维到2维。
(4)KCF/DCF
KCF可以说是对CSK的完善。论文中对岭回归、循环矩阵、核技巧、快速检测等做了完整的数学推导。KCF在CSK的基础上扩展了多通道特征。KCF采用的HoG特征,核函数有三种高斯核、线性核和多项式核,高斯核的精确度最高,线性核略低于高斯核,但速度上远快于高斯核。
在前面提到的挑战中有一种挑战是尺度变化。对于这一问题上述的KCF/DCF和CN都没有涉及到。这样的话如果目标发生尺度变化,那么滤波器就会学习到大量的背景信息,如果目标扩大,滤波器可能会跟踪到目标局部纹理。这两种情况都可能出现非预期的结果,导致跟踪漂移和失败。基于此提出SAMF(基于KCF,特征是HOG+CN。采用多尺度检测。取响应最大的平移位置及所在的尺度。因此可以同时检测目标中心变化和尺度变化),DSST(将目标跟踪分解为目标中心平移和目标尺度变化两个独立问题,这样对应的模块只负责一部分,如尺度滤波器仅需要检测出最佳匹配尺度无须关心平移的情况。)
3.2基于深度学习的典型算法
(1)MDNet
MDNet直接使用跟踪视频预训练CNN获得的general目标表示能力,但实际上训练序列也存在问题,因为不同的视频中我们要跟定的目标是不相同的,可能这个视频中要跟踪的目标在下一个视频中就是背景,因此只使用单独一个CNN完成所有的训练序列中前景和背景区分的任务较为困难。
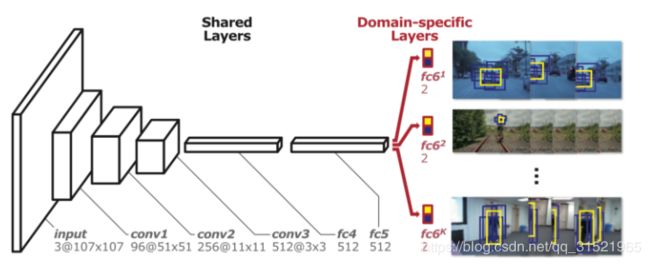
上图包含了MDNet的基本思想。MD分为共享层和domain-specific层两部分。其具体做法是将每个训练序列当成一个单独的domain,每个domain都有一个针对它的二分类层(fc6),用于区分当前序列的前景和背景,而网络之前的所有层都是序列共享的。这样共享层达到了学习跟踪序列中目标general的特征表达的目的,而domain-specific层又解决了不同训练序列分类目标不一致的问题。在具体的训练时,MDNet的每一个mini-batch只由一个特定序列的训练数据构成,只更新共享层和针对当前序列的特定fc6层。这样使得共享层获得了所有的序列共有特征的表达能力,而对应于特定序列的fc6层则只保存有当前序列的特征。
在具体的跟踪阶段,MDNet的主要做法为:
(1)随机初始化一个新的fc6层
(2)使用第一帧的数据来训练该序列的bounding box回归模型。
(3)用第一帧提取正样本和负样本,更新fc4,fc5和fc6层的权重。
(4)之后产生256个候选样本,并从中选择置信度最高的,之后做bounding-box regression得到的结果。
(5)如果当前帧的最终结果置信度比较高,那么采样更新样本库,否则根据情况对模型做短期或者长期的更新。
(2)TCNN
TCNN用了很多个CNN的模型,并构建成一棵树的结构,如图1所示,红色的框越粗说明对应的CNN模型的可靠性(reliability)越高。连接的红色的线越粗,说明两个CNN之间的相关性越高(affinity)。黑色的箭头越粗表示对应的CNN模型对目标估计的权重越高。TCNN还对每一个CNN模型进行了可靠性评估。如下图所示:

每个CNN的网络结构是一样的,前面的卷积层的参数共享,是来自于事先用imageNet训练好的VGG-M网络,再加上后面的全连接层。构成了TCNN。其在第一帧的时候随机初始化并进行迭代训练,后面每次更新的时候都只更新全连接层的参数。如下图所示:

总的来说TCNN效果较好,但差于ECO。
效果好的原因:
(1)使用了多个CNN模型进行检测(10个)
(2)使用了树的结构来组织CNN模型,避免它们只对最近的帧过拟合
(3)CNN会一直有新的模型加进来,且经过fine-tuning。
(4)在确定最终的位置时还做了Bounding Box Regression,进一步提高定位准确性。
3.3深度学习与相关滤波相结合
(1)SRDCF&DeepSRDCF
SRDCF在KCF优化目标的基础上加入了空域正则化,增强了模型的判别能力,优化目标变为:

其中的![]() 指的是对w施加的空间正则化权重。这表明,某些位置(主要是边界)的滤波器系数会受到惩罚。
指的是对w施加的空间正则化权重。这表明,某些位置(主要是边界)的滤波器系数会受到惩罚。
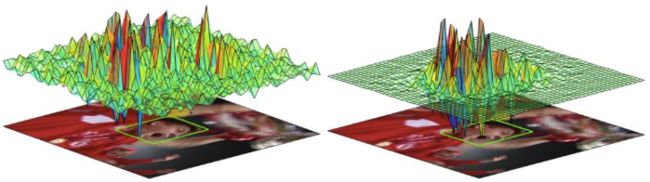
DCF(左)与SRDCF(右)的效果对比。
传统方式获取特征是HOG+CN,后来发现CNN浅层特征比HOG手工特征效果要好后。于是作者将SRDCF的模型更改为使用CNN,也就形成了一个新的模型,即:DeepSRDCF
(2)C-COT
使用一种隐式的插值方式将模型的学习投射到一个连续的空间域中,提出了一种在连续空间域上的卷积算子。C-COT将多种分辨率的深度特征进行了高效的集成,使得模型在各个数据集上的性能都得到了很大的提升。

C-COT的特征图,卷积核,各层置信图和融合后连续空间的输出置信图。
(3)ECO
ECO在C-COT的基础上进一步提升。主要有两点。①ECO降低了C-COT的参数量,对特征提取作了降维简化,提升效率,防止过拟合。②使用高斯混合模型生成不同样本组合,简化训练集的同时还增加了多样性;另外,提出了一种高效的模型更新策略,在提升速度的同时还提升了鲁棒性。

C-COT学习后的卷积核与ECO学习后的卷积核。
(4)SiamFC
SiamFC开创了端到端深度学习相关滤波方法的先河,同时也为深度学习方法逐渐超越相关滤波方法拉开了序幕。其对应的网络如下:
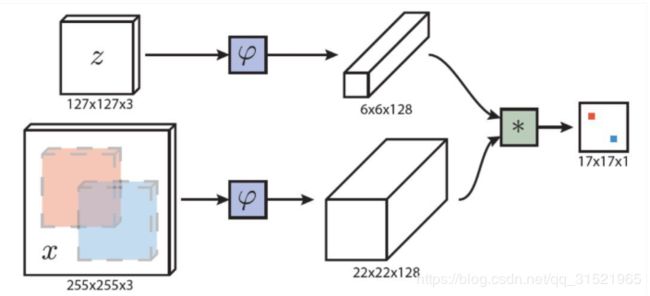
图中φ是CNN编码器,而上下使用的两个CNN结构相同,同时参数也共享。而z和x分别是要跟踪的目标模板图像和新的一桢中的搜索范围(255*255).二者经过同样的编码器后得到各自的特征图,对二者进行互相关运算后则会得到一个如上图所示的响应图(17*17),其每一个像素的值对应了x中与z等大的一个对应区域出现跟踪目标的概率。
(5)SiamRPN&DaSiamRPN
SiamRPN在x和y经过孪生CNN得到各自的特征图后,没有直接对二者进行互相关运算,而是将这两个特征图各自放入RPN部分的两个分支中,每个分支中的两个特征图分别经过一个CNN再进行互相关运算。RPN部分的两个分支分别用于进行目标概率的预测和目标边框的回归,并且同样借鉴了目标检测领域的anchor方法,从而降低了目标边框回归的训练难度。 其具体步骤如下图:
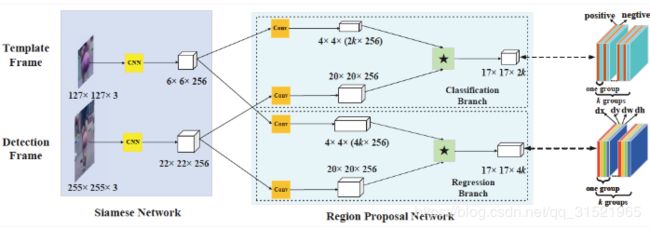
在SiamRPN提出之后,又提出其改进型------DaSiamRPN,对训练数据进行了增强以提升模型对同类别物体干扰的判别能力。同时,DaSiamRPN加入了增量学习的Distractor-aware模块,在运行时采样并更新模型的参数。使得模型模型能够更好的迁移到当前视频的域中。
参考文献
[1] 张微, 康宝生. 相关滤波目标跟踪进展综述[J]. 中国图象图形学报, 2017(8).
[2] 李娟. 基于目标跟踪的视频去运动模糊[D]. 电子科技大学, 2016.
[3] 吴小俊, 徐天阳, 须文波. 基于相关滤波的视频目标跟踪算法综述[J]. 指挥信息系统与技术,2017(3).
[4] 王硕. 基于相关滤波的目标跟踪算法[D].
[5] Wang N , Shi J , Yeung D Y , et al. Understanding and Diagnosing Visual Tracking Systems[J]. 2015.
[6] https://www.zhihu.com/question/26493945/answer/156025576
[7] https://www.cnblogs.com/jjwu/p/8512730.html
[8] https://blog.csdn.net/qq_34919792/article/details/89893433
[9] https://blog.csdn.net/zhu_hongji/article/details/80515031
[10] https://blog.csdn.net/weixin_39467358/article/details/84568474
[11] https://www.zhihu.com/question/26493945